

NSDI 是 USENIX 协会在网络系统设计和实现领域的顶会之一,与 SIGCOMM 并列为全球计算机科学专业顶级学术会议列表CSRankings收录的计算机网络领域两大国际顶级学术会议,被计算机学会(CCF)评为推荐A类会议,Core Conference Ranking 给予 A 级别评价,具备极高的学会价值和影响力。
本年度USENIX NSDI 共有601篇投稿,录用112篇,录取率18.6%。本文简单介绍了NSDI 2024中调度网络、网络协议、网络可编程、大规模机器学习、广域和边缘方向的部分论文,文末附NSDI 2024全部论文下载链接。
调度网络
标题:Revisiting Congestion Control for Lossless Ethernet
作者: Yiran Zhang, Tsinghua University and Beijing University of Posts and Telecommunications; Qingkai Meng, Tsinghua University and Beihang University; Chaolei Hu and Fengyuan Ren, Tsinghua University
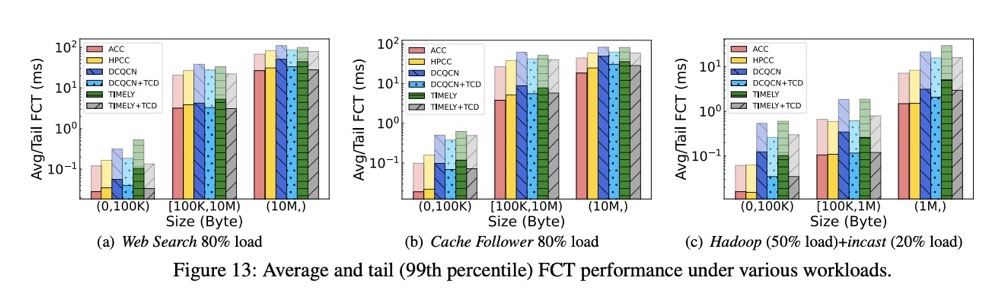
摘要: 拥塞控制是大规模无损以太网的关键使能技术。在本文中,我们从一个新的角度重新审视这一经典主题,即深入理解和充分利用底层无损网络的内在属性。通过实验和分析发现,无损网络的内在属性(例如数据包守恒)在估算管道容量和精确计算过多数据包方面具有重要的指导意义。此外,我们还推导出了如何分别对待拥塞流和受害者流的原则,以便有效处理队头阻塞(HoL blocking)现象。随后,我们提出了针对无损以太网的 ACK 驱动的拥塞控制(ACC)方案,该方案仅依赖于ACK时间序列的知识,通过暂时停止传输以精准排出拥塞流中的过剩数据包,继而使其速率与管道容量相匹配。测试平台和大规模仿真表明,ACC 成功地改善了无损以太网中的基本问题(例如拥塞扩散、HoL 阻塞和死锁),并实现了出色的低延迟和高吞吐量性能。例如,与现有方案相比,ACC将小流的平均和99% FCT性能分别提高了1.3~3.3倍和1.4~11.5倍。
标题:Pudica: Toward Near-Zero Queuing Delay in Congestion Control for Cloud Gaming
作者:Shibo Wang, Xi’an Jiaotong University and Tencent Inc.; Shusen Yang, Xi'an Jiaotong University; Xiao Kong, Chenglei Wu, and Longwei Jiang, Tencent; Chenren Xu, Peking University; Cong Zhao, Xi'an Jiaotong University; Xuesong Yang, Bonree; Jianjun Xiao and Xin Liu, Tencent; Changxi Zheng, Pixel Lab, Tencent America, and Columbia University; Jing Wang and Honghao Liu, Tencent
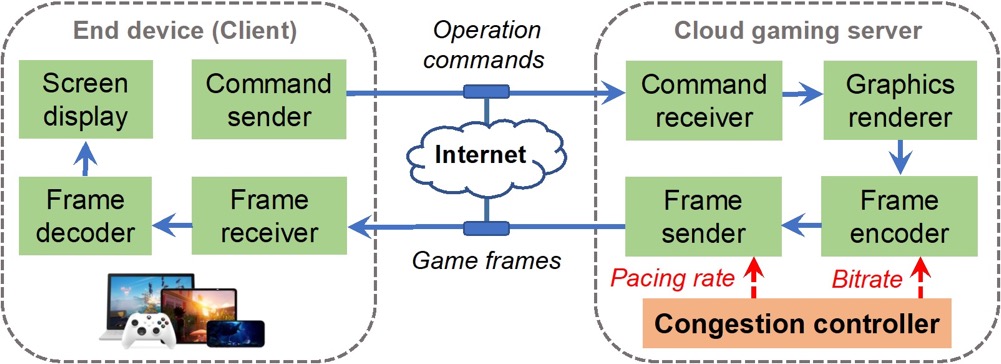
