

本文编译自arthurchiao的博客,主要介绍了英伟达和华为/海思主流 GPU 的型号性能,供个人参考使用,文中使用数据均源自官网。
英伟达GPU L2/T4/A10/A10G/V100对比:

英伟达A100/A800/H100/H800/华为Ascend 910B对比:
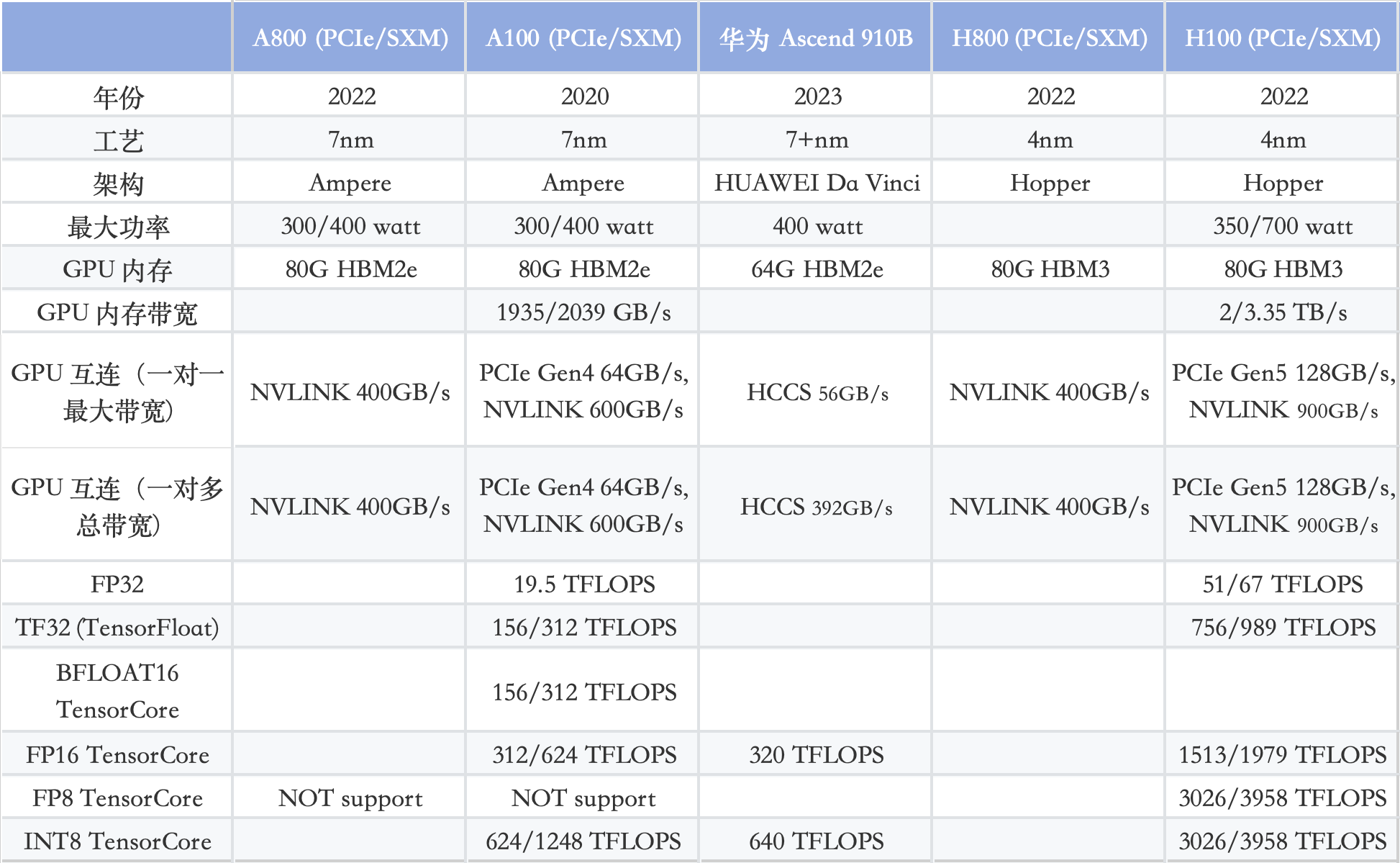
一句话总结,H100 vs. A100:3 倍性能,2 倍价格
值得注意的是,HCCS vs. NVLINK的GPU 间带宽。
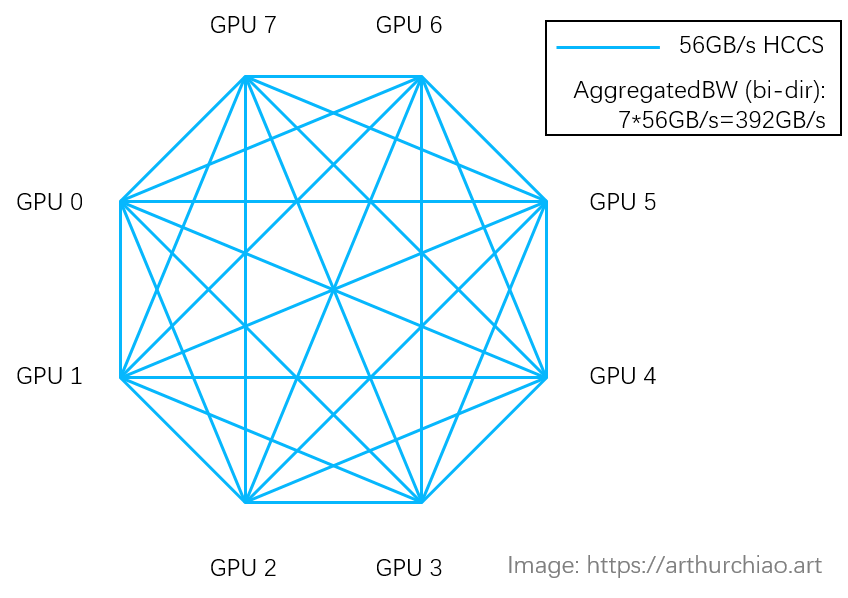
