

作者简介:Explorer,专注于高性能网络、虚拟化网络及网卡的测试方案研究。熟悉dpdk,rdma,sdn等技术的应用与解决方案。
1、RoCEv2为什么需要无损网络
RoCEv2是基于以太网的RDMA实现,它使用了以太网的网络基础设施来传输RDMA数据。然而,RDMA对网络的要求比传统的TCP/IP通信更严格。RDMA通信中,数据传输是直接从发送端的内存到接收端的内存,而不需要中间的操作系统或CPU参与。这种特性使得RDMA对网络延迟和可靠性的要求更高,尤其是对网络包的丢失和延迟敏感。
无损网络是指能够提供高带宽、低延迟、低丢包率的网络。在RDMA的情境下,无损网络可以确保数据包能够按时到达,并且不会因为网络拥塞或错误而丢失,从而保证了RDMA通信的可靠性和低延迟。这是因为RDMA在传输过程中依赖于数据包按序到达,一旦出现丢失或者重传,会影响整个数据传输的完整性和效率。
在实际应用中,使用RDMA通常是为了实现高性能的数据传输,比如在数据中心内部或者高性能计算等场景下。这些应用通常需要高带宽和低延迟,并且对数据传输的可靠性有严格要求。举例来说,大规模数据分析、人工智能模型训练、高性能存储系统等都是需要使用RDMA来实现高性能数据传输的场景。
在这些场景下,无损网络的存在可以保证数据传输的可靠性和低延迟。假设在高性能计算集群中,如果网络出现拥塞或丢包,会导致RDMA通信中的数据丢失或延迟增加,从而降低整个系统的性能和效率。因此,通过使用无损网络,可以避免这些问题,确保RDMA通信能够以高性能和可靠性进行。
2、拥塞控制算法
2.1 PFC
简介
传统的以太网PAUSE帧技术,当网络中的下游设备发现其流量接收能力小于上游设备的发送能力时,会主动发PAUSE帧给上游设备,要求上游设备暂停流量发送,等待一段时间后再继续发送。此种技术引来的弊端,流量暂停是针对整个端口,而实际的线网业务中,各类业务流量会共享端口链路,此时该端口下所有的业务流量都将会受到影响。
为了解决上述问题,IEEE 802.1Qbb 定义了PFC(Priority-based Flow Control,基于优先级的流量控制),PFC可以有效的防止交换机和网卡的缓冲区溢出,交换机和网卡监测入方向队列,当队列超过一定阈值时,将会向数据上游设备发送PAUSE消息。上游设备收到PAUSE消息后将会停止发送该队列数据,直到接收到RESUME消息。PFC支持8个优先级队列,PAUSE和RESUME消息都是基于单个队列,使能了PFC功能的队列称之为无损队列。由此可见PFC解决了传统以太网PAUSE帧技术的弊端,可以将共享端口链路下不同队列的数据单独使能PFC功能,从而不影响其他队列。
工作模式
PFC的工作模式,如Figure 1,当某个队列缓存发生拥塞时,就会向上游设备发送反压信号,上游发送方收到信号后就会停止发送该队列流量,直到收到接收端发送的解除流量抑制的信号或者超时。支持基于PCP或者DSCP的PFC功能,在本文实验章节中会有详细描述。