摘要:以云游戏为代表的超低时延交互视频流应用,受到学术界和产业界的共同关注。其提供计算与交互分离式的系统架构,可以摆脱终端的性能束缚,同时享受便捷优质的互联网云服务。然而,此架构高度依赖视频帧的低时延传输,否则将难以满足用户的体验要求。因此,云游戏系统需要自适应的端到端发送率控制,以匹配动态变化的网络状态,避免数据在网络管道中的堆积进而造成高排队时延。
基于此,本论文提出了面向云游戏的超低时延拥塞控制算法Pudica。Pudica通过精准的带宽利用率预测和敏捷的码率控制,在毫秒级尺度实现快速收敛至效率与公平。并且,Pudica通过对更细粒度网络信号的探索利用,实现了及时的拥塞避让和数据堆积排空。通过大规模产品级线上实验(超过5000真实云游戏用户),该算法降低平均传输时延3x,降低云游卡顿率8x,提升游戏码率23%。该算法已在腾讯公司START云游戏平台部署运行至今。
网络协议
标题:A large-scale deployment of DCTCP
作者:Abhishek Dhamija and Balasubramanian Madhavan, Meta; Hechao Li, Netflix; Jie Meng, Shrikrishna Khare, and Madhavi Rao, Meta; Lawrence Brakmo; Neil Spring, Prashanth Kannan, and Srikanth Sundaresan, Meta; Soudeh Ghorbani, Meta and Johns Hopkins University
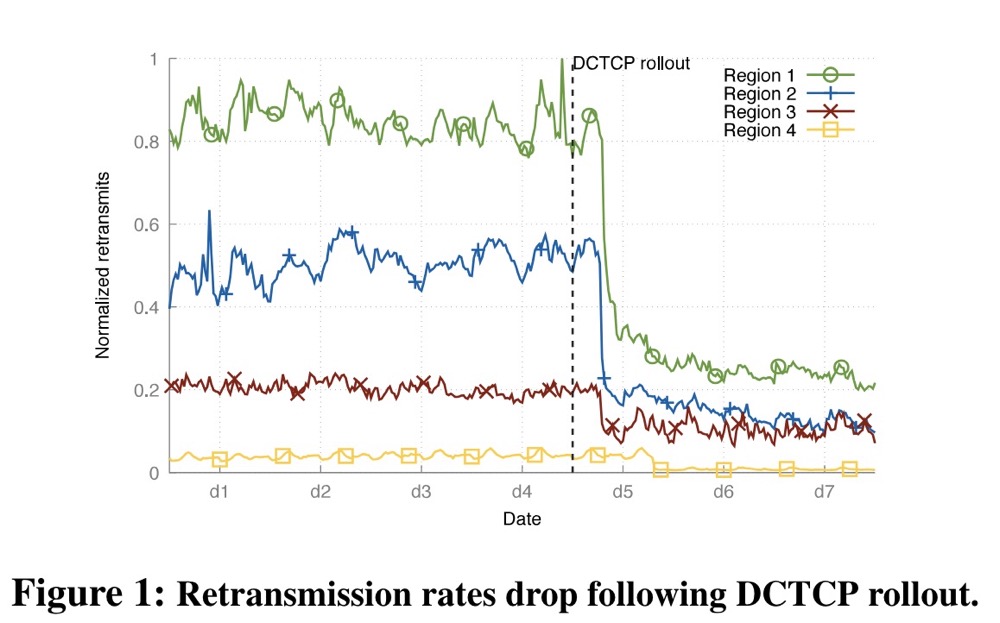
摘要:本文介绍了在大规模数据中心网络中部署数据中心TCP(DCTCP)协议的流程和操作经验。传统的拥塞控制协议依赖丢失作为主要拥塞信号,而DCTCP则向发送方发出网络内拥塞信号(基于队列占用率),并根据拥塞程度按比例调整发送速率。在我们的部署过程中,该协议经过了充分的研究,并且效率得到了提升。与数据中心的传统协议相比,DCTCP协议性能有所提高,数据包丢失显著减少。最后介绍了推出DCTCP时遇到的一些障碍和挑战。
标题:TECC: Towards Efficient QUIC Tunneling via Collaborative Transmission Control
作者:Jiaxing Zhang, Alibaba Group, University of Chinese Academy of Sciences; Furong Yang, Alibaba Group; Ting Liu, Alibaba Group, University of Chinese Academy of Sciences; Qinghua Wu, University of Chinese Academy of Sciences, Purple Mountain Laboratories, China; Wu Zhao, Yuanbo Zhang, Wentao Chen, Yanmei Liu, Hongyu Guo, and Yunfei Ma, Alibaba Group; Zhenyu Li, University of Chinese Academy of Sciences, Purple Mountain Laboratories, China
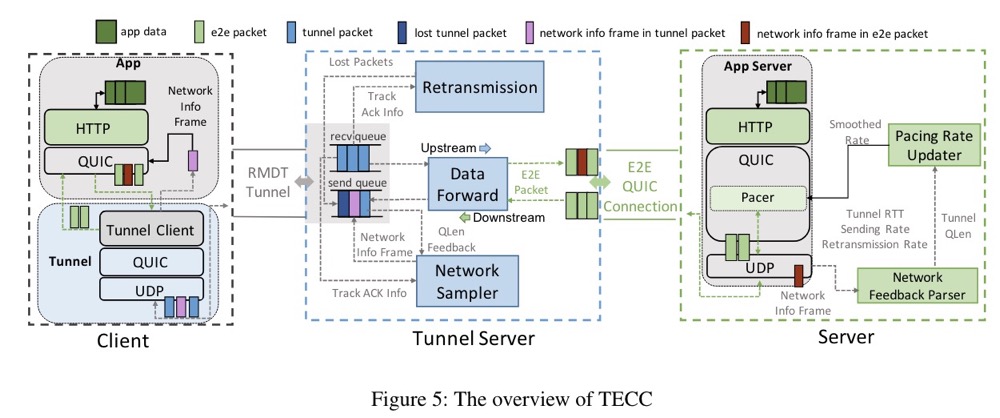
