

AI、元宇宙、大模型……每一个火爆名词的背后都代表着巨大的算力需求。据了解,AI模型所需的算力每100天就要翻一倍,远超摩尔定律的18-24个月。5年后,AI所需的算力规模将是今天的100万倍以上。
在这种背景下,加速计算提供了必要的计算能力和内存,其解决方案涉及硬件、软件和网络的组合。接下来,我们将回顾和梳理常见的硬件加速器,如GPU、ASIC、TPU、FPGA等,以及如CUDA、OpenCL等软件解决方案。此外,还将探讨PCIe、NVLink、CXL、InfiniBand、以太网等网络互联技术。
硬件、软件和网络互联
摩尔定律的终结标志着 CPU 性能增长的放缓,人们开始对当前价值 1 万亿美元的纯 CPU 服务器市场的未来发展产生质疑。随着对更强大的应用程序和系统的需求不断增加,传统的 CPU 难以与加速计算竞争。与传统CPU相比,加速计算利用 GPU、ASIC、TPU 和 FPGA 等专用硬件来加速某些任务的执行。
加速计算适用于可并行化的任务,如HPC、AI/ML、深度学习和大数据分析等。通过将某些类型的工作负载卸载到专用硬件设备上,加速计算可极大提高性能和效率。
硬件加速器
硬件加速器是加速计算的基础,包括图形处理单元 (GPU)、专用集成电路 (ASIC) 和现场可编程门阵列 (FPGA)。
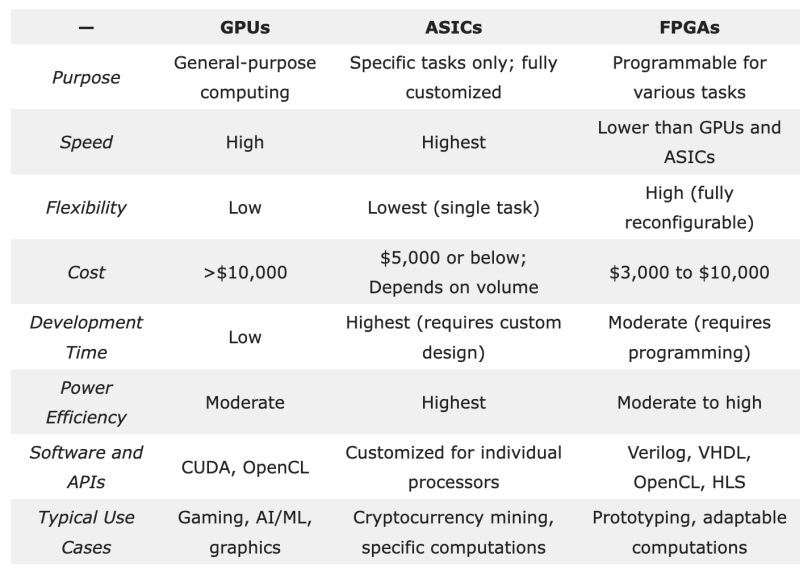
GPU广泛应用于各种计算密集型任务,擅长同时执行许多复杂的计算,并行计算能力使其成为处理复杂数据集和大规模神经网络训练的理想选择。
ASIC是为执行特定任务而设计的定制芯片,在速度、功耗和整体性能方面具有一定优势。神经处理单元 (NPU) 和深度学习处理器 (DLP) 也属于ASIC,旨在加速 AI 工作负载。谷歌的的张量处理单元 (TPU)也是ASIC家族的一员,专为加速机器学习工作负载而设计。
FPGA是一种半导体集成电路,与通用 CPU 相比,FPGA可以重新编程,更有效地执行特定任务。与 ASIC、GPU 和 CPU 中的固定架构不同,FPGA 硬件包括可配置逻辑块和可编程互连。这样就算在芯片发货和部署后,也可以进行功能更新。
尽管FPGA因其灵活性在HPC和AI/ML领域备受青睐,但与GPU和专用ASIC相比,其开发速度较慢,软件生态系统也相对不够完善。由于其编程复杂性,FPGA 在人工智能工作负载中的采用较为缓慢,专业工程师的数量也有限。
软件
加速计算利用API 和编程模型(如CUDA和OpenCL)将软件和硬件加速器连接,API 和编程模型使开发人员能够编写在 GPU 上运行的代码,并利用软件库来高效实现算法。
CUDA(统一计算架构)是英伟达开发的专有 GPU 编程框架,与英伟达的 GPU 紧密集成,充分利用了 GPU 的并行计算能力和专用硬件优化。CUDA 提供了更底层的编程接口,允许开发人员直接访问 GPU 的内部特性和功能。
CUDA 的生态系统主要集中在英伟达的 GPU 上,由于其专用硬件优化和与 GPU 的紧密集成,可以提供更高的性能。英伟达还提供了丰富的开发工具和库,使得 CUDA 在深度学习、科学计算等领域得到广泛应用。
OpenCL(开放计算语言)是一个开放的、跨平台的编程框架,由 Khronos Group 组织开发和维护。它的设计目标是支持各种硬件平台,包括不仅限于 GPU 的处理器单元,如 CPU、FPGA 等。OpenCL 使用基于 C 语言的编程模型,允许开发人员利用各种设备上的并行计算能力。
OpenCL 拥有更广泛的硬件支持,包括多个厂商的 GPU、CPU 以及其他加速设备。这意味着开发人员可以在不同的硬件平台上使用相同的代码进行开发,并且能够更灵活地适应不同的需求。
OpenCL和CUDA都是强大的GPU加速计算框架,CUDA在与英伟达GPU的紧密结合下提供了更高性能,适用于专注于英伟达平台开发者;而OpenCL具有跨平台兼容性和多厂商支持的优势,适用于需要在不同硬件平台上进行开发的场景。
网络互联
网络在加速计算中发挥着至关重要的作用,它促进了数以万计的处理单元(例如 GPU、内存和存储设备)之间的通信。各种网络技术被用来实现计算设备之间的通信,多个设备之间共享数据。常见的技术包括:
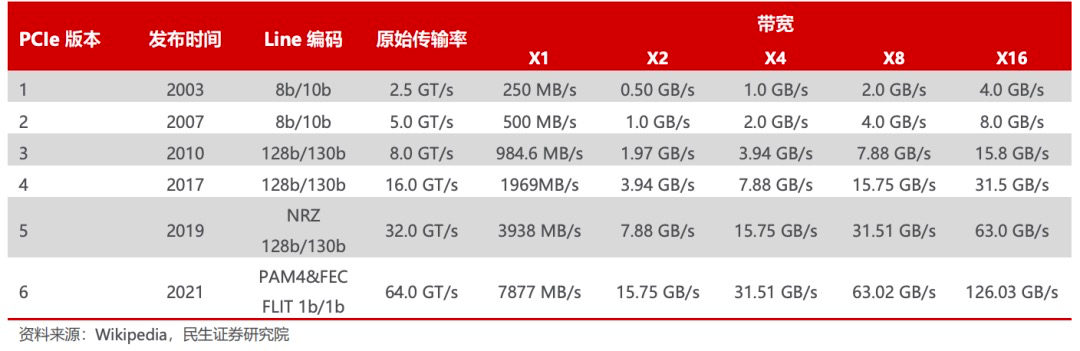
PCI Express (PCIe)是一种高速串行计算机扩展总线标准,主要用于连接CPU与各类高速外围设备,如GPU、SSD、网卡、显卡等。与传统的PCI总线相比,PCIe采用点对点连接方式,具有更高的性能和可扩展性。伴随着AI、自动驾驶、AR/VR等应用快速发展,计算要求愈来愈高,处理器I/O带宽的需求每三年实现翻番,PCIe也大致按照3年一代的速度更新演进,每一代升级几乎能够实现传输速率的翻倍,并有着良好的向后兼容性。

