

*本文系SDNLAB编译自瞻博网络技术专家兼高级工程总监Sharada Yeluri领英
在路由器和交换机中,缓冲区至关重要,可以防止网络拥塞期间的数据丢失。缓冲区到底要多大?这个问题在学术界和工业界一直备受争议。本文探讨了高端路由器中数据包缓冲的历史和演变,以期概述当前的实践和未来的趋势。
网络芯片中的缓冲区
在典型的路由器/交换机 ASIC 中,会发现三种类型的数据包缓冲区。
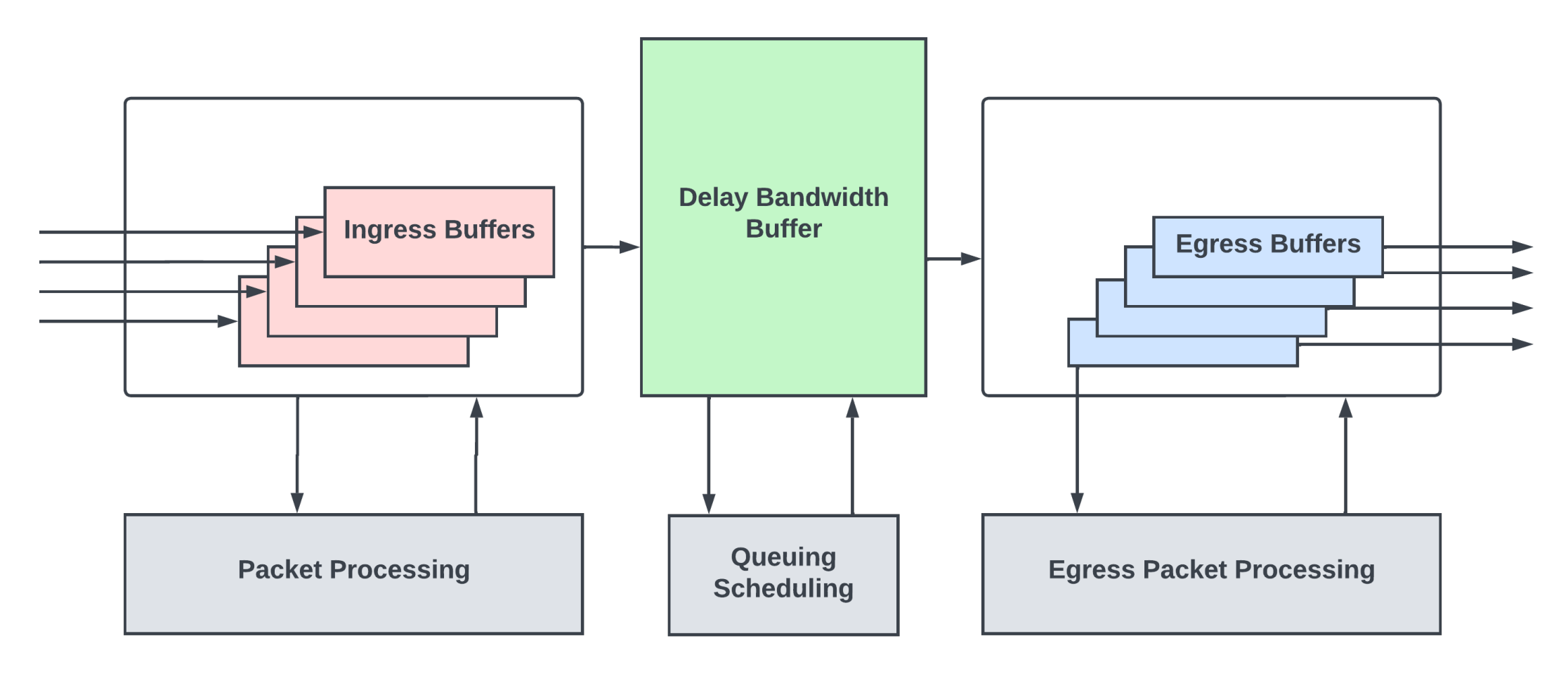
入口缓冲区
入口缓冲区保存来自输入链路的传入数据包,而数据包头(通常是数据包的前128-256 字节)由数据包处理逻辑处理。该处理逻辑检查数据包头中的各种协议头来计算下一跳。然后为数据包分配出口队列/优先级,并确定数据包必须从哪个出口输出链路转发出去。
数据包在入口缓冲区中驻留一段时间,直到处理完成。在固定的pipeline架构中,数据包处理延迟约为 1-2 微秒。确定入口缓冲区的大小是为了在处理数据包头时保存数据包内容。
网络芯片性能的衡量标准是在不丢失数据包的情况下,每秒按线路速率可以处理多少比特的流量,以及满足该速率的最小数据包的大小。尽管以太网链路上 IP 数据包最小可低至 64 字节,但许多网络芯片都会考虑到典型的网络负载,并设计数据包处理pipeline以满足远大于 64字节的数据包性能要求,有效地减少了每秒通过芯片的数据包数量。这样做可以优化数据包处理逻辑,以节省芯片的面积和功耗。
虽然典型工作负载的平均数据包大于 350字节,但可能会出现小数据包的瞬时突发(通常是保持网络活动的控制数据包或 TCP 协议的 syn/ack 数据包),这可能超额订阅数据包处理逻辑,因为它们不是为处理如此高的每秒数据包转发而设计的。
在网络芯片中,“超额订阅(oversubscription)”意味着资源/逻辑所承受的负载超出了其处理能力。在数据包处理超额订阅的瞬时期间,入口缓冲区会吸收数据包突发。当缓冲区已满时,它们会进行优先级感知丢弃。
延迟带宽缓冲区 (DBB)
在完成数据包处理并确定下一跳后,数据包一般会进入一个深度缓冲区,通常称为延迟带宽缓冲区(DBB)。当路由器的部分/全部输出链路被超额订阅,该缓冲区将在网络瞬时拥塞期间提供缓冲。
当流经网络的流量超过网络的最大容量时,就会发生网络拥塞。造成拥堵的原因有很多:
- 为了降低系统成本,网络中可能会存在故意的超额订阅。当某些用户使用的带宽超过平均分配的带宽,就会导致拥塞;
- 当多个主机开始相互通信时,多播/广播流量也可能导致拥塞;
- 当端点上的某些接口出现故障时,需要将流量分配到剩余的接口,这可能会导致上游网络设备拥塞;