摘要:TECC是一种基于协作传输控制的系统,旨在解决内部和外部连接之间发送行为不匹配的问题,从而实现高效的QUIC隧道。TECC实现了反馈框架,使终端主机能够收集隧道服务器上更精确的网络信息,从而有助于内部端到端连接实现更好的拥塞控制和丢失恢复。在仿真网络和现实世界的大规模A/B测试中,TECC相比于最先进的QUIC隧道解决方案显著缩短了流程完成时间。具体来说,在仿真网络中,TECC将流量完成时间平均缩短了30%,99th percentile缩短了53%。此外,TECC还使RPC(远程过程调用)请求完成时间平均缩短了3.9%,在大规模A/B测试中,99th percentile缩短了13.3%。
标题 :Understanding Routable PCIe Performance for Composable Infrastructures
作者:Wentao Hou, University of Wisconsin-Madison; Jie Zhang and Zeke Wang, Zhejiang University; Ming Liu, University of Wisconsin-Madison
摘要:可路由PCIe已成为构建新兴可组合基础设施的主要集群互连。在PCIe非透明桥接设备的支持下,PCIe事务可以遍历多个交换域,从而使服务器能够弹性地将多个远程PCIe设备集成为本地设备。然而,在不了解其功能和限制的情况下,如何在可路由的PCIe结构上有效地移动数据或执行通信尚不清楚。
本文介绍了rPCIeBench的设计和实现,这是一个软硬件协同设计的基准测试框架,用于系统地表征可路由PCIe结构。rPCIeBench提供灵活的数据通信原语,公开端到端PCIe事务的可观察性,并支持可重构的实验部署。使用rPCIeBench,首先分析可路由PCIe路径的通信特性,量化其性能税,并将其与本地PCIe链路进行比较。然后,使用它来剖析 fabric内流量编排行为,并得出三个有趣的发现:近似最大-最小带宽划分、快速端到端带宽同步以及正交数据路径之间的无干扰。最后,我们将收集到的表征见解编码为流量编排规则,并开发了一种边缘约束放松算法来估计共享结构上的PCIe流传输性能。验证了其准确性,并展示了它的潜力,为设计高效的流调度程序提供了优化指导。

网络可编程
标题:Brain-on-Switch: Towards Advanced Intelligent Network Data Plane via NN-Driven Traffic Analysis at Line-Speed
作者:Jinzhu Yan and Haotian Xu, Tsinghua University; Zhuotao Liu, Qi Li, Ke Xu, Mingwei Xu, and Jianping Wu, Tsinghua University and Zhongguancun Laboratory
摘要:新兴的可编程网络引发了智能网络数据平面(INDP)的重要研究,该平面实现了基于学习的线速流量分析。INDP的现有技术侧重于在数据平面上部署树/森林模型。我们观察到基于树的INDP方法的一个基本限制:尽管可以在数据平面上表示更大的树/森林表,但在数据平面上可计算的流特征从根本上受到硬件约束的限制。在本文中,我们提出 BoS 通过启用神经网络 (NN) 驱动的线速流量分析来突破 INDP 的界限。设计用于处理顺序数据的许多类型的神经网络(例如循环神经网络 (RNN) 和转换器)比基于树的模型具有优势,因为它们可以将原始网络数据作为输入,而无需动态进行复杂的特征计算。然而,挑战在于RNN推理中使用的循环计算方案与网络数据平面上使用的匹配动作范式具有根本的不同。BoS通过(1)设计一种新颖的数据平面友好的RNN架构来解决这一挑战,该架构可以用有限的数据平面阶段执行无限的RNN时间步长,有效地实现线速RNN推理;(2)以基于off-switch变压器的流量分析模块补充on-switch RNN模型,进一步提升整体性能。我们使用P4可编程交换机作为数据平面的BoS原型,并在多个流量分析任务中对其进行了广泛的评估。结果表明,BoS在分析精度和可扩展性方面均优于最先进的技术。