PFC帧格式
PFC帧的基本格式如Figure 2,其中关于opcode格式内容请参考Figure 3。
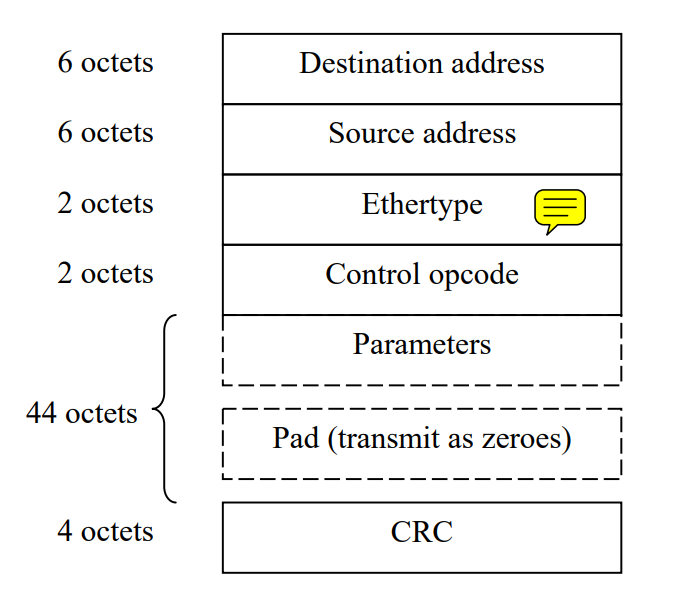
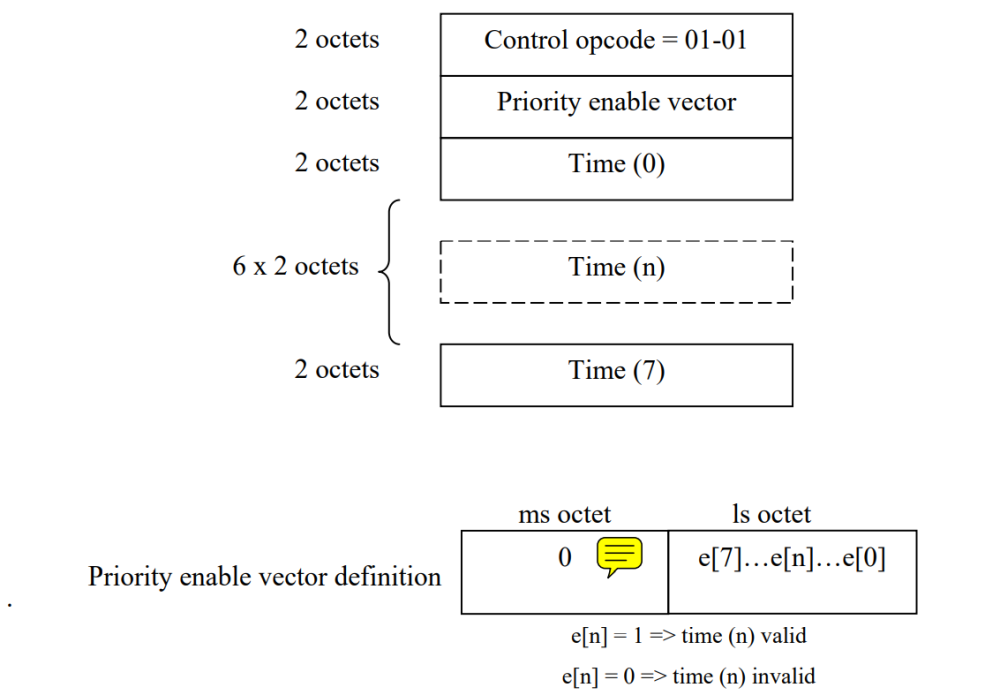
PFC帧含义解释:

PFC的限制
由于PFC的工作模式是基于队列而并非是flow级别的,因此会存在队头堵塞(head-of-line)的问题。
不公平调度( Unfairness ):
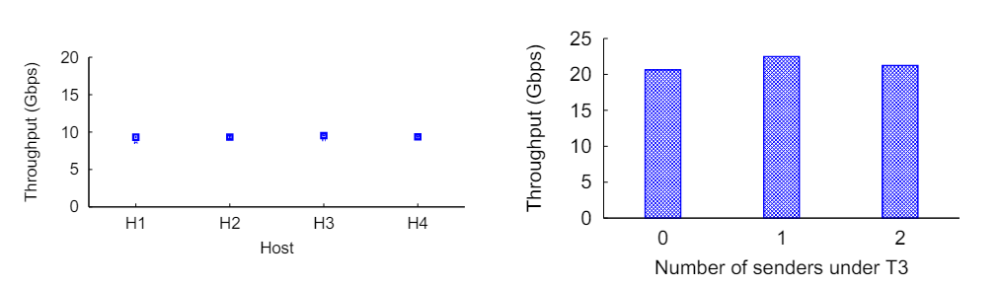
如Figure 5所示,H1-H4四个发送方,通过rdma write消息发送到同一个接收端R,理想情况下,四个发送方应该平等共享T4到R的链路,但实际上在PFC场景下并不是如此。当PFC触发后pause后,它将暂停P2-P4三个入方向的数据流,其中P2方向的数据都是来自于H4,而H1-H3需要共享P3和P4两个入端口,当P1的出方向恢复发送后,H4的数据流可以独享P2的端口,而H1-H3需要在P3和P4的入端口进行竞争,因此H4的带宽始终会高于H1-H3,从而引起了不公平调度。