对于 8 卡 A800 和 910B 模块而言,910B HCCS 的总带宽为392GB/s,与 A800 NVLink (400GB/s) 相当。然而,两者之间也存在一些区别。
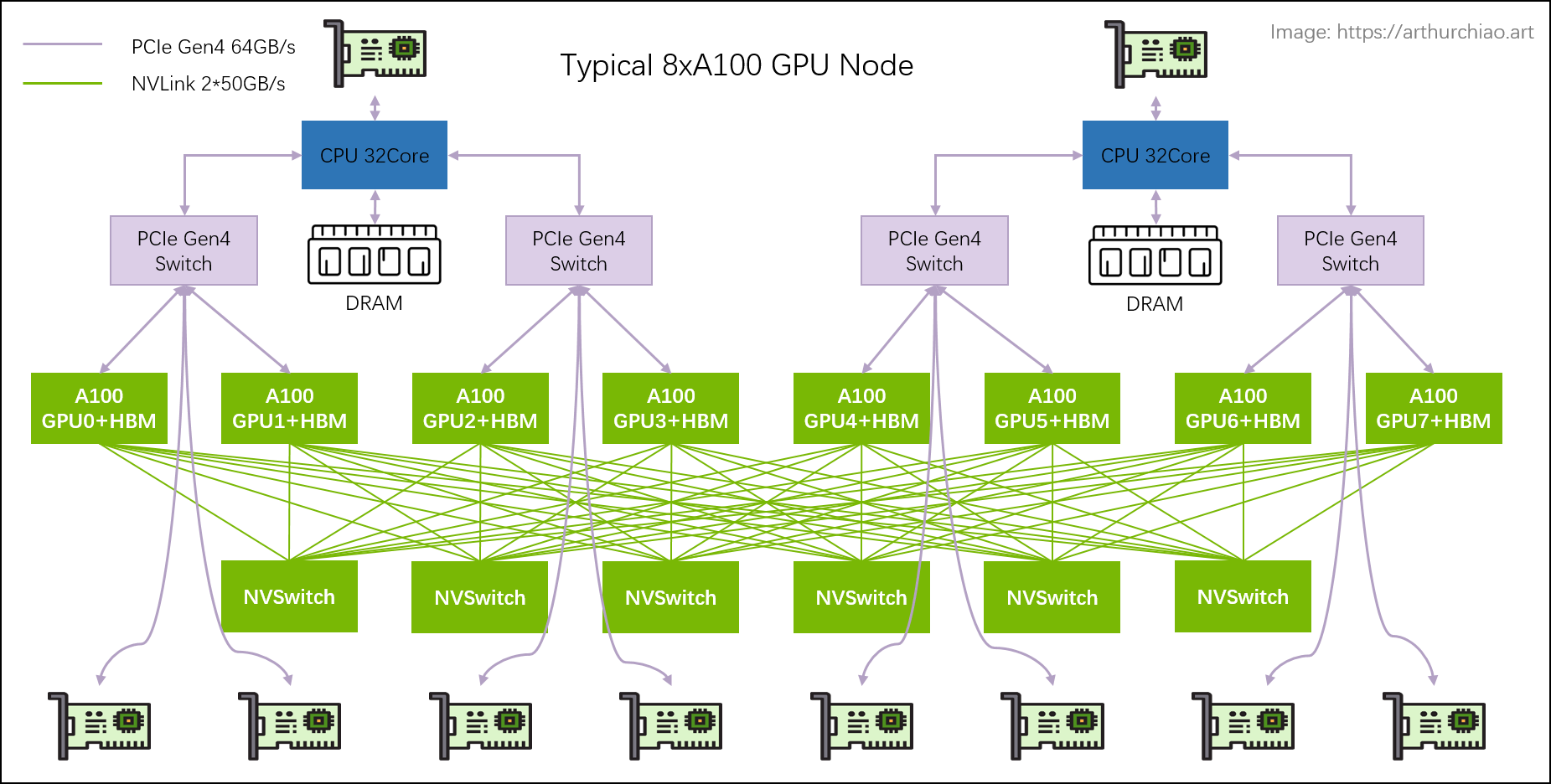
NVIDIA NVLink采用全网状拓扑,如下所示,(双向)GPU-to-GPU 最大带宽可达到400GB/s (需要注意的是,下方展示的是8*A100模块时的600GB/s速率,8*A800也是类似的全网状拓扑);
华为HCCS采用对等拓扑(没有 NVSwitch 芯片之类的东西),所以(双向) GPU-to-GPU 最大带宽是56GB/s;
H20/L20/Ascend 910B对比:








