

作者简介:中国移动智慧家庭运营中心算力网络团队 蔡伸、董文哲、刘昊武
前言
Google在sigcomm17上发表了论文《Carousel: Scalable Traffic Shaping at End Hosts》,Carousel此命名挺有意思,Carousel的释义如下图1,

游乐园旋转木马的流程就是玩家花钱购买了一个时间,工作人员进行时间分配,玩家进入旋转木马,等到自己分配的时间截止,从旋转木马上下来,从出口离开,如图2,

Carousel的设计思想如出一辙,如图3,
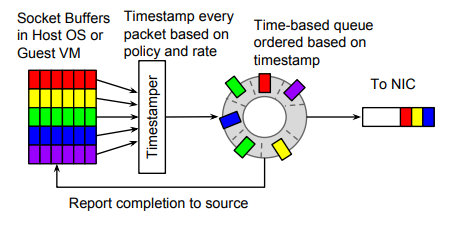
通过以上类别,想必读者对Carousel有了初步概念,后文将详细阐述Carousel的技术细节。
其实,Google网络团队近年围绕流量整形以及拥塞控制的“战略思想”,粗略总结为三点:
1.以时延作为网络拥塞的标识。
2.将时延应用到网络控制的工具中。
3.将拥塞控制放到可操作性更强的发送端(客户端)。
Google 近些年进行了不少实践与研究:
- HULL (NSDI’12) – Less is more: trading a little bandwidth for ultra-low latency
- BwE (Sigcomm’15) – Flexible, Hierarchical Bandwidth Allocation for WAN
- FQ/pacing (IETF88’13) – TSO, fair queuing, pacing: three’s a charm
- Timely (Sigcomm’15) – RTT-based congestion control for the datacenter
- BBR (CACM v60’17) – Congestion-based congestion control,中文版
- Carousel (Sigcomm’17) – Scalable traffic shaping at end hosts
本文将重点介绍流量整形技术Carousel,并将简要介绍谷歌流量整形和拥塞控制的其他实践进展。
一、流量整形技术现状
1.1 什么是流量整形
网络发展至今,一直以来都有一个强烈的需求,就是网络要尽可能的快,也就是所谓的AFAP(as fast as possible)[3],满足AFAP一定是一个优点。然而TCP/IP协议模型在设计之初,虽然IP协议确实尽力而为的(best effort delivery),也就是说它是尽可能快,满足AFAP理念的,但它是不可靠的,UDP同理。然而,网络应用和用户对网络可靠性有需求,基于IP协议有了TCP,建立起了一套可靠传输方式,比如丢包后必须重传才能保证可靠性,同样TCP也需要满足AFAP(在有限制的情况下尽可能快),在TCP传输中,通过慢启动,滑动窗口TCP限制了数据包发送的大小(多少),但是数据包的发送速率还是满足AFAP的,就是尽可能地快,重传也要尽可能快。
然而满足AFAP,存在一种非常常见的情况,发送端一直尽可能快地发送数据包,接收端的接收速率小于发送端的发送速率,将会出现大量丢包,此时TCP这些需要拥塞控制的协议会大大降低吞吐量,导致网络质量下降,与AFAP思想相悖。于是发送端需要通过一种主动调整流量输出速率的措施,其作用是限制流量与突发,使报文以比较均匀的速率向外发送,这就是所谓的流量整形(traffic shaping)。
1.2 令牌桶队列流量整形器
1.2.1 令牌桶队列技术
当前,流量整形通常通过 device output queue(设备发送队列)实现[1];
- 最快发送速率就是队列的流速(drain rate);
- 传输中的最大数据量(inflight data)由接收窗口大小或队列长度决定。
相信很多人接触过QoS,对令牌桶有一定了解。下面,将以令牌桶队列流量整形器(token bucket queue)为例,介绍一下当前广泛应用的流量整形技术,如下图4。
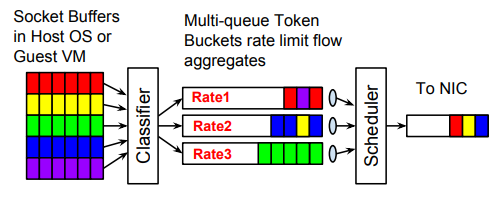
1.主机的出向流量(egress traffic)经过一个分类器(classifier)进行分类;