- 用户错误,如网络配置错误,也可能会导致拥塞;
- 由于应用程序和用户流量的突发性,某些路由器/交换机也可能会出现流量超过其链路容量的情况。
在拥塞期间,路由器可能会发现其部分/全部输出链路被超额订阅。在极端拥塞的情况下,所有输入流量可能都希望通过单个输出离开。在路由器芯片中设置数据包缓冲区吸收瞬时拥塞,有助于整体网络的健康和吞吐量。
出口缓冲区
在网络拥塞期间,路由器需要确保高优先级流量和其他控制流量不会出现丢包,并且需要满足不同优先级下不同用户的服务质量(QoS)。路由器/高端交换机具有复杂的排队和调度子系统,可以在DBB内针对不同的流维护不同的队列。调度程序以不超过该接口链路容量的速率,将流量从这些缓冲区分发到输出端口接口处的浅出口缓冲区。这些出口缓冲区的大小正好足以掩盖DBB到输出接口之间的往返时延,以便流量可以从输出接口流出,而不会出现突发情况。
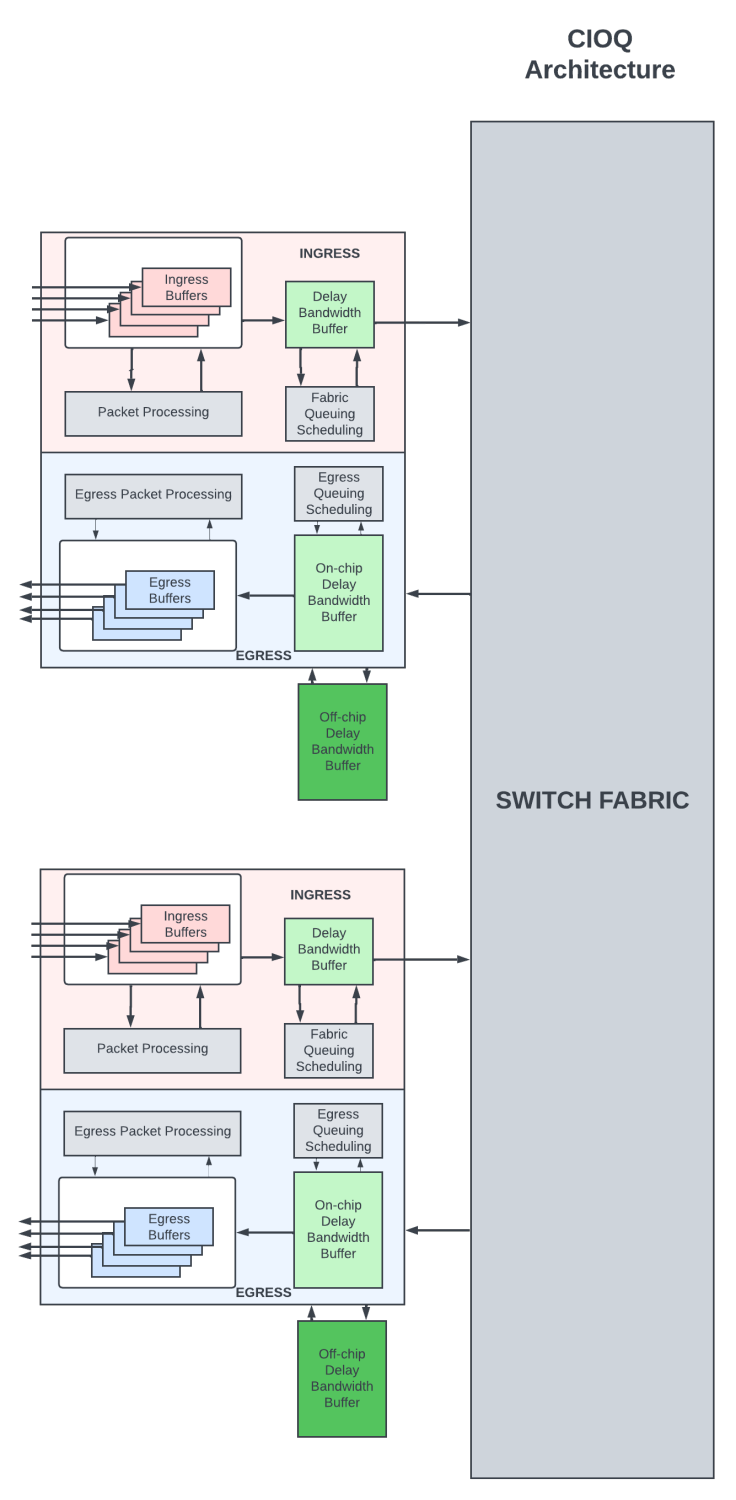
可以使用通过交换fabric互连的多个模块化路由芯片来构建大型路由器。下面将使用PFE来指代这些模块化路由芯片。
在组合输入/输出 (CIOQ) 架构中,数据包在入口 PFE 和出口 PFE上都有缓冲。如果路由器内出现短暂拥塞,浅入口延迟带宽缓冲区会保留数据包,从而通过交换fabric将数据包从入口移动到出口。出口 PFE 处的DBB是深度缓冲区,在网络拥塞期间,数据包在其中排队较长时间。
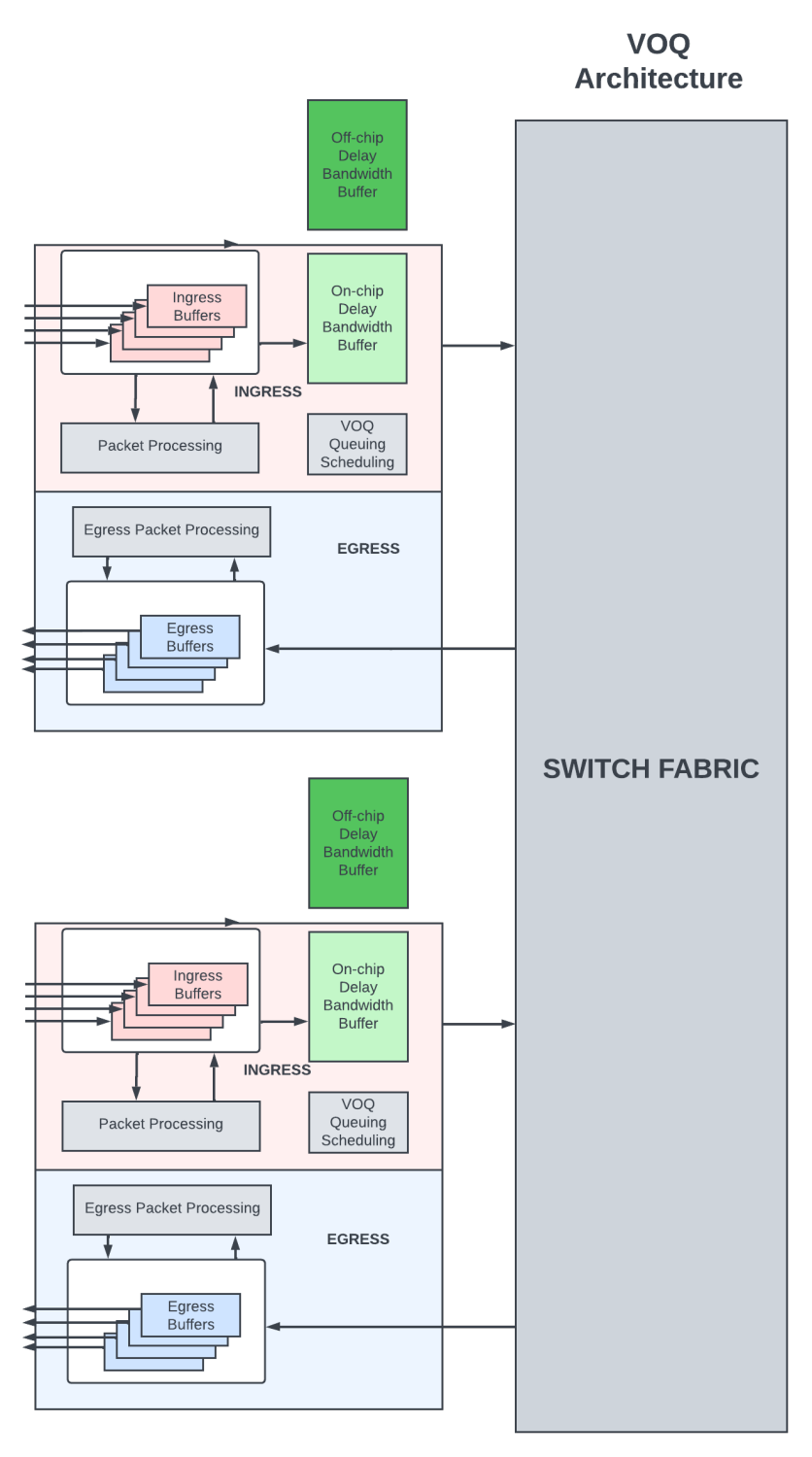
在虚拟输出队列 (VOQ) 架构中,所有延迟带宽缓冲都在入口 PFE 中完成。在这里,数据包在入口 PFE 的虚拟输出队列中排队。VOQ 唯一对应于数据包需要离开的最终 PFE/输出链路/输出队列。数据包通过出口处的复杂调度程序从入口 PFE 移动到出口 PFE,只有在能够将数据包调度出输出链路时,该调度器才会从入口 PFE 接受数据包。在 VOQ 架构中,发往输出队列的数据包可在 VOQ 中的多个入口 PFE 中进行缓冲。
调整数据包缓冲区的大小
两大阵营
当谈到交换机和路由器的数据包缓冲区大小时,存在着持有不同观点的两大阵营:
- 以学者为首的阵营认为,缓冲区总体来说是臃肿的;
- 数据中心 (DC) 网络运营商则要求提供充足的缓冲,以避免通过其路由器/交换机的任何流出现数据包丢失,特别是高度分布式的云/数据挖掘应用。
在大数据应用中,数百台处理查询的服务器可能会向单个服务器发送大量流量,该服务器汇总所有流的响应,这可能会导致持续数十毫秒的短暂拥塞情况。但重要的是,流量不能丢失!