如图Figure 6,由于不公平调度的存在,H4的带宽比H1-H3都要高。

受害者流 (Victim flow):
如Figure 7所示,H11-H14为4个发送端,另外有一条受害者流VS-VR,T4为H11-H14的链路瓶颈,当T4触发反压后,会暂停L3和L4的入方向数据流,依次向上暂停了L1和L2的入方向数据流,最终T1也被迫停止了入方向流量的发送,这时候VS-VR的流量就完全被影响到了。如果加上发送H31和H32两条数据流,VS-VR的影响会更大,这是因为H31和H32在L3和L4上面与H11-H14会竞争带宽。

图Figure 8,T3下面的发送者越多,被害者流VS-VR的影响越大。

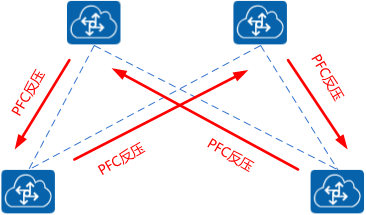
PFC死锁
PFC死锁(PFC DeadLock),是指当多个交换机之间因为环路等原因同时出现拥塞,各自端口缓存消耗超过阈值,而又相互等待对方释放资源,从而导致所有交换机上的数据流都永久阻塞的一种网络状态。
正常情况下,PFC中流量暂停只针对某一个或几个优先级队列,不针对整个接口进行中断,每个队列都能单独进行暂停或重启,而不影响其他队列上的流量,真正实现多种流量共享链路。然而当发生链路故障或设备故障时,在路由重新收敛期间,网络中可能会出现短暂环路,会导致出现一个循环依赖缓冲区(Cyclic Buffer Dependency)。如Figure 9所示,当4台交换机都达到PFC门限,都将同时向对端发送PFC反压帧,这个时候该拓扑中所有交换机都处于停流状态。
2.2 DCQCN
简介
DCQCN是一种基于速率的端到端拥塞控制协议,它建立在QCN和DCTCP之上。大部分的DCQCN功能在网卡中实现。
DCQCN解决了三个核心需求:能够在无损、L3路由、数据中心网络上运行;低CPU开销;在无拥塞的情况下超快启动。
DCQCN算法由三部分组成:
1、RP(Reaction Piont),发送方网卡,响应点。
2、CP(Congestion Point),交换机,拥塞点。
3、NP(Notification Point),接收方网卡, 通知点。
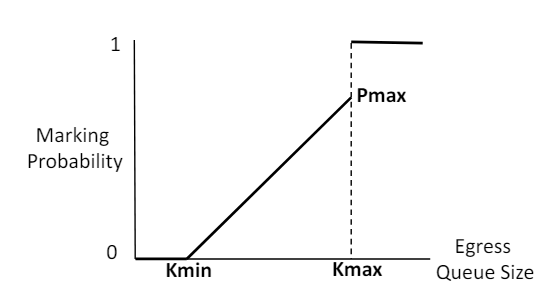
CP算法
CP算法与DCTCP相同,如果交换机的出端口队列长度超过了阈值,那就会对进入交换机的数据标记ECN。交换机使用RED(Random Early Detection)功能来完成该操作,几乎所有的交换机都支持该功能。交换机根据当前队列长度来计算标记ECN的概率,队列长度越接近于阈值上限,则越容易被标记。
NP算法
ecn标记的报文到达接收端网卡表示网络发生了拥塞。接收端网卡通过CNP消息发送回发送端网卡。NP算法则指定了CNP应该如何以及何时生成。
根据不同的流,生成CNP消息,可以设置为50us内只发送一次CNP消息。