2.分类之后的流量分别放到不同的 queue(缓冲队列),各 queue 的发送速率限制可能是不同的,通过令牌桶进行调度;
3.某个调度器(scheduler)负责统一调度以上所有 queue 的发包,将包从 queue 中取出放到主机网卡的 TX queue 中;网卡将 TX queue 中包无差别地发送出去。
令牌桶技术是广泛运用的流量整形基础。什么是令牌桶技术?[2] 如下图5,相信每个写网络包处理的工程师都写过基本的令牌桶限速器。令牌桶是一个形象的描述,即可以想象有一个桶可以容纳一定量的令牌(token),每放行一个数据包便消耗一定量的令牌,数据包的放行与否取决于令牌桶中的令牌个数。
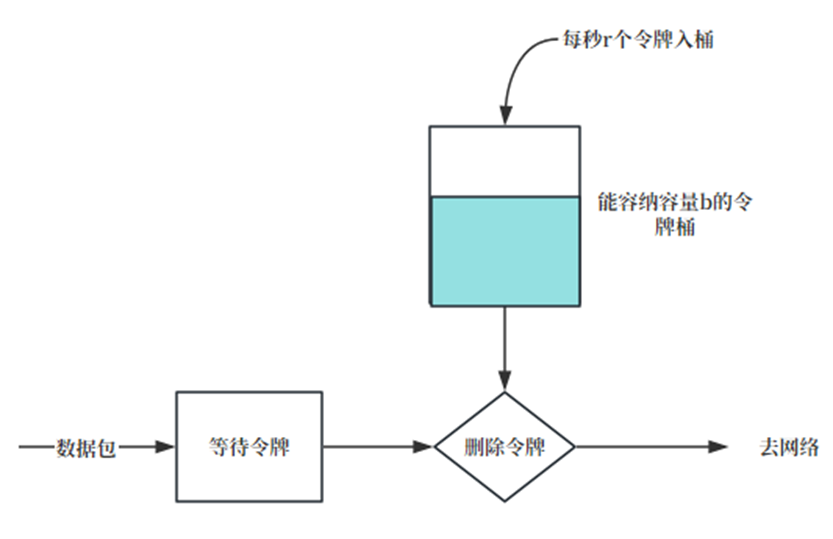
比如,如果令牌桶限制的是 PPS (Packet Per Second),假设一个令牌代表一个数据包。那么一个限定 PPS 为 300K/s 的限速器,每秒会产生的令牌数则是 300K 个。任何一个数据包经过这个限速器,则消耗一个令牌,如果令牌消耗到 0,则进行丢包[2]。
假设 Pt 表示到达时间(去网络)是 t 的数据包,令牌桶上一个经过的数据包的时间为 t′ ,那么在这段时间内,令牌桶产生的令牌数为:
令牌桶里剩余的令牌桶的个数为 T,那么当 Pt 到达时,令牌桶内的令牌为:
令牌桶是有容量的,上述公式的值可能会超过令牌桶的容量,假设令牌桶的容量为 Burst ,如果上述计算的值超过了这个限定,则令牌数等于 Burst 。
此时因为数据包 Pt 要经过,则应该消耗 1 个令牌,于是更新令牌桶的时间戳为 t′ 并按照上述计算更新令牌桶内的令牌数目。如果通过计算发现产生的令牌数超过了消耗,那么放行数据包;如果不是,则需要丢弃数据包。
可能会有人疑惑,为何令牌桶的容量是有限的,而为何最大的容量取名为 Burst ,这其实是因为令牌桶其实是允许在特定的时间窗口内的速率超过限定值。以 300Kpps 限速器为例子,假设 Burst 等于 300K,并且当前令牌桶是满的,此时,即使 100ms 内来了 300K 个包,那么令牌桶也会放行所有数据包(因为令牌桶的令牌数是够用的),而在这 100ms 内,实际速率不是 300Kpps,而是 3Mpps。顾名思义,令牌桶的容量其实限定了其允许的突发速率。
在令牌桶队列整形器中,若需要对多条流按照不用的qdisc(qos规则)进行流量整形,需要创建多个流量整形队列,每个队列基于令牌桶的方式进行流量的限制。
1.2.2 HTB和FQ/pacing
令牌桶队列技术是相对简单粗暴的,流量整形器不会对等待令牌的数据进行缓冲,如果流量将配置的Burst消耗完之后,那么整形器会将后续的数据包丢弃,造成网络质量的急剧下降。通常情况下,网络的使用必定存在许多的微突发,这种相对粗糙的流量整形技术无法提供很好的体验。于是有了HTB和FQ/pacing技术的提出,弥补了单一令牌桶队列技术的不足。
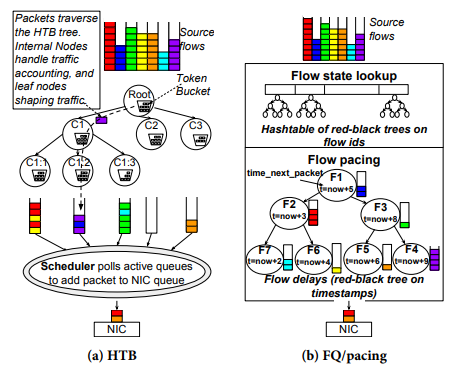
Hierarchical Token Bucket (HTB) [4]:
HTB(分层令牌桶技术)与常规的令牌桶队列技术不同,它会将等待的令牌数据包进行缓存,而不是直接丢弃。如图6(a),基本思路还是采用了常规令牌桶队列技术,但是HTB将流量分类为多个流量类别,每个类别和树中的一个令牌整形器关联。HTB中的层次结构允许共享父节点的叶节点之间进行借用,以实现工作保持调度,简单来说,就是父节点的令牌桶Burst会大于子节点,子节点可以通过父节点缓存超出的数据包,树状的设计可以尽可能的做到缓存的复用,有点类似单速双桶的机制,但是更灵活和高效。
总的来说,HTB有如下优点:
1.提供了数据包缓存功能。
2.树状结构,增加了缓存的复用率。
FQ/pacing[5]:
FQ/pacing(公平队列和节奏控制)是一个用于对出口TCP和UDP流进行公平排队和数据包整形的Linux Qdisc。
首先是FQ调度器,FQ调度器在一个由红黑树(RB)数组组成的数据结构中跟踪每个流的状态,索引是流哈希ID。一个赤字轮询(DRR)调度器从活动流中获取出站数据包。垃圾收集器删除不活动的流。维护每个流的状态提供了支持活动流出口整形的机会。简而言之,FQ通过红黑树和DDR实现了一个高效且公平的流量调度。