DC内的存储应用对丢包也非常敏感。一般来说,现代数据中心的流量是双峰的,由短期、低速率的“老鼠”流和长期、高速率的“大象”流组成。大多数流是老鼠流,但它们仅承载10-15%的数据流量负载。剩余90%的流量负载由少量大象流承载。大象流对应于大数据传输,需要高吞吐量,例如备份。老鼠流对延迟敏感,由查询和控制消息组成,并且需要最少的数据包丢失,以避免整体应用程序性能下降。DC 运营商更喜欢更大的缓冲区,以避免老鼠流的数据包丢失,因为许多传统交换机不支持动态区分队列中的老鼠流和大象流。
互联网服务提供商在缓冲方面有不同的要求,因为其路由器的重点是尽快交换大量数据,并满足视频/语音呼叫等高优先级流量的服务级别协议(SLA),他们倾向于尽可能地利用昂贵/高容量的 WAN 链路,以降低设备成本。但链路使用越频繁,丢包的可能性就越大。因此,互联网服务提供商也要求路由器中有足够的缓冲,以区分可以容忍数据包丢失的尽力而为的流量和必须以接近零流量丢失方式传送的高优先级流量。
在过去的二十年中,缓冲区大小一直是个热门话题。随着路由芯片带宽的增长,内存的扩展程度却无法跟上,提供大量缓冲变得越来越昂贵。
无论是何种应用(交换/路由),整个行业的趋势都是在不影响 QoS 的情况下尽可能减少缓冲。这在很大程度上依赖流量工程、先进的端到端拥塞控制算法和主动队列管理 (AQM) 来提前向端点通知拥塞情况,并通过较小的延迟带宽缓冲区来保持链路饱和。
拥塞控制算法
拥塞控制算法使用的协议是闭环的,其中接收方将收到的数据包信息发送给发送方。TCP/IP 就是这种流行的协议套件。TCP 是一种面向连接的协议。在数据传输之前,需要在发送方和接收方之间建立连接。TCP 从应用层的数据流接收数据,将其划分为块,并添加 TCP报头以创建 TCP 段。然后,TCP 段被封装到 IP 数据报中,并通过网络传输到端点。
TCP 报头包含许多字段,有助于建立和维护连接,并检测丢失的段以进行重传和拥塞控制。其中一个字段是序列号字段。TCP 使用递增的序列号标记数据流的每个字节。当发送一个报文段时,它发送该报文段中数据第一个字节的序列号。接收方使用序列号将无序接收的 TCP 段组合在一起。对于接收到的每个数据段,接收方都会发送一个确认 ( ACK ),表示它期望从发送方收到的下一个数据段。ACK丢失则表示网络中出现数据包丢失或网络拥塞。发送方使用此信息来降低传输速率,并重新传输丢失的段。
自 TCP/IP 诞生以来,已经开发出许多的拥塞控制算法,帮助端点在拥塞期间调节进入网络的数据传输速率。这些算法依赖于更改拥塞窗口大小,即发送方在不等待网络拥塞确认的情况下即可发送的 TCP 段数量。
