

近日,MIT和Meta团队发布了名为“Rail-Only”的全新大语言模型架构设计,对专门用于训练大型语言模型的 GPU 集群的传统any-to-any网络架构提出了挑战。
Rail-Only架构通过将GPU分组,组成一个高带宽互联域(HB域),然后再将这些HB域内的特定的GPU跨接到特定的Rail交换机,虽然增加了跨域通信的路由调度复杂度,但是通过合理的HB域和Rail交换机设计,整体架构可以大量减少交换机的使用,最多可以降低75%的网络通信耗费。

*本文对该论文进行了初步的简要翻译,关于Rail-Only架构的详细内容可在文末下载原版论文进行查阅
引言
LLM是最大和计算最密集的深度神经网络(DNN)之一。最新的GPT4模型估计有数万亿个参数,需要几个月的时间来训练。研究人员试图通过优化并行化策略、复杂的调度、高级压缩,甚至重新配置网络拓扑等方法以提高分布式DNN训练和推理的性能,但LLM仍需要大量的原始计算能力。随着摩尔定律的放缓,LLM规模和计算需求的增长速度超过了加速器,使得超大规模GPU集群成为必然。下一代LLM想要在合理的时间内完成训练,可能需要30000多个GPU的计算能力。
以GPU为中心的集群通常采用两种类型的连接。第一种,几个GPU通过NVLink等短距离通信协议驻留在HB域的高带宽域中。第二种连接形成了一个网络,该网络使用支持RDMA功能的NIC进行any-to-any GPU通信。该网络集群使用RDMA协议,以通过GPU-Direct绕过CPU和操作系统。
然而,将RDMA网络扩展到数万个GPU具有非常大的挑战。研究表明,大规模RDMA网络容易发生死锁和PFC风暴,从而降低性能。此外,随着规模的扩大,Clos架构成本高昂。之前业界也提出过几种技术来实现大规模RDMA网络并降低其成本,这些方法从根本上依赖于网络能够进行any-to-any通信的假设。这一假设构成了几十年来数据中心概念化和开发的基础。
在本文中,我们对该传统观念提出了挑战,通过分析现有的GPU集群架构和训练过程的数据通信,我们发现并不是所有的GPU都需要配对通信、同时不同的训练阶段参与通信的GPU对和数据量也不同。我们提出了一种名为“Rail-Only”的新架构。
背景
GPU集群设计