其次是pacing,在说pacing之前,笔者先带大家回忆一下TCP吞吐量的计算,如下:

大多数情况下TCP的吞吐量,基本等于滑动窗口(cwnd)/往返时延(RTT)。pacing阶段如上图6(b),使用了一个漏桶队列(leaky bucket),数据包入队速率是cwnd/rtt,出队速率设置pacing rate大于cwnd/rtt(linux默认设置为2倍cwnd/rtt)确保漏桶不溢出,然后通过使用:数据包大小/pacing rate,为数据包分配发送时间,通过漏桶队列机制实现数据包的pacing。
总的来说,FQ/pacing有如下优点:
1.对单TCP流支持更好。
2.提高了TCP的一致性。
1.3 现有技术缺陷
令牌桶队列技术:
简单的令牌桶队列技术,没有对数据包进行缓存,数据包超过Burst就会被丢弃,同时令牌桶的颗粒度也较大容易出现令牌桶浪费。总的来说,令牌桶队列技术有如下明显缺点:
1.精度差。
2.丢弃数据包会触发TCP的不良行为。
HTB和FQ/pacing:
增加了CPU消耗。FQ/pacing和HTB的令牌桶架构需要多个队列,每个速率限制一个队列,以避免头部阻塞。维护成本随着队列的数量而增加,有时超线性增长。CPU成本来自多种因素,特别是需要轮询队列以处理数据包的需求。通常,调度器使用简单的循环调度算法,轮询的成本与队列数量成线性关系,或者使用跟踪活动队列的更复杂算法。
此外,在多CPU系统上的成本主要是CPU之间共享队列和相关速率限制器的锁定和争用开销。HTB和FQ/pacing在每个数据包基础上获取全局锁,随着CPU数量的增加,锁的争用情况变得更糟。
增加了内存成本。内存成本是由于维护整形器的数据结构。挑战在于分割和约束资源,以便在正常操作期间不丢失数据包;例如,HTB类别中的队列可以配置为增长到16K个数据包,FQ/pacing具有全局限制为10K个数据包和每个队列限制为1000个数据包,超过这个数量的数据包将被丢弃,即使全局内存还有很多可用空间。在配置调整不当的情况下,即使全局池中还有足够的空间,队列内的数据包可能会被丢弃。
综上所述,问题变成了我们是否能以更小的开销获得相同的流量整形能力,于是Google提出了Carousel技术。
二、Carousel设计思想
正如paper中指出的Carousel源自对许多场景的观察、思考以及归纳,通过观察各类流量场景的需求,归纳不足,思考能否生成一个统一的、准确的、高效的流量整形机制。综合上文分析和实际场景,Carousel的整体设计思想围绕了以下原则[6]:
1.与更高级的拥塞控制机制(如TCP)兼容工作。
2.正确进行数据包节奏控制(pacing):避免突发和不必要的延迟。
3.提供反压力并避免数据包丢失:由于速率限制而延迟数据包应该迅速导致终端应用程序变慢。否则,应用程序生成的每个额外数据包都需要在整形器中进行缓冲或丢弃,浪费内存和CPU资源来排队或重新生成数据包。此外,基于丢包的拥塞控制算法常常通过显著降低相应流的速率来对数据包丢失做出反应,这需要更长的时间才能恢复到原始带宽。
4.避免头部阻塞:整形属于一个流量聚合的数据包不应该延迟其他聚合的数据包。
5.高效使用CPU和内存资源。
为了满足上述原则,Carousel技术在设计时使用了如下三个技术:
1.单队列整形(single queue shaping):通过依赖一个单一队列来进行数据包整形,可以减轻多队列系统(使用令牌桶)的低效和开销,因为这些系统需要每个速率限制一个队列。
2.延迟完成(deferred completions):发送方必须限制每个流的在途数据包数量,可使用现有机制(如TSQ或拥塞窗口)。
3.单核独立整形器(silos of one shaper per-core):将单队列整形器隔离到一个核心中可以减轻由于锁定和同步导致的CPU效率低下的问题。
三、Carousel核心技术拆解
Carousel整形器对于每个数据包包括三个顺序步骤,如下图7。
1.网络堆栈计算数据包的时间戳。
2.堆栈将数据包入队到由这些时间戳索引的队列中。
3.当数据包的传输截止时间过期时,堆栈将数据包出队并触发一个完成事件,该事件可以用于传输更多的数据包。
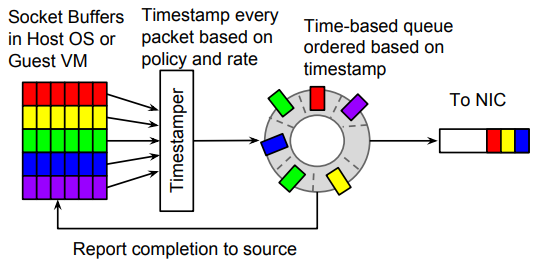
下面笔者将详细展开解释一下每个步骤中涉及的关键技术。