2003 年PCIe 1.0 正式发布,可支持每通道传输速率为 250MB/s,总传输速率为 2.5 GT/s。
2007 年推出PCIe 2.0 规范。在 PCIe 1.0 的基础上将总传输速率提高了一倍,达到 5 GT/s,每通道传输速率从 250 MB/s 上升至 500 MB/s。
2022 年 PCIe 6.0 规范正式发布,总带宽提高至 64 GT/s。
2022年6月,PCI-SIG联盟宣布PCIe 7.0版规范,单条通道(x1)单向可实现128GT/s传输速率,计划于2025年推出最终版本。
NVLink 是英伟达开发的高速互连技术,旨在加快 CPU 与 GPU、GPU 与 GPU 之间的数据传输速度,提高系统性能。NVLink通过GPU之间的直接互联,可扩展服务器内的多GPU I/O,相较于传统PCIe总线可提供更高效、低延迟的互联解决方案。

NVLink的首个版本于2014年发布,首次引入了高速GPU互连。2016年发布的P100搭载了第一代NVLink,提供 160GB/s 的带宽,相当于当时 PCIe 3.0 x16 带宽的 5 倍。V100搭载的NVLink2将带宽提升到300GB/s ,A100搭载了NVLink3带宽为600GB/s。目前NVLink已迭代至第四代,可为多GPU系统配置提供高于以往1.5倍的带宽以及更强的可扩展性,H100中包含18条第四代NVLink链路,总带宽达到900 GB/s,是PCIe 5.0带宽的7倍。

