

本文由张景涛翻译解读
1背景介绍
威斯康星大学麦迪逊分校和浙江大学在今年4月份的NSDI 2024联合发表了《Understanding Routable PCIe Performance for Composable Infrastructures》一文,文中详细介绍了rPCIeBench,这是一个软硬件共同设计的基准测试框架,旨在量化可路由PCIe的性能。可路由PCIe作为构建新兴可组合基础设施的主要互连技术,如果能够系统地分析和理解在可路由PCIe结构上进行数据移动和通信的性能特点,对于后续构建基于PCIE或者CXL的可组合基础设施具有很重要的参考意义。(文末附下载)
本文首先分析了单个可路由PCIe路径的通信特性,并与本地PCIe链路进行了比较。接着利用rPCIeBench剖析了在可路由PCIe结构内部的流量编排行为,并得出了几个关键的发现。基于这些见解,研究者开发了一个边缘约束放宽算法,用于准确预测在共享的可路由PCIe结构上每个PCIe流的通信性能。最后,通过不同的实验设置验证了算法的准确性,并展示了其在设计高效流调度器方面的潜力。
2引言
最近,可组合基础设施——将计算、内存和存储组织为弹性资源池——越来越受到关注。通过新兴的集群互连技术,在这样的平台上运行的应用程序可以本地访问分散的硬件资源,根据工作负载需求进行自适应扩展,并与同位置的租户实现细粒度共享,从而实现独立的扩展能力、高设备利用率和成本效率的提高。
已经看到了许多早期的工程样本和商业原型,如GigaIO的FabreX、Liqid的SmartStack、H3的Falcon、Groq的GroqRack和Enfabria的ACF。PCIe(外围组件互连快速)是高性能主机内通信的事实标准互连。通过引入一种特殊的非透明桥接(NTB)设备,可以扩展PCIe总线树,并促进来自不同交换域的PCIe设备之间的通信,从而实现主机间PCIe事务或可路由PCIe。
这些技术为当今许多可组合基础设施奠定了基础。更重要的是,可路由PCIe还作为新兴内存结构(如CXL)的基础。然而业界对可路由PCIe的能力和限制的系统理解,因此迫切需要对可路由PCIe结构进行量化来准确的回答这些问题。
3 rPCIeBench框架