3.1 单队列整形
如图七,可以看到,实现一个基于时间戳的单队列分为两个模块,分别为Timestamper和Time-based queue。简而言之,这部分主要的实现分为如何为数据包计算时间戳以及如何根据时间索引关联上队列。
3.1.1 时间戳计算
时间如何和rate limit关联上的,速率=长度/时间。在流量整形的场景下,速率是一个配置好的常量,数据包的长度是一个已知量,于是时间和速率之间就有了互相标识的能力。
时间戳计算是Carousel中流量整形的第一步。数据包的时间戳决定了其发出时间,即数据包应该在何时传输到网卡上。一个数据包可能会受到多个整形策略的控制,例如传输协议的节奏控制、每个连接的流量限速和流量的总体限速。在典型的Qos设置中,这些策略是独立实施的,每一个在网络堆栈的实现点上都会执行相应的策略。然而Carousel只要求在数据包的每个时间戳点都按照该点的速率进行计算,而不是在该点强制实施速率。举个例子:TCP堆栈首先使用释放时间为每个数据包进行时间戳标记,以在连接内引入数据包之间的间隔(pacing);随后,数据包在路径中的不同速率限制器会修改数据包的时间戳,以符合与不同流量聚合相关的一个或多个速率。
时间戳算法包括两个步骤:
1)基于各个策略(如节奏控制和速率限制)计算时间戳,
2)合并不同的时间戳,使得数据包的最终传输时间符合期望的整形行为。数据包的最终时间戳可以被视为数据包传输到网卡上的最早释放时间(ERT)。
设置时间戳:和pacing以及常规的rate limit技术通过设置一个相对时间戳,即计算一个时间间隔,相对当前时间一定时间后进行传输不同,Carousel设置的是绝对时间戳,即到了这个时间,数据包就需要发送。简单来说,回顾一下本节第一段的知识,Carousel计算绝对时间戳是根据创建的时间戳LTSi+len(数据包)/策略Rate获得一个绝对时间戳。在pacing的情况下,通过策略的数据包可以属于相同的流,在rate limit的情况下,可以属于聚合流。如果未对流施加任何策略,时间戳为0。
合并时间戳:合并时间戳很好理解,例如多个策略规则作用到同一个数据包上,根据rate=length/time,需要用较大的时间戳代表较小的速率,综合各个策略规则,经过合并,将最大的时间戳作为最后限速的结果。
3.1.2 时间关联队列
Carousel的时间关联队列核心技术是使用了Timing Wheel(时间轮)。时间轮是一种按时间分槽的高效队列。上文也提到了,Carousel想要减少消耗以及队列,时间轮很好的满足了这一点。
什么是Timing Wheel(时间轮)[7]:
相信接触过C语言研发的读者都接触过ring buffer这种结构,我们不妨从ring buffer开始理解时间轮,ring buffer做到了buffer的插入,取出和复用,时间轮也一样,时间轮算法的核心是,轮询线程不再是负责遍历所有任务,而只负责处于其当前时间上的任务。就像钟表一样,时间轮有一个指针会一直旋转,每转到一个新的时间,就去执行挂在这一时刻下的所有任务,当然,这些任务通常是交给其他线程去做,指针要做的只是继续往下转,不会关心任务的执行进度。这样子就形成了一个时间复杂度是O(1)的算法。
Carousel如何使用时间轮:
在使用Timing Wheel时,Carousel跟踪一个变量now表示当前时间。时间戳比now早的数据包不需要入队,立即发送。此外,Carousel允许配置horizon(时间范围),即数据包可以排队的最长时间点与now之间的最大时间间隔。如果Rmin表示支持的最小速率,Lmax表示队列中属于相同聚合的最大数据包数目,该聚合的速率被限制为Rmin,则有以下关系:horizon = Lmax/Rmin秒。
举个例子:假设Timing Wheel配置的最小速率为1.5Mbps,数据包大小为1500字节,时间槽粒度=1500字节8/1.5Mbps=8微秒,时间范围配置为4秒。这个配置产生了horizon/gmin=4s/8us=500K个时间槽。支持的最小速率限制或节奏速率是每个时间范围内发送一个数据包,即为配置的最小速率1.5Mbps。每流量的最大支持速率=15008/8us=1.5Gbps。综上,可以通过增加在一个时间槽内调度的数据包的大小(例如,调度一个4KB的数据包)或者减小时间槽的粒度来支持更高的速率。