Infinity Fabric是AMD 开发的高速互连技术,被用于连接AMD处理器内部的各个核心、缓存和其他组件,以实现高效的数据传输和通信。Infinity Fabric采用了一种分布式架构,其中包含多个独立的通道,每个通道都可以进行双向数据传输。这种设计使得不同核心之间可以直接进行快速而低延迟的通信,从而提高了整体性能。此外,Infinity Fabric还具备可扩展性和灵活性。它允许在不同芯片之间建立连接,并支持将多颗处理器组合成更强大的系统。
Compute Express Link (CXL)是一种开放式行业标准互连,可在主机处理器与加速器、内存缓冲区和智能 I/O 设备等设备之间提供高带宽、低延迟连接,从而满足高性能异构计算的要求,并且其维护CPU内存空间和连接设备内存之间的一致性。CXL优势主要体现在极高兼容性和内存一致性两方面上。

CXL 3.0是2022年8月份发布的标准,在许多方面都进行了较大的革新。CXL3.0建立在PCI-Express 6.0之上(CXL1.0/1.1和2.0版本建立在PCIe5.0之上),其带宽提升了两倍,并且其将一些复杂的标准设计简单化,确保了易用性。
InfiniBand是一种高速、低延迟互连技术,由 IBTA(InfiniBand Trade Association)提出,其规定了一整套完整的链路层到传输层(非传统OSI七层模型的传输层,而是位于其之上)规范,但是其无法兼容现有以太网。InfiniBand拥有高吞吐量和低延迟,扩展性好,通过交换机在节点间的点对点通道进行数据传输,通道私有且受保护。
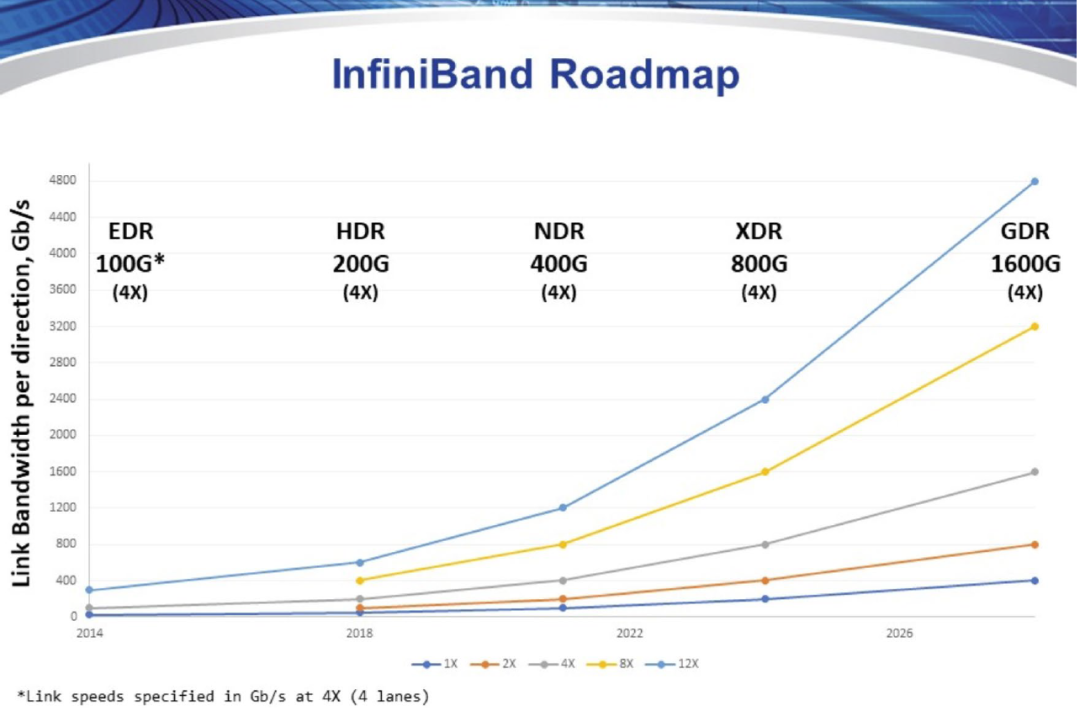
目前InfiniBand的传输速度为400Gb/s,路线图显示,IBTA计划于2024年推出XDR 800Gb/s InfiniBand产品,并在2026年后推出GDR 1600Gb/s产品。InfiniBand的高传输速度打通高性能计算中数据传输速率瓶颈,提升吞吐量和计算效率。
以太网是应用最广泛最成熟的网络技术,可在数据中心的服务器之间传输大量数据,这对于许多加速计算任务至关重要。RoCE协议下,以太网融合RDMA功能,在高性能计算场景下的通信性能大幅提升。今年,为应对AI 和HPC工作负载提出的新挑战,网络巨头联合成立了超以太网联盟(UEC),超以太网解决方案堆栈将利用以太网的普遍性和灵活性处理各种工作负载,同时具有可扩展性和成本效益,为以太网注入了新的活力。
加速计算为传统CPU和日益增长的数据需求之间搭起了一座桥梁,从数据中心到边缘计算,加速计算已广泛应用于各种领域。英伟达创始人黄仁勋曾表示,计算已经发生了根本性的变化,CPU扩展的时代已结束,购买再多的CPU已无法解决问题。加速计算将与AI一起推动,新计算时代“引爆点”已到来。