rPCIeBench由三个组件组成(图1-b),分布在主机服务器和远程设备上。第一个是编程API,允许开发人员实现和部署任意测试场景。用户指定基准测试服务器和目标设备,初始化系统环境,并配置数据移动模式和属性。第二部分是主机运行时和驱动程序,负责制造和提交PCIe请求,与底层PCIe子系统和主机适配器交互,处理事务完成,并进行性能分析。最后一块是FPGA加速器中的位流。位流设置FPGA执行环境,接收数据传输请求,通过可路由PCIe结构上的DMA引擎实例化一系列数据传输,读取写入内存目标,并发出返回信号。
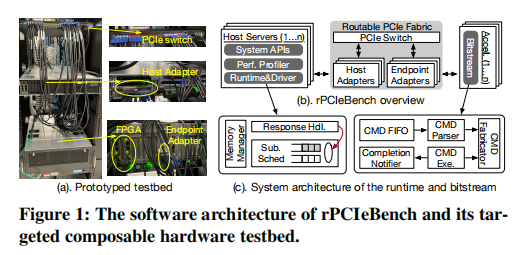
3.1 系统API
rPCIeBench提供了三种类型的API。第一种用于初始化远程FPGA的执行环境,配置设备内存,并设置主机-设备地址映射。第二类允许设备端内存管理,以便可以为数据传输指定内存位置的源和目的地。最后一类提供通用通信原语,通过MMIO(内存映射IO)或DMA引擎实现主机-设备和设备-设备数据移动。
3.2软件组件
rPCIeBench使用三个软件子系统(图1-b)对可路由PCIe结构进行基准测试和特性化。
- 性能分析器:跟踪一个PCIe事务的整个生命周期,从基准测试应用程序提交请求直到接收完成信号。实用程序在纳秒精度上标记了事务排队时间(第1阶段)、数据在结构上传输的时间(第2阶段)以及远程加速器上的命令执行(第3阶段)。使用轮询来提高系统分析的准确性。
3.3命令数据路径

rPCIeBench支持三种类型的通信原语(表1)。第一类是主机处理器发出的MMIO读写,它只生成一个PCIe读写事务来访问设备内存。第二类是主机-设备数据移动。
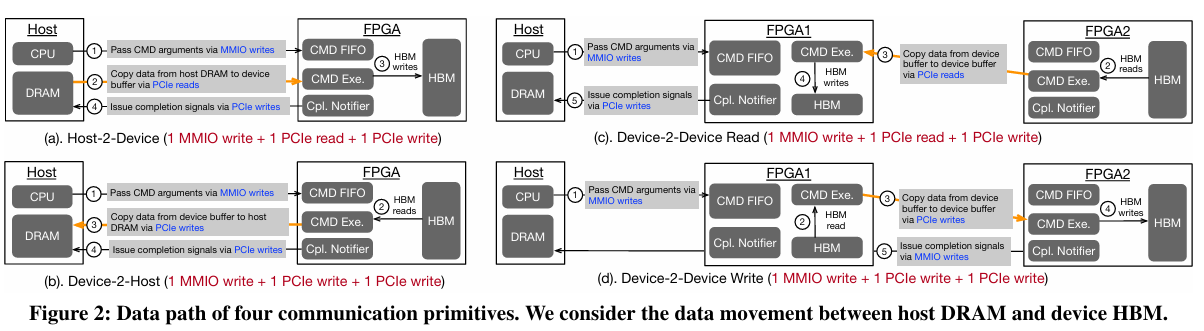
如图2-ab所示,它包括四个步骤:(a) 通过MMIO写传递命令参数,(b) 在主机和设备之间移动数据,(c) 读写HBM,以及 (d) 通过另一个PCIe写入发出完成信号,总共产生1个MMIO写入和2个PCIe传输(这将根据命令大小转换为多个PCIe事务)。最后一种是设备-设备通信(图2-cd),其操作类似于主机-设备情况。
4 可路由PCIe的基本性能
本节检查可路由PCIe的性能特性,并将其与本地PCIe情况进行比较。
4.1 实验方法