3.2 延迟完成
看过上文,相信读者已经对流量整形有了一定了解。假设当发送端(end hosts)发送速率已经大于限速器的缓存,此时会一直出现丢包,如果发送端不降低发送速率,网络情况会持续恶化。此时就需要限速器对发送端进行反压(backpresure)通过一定方式,让发送端将发送速率下降,常见的方式是结合TSQ反压发送客户端。Carousel对此提出了两种方式:延迟完成和基于延迟的拥塞控制。
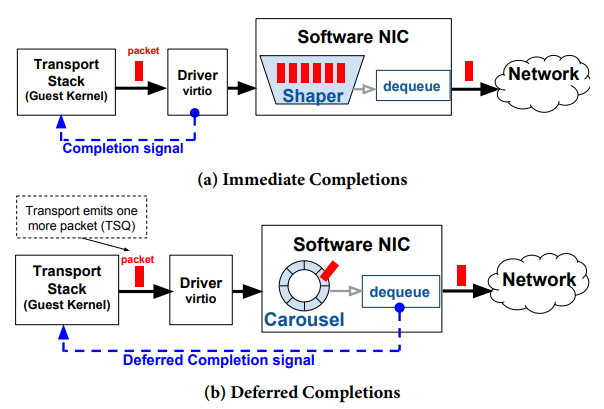
延迟完成(Deferred Completions)的思想如图8所示,它在Carousel将数据包传输到线路之前保持完成信号,防止堆栈将更多数据包入队到NIC。在图8(a)中,客户端堆栈的驱动程序在入队时生成完成信号,导致Timing Wheel被堆积了与拥塞窗口相当数量的TCP流的数据包,超过了Timing Wheel的时间范围,导致丢包。在图8(b)中,软件NIC中的Carousel仅在数据包从Timing Wheel中出队后向客户端堆栈返回完成信号,因此严格限制了整形器(shaper)中的数据包数量,因为传输堆栈依赖于完成信号来入队更多数据包到Output Queue。延迟完成同时结合了TCP-TSQ,只有数据包从哈希映射中移除的操作向上传播到堆栈中,才允许TSQ入队另一个数据包。
基于延迟的拥塞控制(CC)是对延迟完成的另一种形式的反压力。基于延迟的CC感知到shaper引入的延迟,并随着往返时延(RTT)增加而调整TCP的拥塞窗口为较小的值。拥塞窗口用作Timing Wheel中数据包数量的限制。
3.3 单核独立整形器
上文列举了很多Carousel的工作方式和技术,笔者都是基于单核单流量整形器展开的,然而实际情况中,常常需要单个聚合速率来整形多个TCP流,然而不同的TCP流常常被散列到不同的CPU上。因此,Carousel提出了两个组件来解决多核扩招的问题,分别如下。
(1)NIC级别的带宽分配器(NBA):NBA接受对流聚合的总速率限制,如下图9,并定期重新分配每个核心的Timestamper的速率限制。NBA使用简单的水填充算法来实现工作保持和最大最小公平性。各个Timestamper以(字节计数,字节计数测量的时间戳)对的序列形式向NBA提供最新的流使用数据;NBA对Timestamper的速率分配以字节每秒为单位进行。水填充算法确保如果某个核心上的流量使用量小于其公平份额,则将额外的流量分配给其他核心上的流量。如果任何核心上的流量需求为零,则中央算法仍然保留聚合速率的1%作为预留,以提供空间进行增加。
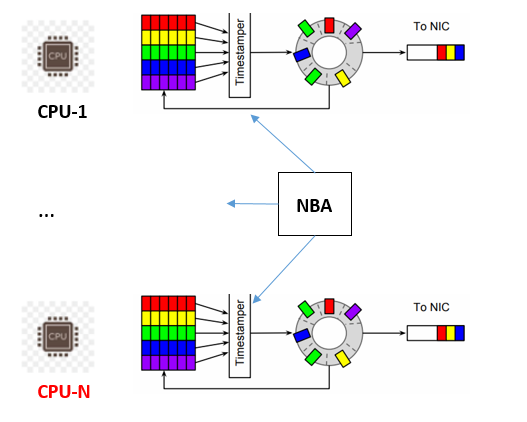
(2)NBA和每个核上的Timestamper通信组件:时间戳器的使用更新和NBA的速率传播以一种懒惰算法定期进行(paper原文是lazy manner,笔者将它翻译成懒惰算法,猜测是类似机器学习的KNN懒惰算法类似,在和多个Timestamper通信时NBA会将速率相似的归为一类,为剩下的分配速率)。选择懒惰的更新方式是为了避免在每次更新时增加数据路径的开销。更新的频率是稳定性和计算速率的快速收敛之间的权衡;目前Carousel使用约0.1秒的更新频率。
四、Carousel总结
综上所述,在本文中,笔者在第一章节向大家展示了终端主机流量整形的不足,如性能开销很大,限制了整个系统的可扩展性,特别是当每个服务器有数千个单独的流量类别时尤为突出。并且生产服务器的测量结果显示,在主机上进行整形会消耗大量的CPU和内存,不必要地丢弃数据包,遭受头部阻塞和不准确性,并且不能提供反馈给上层。于是Google提出了Carousel技术,笔者认为这个技术可以说是格物、致知的结果,该技术可以扩展到每个服务器的数万个策略和流量,它由三个关键思想的综合构建而成:
i)单队列整形,使用时间作为释放数据包的基础的单个队列整形器。
ii)延迟完成,高层中资源的精细、及时释放与实际数据包出发相结合。
iii)单核独立整形,每个CPU核心一个整形器,使用无锁协调。
Google在一个云服务提供商的视频流量服务中的生产经验表明,Carousel能够准确进行流量整形,同时相对于最先进的部署方案,改善了整体机器CPU利用率8%(网络部分的CPU利用率提高了20%),它还比现有方法消耗少两个数量级的内存,并且对目标速率的符合性提高了10倍。
