

人工智能 (AI) 的兴起极大地提高了对强大、高效和可扩展的网络传输协议的需求。本文深入探讨了 RDMA(远程直接内存访问)传输协议,并重点讨论 ROCEv2 协议,目前基于 ROCEv2 的 RDMA已经在一些超大规模数据中心中取代了 TCP。
在最近的NDSI-23-Talk中,微软强调,70% 的 Azure 云网络流量(主要是存储网络流量)在基于以太网的 ROCEv2 RDMA 上运行,只有一小部分依赖基于 TCP/IP 的网络,这一转变在 Oracle、阿里巴巴和 Meta 等其他超大规模提供商中也很明显。这一趋势表明,随着云计算、人工智能/机器学习工作负载的持续增长,整个行业正朝着采用RDMA技术来优化网络性能的方向发展。
RDMA概述
RDMA 通过直接将“内存映射”数据传输到远程内存位置来运行,具有两个关键优势:
CPU 效率:与消耗多个 CPU 核心的 TCP/IP 不同,RDMA在内存注册后将数据传输委托给 RDMA 网络适配器来执行,这样的方式释放了CPU资源,对于云服务提供商来说,这可以更有效地利用这些新可用的CPU核心,实现更高的资源利用率。
低延迟和内存效率:RDMA 绕过 Linux 内核,直接将数据传输到应用程序缓冲区,这一功能称为零复制。这消除了在发送和接收端点节点处进行内存复制的需要。内核旁路和零拷贝功能可最大限度地减少延迟和抖动。
RoCEv2 RDMA 起源于高性能计算 (HPC),并结合了 IB 传输协议。
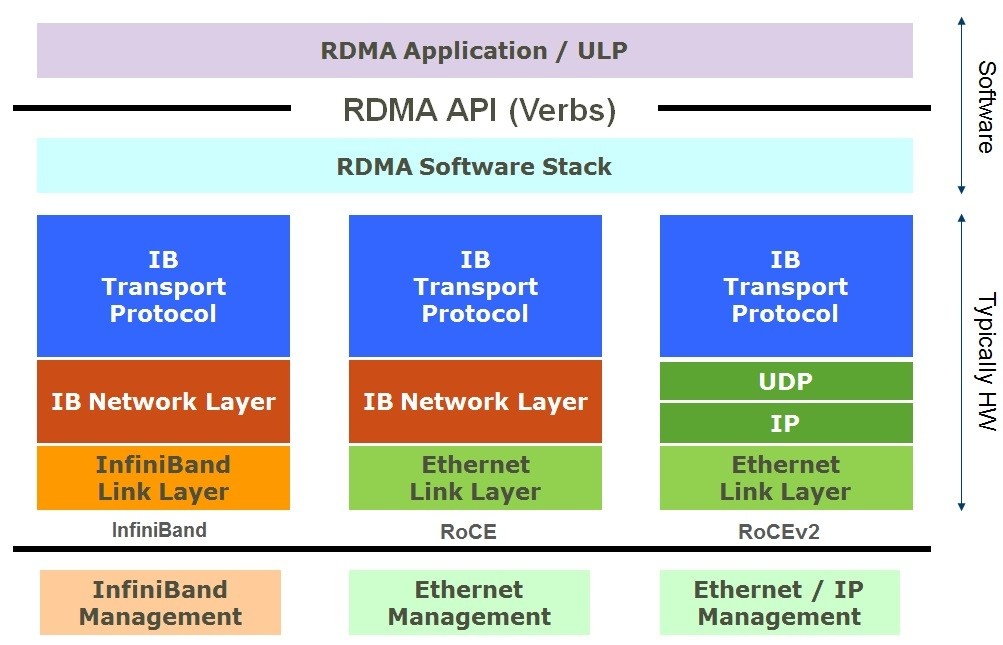
| InfiniBand 和 ROCEv2 协议栈
RoCEv2 保留了 InfiniBand 语义及其传输和网络协议,并将InfiniBand链路层和物理层替换为以太网。
因此,ROCEv2 RDMA 已成为数据中心后端网络的标准,可提供高吞吐量、微秒范围的低延迟和完整的 CPU 卸载。
注意:前端网络通常运行 TCP/IP 或 QUIC 等其他协议。RDMA、InfiniBand 等协议作为后端网络,通常被称为东西向流量,占现代数据中心流量的 70-80%。
以太网 ROCEv2 挑战
InfiniBand架构
InfiniBand架构是无损网络,重点关注服务质量 (QoS) 和传输层端到端信用。IB 协议栈非常适合 HPC 和 AI/ML 网络。然而,InfiniBand 网络通常比以太网更昂贵,可扩展性也更差。
注意:无损意味着底层网络被配置为避免因网络拥塞而导致数据包的丢失。尽管如此,偶尔仍可能会由于错误情况导致数据包损坏或丢失。在这种情况下,传输协议包括一种端到端的交付机制,其中内置了数据包重传逻辑,通常由硬件实现,以此在不需要软件干预的情况下触发,以恢复丢失的数据包。这确保了在网络出现问题时可以自动纠正数据包的丢失,无需人工介入。
ROCEv2架构
RoCEv2 在以太网链路上通过 UDP/IP 上运行。UDP 是一种不可靠的数据报服务,而以太网的架构并非无损。由于 ROCEv2 期望底层网络是无损的,因此在将以太网配置为无损网络时面临着多项挑战,如下所述。

| ROCEv2 数据包格式
队头 (HOL) 阻塞:由于优先流量控制 (PFC),不同流中的数据包可能会被拥塞流阻塞,跨更大的网络、跨多个交换机进行扩展成为一个挑战。
拥塞管理:通常由软件以带外方式处理。现有技术缓慢且复杂,一些供应商借用了 InfiniBand 的硬件技术,但这些是定制的,不是以太网标准的一部分。
减少有效吞吐量:以太网不是一个无损网络。由于拥塞下降,可能会发生数据包丢失,这种数据包丢失会导致整个数据包窗口的重传(称为 Go-back-to-N),从而降低网络“goodput”。
尽管存在这些挑战,大型 ROCEv2 网络已经成功部署,但要求对其进行精细调优和持续监控。大多数超大规模企业都采用自定义、非标准的 ROCEv2 解决方案,并在针对不同工作负载微调RDMA堆栈方面投入了大量资金。