硬件测试平台。主机服务器是2U Dell R740机箱,内含两颗20核Intel Xeon Gold 6248处理器(运行在2.5GHz),192GB DRAM,以及1.92TB HDD。禁用了超线程和Turbo Boost功能。服务器的所有PCIe通道都是Gen3。使用Xilinx Alveo U55C卡(×16)作为主要的连接到结构的设备。如上所述,选择GigaIO的Farbex作为可路由PCIe基础的可组合测试平台。它的RS4024交换机有24个端口,每个端口连接到一个PCIe Gen3×4链路。
实验配置。本节重点关注单个通信路径。在可组合测试平台中,有三种类型的通信路径:主机到设备(H2D)、设备到主机(D2H)和设备到设备(D2D)。为每种路径设置环境,并使用rPCIeBench的通信原语进行流量生成。通过改变突出的PCIe流的数量、每个流的每个数据包大小和其突发性来改变流量配置文件。rPCIeBench报告平均尾部延迟和吞吐量作为主要性能指标。
4.2 延迟
单向PCIe。首先使用rPCIeBench的跟踪功能,剖析两个实体之间的单向PCIe延迟。在服务器内部通信时,实验发现本地PCIe单向延迟为379.0纳秒,这与最近文献中报告的数字相匹配。然而,当跨越可路由PCIe结构时,单向PCIe延迟上升至868.6纳秒,增加了489.6纳秒(129.2%)的开销!这对于小尺寸的PCIe传输来说并非微不足道。进一步与设备供应商合作,进行了延迟分解。发现(1)主机适配器、交换机和目标适配器分别由于NTB交换各自消耗大约105纳秒;(2)铜线的实际延迟约为5纳秒;(3)RS4024有10纳秒的处理延迟;(4)主机端软件耗时约150纳秒。
DMA引发的PCIe。当通过DMA触发PCIe传输时,还应该包括DMA引擎执行成本,包括准备命令、将其提交到命令队列以及捕获完成信号。检查了加速器内的硬件模块,发现这个开销大约是418.0纳秒,无论是本地还是远程情况。例如,通过DMA引擎发出的64B PCIe写入将分别在本地和远程情况下花费946.0纳秒和1421.4纳秒才能完成。
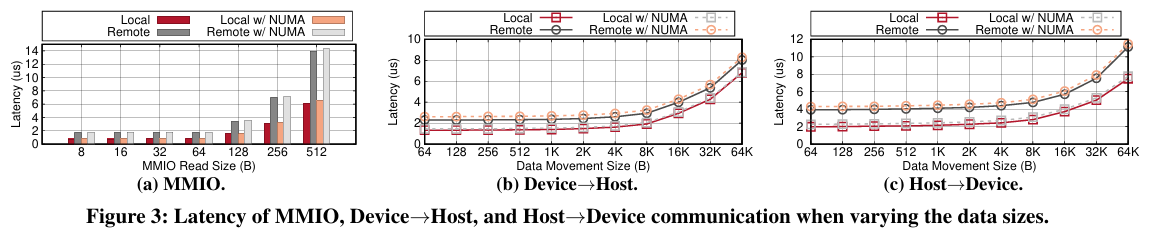
MMIO & H2D & D2H。MMIO读取的延迟取决于生成的缓存行数。如图3-a所示,本地64B PCIe读取需要766.0纳秒,而远程情况需要1751.0纳秒,因为需要一个PCIe往返行程(两个单向)。当跨越CPU Socket时,观察到本地和远程情况分别增加了67.0纳秒和52.0纳秒,分别为833.0纳秒和1803.0纳秒。