至此,笔者对Carousel技术的介绍结束了,相信大家对Carousel技术已经有了一定的思考,下面笔者将会简单地拓展一下Carousel技术的技术演进,以及将Carousel技术和其他现有的流量整形以及拥塞控制技术进行对比,为读者提供更多的思考空间。
五、谷歌的Carousel研究路径
本章节将结合前言中罗列的Carousel技术路径中的技术进行简单的介绍,有兴趣可以阅读,在整理这部分论文的时候,笔者还发现了一个有趣的地方,Google的技术框架都是先在自己的数据中心或者业务上大规模部署使用后,才进行论文的发表。
1.HULL (NSDI’12) – Less is more: trading a little bandwidth for ultra-low latency[8]:这篇论文是斯坦福大学联合思科谷歌以及NEC联合发表的文章,可以说是谷歌网络团队中最早发布的关于时延作为网络标识和改进网络质量的论文,本文主要介绍了HULL (High-bandwidth Ultra-Low Latency)技术架构,具体如下,传统的网络质量衡量标准,如好吞吐量、服务质量和公平性,通常以带宽为基础。网络延迟很少是主要关注点,因为提供最高级别的带宽实质上就意味着增加延迟——在平均值和尤其是在尾部。然而,最近对延迟作为主要指标在主流应用中重新引起了关注。在本文中,提出了HULL(高带宽超低延迟)架构,以平衡两个看似矛盾的目标:接近基准的网络延迟和高带宽利用率。HULL通过使用Phantom Queues在网络链路完全利用和交换机形成队列之前传递拥塞信号,留下“带宽余地”。通过将利用率限制在小于链路容量的水平,为对延迟敏感的流量留下了避免缓冲和相关大延迟的空间。同时,采用了最近提出的拥塞控制算法DCTCP,以自适应地应对拥塞并减轻无缓冲方式运行所带来的带宽损失。HULL还采用了报文节奏控制来对抗中断合并和大型发送卸载所引起的突发性。实现和模拟结果表明,通过牺牲一小部分(例如10%)的带宽,HULL可以显著降低数据中心的平均延迟和尾延迟。
2.BwE (Sigcomm’15) – Flexible, Hierarchical Bandwidth Allocation for WAN[9]:BwE是谷歌在15年的Sigcomm上发表的一种灵活的、分层的WAN带宽分配框架,具体如下,广域网(WAN)带宽仍然是一种受限的资源,从经济成本上来说,大量超额配置是不可行的。因此,根据服务优先级和额外分配的增值来分配带宽是很重要的。例如,对于某个服务来说,获得10Gb/s的带宽可能是最高优先级,但是一旦达到这样的分配,额外的优先级可能会急剧下降,不利于将带宽分配给其他服务。基于固定优先级的单个流可能不是带宽分配的理想基础,受到这一观察的启发,论文提出了Bandwidth Enforcer (BwE)的设计和实现,它是一种全局的分层带宽分配基础设施。BwE支持:i)根据优先级带宽函数进行服务级带宽分配,其中一个服务可以表示任意一组流量;ii)根据用户定义的层次结构进行独立分配和委派策略,同时考虑带宽和故障条件的全局视图;iii)在流量工程网络中常见的多路径转发;iv)在异常情况下,中央管理点可以覆盖(可能是错误的)策略。多年来,BwE在生产环境中实现了更高效的带宽利用和更简单的管理。
3.Timely (Sigcomm’15) – RTT-based congestion control for the datacenter[10],Timely是谷歌网络团队发布在15年Sigcomm会议上的一种基于时延的数据中心拥塞控制框架,具体如下,数据中心传输旨在提供低延迟的消息传递和高吞吐量。论文表明,简单的数据包延迟,以主机上的往返时间(RTT)来衡量,是一种有效的拥塞信号,无须进行交换机反馈。首先,本文展示了网卡(NIC)硬件的进步使得微秒级准确度的RTT测量成为可能,并且这些RTT足以估计交换机的排队情况。然后,本文描述了TIMELY如何使用RTT梯度调整传输速率,以保持数据包延迟低而同时提供高带宽。谷歌在具有操作系统绕过能力的NIC上运行的主机软件中实现了本文的设计。通过在Clos网络拓扑上进行多达数百台机器的实验,Timely展示了出色的性能:在使用PFC的绕过操作系统的消息传递中开启TIMELY时,99分位数尾延迟降低了9倍,同时保持接近线速的吞吐量。谷歌采用Timely的系统还优于在优化内核中运行的DCTCP,将尾延迟降低了13倍。据悉,TIMELY是第一个用于数据中心的基于延迟的拥塞控制协议,并且尽管RTT信号数量比早期的基于延迟的方案(如Vegas)少一个数量级(由于NIC卸载),但它仍然取得了相应的结果。