在某些情况下,组织甚至为 AI/ML 或存储等特定应用程序建立了单独的基于 ROCEv2 RDMA 的数据中心,但这也导致了运营成本的显著增加。
接下来,我们将深入研究三个不同的案例,以便更全面地理解这一情况。
大厂案例
微软
十多年来,微软一直在大型数据中心部署 RoCEv2,并发表了一篇见解深刻的Microsoft-RDMA-Challenges研究论文。微软的部署面临 PFC 死锁挑战、RDMA 传输活锁挑战以及其他网卡相关问题。
微软认为,单靠协议理论不足以满足现实世界的部署,严格的大规模测试、分阶段部署和网卡供应商协作对于发现协议最初设计时隐藏的漏洞至关重要。微软已经为ROCEv2开发了自定义协议扩展,例如基于 DSCP 的 PFC,一些网卡/交换机供应商已经支持该协议。此外,微软还实施了用于健康跟踪和故障排除的遥测系统,这对于识别这些隐藏的复杂性问题至关重要。
Oracle
OCI(Oracle Cloud Infrastructure,Oracle 云基础设施)是一个公有云,可在同一 RDMA 网络上运行 AI、HPC、数据库和存储等多种不同应用程序。
| Oracle RDMA 网络结构
Oracle 通过多种方法应对 ROCEv2 挑战:
限制优先级流控制 (PFC):仅限于 3 层 Clos 网络中的网络边缘。
网络局部性提示:Oracle 根据网络关联性放置工作负载,以将大部分流量保持在本地,称为网络局部性提示。
微调拥塞控制:利用显式拥塞通知 (ECN) 和 DC-QCN,每个都针对特定 RDMA 工作负载进行微调,以平衡延迟和吞吐量。
Meta
Meta 专注于针对 AI/ML 工作负载的 ROCEv2 RDMA 部署,正如Meta @Scale 2023活动视频中所讨论的那样,主要工作负载包括推荐引擎、内容理解和大语言模型(LLM),这些集群的规模从数百个 GPU 到数万个 GPU不等。
有趣的是,Meta 并没有面临与微软相同的挑战。例如,由于骨干交换机中的深度缓冲区,PFC HOL 阻塞不再是问题。Meta 还成功地使用 DC-QCN 进行拥塞控制,并且由于现代 NIC 具有更大的 NIC 缓存,因此没有面临扩展问题。总的来说,由于具有先进功能的新硬件以及拓扑、工作负载和软件策略的差异等多种原因,Meta 没有遇到相同的问题。
Meta的关键挑战主要围绕负载均衡,这通过依靠 SDN 控制器对路由进行编程来解决。在网络事件发生之前,这些路由不会更新。ECMP 哈希方案仅在网络事件发生后生效。跨多个队列对 (QP) 的元多路复用流和定制的 ECMP 哈希方案以增加熵。
Meta 使用 PCIe 点对点 (P2P) DMA 技术,通过支持跨 GPU 的直接数据传输来提高应用程序性能。
Meta 还超额订阅了主干层,因为 AI/ML 流量模式不需要完整的非阻塞主干连接。这降低了数据中心成本。
与许多其他公司一样,Meta 正在探索数据包喷射、基于分解 VOQ 的交换机以及可以容忍乱序交付的自定义传输协议。
一篇MIT + Meta 研究论文《针对 LLM 的优化网络架构》提出了一种针对 LLM 流量模式的新网络架构,可以将网络成本削减 37% - 75%。该架构为具有高通信需求的 GPU 定义了高带宽或 HB 域。在 HB 内,GPU 通过任意对任意互连进行互连。在Meta部署中,跨HB网络流量稀疏,可以消除跨HB域的连接和交换机,从而降低网络成本。
RDMA 的未来
超大规模厂商和供应商都以自定义的方式解决了 ROCEv2 的潜在问题。ROCEv2 网络仍然需要针对每个工作负载进行定制和微调。
1RMA 扩展框架