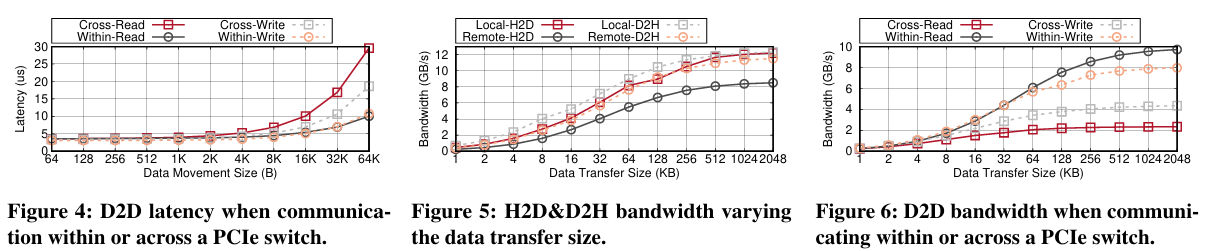
D2D。专注于两种类型的设备-设备通信:一种是跨外部PCIe交换机;另一种是在PCIe子树内,不跨交换机。显然,穿越交换机并非没有代价。当数据传输大小小于1KB时,如图4所示,跨交换机为读取和写入场景分别增加了2.2%和11.0%的额外延迟。当数据移动大小超过1KB时,发现开销显著增加。
要点。通过可路由PCIe结构(通过交换机和适配器)进行通信并不像本地情况那样性能优越。单向PCIe传输需要868.6纳秒(与本地情况的379.0纳秒相比)。当使用DMA引擎进行数据移动时,还应考虑引擎执行成本(在我们的情况下是418.0纳秒)。大于4KB的大数据传输可以摊销可路由PCIe引起的延迟开销,这表明批量处理的有效性。然而,对于D2D通信,穿越外部PCIe交换机成本很高,尤其是对于4+KB的数据大小。这表明在构建D2D通信子系统时,应考虑它们在结构上的位置以及数据传输粒度。
4.3 带宽
外部PCIe交换机的转发速率比服务器内部PCIe交换机慢,导致H2D和D2H场景分别出现30.4%和6.9%的带宽降级。设备到设备通信不仅穿过外部PCIe交换机,而且可能会引起根复合体争用(当设备位于本地-远程混合场景时),从而危及最大达到的带宽。
4.4 延迟与吞吐量的比较
检查了每个数据移动方向的延迟-吞吐量关系。逐渐增加更多的背景流量并测量64B PCIe请求的平均延迟。

如图7和图8所示,当接近最大带宽时,延迟开始上升,因为信用饥饿导致请求暂停。然而,发现可路由PCIe结构需要更多时间来补充信用。由于(可路由)PCIe结构采用逐跳基于信用的流控制,路径上的中间实体越多,就会观察到更多的信用交互。当带宽(接近)过载时,更长的通信路径需要更多的信用协调来传递事务。
4.5 带宽划分
探索了如何在同一通信路径上并发的PCIe流之间划分带宽。实验配置如下:对于每个数据移动方向,合并了两个PCIe流,这些流持续发出一个outstanding的PCIe请求:Flow1发送一个4KB请求;Flow2将其事务大小从64B增加到32KB。我们发现,当并发PCIe流共享相同的通信路径时,这些流之间的带宽划分大致与它们outstanding字节的比例成比例。