RP算法
RP算法分为Alpha Update,Rate Decrease和Rate Increase。
当一个RP收到一个CNP时,会降低它的当前速率(RC),并像DCTCP一样更新速率降低因子α的值,并将当前速率记为目标速率(RT),以便以后恢复,更新的方式如Figure 12,Alpha得初始值为1

如果NP没有收到标记ECN的数据包,则不会发送CNP。因此,如果RP在K个时间单位内没有得到CNP,则更新α,注意,K必须大于CNP生成定时器,比如上面描述的50us。那这里K我们就可以设置为55us。更新的公式如下。

RP使用和QCN相同的提升速率方式,使用time定时器和byte计数器来提高其发送速率,byte计数器每增加B个字节开始提升速率,而time定时器则每T个时间单位提升速率,这两个参数可以调节达。
整个过程的状态机如Figure 14所示:

相同的测试实验结果,dcqcn可以有效的避免PFC引起的不公平调度和受害者流。
3、测试实验
3.1 测试拓扑
本测试实验环境使用Mellanox CX-4网卡,使用多打一的组网方式进行拥塞模拟,拓扑如Figure 16所示,ServerA、ServerB和ServerC分别搭载一张Mellanox CX-4网卡。

3.2 PFC测试实验
ServerA和ServerB发送不同优先级的数据包到Switch,当Switch上队列缓存发生拥塞时就会向上游设备发送反压信号。
Server A配置
设置ServerA上网卡启用队列优先级3的PFC功能,并且信任dscp,这里可以查看dscp-prio的mapping,dscp 24-31对应优先级3。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
root@ServerA:~# mlnx_qos -i enp3s0f0np0 -f 0,0,0,1,0,0,0,0 --trust dscp DCBX mode: OS controlled Priority trust state: dscp dscp2prio mapping: prio:0 dscp:07,06,05,04,03,02,01,00, prio:1 dscp:15,14,13,12,11,10,09,08, prio:2 dscp:23,22,21,20,19,18,17,16, prio:3 dscp:31,30,29,28,27,26,25,24, prio:4 dscp:39,38,37,36,35,34,33,32, prio:5 dscp:47,46,45,44,43,42,41,40, prio:6 dscp:55,54,53,52,51,50,49,48, prio:7 dscp:63,62,61,60,59,58,57,56, default priority: Receive buffer size (bytes): 130944,130944,0,0,0,0,0,0, Cable len: 7 PFC configuration: priority 0 1 2 3 4 5 6 7 enabled 0 0 0 1 0 0 0 0 buffer 0 0 0 1 0 0 0 0 tc: 1 ratelimit: unlimited, tsa: vendor priority: 0 tc: 0 ratelimit: unlimited, tsa: vendor priority: 1 tc: 2 ratelimit: unlimited, tsa: vendor priority: 2 tc: 3 ratelimit: unlimited, tsa: vendor priority: 3 tc: 4 ratelimit: unlimited, tsa: vendor priority: 4 tc: 5 ratelimit: unlimited, tsa: vendor priority: 5 tc: 6 ratelimit: unlimited, tsa: vendor priority: 6 tc: 7 ratelimit: unlimited, tsa: vendor priority: 7 |
设置ServerB上网卡启用队列优先级5的PFC功能,并且信任dscp,这里可以查看dscp-prio的mapping,dscp 40-47对应优先级5。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
root@ServerB:~# mlnx_qos -i ens6f0np0 -f 0,0,0,0,0,1,0,0 --trust dscp DCBX mode: OS controlled Priority trust state: dscp dscp2prio mapping: prio:0 dscp:07,06,05,04,03,02,01,00, prio:1 dscp:15,14,13,12,11,10,09,08, prio:2 dscp:23,22,21,20,19,18,17,16, prio:3 dscp:31,30,29,28,27,26,25,24, prio:4 dscp:39,38,37,36,35,34,33,32, prio:5 dscp:47,46,45,44,43,42,41,40, prio:6 dscp:55,54,53,52,51,50,49,48, prio:7 dscp:63,62,61,60,59,58,57,56, default priority: Receive buffer size (bytes): 130944,130944,0,0,0,0,0,0, Cable len: 7 PFC configuration: priority 0 1 2 3 4 5 6 7 enabled 0 0 0 0 0 1 0 0 buffer 0 0 0 0 0 1 0 0 tc: 1 ratelimit: unlimited, tsa: vendor priority: 0 tc: 0 ratelimit: unlimited, tsa: vendor priority: 1 tc: 2 ratelimit: unlimited, tsa: vendor priority: 2 tc: 3 ratelimit: unlimited, tsa: vendor priority: 3 tc: 4 ratelimit: unlimited, tsa: vendor priority: 4 tc: 5 ratelimit: unlimited, tsa: vendor priority: 5 tc: 6 ratelimit: unlimited, tsa: vendor priority: 6 tc: 7 ratelimit: unlimited, tsa: vendor priority: 7 |
交换机启用PFC功能,分别在连接ServerA和ServerB设备的接口上配置PFC使能,并且配置使能pfc的优先级队列,这里配置了0-7全使能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