传统的网络集群旨在使用多层Clos网络为CPU密集型工作负载提供服务,如下图所示。在典型的基于胖树的集群中,每个服务器都配备一个NIC(40 Gbps到400 Gbps),K台服务器排列在连接到ToR交换机的机架中。然后,ToR交换机连接到聚合交换机,以提供跨机架的连接,形成一个pod。最后,pod与Spine交换机互连,允许CPU集群中的服务器之间进行any-to-any通信。
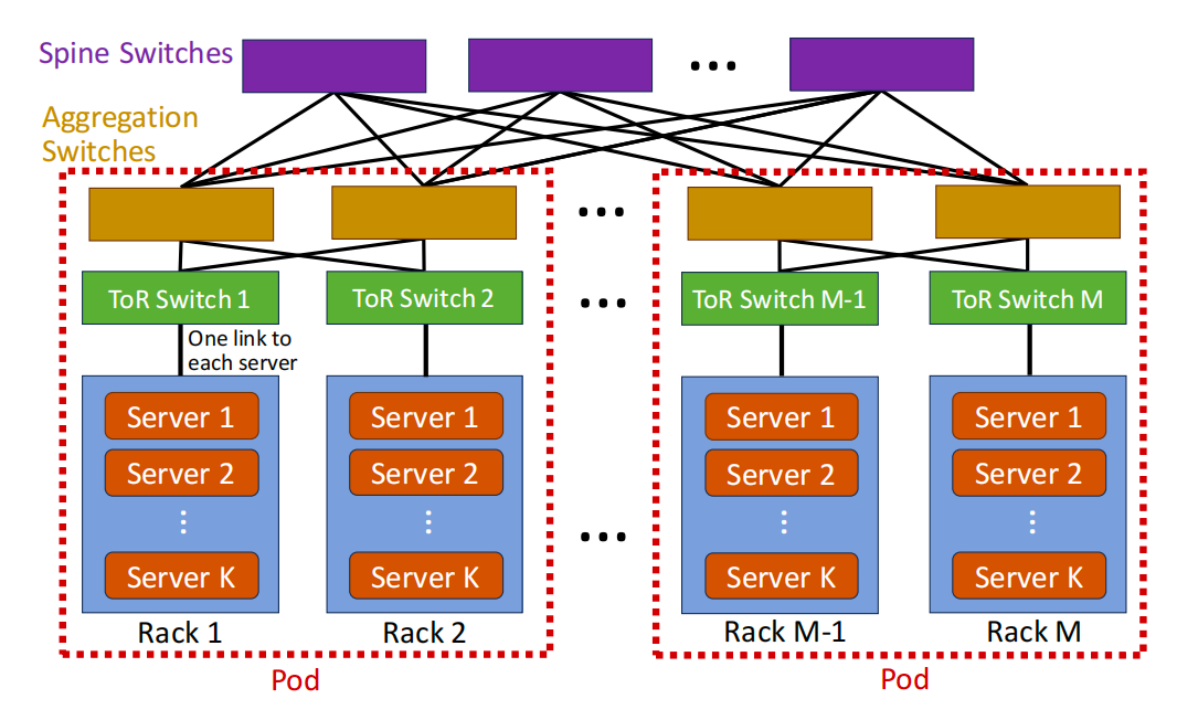
|图1. 具有Clos网络的CPU集群
网络密集型ML工作负载的增加使以GPU为中心的集群占据了主导地位,其中每个GPU具有专用的NIC。下图说明了典型GPU集群的网络体系结构。每个GPU有两个不同的通信接口:支持高带宽但短距离互连的NVLink接口,以及支持RDMA的传统NIC。
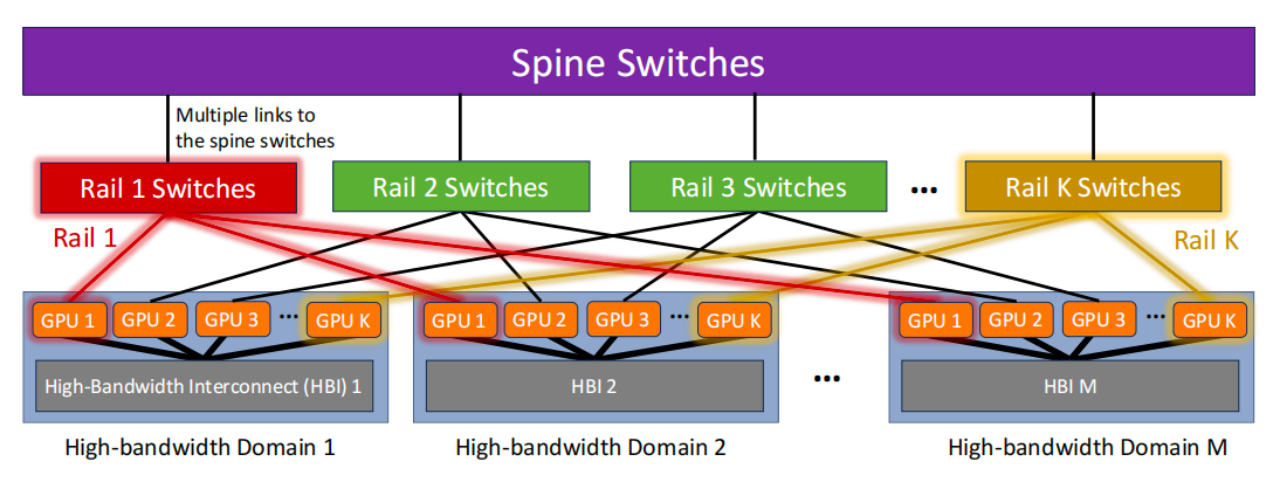
|图2. GPU集群基于Rail-Optimized的any-to-any网络
NVLinks连接K个GPU,为每个GPU提供太比特无阻塞的any-to-any带宽的输入/输出。这组具有快速互连的GPU形成高带宽互联域(HB域)。传统上,HB域仅限于单个服务器。但是,最近英伟达推出的拥有256个GH200超级芯片的NVIDIA DGX GH200超级计算机,在多个机架上形成了一个HB域。
然而,即使使用256个GPU,一些LLM对单个HB域进行训练也需要很长的时间。为了能够跨多个HB域训练LLM,GPU集群运营商使用支持RDMA的NIC将多个HB域互连在一起。用于互连HB域的传统网络架构称为Rail-Optimized网络。
在Rail-Optimized架构中,HB域内的GPU被标记为从1到K。一个Rail是在不同HB域上具有相同索引的GPU的集合,与Rail交换机互连。例如,上图以红色和黄色分别说明了Rail 1和Rail K。这些Rail交换机随后连接到Spine交换机,以形成any-to-any Clos网络拓扑的full-bisection。该网络确保不同HB域中的任何GPU对都可以以网络线路速率通信。例如,GPU 1、Domain 1和GPU 1之间的流量仅通过Rail交换机1,而GPU 1、Domain 1以及GPU 2、Domain 2之间的流量要通过各自的Rail和Spine交换机。
LLM网络流量分析