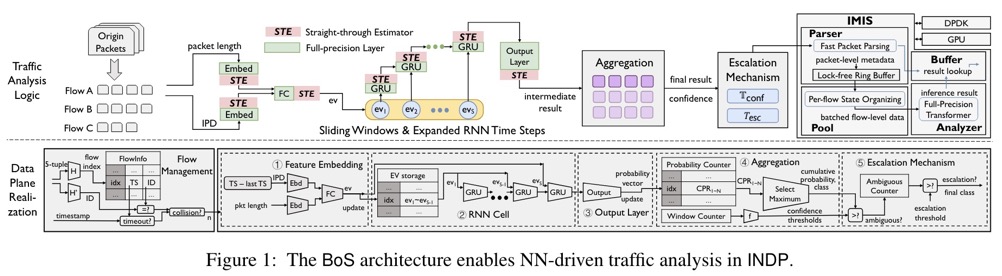
标题:Sirius: Composing Network Function Chains into P4-Capable Edge Gateways
作者:Jiaqi Gao, Jiamin Cao, Yifan Li, Mengqi Liu, Ming Tang, Dennis Cai, and Ennan Zhai, Alibaba Cloud
摘要:阿里云设计并部署了支持P4的网关,以加速边缘云多样化业务流量的处理。由于网关中的可编程ASIC只接受单片、流水线的P4程序,因此必须将针对不同业务流量的数十个网络功能链组合成一个。由于网络功能链的复杂性和可编程 ASIC 中的有限资源之间的争用,这一点并不简单。在本文中,我们提出了 Sirius,一个自动化网络功能链组成过程的系统。 Sirius 综合表格来识别输入数据包所属的业务流量,通过再循环在合并的网络功能图中进行管道循环,并在所需的内存消耗超出 ASIC 的能力时在可编程 ASIC 和 CPU 之间划分图形。到目前为止,Sirius已经在数百个网关中实现了网络功能的自动化部署,并有效地将程序员的工作量减少了三个数量级,从几周减少到几分钟。
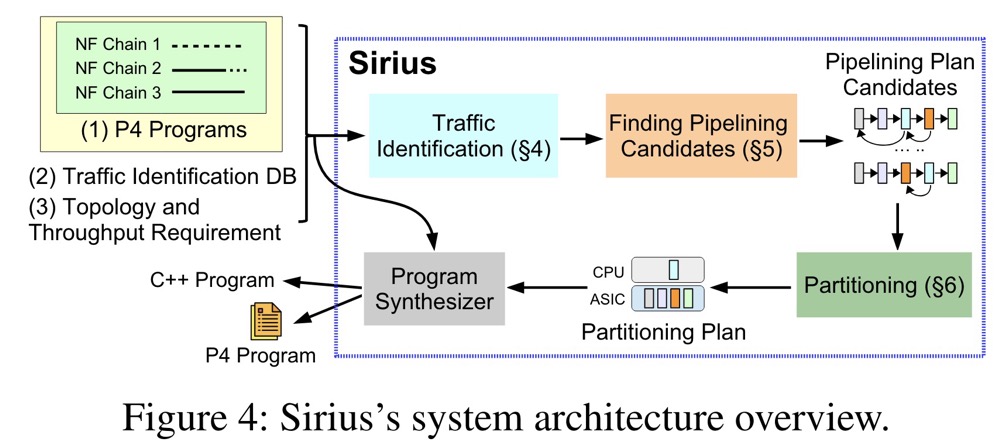
标题:Empower Programmable Pipeline for Advanced Stateful Packet Processing
作者:Yong Feng and Zhikang Chen, Tsinghua University; Haoyu Song, Futurewei Technologies; Yinchao Zhang, Hanyi Zhou, Ruoyu Sun, Wenkuo Dong, Peng Lu, Shuxin Liu, and Chuwen Zhang, Tsinghua University; Yang Xu, Fudan University; Bin Liu, Tsinghua University
摘要:在一定程度上,可编程管道提供了灵活和高吞吐量的数据包处理能力,当需要比基本数据包处理和转发的更高级的数据平面功能时,管道就会受到阻碍。最根本的原因是,大多数有状态操作需要向后跨阶段数据传递和管道延迟以实现状态更新和一致性,这对于标准管道来说是不正常的。为了解决这个问题,我们增加了一个低成本、快速的侧环来促进数据的反向传递,并进一步应用推测执行技术来避免管道停顿。由此产生的架构 RAPID 支持使用增强型 P4 语言的本机和通用有状态函数编程。我们构建了一个基于 FPGA 的原型来评估系统,并构建了一个软件仿真器来评估 ASIC 实施的成本和性能。我们实现了 RAPID 支持的多个有状态应用程序,以展示它如何将可编程数据平面的潜力扩展到新的水平。
标题:AutoSketch: Automatic Sketch-Oriented Compiler for Query-driven Network Telemetry