[H3C-Twenty-FiveGigE1/0/14]dis th # interface Twenty-FiveGigE1/0/14 port link-mode bridge priority-flow-control enable priority-flow-control no-drop dot1p 0-7 qos trust dscp # return [H3C-Twenty-FiveGigE1/0/15]dis th # interface Twenty-FiveGigE1/0/15 port link-mode bridge priority-flow-control enable priority-flow-control no-drop dot1p 0-7 qos trust dscp # return ServerC启动2个iperf3服务端 root@ServerC:~# iperf3 -s -p 1000 ----------------------------------------------------------- Server listening on 1000 ----------------------------------------------------------- root@ServerC:~# iperf3 -s -p 2000 ----------------------------------------------------------- Server listening on 2000 ----------------------------------------------------------- |
ServerA和ServerB分别发送udp报文,模拟拥塞场景。
ServerA发送,-S指定tos字段,指定为0x60,根据交换机的dscp-dot1p的映射表,就可以进入到优先级为3的队列中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
root@ServerA:~# iperf3 -c 192.168.10.12 -p 1000 -t 100 -i 2 -S 0x60 -u -b 10g -l 65500 warning: UDP block size 65500 exceeds TCP MSS 1448, may result in fragmentation / drops Connecting to host 192.168.10.12, port 1000 [ 5] local 192.168.10.10 port 43661 connected to 192.168.10.12 port 1000 [ ID] Interval Transfer Bitrate Total Datagrams [ 5] 0.00-2.00 sec 1.75 GBytes 7.52 Gbits/sec 28686 [ 5] 2.00-4.00 sec 1.80 GBytes 7.75 Gbits/sec 29570 [ 5] 4.00-6.00 sec 1.82 GBytes 7.80 Gbits/sec 29783 [ 5] 6.00-8.00 sec 1.81 GBytes 7.78 Gbits/sec 29713 [ 5] 8.00-10.00 sec 1.35 GBytes 5.78 Gbits/sec 22053 [ 5] 10.00-12.00 sec 1023 MBytes 4.29 Gbits/sec 16375 [ 5] 12.00-14.00 sec 1.01 GBytes 4.33 Gbits/sec 16534 [ 5] 14.00-16.00 sec 1.01 GBytes 4.32 Gbits/sec 16494 [ 5] 16.00-17.32 sec 674 MBytes 4.29 Gbits/sec 10782 |
ServerB发送,-S指定tos字段,指定为0xa0,根据交换机的dscp-dot1p的映射表,就可以进入到优先级为5的队列中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
root@ServerB:~# iperf3 -c 192.168.10.12 -p 2000 -t 100 -i 2 -S 0xa0 -u -b 10g -l 65500 warning: UDP block size 65500 exceeds TCP MSS 1448, may result in fragmentation / drops Connecting to host 192.168.10.12, port 2000 [ 5] local 192.168.10.11 port 47420 connected to 192.168.10.12 port 2000 [ ID] Interval Transfer Bitrate Total Datagrams [ 5] 0.00-2.00 sec 1.21 GBytes 5.19 Gbits/sec 19820 [ 5] 2.00-4.00 sec 1.20 GBytes 5.14 Gbits/sec 19617 [ 5] 4.00-6.00 sec 1.19 GBytes 5.12 Gbits/sec 19545 [ 5] 6.00-8.00 sec 1.18 GBytes 5.07 Gbits/sec 19365 [ 5] 8.00-10.00 sec 1.20 GBytes 5.14 Gbits/sec 19626 [ 5] 10.00-12.00 sec 1.20 GBytes 5.14 Gbits/sec 19622 [ 5] 12.00-14.00 sec 1.19 GBytes 5.11 Gbits/sec 19488 [ 5] 14.00-16.00 sec 1.20 GBytes 5.16 Gbits/sec 19691 [ 5] 16.00-18.00 sec 1.20 GBytes 5.17 Gbits/sec 19750 [ 5] 18.00-20.00 sec 1.19 GBytes 5.13 Gbits/sec 19567 [ 5] 20.00-22.00 sec 1.20 GBytes 5.17 Gbits/sec 19715 [ 5] 22.00-24.00 sec 1.19 GBytes 5.09 Gbits/sec 19446 [ 5] 24.00-26.00 sec 1.19 GBytes 5.11 Gbits/sec 19493 |
可以观察到ServerA先打的流量,等ServerB流量进来后,形成了拥塞,ServerA的发送流量被抑制了(7.52Gbit/s->4.29Gbit/s)。
查看交换机从ServerA和ServerB连接口发出的PFC计数,因为交换机接口设置了trust dscp,因此发到交换机的报文直接通过报文本身的dscp去映射dot1p,可以查看dscp-dot1p的映射表。