下面分析的是OpenAI的GPT3、Meta的OPT3-175B和Google的PaLM-540B的流量模式和迭代时间,它们分布在由数百台英伟达 GH200超级计算机组成的集群中。每个GH200超级计算机都包含两层NVSwitch架构,在256个H100 GPU上实现2 Pbps的full-bisection bandwidth。此外,每个GPU都有一个Connect-X7 HCA Infiniband网络接口,该接口在每个GPU中提供400 Gbps的网络带宽。在该设置中,每个GH200超级计算机形成一个HB域。
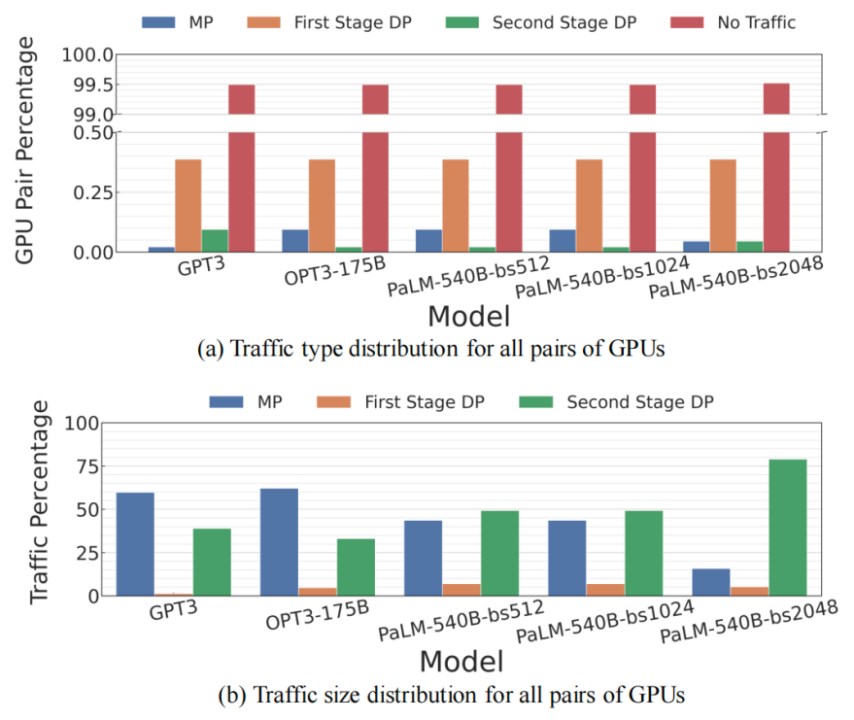
|图3.(a)所有GPU的通信类型对;(b)具有非零通信的所有GPU对的流量大小
图a中指出,超过99%的GPU对不携带流量,不到0.25%的GPU对在它们之间承载MP和第二阶段DP流量。同时,图b显示这些流量类型占总传输数据的90%以上。该模式在所有模型中都是一致的,这表明在LLM模型的HB域之上构建具有any-to-any连接的集群是多余的。
在HB域中,互连需要支持大量的any-to-any通信,以训练各种各样的LLM。下图显示了GPT3和OPT3-175B的训练迭代期间流量的热图。在该图中,每一组连续的256个GPU都位于同一HB域中。

|图4.Traffic heatmaps for GPT3 and OPT3-175B
这些观察结果表明,在不损害LLM的训练性能的情况下,可以删除不承载任何网络流量的链路。分析表明,在any-to-any 400 Gbps Clos网络中,33%的链路是可移动的。
Rail-Only网络设计
我们提出了一种网络架构,将其命名为Rail-Only,架构如下图所示。与传统的Rail-Optimized GPU集群相比,Rail-Only保留了HB域,并仅在同一Rail上提供连接。
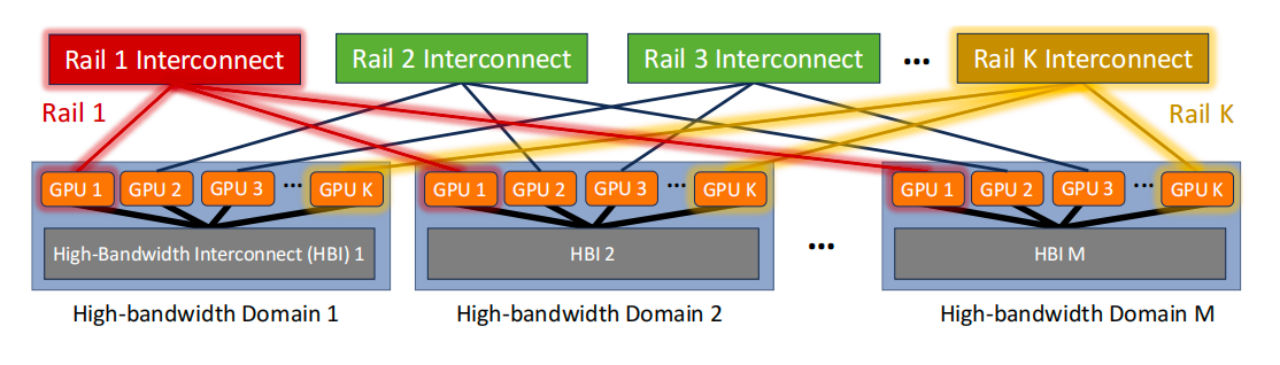
|图5. Rail-Only网络架构
实现Rail-Only架构的一个简单方法是从图2中删除Spine交换机,并将连接Rail交换机到Spine的所有上行链路重新用作到GPU的下行链路。因此,每个Rail都由专用且独立的Clos网络连接。
Rail-Only网络架构消除了不同Rail中具有不同等级GPU之间的网络连接。然而,通过HB域转发数据也可以实现这种通信。尽管我们的分析表明LLM流量不需要这种转发,但此连接可能需要用于控制消息、测量或训练该集群中的其他DNN模型。
讨论
LLM趋势