作者:Haifeng Sun and Qun Huang, National Key Laboratory for Multimedia Information Processing, School of Computer Science, Peking University; Jinbo Sun, Institute of Computing Technology, Chinese Academy of Sciences; Wei Wang, Northeastern University, China; Jiaheng Li, National Key Laboratory for Multimedia Information Processing, School of Computer Science, Peking University; Fuliang Li, Northeastern University, China; Yungang Bao, Institute of Computing Technology, Chinese Academy of Sciences; Xin Yao and Gong Zhang, Huawei Theory Department
摘要:网络遥测系统是网络管理的核心,为网络管理任务的决策提供丰富的流量统计信息。近年来,基于Sketch的网络遥测算法由于其误差理论可控和低内存开销的特点受到广泛关注。但是在实际部署中,用户需要面临在现有的可编程网络设备上选择、配置和实现Sketch算法的负担。AutoSketch结合了查询驱动型遥测系统与基于Sketch的遥测算法二者的优势,降低上述应用Sketch算法的用户负担。AutoSketch的核心功能是将高层次的算子(例如,distinct, reduce等)自动编译为Sketch实例,从而在用户层保证丰富的表达能力,在数据平面保证可控的测量精度和低资源开销。为了结合高级遥测语言与基于Sketch的遥测算法,AutoSketch解决了三个方面的挑战:首先,它扩展了基于高级算子的遥测接口,使用户能够指定所需的遥测精度,这一精度将指导编译过程中的Sketch算法选择与配置;其次,通过语法分析和性能评估等技术构建高效的Sketch实例;最后,AutoSketch能自动搜索最合适的参数配置,以最小的资源开销满足精度需求。实验结果表明,与现有的遥测解决方案相比,AutoSketch在表达力、精度和资源利用率方面均显示出卓越的性能。

大规模机器学习
标题:Characterization of Large Language Model Development in the Datacenter
作者:Qinghao Hu, Shanghai AI Laboratory and S-Lab, Nanyang Technological University; Zhisheng Ye, Shanghai AI Laboratory and Peking University; Zerui Wang, Shanghai AI Laboratory and Shanghai Jiao Tong University; Guoteng Wang, Shanghai AI Laboratory; Meng Zhang and Qiaoling Chen, Shanghai AI Laboratory and S-Lab, Nanyang Technological University; Peng Sun, Shanghai AI Laboratory and SenseTime Research; Dahua Lin, Shanghai AI Laboratory and CUHK; Xiaolin Wang and Yingwei Luo, Peking University; Yonggang Wen and Tianwei Zhang, Nanyang Technological University