在流量拥塞的时候,达到了交换机缓存队列的门限值,ServerA和ServerB的交换机直连口都发送了反压帧,以此来抑制发送方的流量。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
[H3C-Twenty-FiveGigE1/0/14]priority-flow-control enable [H3C-Twenty-FiveGigE1/0/14]dis priority-flow-control interface Twenty-FiveGigE 1/0/14 Conf -- Configured mode Ne -- Negotiated mode P -- Priority Interface Conf Ne Dot1pList P Recv Sent WGE1/0/14 On On 0-7 3 0 99393 [H3C-Twenty-FiveGigE1/0/14]dis priority-flow-control interface Twenty-FiveGigE 1/0/15 Conf -- Configured mode Ne -- Negotiated mode P -- Priority Interface Conf Ne Dot1pList P Recv Sent WGE1/0/15 On On 0-7 5 0 29792 <H3C>dis qos map-table dscp-dot1p MAP-TABLE NAME: dscp-dot1p TYPE: pre-define IMPORT : EXPORT 0 : 0 1 : 0 2 : 0 3 : 0 4 : 0 5 : 0 6 : 0 7 : 0 8 : 1 9 : 1 10 : 1 11 : 1 12 : 1 13 : 1 14 : 1 15 : 1 16 : 2 17 : 2 18 : 2 19 : 2 20 : 2 21 : 2 22 : 2 23 : 2 24 : 3 25 : 3 26 : 3 27 : 3 28 : 3 29 : 3 30 : 3 31 : 3 32 : 4 33 : 4 34 : 4 35 : 4 36 : 4 37 : 4 38 : 4 39 : 4 40 : 5 41 : 5 42 : 5 43 : 5 44 : 5 45 : 5 46 : 5 47 : 5 48 : 6 49 : 6 50 : 6 51 : 6 52 : 6 53 : 6 54 : 6 55 : 6 56 : 7 57 : 7 58 : 7 59 : 7 60 : 7 61 : 7 62 : 7 63 : 7 |
虽然流量被抑制了,但是在交换机的出接口队列3和队列5并没有丢包。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
<H3C>dis qos queue-statistics interface Twenty-FiveGigE 1/0/13 outbound Interface: Twenty-FiveGigE1/0/13 Direction: outbound Forwarded: 83507667 packets, 126408157882 bytes Dropped: 0 packets, 0 bytes Queue 0 Forwarded: 0 packets, 0 bytes, 0 pps, 0 bps Dropped: 0 packets, 0 bytes Current queue length: 0 packets Queue 1 Forwarded: 0 packets, 0 bytes, 0 pps, 0 bps Dropped: 0 packets, 0 bytes Current queue length: 0 packets Queue 2 Forwarded: 46 packets, 4986 bytes, 0 pps, 0 bps Dropped: 0 packets, 0 bytes Current queue length: 0 packets Queue 3 Forwarded: 37714815 packets, 57090172626 bytes, 0 pps, 0 bps Dropped: 0 packets, 0 bytes Current queue length: 0 packets Queue 4 Forwarded: 0 packets, 0 bytes, 0 pps, 0 bps Dropped: 0 packets, 0 bytes Current queue length: 0 packets Queue 5 Forwarded: 45792720 packets, 69317966688 bytes, 0 pps, 0 bps Dropped: 0 packets, 0 bytes Current queue length: 0 packets Queue 6 Forwarded: 0 packets, 0 bytes, 0 pps, 0 bps Dropped: 0 packets, 0 bytes Current queue length: 0 packets Queue 7 Forwarded: 86 packets, 13582 bytes, 0 pps, 0 bps Dropped: 0 packets, 0 bytes Current queue length: 0 packets |
3.3 DCQCN测试实验
这里通过使用ofed驱动来进行参数设置,安装完驱动后,rp和np的0-7队列默认都为enable。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
root@ServerA:~# cat /sys/class/net/enp3s0f1np1/ecn/roce_rp/enable/* 1 1 1 1 1 1 1 1 root@ServerC:~# cat /sys/class/net/enp1s0f0np0/ecn/roce_np/enable/* 1 1 1 1 1 1 1 1 |
交换机的ECN相关配置,每个厂家的配置略微不同,本实验使用的交换机型号为H3C S6550XE-56HF-HI。
创建wred queue table,这里把所有队列的ecn功能都使能了,实际可以按照测试需求设置。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[H3C-wred-table-test1]dis th # qos wred queue table test1 queue 0 ecn queue 1 ecn queue 2 ecn queue 3 ecn queue 4 ecn queue 5 ecn queue 6 ecn queue 7 ecn # return |
把该table应用到交换机的出端口,交换机就会对使能的队列报文进行ecn标记。
|
1 |
[H3C-Twenty-FiveGigE1/0/13]qos wred apply test1 |
CNP的默认dscp为48,可以修改也可以使用默认值。
|
1 2 |