往返时间 (RTT)
了解往返时间对确定缓冲区大小和开发拥塞控制算法至关重要。RTT 是数据包从发送方传输到接收方以及将确认返回发送方所需的往返时间。RTT 变化很大,具体取决于端点的位置以及路径中网络设备的拥塞程度。

TCP 流的端点使用拥塞避免模式和Slow_start(慢开始)避免拥塞。
发送方一开始并不清楚网络的负荷情况,如果立即把大量数据直接注入到网络,很有可能会引起网络拥塞。所以可以由小到大逐渐增大发送的拥塞窗口值。通常一开始发送分段时,先把拥塞窗口设置为一个MSS(最大传输分段)值,收到ACK后拥塞窗口加一个分段大小,此时可以发出两个分段数据,收到两个ACK后拥塞窗口又加二,这样一轮一轮下去拥塞窗口呈指数增长,直到窗口大小达到阈值。
此时,进入拥塞避免阶段。拥塞窗口大小对每个 RTT 线性增加一个 MSS,使得每一轮不再增加一倍,而是增加一个MSS。 在此阶段,如果通过丢包检测到拥塞,则发送方将拥塞窗口减半(传输速率减半)并重新开始。
主动队列管理(AQM)
如果路由器等到其DBB满了后才丢弃数据包,那么在发送方对丢包做出反应之前,网络内将有更多的流量进入已经满的队列,导致大量的尾部丢弃(Tail-Drop)。几乎所有具有深度数据包缓冲区的交换机/路由器都支持加权随机早期丢弃 (WRED),以便尽早向发送方通知拥塞情况。WRED 通过使用 WRED 曲线在队列满之前概率性地丢弃数据包,防止队列完全填满。
一些路由器和 DC 交换机还支持显式拥塞通知 (ECN)。在 ECN 中,当路由器经历拥塞时,它可能会将某些数据包标记为“经历拥塞”并按原样转发它们。IP 报头的流分类字段用于 ECN 标记。当端点收到这些设置了 ECN 位的数据包时,它们会在发送ACK的同时将拥塞情况反馈给发送方。发送方通过这些信息来降低网络传输速率。
ECN 有助于减少拥塞,且不会造成与 WRED 相关的数据包丢失,但它也有一些局限性。如果网络丢包率较高,ECN可能无法正常工作,因为标记的数据包也可能丢失,拥塞信息无法准确传达。此外,如果不同的 ECN 实现使用不同的标记算法或对拥塞的响应不同,则可能存在互操作性问题。
一些供应商集成了先进的 AQM 技术,可以实现流量感知的早期丢弃,例如区分队列中的老鼠流和大象流(基于输入流量速率),并通过动态调整不同流的队列长度来防止老鼠流被丢弃。
缓冲区大小
确定路由器 ASIC 内部延迟带宽缓冲区大小的关键是确保当发送方因网络拥塞而暂停或减少进入网络的流量时,缓冲区不会变空。当发送方因拥塞而减小窗口大小时,缓冲区充当一个储存库,以保持链路繁忙。如果缓冲区变空,则路由器的输出链路没有得到充分利用。