随着摩尔定律的放缓,当前LLM计算需求的增长率超过了人工智能加速器和网络的速度,这就需要超规模集群和更有效的互连。我们的立场是消除any-to-any网络连接,这是适应LLM训练的网络需求和维持LLM增长趋势的第一步。我们正在努力在不影响性能的情况下减少语言模型的大小和资源需求。
LLM推理
论文中探讨了LLM的训练工作量,推理代表了LLM产品周期的另一个重要部分。与训练相比,推理需要的计算资源更少。每个 HB 域是一个推理服务域,并且Rail-Only连接有助于负载平衡多个推理域。
直连网络拓扑
数据中心运营商可以利用直连网络实现Rail间的互联。为了最大限度地提高此类设计的有效性,我们建议通过 NIC 接口拆分来增加连接到每个 GPU 的网络接口数量。此外,我们建议使用可重构光交换机为跨 HB 域的互连提供更大的灵活性。这种设计还允许为即将到来的与LLM不同的工作负载重新配置一些跨Rail的连接。我们相信,该设计与光学可重构网络交换机相结合,将为 AI-ML 集群开辟出一条新的研究路线。
其它 ML 工作负载和限制
虽然Rail-Only架构主要针对LLM网络设计,但与其它工作相结合时,对其他 DNN 任务来说也是高效的。最新研究试图使并行化策略和集体通信算法对任何 DNN 模型都具有带宽感知能力,这些模型已经产生了类似于 LLM 的流量模式。
我们设计的主要挑战是所有 GPU 之间的all-to-all通信,这通常出现在具有大量嵌入表的推荐模型中。转发方案会引起拥塞并降低all-to-all流量的性能。我们认为all-to-all流量是机器学习工作负载中最具挑战性的流量模式之一。一些潜在的解决方案包括通过over-subscribed网络重新引入小的any-to-any容量、利用快速可重构的网络结构,以及通过调整机器学习模型本身减少最初生成的all-to-all流量。
容错性
初看上去Rail-Only架构的容错能力似乎比标准 Clos 网络要差,假设任一网络中的Rail交换机发生故障,所有连接到故障交换机的 GPU 将变得不可用。但是,Rail-Only设计对交换机需求更少,这就减少了故障点。数据中心运营商可以通过添加额外的Rail交换机来增加冗余容量。与最先进的any-to-any网络设计相比,Rail-Only设计更具成本效益。直连网络还可以提高容错能力,即使控制平面发生故障,光交换机也可能继续工作。
SDNLAB公众号后台回复0817LLM,即可获取论文下载链接






