

原文作者:Ray Kinsella;Chris MacNamara;Georgii Tkachuk
文章来源:DPDK与SPDK开源社区
英特尔® AVX-512 为数据包处理工具包增添了强大的助力。近期即将发布一系列白皮书,重点介绍如何使用英特尔® AVX-512来编写数据包处理软件。
执行摘要
对于熟悉SIMD(单指令多数据)指令集的软件工程师而言,他们能够识别并利用SIMD指令进行优化,从而带来显著的性能提升。英特尔®高级矢量扩展512(英特尔® AVX-512)是英特尔最新一代SIMD指令集,与前几代相比,寄存器宽度、可用寄存器数量都增加了一倍,变得更为灵活,实现了颠覆式创新。自第一代英特尔®至强®可扩展处理器问世以来,英特尔®AVX-512就已投入使用,目前已在最新的第三代处理器中进行了优化,具有明显的性能优势。
本文档总结了即将发布的一系列白皮书的基本原理,后续的白皮书会重点介绍如何利用英特尔® AVX-512指令集编写数据包处理软件。英特尔® AVX-512是Network Transformation Experience Kit的一部分,详情参见链接https://networkbuilders.intel.com/network-technologies/network-transformation-exp-kits.
简介
英特尔®AVX-512是一组功能强大的SIMD指令集。图1显示的是64位整数运算,从英特尔®数据流单指令多数据扩展指令集(SSE)到英特尔®AVX-512指令集,每一代英特尔®架构SIMD的吞吐量都增加了一倍,最终实现了英特尔®AVX-512指令可在每次操作中处理512位数据的能力。
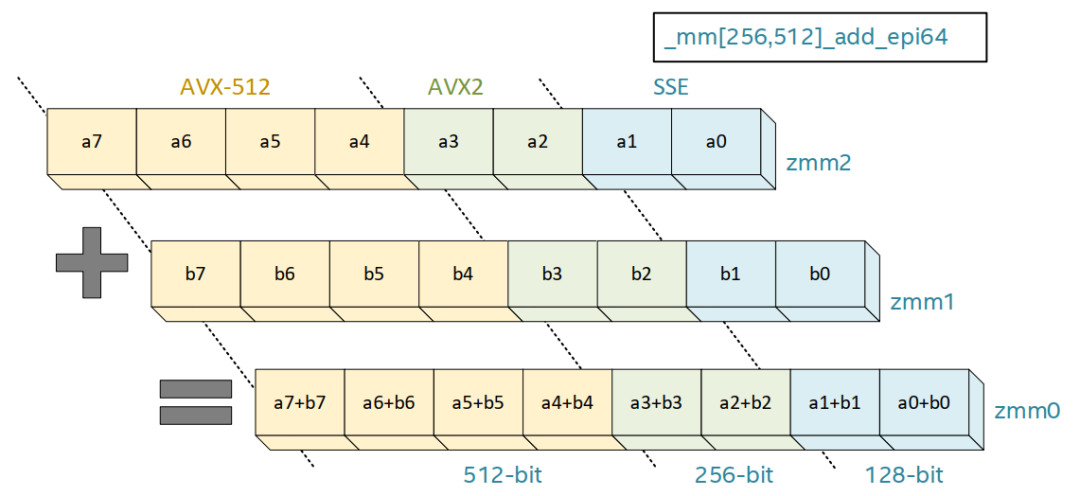
与历代指令集相比,英特尔®AVX-512指令集引入了以下新概念,变得更加灵活:
- 引入了掩码,首次允许在SIMD代码中进行类似分支的操作;
- 同时执行多项操作的三元操作,以及
- 指令集扩展,使英特尔® AVX-512能够随着微处理器的更新换代而不断发展。
英特尔® AVX-512微架构及其性能
第一代英特尔®至强®可扩展处理器(英特尔®微架构代号为Skylake)搭载了英特尔®AVX-512,这是该指令集首次在服务器产品中亮相。其中,微架构扩展了加载、存储和执行端口的宽度,以适应512位宽的指令。两个执行端口可用于运行Intel®AVX-512指令,最多可运行两个Intel®AVX-512指令,并行产生1024位数据。
英特尔®至强®可扩展处理器具有多种功率级别,对应不同的工作负载指令集组合和Turbo频率范围(见表1)。给定工作负载的指令集组合可包括整数和浮点指令,以及8位标量到512位SIMD寄存器宽度。

在工作负载执行期间,指令集组合的变化会导致给定处理核的功率水平发生变化,从而可以使能不同的频率范围集合。