摘要:大语言模型 (LLM) 在多项变革性任务中表现出了令人印象深刻的性能。然而,想要高效利用大规模集群资源来开发LLM并非易事,这一过程中常常面临硬件故障频繁、并行策略复杂、资源利用不平衡等诸多挑战。在本文中,我们对从 GPU 数据中心 Acme 收集的为期六个月的 LLM 开发工作负载跟踪进行了深入的特征研究。具体来说,我们调查LLM与以往特定任务的深度学习 (DL) 工作负载之间的差异,探索了资源利用模式,并识别了各种作业失败的影响。我们的分析总结了遇到的难题,并揭示了针对LLM优化系统的潜在机会。此外,我们还介绍了系统工作:(1)容错预训练,通过涉及LLM的故障诊断和自动恢复机制增强了系统的容错能力;(2)解耦合评估调度,通过试验分解和调度优化实现了及时的性能反馈。

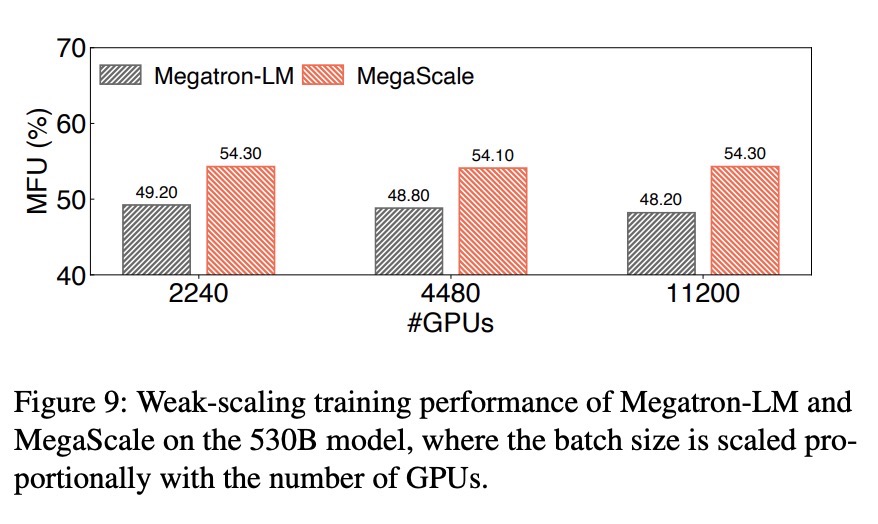
标题:MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
作者:Ziheng Jiang and Haibin Lin, ByteDance; Yinmin Zhong, Peking University; Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, Yulu Jia, Sun He, Hongmin Chen, Zhihao Bai, Qi Hou, Shipeng Yan, Ding Zhou, Yiyao Sheng, Zhuo Jiang, Haohan Xu, Haoran Wei, Zhang Zhang, Pengfei Nie, Leqi Zou, Sida Zhao, Liang Xiang, Zherui Liu, Zhe Li, Xiaoying Jia, and Jianxi Ye, ByteDance; Xin Jin, Peking University; Xin Liu, ByteDance
摘要:大语言模型的性能随着参数规模的增大而不断提高已成为普遍共识。为支持千亿甚至万亿量级的大语言模型预训练,GPU集群已经被扩大到万卡规模。但在这种规模下训练大型语言模型面临前所未有的挑战,主要包括维持高训练效率和训练稳定性两个方面。
为此,该论文深入优化了从软件到硬件的全栈方案,涵盖模型架构、优化器设计、计算与通信重叠、算子优化、数据管道优化和网络性能调优,以实现整个训练过程的高效率。对于训练的稳定性,因为大语言模型预训练的持续时间很长,许多严峻的稳定性问题只有在大规模时才会显现。我们开发了一套诊断工具来监控各个系统组件,以分析各类错误的根本原因,并针对性制定技术以实现容错。MegaScale在使用12,288个GPU训练一个175B 的大语言模型时,达到了55.2%的模型FLOPs利用率(MFU),相较于此前的SOTA系统Megatron-LM,MFU提高了1.34倍。论文中还分享在识别和修复故障及滞后问题中的实际例子,希望这些系统角度的经验能激发未来大语言模型系统研究的灵感。