4.BBR (CACM v60’17) – Congestion-based congestion control[11]:BBR是谷歌在17年发表的一篇论文,相信大家对BBR已经十分熟悉了,Linux内核已经对BBR进行了支持,BBR对TCP流的优化效果十分明显,日常的网络优化和使用中现在常常能见到BBR的身影,本论文是发表在CACM上的,相信讲述了BBR设计的背景和技术路径,具体如下:当瓶颈缓冲区很大时,基于丢包的拥塞控制会使其保持满载,导致缓冲区过度膨胀(bufferbloat)。当瓶颈缓冲区较小时,基于丢包的拥塞控制会错误地将丢包解释为拥塞信号,导致吞吐量降低。解决这些问题需要一种替代基于丢包的拥塞控制的方法。找到这种替代方法需要了解网络拥塞产生的地点和方式。BBR正是这样一种方法。
六、其他有趣的拥塞控制技术
本章节分享一些笔者阅读的一些有趣的网络拥塞控制技术,有些是基于谷歌思想的进一步提升,有些思想和谷歌完全相悖,非常有趣,大家感兴趣可以进行阅读。
1.Starvation in End-to-End Congestion Control(Sigcomm’22) [12]:端到端拥塞控制的饥饿现象是斯坦福大学联合剑桥大学组建的科学和人工智能实验室发表在2022年Sigcomm会议上的论文,本文批评了基于时延拥塞控制技术的不足,并罗列了证据,该文章概述如下,有兴趣可以进一步阅读:为了克服传统基于丢包的拥塞控制算法(CCA)的弱点,研究人员开发并部署了几种延迟限制的CCA(如Vegas,FAST,BBR,PCC Copa等),这些算法在不增加延迟的情况下实现了高利用率。当在具有固定瓶颈速率的路径上运行时,这些CCA会在均衡状态下收敛到一个较小的延迟范围。本文证明了一个令人惊讶的结果:尽管设计用于实现合理的流间公平性,但当前开发延迟限制CCA的方法并不总能避免饥饿,这是一种极端的不公平现象。当这样的CCA在路径上运行时,如果非拥塞网络延迟的变化(由于ACK聚合和终端主机调度等真实世界因素)超过CCA在均衡状态下收敛的延迟范围的两倍,就可能发生饥饿现象。通过链路仿真器提供了对BBR、PCC Vivace和Copa这一结果的实验证据。本文讨论了这个结果的影响,并认为为了确保不发生饥饿,高效的延迟限制CCA应该设计一定量的非拥塞抖动,并确保其均衡延迟振荡至少是这种抖动的一半。
2.HPCC: high precision congestion control(Sigcomm’19)[13]:本文是阿里巴巴发布在2019年Sigcomm会议上的论文(那年Sigcomm会议在北京举行),本文基于谷歌网络团队,基于时延的拥塞控制有了进一步提升,具体如下:拥塞控制(CC)是在高速网络中实现超低延迟、高带宽和网络稳定性的关键。通过多年在大规模高速RDMA网络上的运营经验,发现现有的高速CC方案在实现这些目标方面存在固有的限制。在本文中,提出了一种新的高速CC机制——HPCC(高精度拥塞控制),它能够同时实现这三个目标。HPCC利用网络内遥测(INT)来获取精确的链路负载信息,并精确地控制流量。通过解决拥塞期间延迟的INT信息和对INT信息的过度反应等挑战,HPCC能够快速收敛以利用空闲带宽,同时避免拥塞,并能保持接近零的网络内排队延迟,实现超低延迟。HPCC还具有公平性,并且易于在硬件上部署。使用通用可编程的NIC和交换机实现了HPCC。在评估中,与DCQCN和TIMELY相比,HPCC能够将流完成时间缩短达95%,即使在大规模的集中式流情况下也几乎不会出现拥塞。
七、业内实践
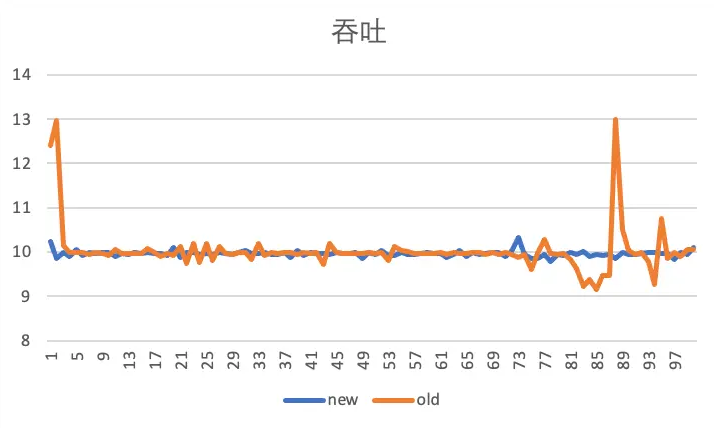