采用英特尔®AVX-512指令集对OSI第2层及以上数据包处理应用进行优化,通常更倾向于采用AVX-512整数指令。这些应用程序通常在Intel®AVX2 Heavy / AVX-512 Light功率级别(Level 1)以及相应的Turbo频率范围内运行。此类应用程序的示例是基于DPDK和FD.io VPP开源软件,这些软件用于构建数据包处理应用。
在第一代英特尔®至强®可扩展处理器上,这意味着使用英特尔®AVX2高功率级别运行时,Turbo频率会降低,然后被使用英特尔® AVX-512指令相关的IPC增益所抵消。尽管Turbo频率略有降低,但使用英特尔®AVX-512指令后每个时钟周期内可以完成更多工作。
在第三代英特尔®至强®可扩展处理器(英特尔®微架构代号为Ice Lake)中,英特尔®AVX2高功率级别的频率范围得到了显著提升。这意味着在第三代英特尔®至强®可扩展处理器上,使用英特尔®AVX-512指令的IPC增益通常会得到保持或增强,与第一代英特尔®至强®可扩展处理器相比,Turbo频率范围有所提升(见图2)。
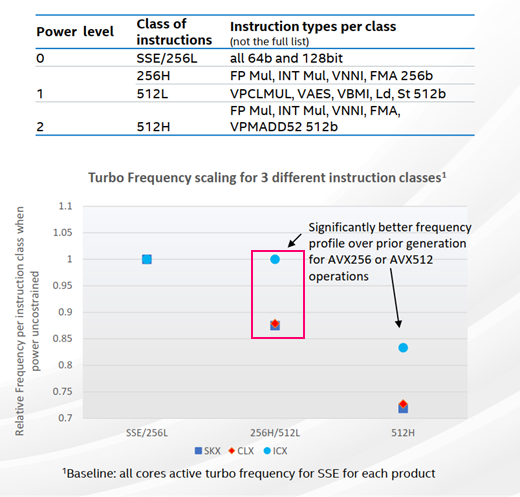
(来源:Hot Chips 2020 presentation)
在第一代英特尔®至强®可扩展处理器上,当处理核确定一个新频率并且指令没有失效时,功率级别切换可能会导致10-20 µs的阻塞时间。在第三代英特尔®至强®可扩展处理器中,频率切换效果得到了显著改善,阻塞时间减少到约0微秒,在不产生延迟的情况下即可实现切换。由于数据包处理应用通常采用轮询模式,这意味着在这些应用程序中,很少出现此类功率级转换。
英特尔®AVX-512指令集在DPDK应用程序的使用
自2014年以来,DPDK就一直使用SIMD指令来加速数据包处理应用程序,并在最新的20.11版本中借助英特尔®AVX-512指令集支持进行了优化。
在DPDK 20.11 中,有许多使用英特尔 ® AVX-512 指令来加速数据包处理算法的范例。比如,
- 英特尔®AVX-512指令集用于加速DPDK的轮询模式驱动程序(PMD),包括英特尔®以太网800系列(代号Columbiaville)、英特尔®以太网自适应虚拟功能(英特尔®AVF)以及Virtio PMD。
- 在访问控制列表(ACL)和转发信息表(FIB)库中,添加了英特尔®AVX-512指令集支持。
- 添加了两个新的API,分别是rte_get_max_simd_bitwidth和rte_set_max_simd_bitwidth,以便应用程序查询和启用DPDK中的英特尔®AVX-512指令。
DPDK ACL库用于开发数据包处理应用程序,例如入侵检测系统与入侵防御系统(IDS / IPS)。在DPDK ACL库中,使用英特尔®AVX-512指令集最多可并行搜索32个流,而使用英特尔®AVX2指令集最多可并行搜索16个流,英特尔®SSE 4.2指令集最多可并行搜索8个流。