经验法则
过去比较流行的规则是,一个总端口速度为C(以每秒比特为单位)的路由器,承载往返时间为RTT的流量,就需要一个相当于RTT * C的缓冲区以保持其输出链路繁忙。这称为延迟带宽积 (DBP) 或带宽延迟积 (BDP)。该规则在早期路由器中广泛使用,当时路由器的总容量小于每秒几百吉比特。
例如,在Juniper配备paradise芯片组的第一代PTX路由器中,具有 400Gbps 端口密度的 PFE 在外部存储器中提供了 4GB的数据包缓冲。这可以覆盖 80ms的 RTT ,可以满足大多数核心路由器应用。
这种根据DBP调整缓冲区大小的模型适用于两个端点之间的一些长期TCP 流,以及遇到瓶颈的单个路由器。
局限性
上述缓冲区大小的经验法则不能很好地应用到当前具有每秒TB级聚合端口带宽的路由器。例如,具有 100 毫秒 RTT 的 14.4Tbps 路由芯片将需要 144GB 的延迟带宽缓冲,这是一个非常大的缓冲区,需要放在片上或外部存储器中。
如今,HBM 存储器因其高密度和带宽被广泛用于数据包缓冲。下一代HBM3可以提供每个部件24GB的总容量。要实现 144Gb 的数据包缓冲,需要 6 个 HBM3 部件。即使使用最大reticle-sized芯片,也很难在芯片边缘为6个 HBM3 接口腾出空间,因为大多数边缘将被高速WAN链路所需的 Serdes 占用。因此,路由器芯片必须在端口密度和提供的延迟带宽缓冲之间做出权衡。
更新的理论
路由器通常承载数千个数据流,每个流的 RTT 差异很大(这些流的端点可能不同),并且这些流很少同步。缓冲区大小的经验法则不适用于这些情况。在多流量情况下,关于缓冲区大小有着不同的研究。
斯坦福大学研究人员于 2004 年发表的 SIGGCOM 论文声称,对于N 个长期存在的非同步流,只需C*RTT(min)/sqrt(N)的缓冲区即可保持链路繁忙。这意味着长期流越多,缓冲就越少。例如,当 10000 个长期流通过 14.4Tb路由器时,只需要 1.44GB 的延迟带宽缓冲区。这完全可以通过片上和外部存储器的组合来实现。作者还得出结论,在短期流(仍处于Slow_start阶段时结束的流)或非 TCP 流中,延迟带宽缓冲区的大小与路由器链路上的负载和流的长度成正比,并且小于C * RTT_min/sqrt(N)。
随后,其他研究人员也发现,缓冲区大小取决于输出/输入容量比以及链路的饱和度。例如,如果数据中心运营商能够通过在scale-out 架构中添加更多交换机来运行未充分利用的链路,那么这些芯片中的缓冲要求可能会下降。
