

作者:张景涛
这几天朋友圈被阿里云最新一代智算集群网络架构HPN 7.0的成果论文确定收录入SIGCOMM2024论文名单的新闻刷屏了,新闻中对这个事件不吝各种赞美之词,“SIGCOMM历史上在AI智算集群网络架构领域的首篇论文”,“阿里云提出的新一代网络架构HPN7.0,有望成为下一代AI高性能网络架构的新范式”,甚至有人把这篇论文和当年谷歌传统数据中心网络Jupiter论文被SIGCOMM收录相提并论。
目前从公开渠道尚未获得论文的原文,不过HPN7.0设计的一些关键思想和核心内容其实在去年就已经通过各种渠道有所透露,为了帮助大家迅速把握HPN 7.0的精髓,笔者将通过公开途径搜集到的信息进行整理汇总(详细说明见参考资料),以飨读者。
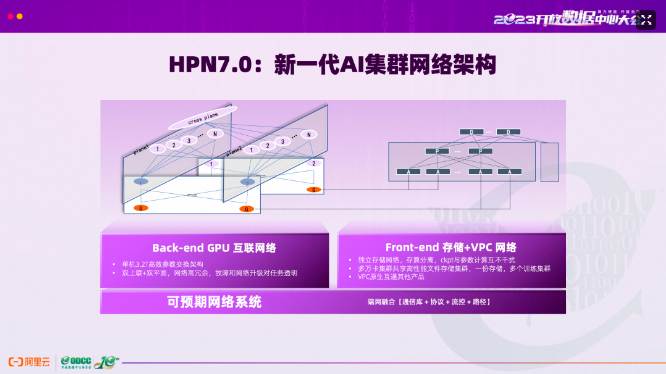
公开新闻稿中描述论文中网络架构的“双上联+多轨+双平面”创新设计,并介绍了自研的Solar-RDMA和ACCL通信库,借助这些通信库可实现网络的高性能和高稳定互联。
阿里巴巴HPN(High-Performance Networking)是专为AI基础设施设计的先进网络架构。HPN 7.0 架构基于顶尖的 51.2Tbps 交换机和 400Gbps 高性能网络接口卡 (NIC) 构建。该架构在精心设计时,对数据中心电源限制和物理布局等基本考虑因素有着敏锐的认识。它拥有可扩展的能力,通过成熟的两层 CLOS 设计,在单个集群中支持超过 100,000 个 GPU 节点。此外,它还集成了弹性双平面网络架构,以确保高可用性。 具备下面几个最基本的特性:轨道优化网络拓扑、RDMA 高性能网络协议的增强、高级流量控制和多路径传输机制。文中还描述了通信库级别的优化,最终形成一种整体、集成的方法,用于在整个堆栈中快速检测故障和细致的性能诊断。
接下来本文会针对两双一多创新设计,Solar-RDMA和ACCL通信库进行简单介绍。
两双一多
HPN 7.0创新性地采用了“双上联+多轨+双平面”的网络架构,通过双上联设计,提高了网络的可靠性和性能;多轨技术则允许多个数据流并行传输,增加了网络吞吐量;而双平面架构进一步增强了网络的稳定性和容错能力。
双上联