如图3所示,与使用ACL流查找微基准进行测试的标量查找相比,英特尔® AVX-512 指令集将 DPDK ACL 库的流搜索性能提高了 3 倍。

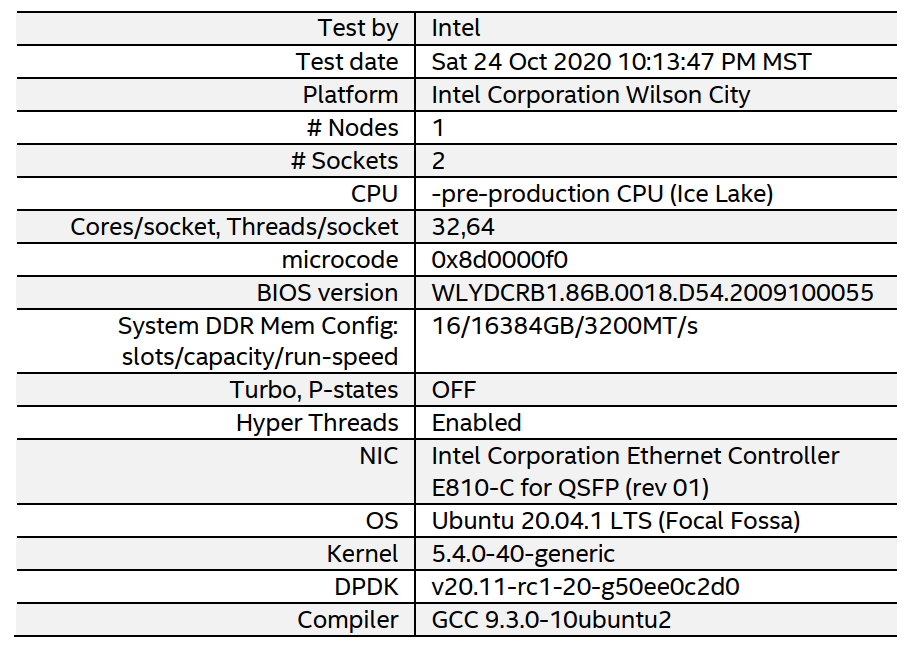
图3. 基于第三代英特尔®至强可扩展处理器,使用DPDK L3FWD-ACL和DPDK-TEST-ACL示例应用,配置4096条流和4096个ACL规则,测试单核和单线程下的64字节数据包性能
在层3转发应用程序中使用相同的DPDK ACL库时,英特尔®AVX-512指令集将数据包处理性能提高了1.35 倍。表2详细介绍了测试配置。
DPDK使用英特尔® AVX- 512指令集的另一个例子是DPDK FIB库,后续发布的白皮书会对此进行详细介绍。
英特尔®AVX-512指令集在FD.io VPP应用程序中的使用
FD.io VPP在20.x发行版中添加了对英特尔®AVX-512指令集的支持,并且以图形节点多架构变体的形式,呈现在终端用户面前。
FD.io VPP被设计为一个数据包处理节点的有向图,图中的每个节点负责数据包处理流水线的一个功能。例如,ip4-input节点执行IPv4协议检查,ip4-rewrite节点重写目标MAC地址(见图4)。
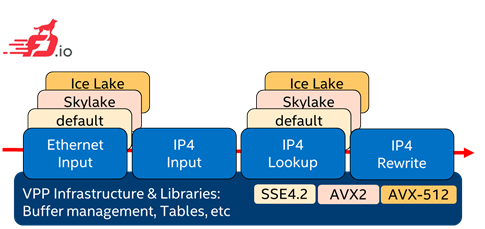
[Skylake和Ice Lake分别是第一代和第三代英特尔®至强®可扩展处理器的代号]
多架构变体可以针对性能敏感的图形节点进行特定架构的优化。它们跟原始(默认)图形节点执行相同的功能,但通过某些特定架构的方式进行了优化。
例如,第一代和第三代英特尔®至强®处理器的以太网输入和IPv4-lookup图形节点就有特定的变体。在运行时,FD.io VPP 会选择针对其执行的微处理器优化过的图形节点变体。
在FD.io 20.09版本中,有适用于第一代和第三代英特尔®至强®处理器架构等的图形节点变体。当在第三代英特尔®至强®处理器上执行时,运行环境会自动选择Ice Lake 图形节点变体,并自动启用第三代英特尔® 至强®处理器特有的英特尔® AVX-512优化。
在后续发布的白皮书中,将详细介绍多架构变体以及使用英特尔®AVX-512指令集优化FD.io VPP的示例。
结论
英特尔®AVX-512是数据包处理工具包中新增的一款功能强大的指令集架构(ISA),具有加速数据包处理的强大能力。最新的DPDK和FD.io版本,让构建使用英特尔® AVX-512指令进行加速的数据包处理应用变得更加容易。
下一代数据包处理应用基于英特尔®架构的英特尔®AVX-512指令集进行优化,DPDK和FD.io已经为此奠定了坚实的基础。从现在起,开始优化你的应用程序吧。