要点。在两个端点之间,同一通信路径上并发PCIe流之间的带宽划分主要取决于它们outstanding字节的比例。事实上的事务层不强制执行公平的带宽执行。可路由PCIe结构扩展了本地PCIe网络的基本方案。
4.6 不对称通信路径
PCIe是一个全双工双向网络。本节探讨了相反方向的流是否互相干扰。我们在同一个物理通信路径上放置了一个对延迟敏感的流(Flow2)从A到B和一个以吞吐量为导向的流(Flow1)在相反方向B→A,然后分析延迟如何随着吞吐量的变化而变化。
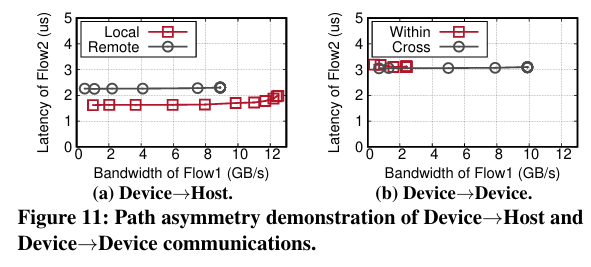
要点。类似于本地PCIe网络,可路由PCIe在任何数据传输方向上的一个物理路径上的并发反向PCIe流之间不会产生通信干扰,无论是主机到设备、设备到主机,还是设备到设备。
5 在结构内部的流量编排
上一节集中讨论了单一通信路径的不同方面。本节分析了多个路径在可路由PCIe结构上如何相互作用,特别是在主机适配器、外部PCIe交换机和端点适配器上。
5.1最大最小公平带宽分配
在结构内部,来自不同通信路径的PCIe流争夺任何中间传输点的带宽资源。
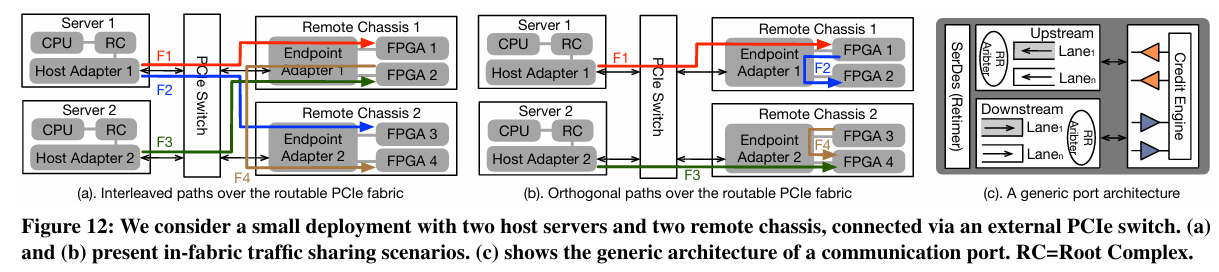
如图12-a所示,配置了三种路径交错场景,分别共享主机适配器(F1与F2)、交换机(F1与F3)和端点适配器(F2与F4)。在每个实验中,固定了一个流的数据包大小,逐渐增加另一个流的数据包大小,并探索带宽如何被划分。结果显示,每个通信实体(例如,一个适配器或一个交换机)实现了一个近似的最大最小带宽分配方案。具体来说,当N个来自不同路径链路的流共享一个上下游端口,并且有以下需求BWF1,BWF2,...,BWFn,如果聚合带宽小于链路容量,每个流都可以实现其期望的速率;如果带宽过载,每个流Fi将获得其最大最小份额。
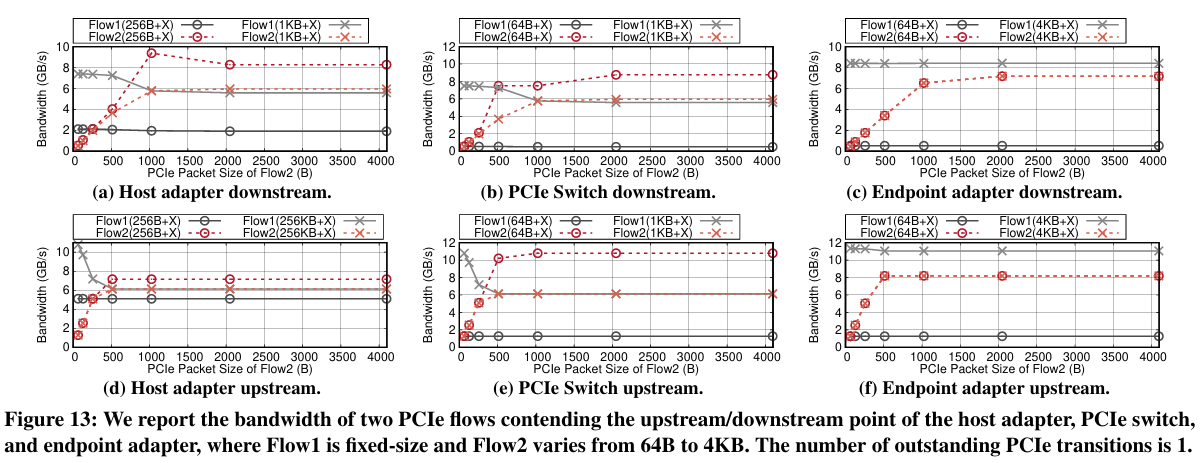
要点。在可路由PCIe结构中,任何通信端口(在交换机或适配器内)实现了不同活动链路上的逐信用循环调度,从而实现了最大最小带宽划分。这不仅有助于在链路拥塞下简化性能推理,还帮助推导出一个可预测的流调度器。
5.2 快速端到端带宽同步