标题:Resiliency at Scale: Managing Google’s TPUv4 Machine Learning Supercomputer
作者:Yazhou Zu, Alireza Ghaffarkhah, Hoang-Vu Dang, Brian Towles, Steven Hand, Safeen Huda, Adekunle Bello, Alexander Kolbasov, Arash Rezaei, Dayou Du, Steve Lacy, Hang Wang, Aaron Wisner, Chris Lewis, and Henri Bahini, Google
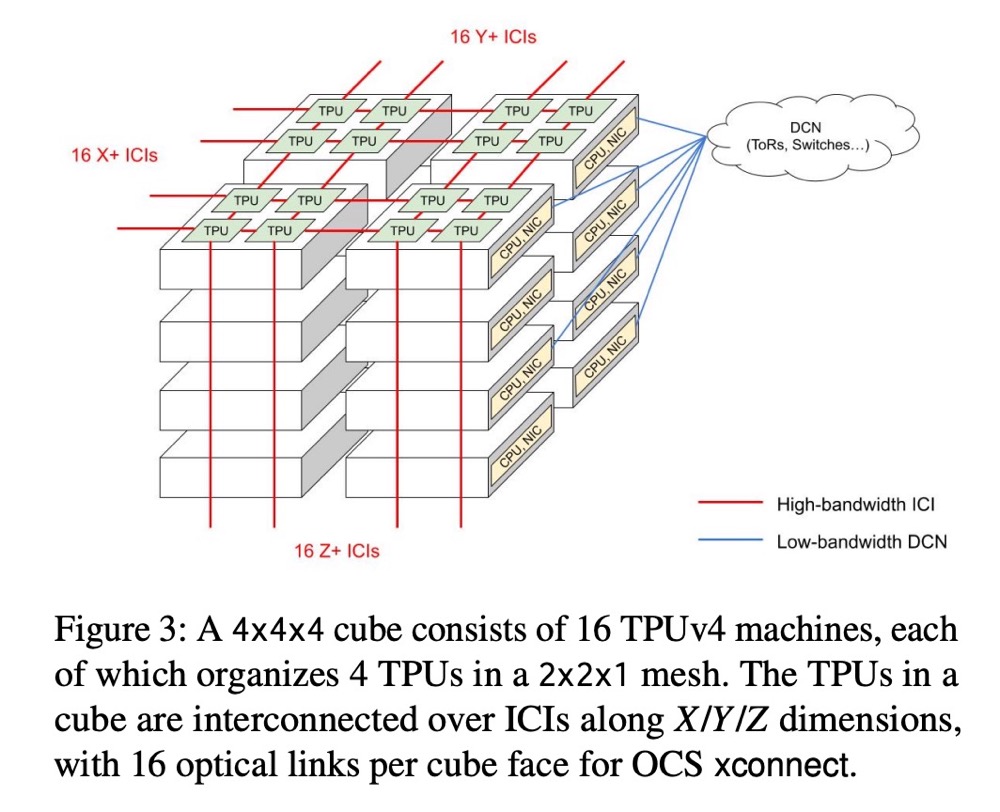
摘要:TPUv4(张量处理单元)是第三代专门用于机器学习训练的加速器,其部署形式为配备定制3D环面互连结构的4096节点超级计算机。在本文中,我们描述了我们在设计和操作允许 TPUv4 超级计算机大规模运行的软件基础设施的经验,包括自动故障恢复和硬件恢复的功能。我们采用软件定义网络 (SDN) 的方法来管理 TPUv4 的高带宽芯片间互连 (ICI) 结构,使用光路交换技术动态配置路由以解决机器、芯片和链路故障。我们的基础设施能够检测故障并自动触发重新配置,从而最大程度地减少对运行工作负载的干扰,同时启动受影响组件的修复和维修工作流程。类似的技术也应用于硬件和软件的维护与升级工作流程。我们的动态重构方法使TPUv4超级计算机能够实现99.98%的系统可用性,妥善处理约1%的训练作业所经历的硬件中断。
广域和边缘
标题:Application-Level Service Assurance with 5G RAN Slicing
作者:Arjun Balasingam, MIT CSAIL; Manikanta Kotaru and Paramvir Bahl, Microsoft
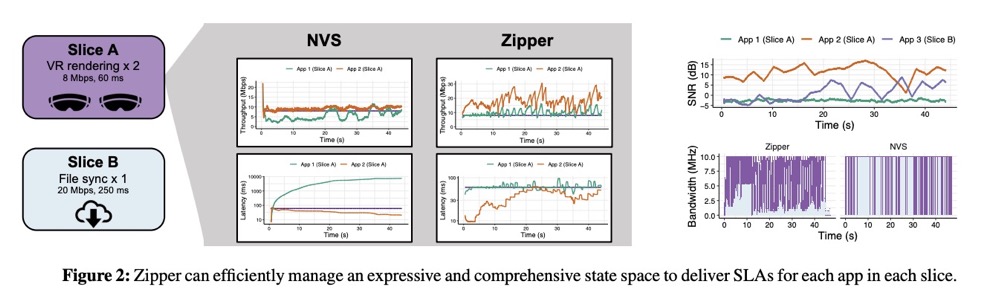
摘要:本文介绍了一种新型无线接入网络(RAN)切片系统——Zipper,该系统能够为应用层提供吞吐量和延迟的确保。目前的RAN切片系统侧重于优化切片级别的性能保障,但在为单个移动应用提供可预测的网络性能方面存在问题。若将切片级别扩展至应用级别,会带来一个棘手的优化问题,其状态和操作空间会急剧膨胀。为了简化搜索空间,Zipper 将问题转化为模型预测控制器,并显式跟踪每个用户的网络动态。它使用高效的算法来计算满足每个应用程序要求的切片带宽分配。
我们在一个生产级的5G虚拟RAN测试平台上实现了Zipper,该平台集成了控制切片带宽的hook,并在真实工作负载上对其进行了评估,包括视频会议和虚拟现实应用。在一个典型的RAN工作负载上,我们的实时实现能支持 100 MHz 通道上多达 200 个应用程序和超过 70 个切片。相对于切片级服务保证系统,Zipper 将尾部吞吐量和延迟违规(以应用程序请求的违规比率来衡量)减少了 9 倍。
标题:LuoShen: A Hyper-Converged Programmable Gateway for Multi-Tenant Multi-Service Edge Clouds