root@ServerC:~# cat /sys/class/net/enp1s0f0np0/ecn/roce_np/cnp_dscp 48 |
ServerC启用2个ib_send_bw服务端,用来分别和ServerA和ServerB通信。
|
1 2 3 4 5 6 7 8 9 10 11 |
root@ServerC:~# ib_send_bw -d mlx5_0 --report_gbits -F --run_infinitely -R -T 96 -p 5000 ************************************ * Waiting for client to connect... * ************************************ root@ServerC:~# ib_send_bw -d mlx5_0 --report_gbits -F --run_infinitely -R -T 64 -p 6000 ************************************ * Waiting for client to connect... * ************************************ |
ServerA和ServerB分别指定不同的TOS,ServerA指定TOS为96,对应到队列3,ServerB指定TOS为60,对应到队列2。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
root@ServerA:~# ib_send_bw -d mlx5_1 --report_gbits -F --run_infinitely -R -T 96 -p 5000 192.168.10.12 --------------------------------------------------------------------------------------- Send BW Test Dual-port : OFF Device : mlx5_1 Number of qps : 1 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: ON ibv_wr* API : ON TX depth : 128 CQ Moderation : 1 Mtu : 1024[B] Link type : Ethernet GID index : 5 Max inline data : 0[B] rdma_cm QPs : ON Data ex. method : rdma_cm TOS : 96 --------------------------------------------------------------------------------------- local address: LID 0000 QPN 0x019f PSN 0x183167 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:10:10 remote address: LID 0000 QPN 0x010c PSN 0xa07276 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:10:12 --------------------------------------------------------------------------------------- #bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps] 65536 88282 0.00 9.26 0.017656 65536 88291 0.00 9.26 0.017658 65536 88291 0.00 9.26 0.017658 65536 41595 0.00 4.36 0.008319 65536 6373 0.00 0.67 0.001275 65536 6387 0.00 0.67 0.001277 65536 6384 0.00 0.67 0.001277 65536 6378 0.00 0.67 0.001276 65536 6387 0.00 0.67 0.001277 root@ServerB:~# ib_send_bw -d mlx5_1 --report_gbits -F --run_infinitely -R -T 64 -p 6000 192.168.10.12 --------------------------------------------------------------------------------------- Send BW Test Dual-port : OFF Device : mlx5_1 Number of qps : 1 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: ON ibv_wr* API : ON TX depth : 128 CQ Moderation : 1 Mtu : 1024[B] Link type : Ethernet GID index : 3 Max inline data : 0[B] rdma_cm QPs : ON Data ex. method : rdma_cm TOS : 64 --------------------------------------------------------------------------------------- local address: LID 0000 QPN 0x01ae PSN 0x373fa3 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:10:11 remote address: LID 0000 QPN 0x010e PSN 0x5fab61 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:10:12 --------------------------------------------------------------------------------------- #bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps] 65536 66058 0.00 6.93 0.013211 65536 66599 0.00 6.98 0.013320 65536 66511 0.00 6.97 0.013302 65536 66479 0.00 6.97 0.013296 65536 66560 0.00 6.98 0.013312 65536 66566 0.00 6.98 0.013313 65536 66477 0.00 6.97 0.013295 65536 66639 0.00 6.99 0.013328 |
交换机在出接口给报文打上ecn标记。

当ServerC收到打上标记的报文后,发送CNP报文给源端。

CNP对应的的OP Code.

当RP设备收到CNP后,进行降速,保证整个链路上的拥塞避免,队列2和队列3并没有出现丢包。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
<H3C>dis qos queue-statistics interface Twenty-FiveGigE 1/0/13 outbound Interface: Twenty-FiveGigE1/0/13 Direction: outbound Forwarded: 7575313 packets, 8378293289 bytes Dropped: 0 packets, 0 bytes Queue 0 Forwarded: 0 packets, 0 bytes, 0 pps, 0 bps Dropped: 0 packets, 0 bytes Current queue length: 0 packets Queue 1 Forwarded: 0 packets, 0 bytes, 0 pps, 0 bps Dropped: 0 packets, 0 bytes Current queue length: 0 packets Queue 2 Forwarded: 5730147 packets, 6337542582 bytes, 869210 pps, 7687990184 bps Dropped: 0 packets, 0 bytes Current queue length: 172 packets Queue 3 Forwarded: 1845163 packets, 2040750278 bytes, 279962 pps, 2471996680 bps Dropped: 0 packets, 0 bytes Current queue length: 26 packets |
同样的组网测试环境下,在RP侧把队列2的ecn禁用,这时候收到CNP报文后则不会进行降速,队列2就出现了丢包。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
root@ServerA:~# mlnx_qos -i ens6f1np1 --trust dscp root@ServerA:~# echo 0 > /sys/class/net/ens6f1np1/ecn/roce_rp/enable/2 <H3C>dis qos queue-statistics interface Twenty-FiveGigE 1/0/13 outbound Interface: Twenty-FiveGigE1/0/13 Direction: outbound Forwarded: 13967548 packets, 15448051477 bytes Dropped: 1328925 packets, 1443212550 bytes Queue 0 Forwarded: 44 packets, 5472 bytes, 0 pps, 0 bps Dropped: 0 packets, 0 bytes Current queue length: 0 packets Queue 1 Forwarded: 0 packets, 0 bytes, 0 pps, 0 bps Dropped: 0 packets, 0 bytes Current queue length: 0 packets Queue 2 Forwarded: 6190834 packets, 6847060884 bytes, 856920 pps, 7576002320 bps Dropped: 1328925 packets, 1443212550 bytes Current queue length: 25139 packets Queue 3 Forwarded: 7776659 packets, 8600983334 bytes, 273259 pps, 2416003360 bps Dropped: 0 packets, 0 bytes Current queue length: 22 packets |
4、总结
PFC和DCQCN都是为了提高数据中心网络的性能和可靠性而设计的。PFC主要关注于防止丢包,而DCQCN则更侧重于拥塞控制和避免。在实际应用中,这两种技术也是相结合使用,以达到最佳的网络性能。