具有多个租户的公共云需要大规模扩展,达到数百万个节点和数十亿个流。由于 ROCEv2 面向连接的特性,工作队列条目 (WQE) 通常在硬件中实现,这限制了流量扩展。跨多个租户的安全性和线速加密给 RoCEv2 带来了额外的挑战。

| 消费者排队模型
云数据中心的一个替代方案是1RMA 论文中记录的 1-Shot 远程内存访问 (1RMA) 方法,该方法建议以软件为中心的重新架构。由于片上系统 (SoC)处理器内核现在可在基于 DPU/IPU 的网络适配器上运行软件,因此这种以软件为中心的方法变得更加可行。主要思想是:
软件重点:将一些传统的网卡硬件数据结构(例如排队、数据包排序、数据包调步和拥塞控制)转移到软件中。
硬件重点:将网卡硬件重点放在主数据路径、DMA 传输、incast 边界、身份验证和加密上。硬件无需连接,并向软件提供细粒度的延迟测量和故障通知。
1RMA 方法主张将连接和大部分状态转移到软件中,以获得更好的可扩展性。这简化了硬件并支持公共云所需的大规模扩展。
请注意,采用 1RMA 方法可能需要从头开始重新架构,涉及新协议和 NIC 硬件。此外,1RMA 的研究重点是云数据中心的需求;AI/ML 和 HPC 网络可能需要不同的权衡。
UEC联盟
UEC联盟提议用基于UDP/IP的新开放协议取代ROCEv2。UEC 的重点是 AI/ML 和 HPC 网络。
ROCEv2 替代协议的关键属性:
- 多路径和数据包喷射
- 灵活的交付顺序和选择性重传
- 响应式拥塞控制机制
- 规模更大、稳定可靠
堆栈的所有层可能都需要进行更改。
UEC联盟白皮书中的一些主题确实与1RMA Paper和EDQS Paper(由Correct Networks撰写,被Broadcom收购)产生了共鸣。
在10 月 17 日的OCP峰会上,OCP与 UEC 达成合作,利用两家组织的专业技能来提高AI工作负载的以太网性能。已确定初步探索潜在合作的领域包括 OCP交换机抽象接口(SAI)、OCP Caliptra Workstream、OCP网络项目、OCP网卡Workstream、OCP Time Appliance项目和OCP未来技术倡议。
未来的开放标准
到目前为止,还没有 ROCEv3 标准。针对这些挑战的可扩展、通用和开放的解决方案仍然难以实现。
AI/ML、HPC 和云数据中心工作负载的需求可能差异很大,以至于我们需要多种解决方案。例如,
UEC联盟:UltraEthernet 联盟仅专注于大规模人工智能和高性能计算。
工作负载特征:HPC 要求超低延迟,而 AI/ML 训练优先考虑高吞吐量和低尾延迟。
多种拓扑:公共云通常使用 2 层或 3 层 Clos 网络,而 AI/HPC 网络可能采用蜻蜓、3D 环面或超立方体拓扑,这些仍在不断发展。
不断变化的需求:AI/ML 算法不断发展,云数据中心工作负载也在不断发展,这可能会导致未来进一步分化。
开放与封闭:云数据中心可以继续使用定制解决方案或在 OCP 等论坛中协作来定义开放标准。
如果出现多种开放解决方案,协作可以帮助建立统一的基础架构。这将防止解决方案出现分歧以及相关的成本问题。虽然具有挑战性,但重要性不言而喻。
新标准需要时间才能成熟。定义后,硬件开发可能需要长达两年的时间,然后是规模测试和错误修复,这让时间线又增加了几年。短期内,预计主要参与者将继续进行定制创新。
结 论
虽然有多种定制和复杂的方法可以解决 ROCEv2 的挑战,但业界正在积极探索基于开放标准的 ROCEv2 RDMA 替代方案。未来的 RDMA 协议必须发展成为适用于广泛工作负载的“即插即用”解决方案,就像今天的 TCP 一样。
最后,DPU/IPU与内置SOC正在彻底改变我们对网络的看法,它们使我们能够重新定义硬件-软件边界,直接在网络硬件上运行关键软件,使我们的系统变得灵活且面向未来。
SDNLAB后台回复1024RDMA,即可下载文内相关白皮书。