尽管这些论文发表于几十年前,但服务提供商和网络芯片供应商还没有准备好减少设备中的缓冲。直到最近几年,当内存不再随着工艺节点的进步而扩展时,他们别无选择。厂商们犹豫不决的原因是很难确定N 的值,该值在时间间隔内变化很大,具体取决于客户流量和运行在这些路由器上的应用。
学术论文通常没有考虑到现实的流量场景,大多数论文还认为短暂的数据包丢失或链路未充分利用是可接受的行为。但事实是,许多应用程序在丢包的情况下无法正常运行。这些应用需要更大的缓冲区(大约数十毫秒),以在拥塞期间缓冲对丢失敏感的流量。因此,确定缓冲区的大小是一个复杂的决定,一个公式并不适合所有的应用!
现代路由器和超额订阅缓冲区
正如上文中提到的,高端路由芯片供应商面临着一个艰难的选择,即在芯片/封装内的交换和缓冲能力之间进行权衡。
它们可以完全依赖片上 SRAM 进行延迟带宽缓冲。但是,片上 SRAM 的扩展跟不上工艺节点的进步。例如,在先进的 3nm 工艺中,256MB的存储器和控制器可以占据reticle-sized 芯片的 15-20%。在 7.2Tbps 流量下,这相当于大约 35 微秒的 DBB。数据中心的高带宽交换机大多数流量的 RTT 小于 50 微秒。
对于支持数千个具有不同QoS属性和RTT(几十毫秒)的队列以及频繁发生瞬时拥塞事件的高带宽路由芯片来说,50微秒是行不通的。这些路由芯片有两种选择:
他们可以完全依赖 HBM 等外部存储器来进行延迟带宽缓冲。但是,如果每个数据包都需要往返于 HBM,对于 14.4Tbps 的路由芯片来说,将需要足够的 HBM 接口来支持 14.4Tbps 的读写带宽。从核心芯片到 HBM 部件,很难提供如此多的 HBM 接口,同样也不可能将如此多的 HBM 部件封装在 2.5D 封装中。此外,外部存储器延迟很大,会显着增加通过路由器的排队延迟。
因此,许多高端路由 ASIC 开始使用混合缓冲方法,其中延迟带宽缓冲分布在片上和外部存储器之间。数据包在各自队列中的片上延迟带宽缓冲区中进行缓冲。排队子系统监视每个队列的队列长度。当队列超过可配置阈值时,到达该队列的新数据包将被发送到外部存储器。随着数据包从队列中脱离,并且当队列不再拥塞,到达率低于出队率,队列长度将减少。当队列长度低于片上阈值时,该队列的新数据包将保留在片上存储器。该架构仅提供总带宽的一小部分用于外部存储器,从而减少了芯片的外部存储器接口的数量。
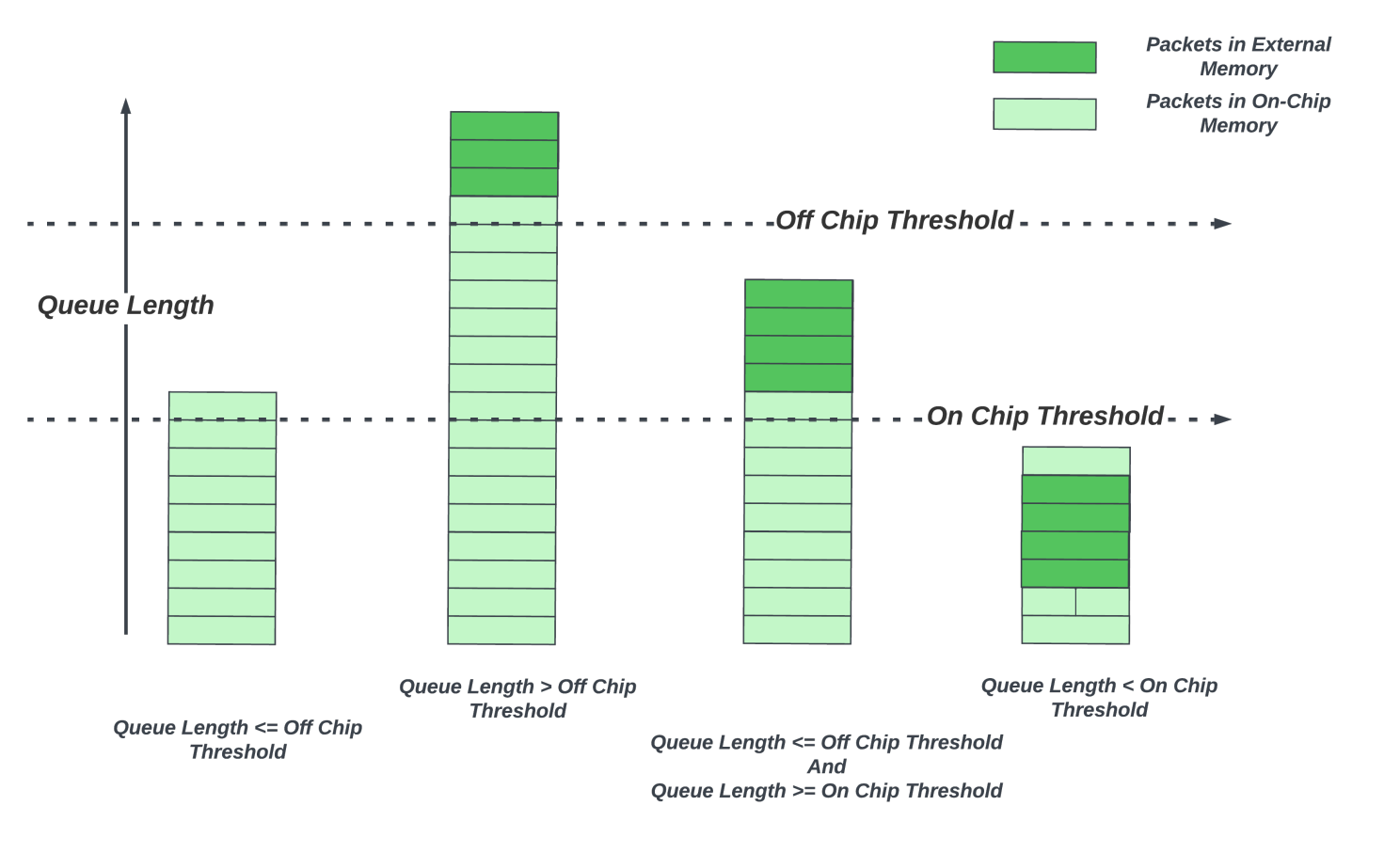
尽管可能有成千上万个流量流经路由器,但先进的拥塞控制算法和更智能的网络管理可以让网络流量均匀分布,因此许多流量不会出现持续拥塞的情况。小规模的瞬时拥塞事件可以仅由片上缓冲器吸收。只有一小部分队列会出现持续拥堵。随着这些队列的增长,它们可以从深度缓冲区中受益。