本章回到Carousel技术框架,不像Falcon协议体系下的PLB、SNAP等有很多的实践,包括开源代码,Carousel能够获取到的资料较少,笔者经过咨询和了解,已知的是字节跳动系统与技术工程团队(简称 STE 团队)花了两年时间在限速器优化方面的一些探索,基于OVS-DPDK实现了Carousel,在实际测试中取得了对TCP流量更加稳定的流量整形效果,如图10[2]。
八、借鉴意义
Google的多项技术都在论文中指出使用场景是在数据中心应对INCAST情况,那么在其他场景是不是也会出现类似数据中心INCAST的情况。笔者注意到近些年BBF发布了家庭网关上云的标准,相关专利也持续布局。中国电信推出了云网关,中国移动推出了家庭边缘算力网关等应用场景,可以设想一下,家庭智能网关(ONU)上云,多个家庭用户接入同一个网关上网,将会面临大量家庭终端设备访问一个云化网关上网的情景,那么传统的网关Qos限速方式可能已经无法匹配,具体如下:1)、端口整形器,无法针对个性化业务。2)、队列整形器,CPU、内存、性能开销过大。
基于上述分析,Carousel整形器框架可能是非常值得借鉴的一个技术框架,能够降低开销,同时支持大量的rate limit策略,然而实际实现过程中有很多问题需要我们思考:1)、网关云化的主要部署场景是云化,虚拟机部署,在软件层面实现Carousel涉及到内核驱动改造适配,工作量大。2)、网关云化支持大量家庭以及终端接入,类似数据中心,同时存在的流量连接极限可能超过百万个,需要考虑应对Incast的情况,仅基于时延来进行流量整形,有序的延迟完成容易饿死老鼠流,故而Google 在论文 PicNIC [13]中提出,在 Carousel 之上,利用 virtio 支持 out-of-order completion (乱序完成) 的特点,实现了更细粒度的反压,这都需要设计驱动层面以及协议栈层面的修改。
Carousel的技术分析到这就结束了,感谢大家的阅读。
参考资料
[1] Traffic policing in eBPF: applying token bucket algorithm
[2] 字节跳动在限速器优化上的实践探索
https://my.oschina.net/u/6150560/blog/8590677
[3] Netdev 2018: Evolving from AFAP: Teaching NICs about time
[4] Linux TC 流量控制与排队规则 qdisc 树形结构详解(以HTB和RED为例)
https://blog.csdn.net/qq_44577070/article/details/123967699
[5] TSO, fair queuing, pacing: three’s a charm
https://www.ietf.org/proceedings/88/slides/slides-88-tcpm-9.pdf
[6] Carousel (Sigcomm’17) – Scalable traffic shaping at end hosts
[7] Hashed and Hierarchical Timing Wheels: data structures to efficiently implement a timer facility
[8] HULL (NSDI’12) – Less is more: trading a little bandwidth for ultra-low latency
[9] BwE (Sigcomm’15) – Flexible, Hierarchical Bandwidth Allocation for WAN
[10] Timely (Sigcomm’15) – RTT-based congestion control for the datacenter
[11] BBR (CACM v60’17) – Congestion-based congestion control
[12] Starvation in End-to-End Congestion Control(Sigcomm’22)
[13] HPCC: high precision congestion control
[14] PicNIC: Predictable Virtualized NIC, SIGCOMM 2019