作者:Tian Pan, Kun Liu, Xionglie Wei, Yisong Qiao, Jun Hu, Zhiguo Li, Jun Liang, Tiesheng Cheng, Wenqiang Su, Jie Lu, Yuke Hong, Zhengzhong Wang, Zhi Xu, Chongjing Dai, Peiqiao Wang, Xuetao Jia, Jianyuan Lu, Enge Song, and Jun Zeng, Alibaba Cloud; Biao Lyu, Zhejiang University and Alibaba Cloud; Ennan Zhai, Alibaba Cloud; Jiao Zhang and Tao Huang, Purple Mountain Laboratories; Dennis Cai, Alibaba Cloud; Shunmin Zhu, Tsinghua University and Alibaba Cloud
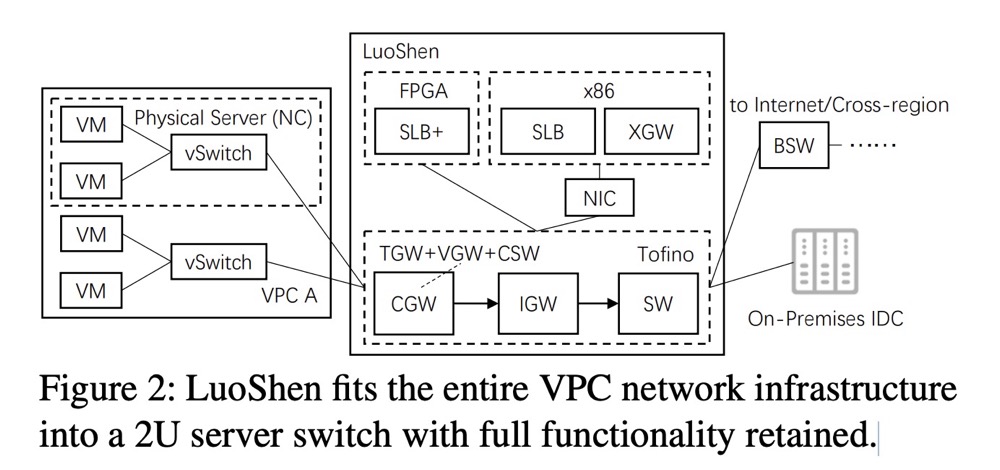
摘要:在未来十年,边缘云预计将成为云服务提供商的关键收入增长动力;然而,简单地将公共云的网络基础设施复制到边缘环境会面临部署问题。在边缘环境中,云网络设计面临的挑战是在严格的硬件预算和部署空间限制下,仍要保持功能等效性的同时提供所需性能。
为此,我们提出了洛神,一种用于多租户多服务边缘云的超融合网关,通过将整个云网络基础设施整合到一个基于P4中心架构的2U服务器交换机中。在数据平面,洛神执行 pipeline折叠技术,通过精细的芯片内资源预算,将原始的 overlay 和underlay 设备融入交换机pipeline。在控制平面,洛神依靠BGP对等连接以确保各组件间的可达性。洛神实现了高达1.2Tbps的吞吐量,并且与原始云网络架构相比,其前期成本、部署尺寸和能耗分别降低了75%、87%和60%。目前,洛神已在阿里云的数百个边缘站点部署使用。
标题:Hairpin: Rethinking Packet Loss Recovery in Edge-based Interactive Video Streaming
作者:Zili Meng, Tsinghua University, Hong Kong University of Science and Technology, and Tencent; Xiao Kong and Jing Chen, Tsinghua University and Tencent; Bo Wang and Mingwei Xu, Tsinghua University; Rui Han and Honghao Liu, Tencent; Venkat Arun, UT Austin; Hongxin Hu, University at Buffalo, SUNY; Xue Wei, Tencent
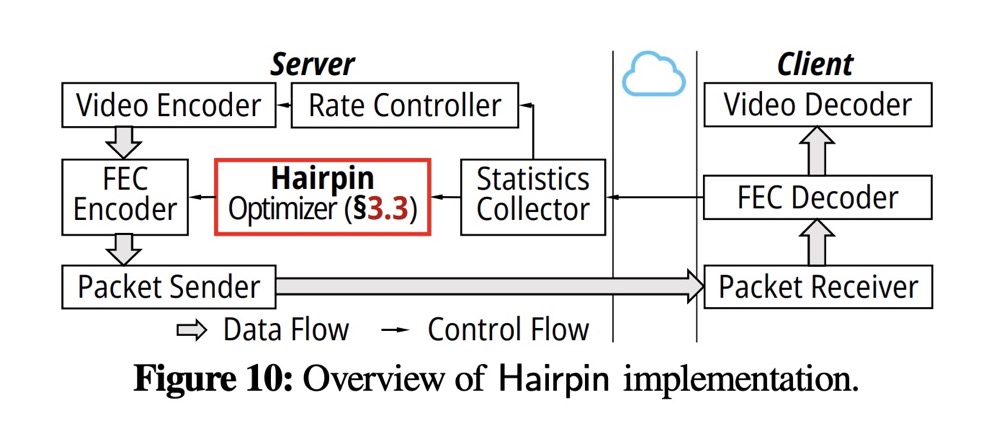
摘要:交互式流媒体需要最大限度地减少卡顿事件(或视频帧的截止期限未达情况),以确保用户和应用程序之间的无缝交互。然而,现有的丢包恢复机制对初始传输和重传统一优化冗余,仍然无法满足交互式流媒体的时延要求,而且还引入了相当大的带宽成本。我们认为,在基于边缘的交互式流媒体中,区分冗余设置的重传通常可以同时实现低带宽成本和低截止期限未达率。在本文中,我们提出了 Hairpin,一种针对基于边缘的交互式流媒体的新型丢包恢复机制。 Hairpin在多轮传输中找到数据包、重传和冗余包的最佳组合,从而在保证端到端延迟要求的同时,显着降低带宽成本。生产部署实验表明,与最先进的解决方案相比,Hairpin 平均可将带宽成本平均降低 40%,并将截止日期未达率平均降低 32%。
SDNLAB公众号后台回复NSDI24,即可获取会议全部论文