在共享网络结构中,链接可用带宽随着应用行为和底层拓扑变化而大幅波动。这种变化可能导致链路拥塞(例如,网络内队列堆积和传输延迟增加)或带宽未充分利用。在以太网结构中,终端主机的拥塞控制机制将根据规定的拥塞信号相应地调整流量发送速率。由于可路由PCIe没有这样的层,本节我们想探索PCIe流带宽是如何根据流量条件进行调整的。配置了三种实验场景,每个场景都有两个PCIe流共享来自不同路径的中间通信点。第一个流是固定的,消耗超过一半的链路带宽容量。然后逐渐增加第二个流的带宽利用率,并测量Flow1的每个PCIe事务的P50、P90和P99延迟。我们发现可路由PCIe结构的排队效应很小,带宽需求可以快速从瓶颈点向上游实体沿着路径反向传播。
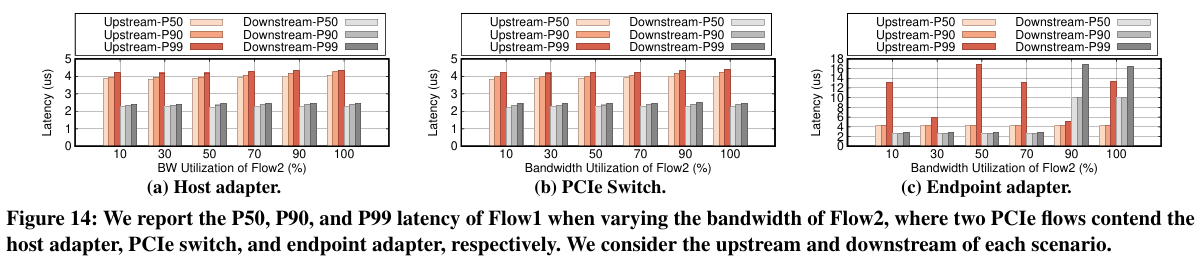
要点。可路由PCIe结构提供了两个端点之间的超低延迟通信,并在两个适配器和交换机中保留了很少的缓冲。带宽可用性将通过信用进行快速反向传播,从拥塞点到上游实体,直到源节点。当协调并发流时,可以使用它作为拥塞信号。
6可路由PCIe结构的性能模型:优化指南
开发一个算法来预测PCIe流传输性能,并在实际设置中验证其准确性。
6.1 边缘约束放宽算法

文中提出了一种新算法(称为边缘约束放宽)来解决问题。关键思想是应用迭代减少,根据过载链路的容量逐步限制流带宽。
6.2 验证和讨论
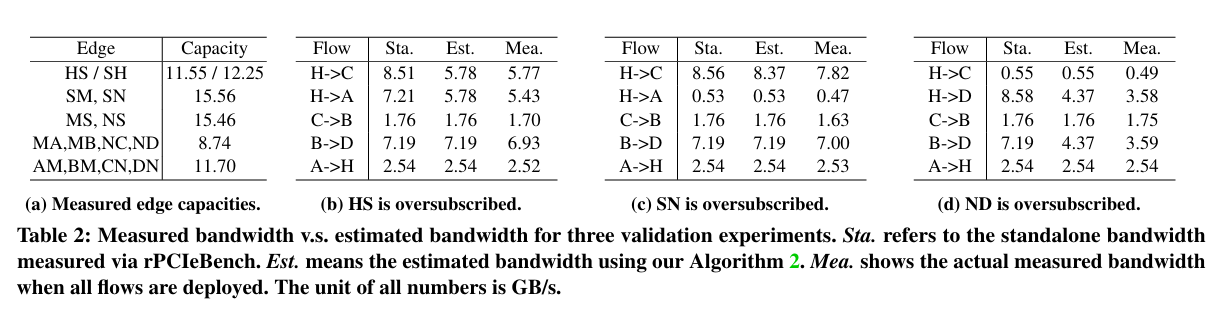
文中设计了三个实验来验证提出的算法的准确性。每个实验针对不同的过载链路。使用rPCIeBench来确定每个流的独立带宽和链路容量(表2-a)。表2-bcd展示了每个实验场景的比较(即,测量与估计)。实验证明算法能够预测正确的趋势,但由于链路容量的减少,估计误差率增加到11.32%。
7结论
本文介绍了rPCIeBench,这是一个软硬件共同设计的基准测试框架,用于特性化可路由PCIe的性能,这是构建新兴可组合基础设施的基础集群互连。使用rPCIeBench首先检查了一个可路由PCIe路径的性能,然后剖析了在结构内部的流量编排行为。基于收集到的见解还开发了一个边缘约束放宽算法,以准确预测在共享的可路由PCIe结构上每个PCIe流的通信性能。
SDNLAB公众号后台回复0514PCIe,即可获取下载链接