带宽为 6.5Tbps 的下一代 24GByte HBM3 部件可为约 2.5Tbps 的输出链路提供约 70 毫秒的延迟带宽缓冲。假设在任何时间点拥塞的流量不超过 25%,那么对于 10Tbps 路由 ASIC 来说,一个外部存储器就足够了。
构建混合缓冲系统
想在路由芯片中构建一个混合缓冲子系统,使其能够有效地利用片上和外部存储器延迟带宽缓冲并满足所有的 QoS 要求,还存在着许多挑战。
共享片上内存
一个理想的状态是让所有输入和输出链路完全共享延迟带宽缓冲内存的片上部分,因为可能会存在拥塞情况,即来自所有输入端口的数据包可能希望从某几个输出端口离开。在这些情况下,最好让这些队列占用大部分缓冲区以避免数据包丢失。
对于具有 144 个 100G 端口的 14.4Tbps 路由器来说,同时访问所有这些端口的共享延迟带宽缓冲区是一项挑战。许多高端架构使用了两种技术让这种缓冲设计更加可行。使用宽数据总线(wide data buses)允许来自多个 100G 端口的数据包共享到共享缓冲区的同一宽接口。共享缓冲区本身被静态地划分为许多存储区,数据包被分成更小的块,并喷洒(spray)到这些存储区中,以在多个存储区上分配读/写。但这样做有一个副作用,同一数据包的不同块从这些存储区中乱序写入和读取。缓冲区外部的控制逻辑需要将这些事务按顺序排列,然后再呈现给下游区块。
一些供应商进一步采用中央共享缓冲区方法,在延迟带宽缓冲区和出口缓冲区之间共享同一组片上存储器。这允许针对芯片的不同用例灵活地划分内存。
外部内存超额订阅管理
对于超额订阅的外部存储器,需要复杂的算法来决定队列何时移动到片外延迟带宽缓冲区。可以给每个输出队列分配一个配置文件,该配置文件告诉队列在移动到外部存储器之前可以在片上填充多少。
但是,如果算法仅根据每个输出队列的队列长度做出独立决策,那么在多个输出链路极度拥塞时,它可能会决定将传入流量的很大一部分发送到片外,而外部存储器接口不一定可以处理。这给缓冲区管理逻辑增加了额外的复杂性,需要仔细规划跨拥塞队列的片外移动。
跨队列分配片上缓冲区
在业务边缘应用程序中,在给定的时间间隔内可能有数千个活动流。由于片上缓冲有限,不可能提供相同的队列阈值。这些芯片架构必须为网络运营商提供灵活性,以便为他们配置的每个队列选择“配置文件”。但是,通过配置队列的实际流量可能与预配置速率有很大差异,这会导致缓冲区空间和资源的使用效率低下。
高级架构在基于实时队列耗尽率动态调整混合队列长度和片外阈值的算法上投入了大量资金,以有效地利用延迟带宽缓冲区。一些供应商还实现了高级算法来动态区分大象流和老鼠流,并通过调整这些流的缓冲区分配来防止老鼠流丢弃数据包。