双上联指的是服务器上的所有网络接口卡(NIC)均配置有两组端口,每组端口分别连接至不同的交换机,以形成一个聚合链路(bond port)来提供服务。这种设置确保了在任一上联链路或接入层交换机发生故障时,网络流量能够自动切换至另一端口,从而保障了训练任务的连续性和稳定性。 采用双上联的架构设计有效规避了单一上联链路接入交换机可能引发的单点故障风险,显著增强了整个系统的网络连接可靠性。此外,这种设计还为集群系统的交换机提供了热升级的可能性,简化了网络的运维工作,并为功能的迭代升级提供了便利。
双平面
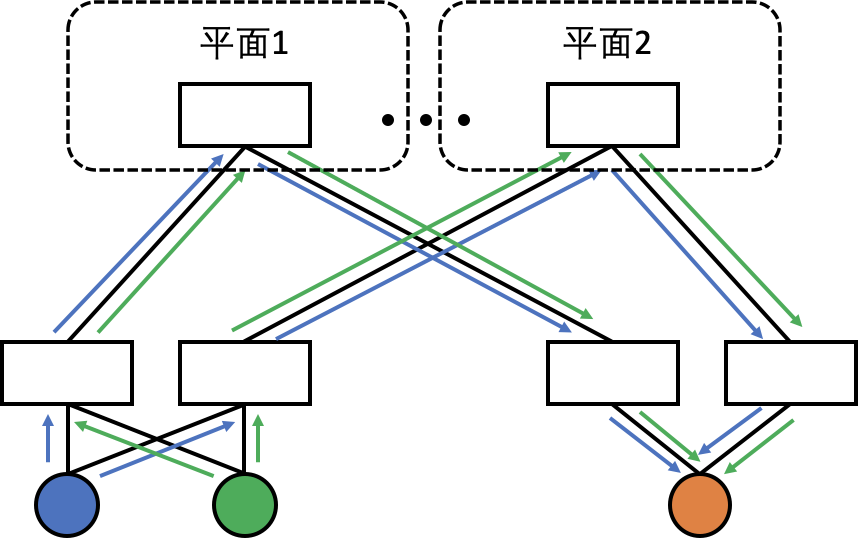
HPN在接入层与汇聚层交换机的设计中,提出了双平面转发机制。具体来说,每个网络接口卡(NIC)的两个上联端口被分别映射到两个独立的网络平面。这种设计意味着,只要发送端在聚合端口(bond port)发送流量时,确保流量均匀分配至两个发送端口,接收端的接入层交换机便能接收到均衡的网络流量。这一机制显著降低了哈希极化现象的发生机率,从而优化了网络流量的分配效率和网络的整体性能。
多轨
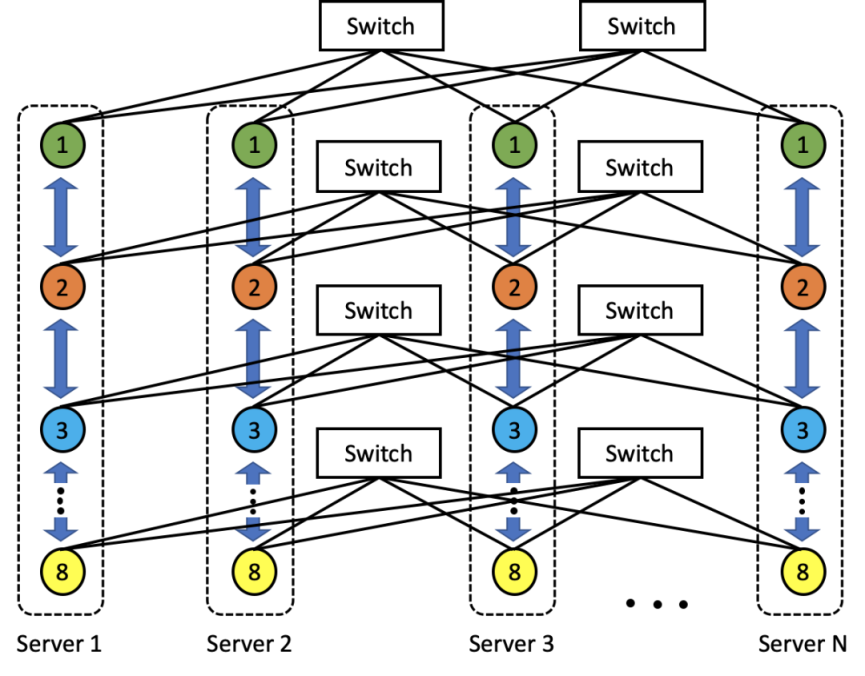
多轨通信技术的核心在于整合单个服务器节点内部的NVLink以及节点间高性能网络等互联资源,以在集群层面逼近网络通信性能的理论极限。在HPN架构中,每个GPU都与两张400Gbps的网卡相连,而一个服务器节点配备有8张GPU,因此整个节点拥有高达6.4Tbps的网络转发能力。这16张网卡的端口分别连接至不同的接入交换机,使得多个服务器节点能够通过单次网络转发实现直接连接。 此外,结合节点内的NVLink技术以及自主研发的通信库进行性能优化,该架构能够实现多个服务器组成的POD节点内所有GPU卡之间的全互联。这种设计极大地减少了资源竞争的可能性,并显著优化了长尾时延,从而为大规模集群计算提供了更加高效和稳定的网络通信支持。
Solar-RDMA协议
在商用生态系统中,基于RoCE(RDMA over Converged Ethernet)的解决方案尽管具有其优势,但也面临着一些挑战性的技术问题:
- 传统的RDMA技术通常采用单一路径传输,这限制了其在面对网络故障时的鲁棒性。
- 现有的拥塞控制算法精度不足,难以实现对网络传输速率的精细控制。
- 在多租户环境下,支持能力较弱,缺乏能够实现端到端全链路带宽资源隔离的解决方案。
为了克服这些难题,阿里在SIGCOMM2022上的论文中《From Luna to Solar: The Evolutions of the Compute-to-Storage Networks in Alibaba Cloud》提到了Solar-RDMA,它带来了以下创新:
- 实现了每个连接的多路径传输能力,在任一路径发生故障时能够迅速切换至备用路径,从而减少对业务的影响。
- 开发了HPCC(High Precision Congestion Control)高精度拥塞控制算法,结合网络负载的动态感知,能够实现对数据流级别的精细控制。
- 提供了端到端的全链路服务质量(QoS)保障,能够为不同租户的任务分配定制化的网络资源。
ACCL集合通信库
ACCL(Alibaba Collective Communication Library)是一款高性能通信库,提供了AllReduce、 AllToAllV、Broadcast等常用集合操作接口以及点到点Send/Recv接口,为多机多卡训练提供高效的通信支持。ACCL面向阿里云灵骏架构设计,通过算法与拓扑的深入协同来收获更好的通信性能,充分挖掘高性能RoCE网络的带宽效率、最大化分布式训练系统的可扩展性。
ACCL提供了简单易用的C++ API,语义与MPI等主流集合操作接口相近。还提供了对PyTorch、Horovod 等深度学习框架以及数据并行、模型并行等主流并行训练模式的支持,便于深度学习用户快速使用。
ACCL的关键特性包括:
- 异构拓扑感知,例如节点内PCIE与NVLink/NVSwitch、节点间多轨RDMA网络,分层混合算法设计,充分利用不同互连的带宽。
- 端网协同选路,算法与拓扑协同设计实现无拥塞通信,支撑训练性能上规模可扩展。
- 端侧RoCE LAG感知、在网多流负载均衡,多任务并发、资源争抢时保障整体吞吐。
详细的内容可以参考论文《ACCL: Architecting Highly Scalable Distributed Training Systems With Highly Efficient Collective Communication Library》。

参考资料:
1 《AI Infra网络设计及思考》 2023年开放数据中心大会
2 《灵骏可预期网络:Built for AI Infrastructure 》
3 《详解灵骏智能算力之可预期高性能网络》
4 《From Luna to Solar: The Evolutions of the Compute-to-Storage Networks in Alibaba Cloud》
5 《ACCL: Architecting Highly Scalable Distributed Training Systems With Highly Efficient Collective Communication Library》