数据包抖动
路由器不得对流内的数据包重新排序。但是,如果队列在片内和外部存储器之间移动,由于从外部存储器读取时会产生数百个周期的额外延迟,因此需要额外的逻辑来从外部存储器预取内容并保持数据包之间的顺序要求。该预取向出口缓冲区添加了额外的缓冲区。
尽管实施过程中面临着一定挑战,但在当前工艺节点/存储器和封装技术下,混合缓冲可能是唯一适用于高容量路由芯片的方法。高端路由芯片供应商正不断投资高级算法,以有效利用芯片上有限的内存资源和有限的外部存储器带宽。
未来
在芯片方面,随着 3D 封装的发展,可以将多个芯片(逻辑芯片和存储芯片的混合)堆叠在一起。当存储器芯片层堆叠在逻辑芯片上时,逻辑芯片可从存储器获得更高的数据吞吐量,因为存储器到逻辑芯片的互连可以使用芯片的整个表面区域。目前,该技术主要应用于针对HPC的CPU芯片。用不了多久,高端网络芯片供应商将使用这项技术来增加带宽和延迟带宽缓冲区的容量,以跟上核心内聚合的端口容量的增加。
在拥塞控制方面,过去几十年内取得了许多进展,迄今为止已有 20 多种拥塞控制和主动队列管理 (AQM) 算法。
基于延迟的算法,即发送者通过密切监视流量的往返延迟来调制进入网络的流量,变得越来越流行。FQ-CoDel/PIE 是两种针对缓冲区膨胀的 AQM 算法。由谷歌开发的TCP BBRv2实时构建网络模型,动态调整发送速率。与传统的基于数据包丢失的算法产生的突发相比,这些算法还可以更均匀地调配带宽,并有助于缓解大型网络中的拥塞。
学术界和工业界正在不断努力提高具有不同流量的大型网络中的拥塞控制算法的性能、效率和公平性。基于机器学习的网络模型也正在开发中,该模型可以学习实时拥塞情况。任何由端点持续缓解的拥塞都可以减少路由器中的缓冲区要求。
因此,随着混合缓冲和主动队列管理技术的进步、高端的3D封装技术以及拥塞控制算法的改进,即使高端路由芯片的带宽每2到3年翻一番,也不需要在缓存上做出取舍。
微信搜索SDNLAB公众号后台回复20240201,获取文中提及论文下载链接
参考
Sizing router buffers by Guido Appenzeller,作者:Guido Appenzeller、Isaac Keslassy 和 Nick McKeown - ACM SIGGCOM 2004
Updating the Theory of Buffer Sizing by Bruce Spang,作者:Bruce Spang、Serhat Arslan 和 Nick Mckeown








