

李笑来在谈到有关“机会”的文章时提到:人们在哀怨又错过逝去的机会同时,此刻的机会也是一直存在的。我们要做的是认清大趋势,并且坚定的执行。

为了举例,他甚至创造了一个词叫GAFATA:就是谷歌、亚马逊、脸书、苹果、腾讯、阿里的首字母缩写。如果大趋势是互联网将成为终将建成的新世界,那么这里面的巨头-GAFATA的盈利能力也是一定会大几率变成新世界的主宰,那么定投这些公司,也许短期波动,但长期无风险,因为大趋势在那里。
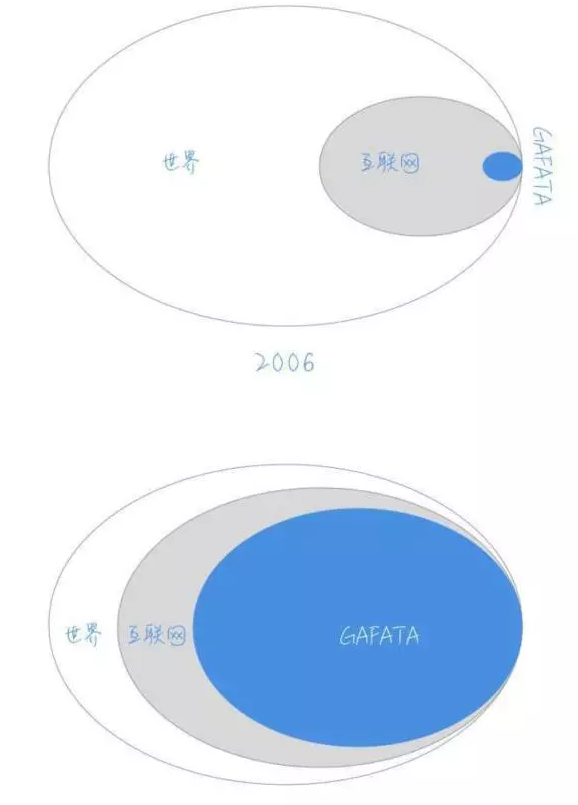
这个趋势对网络设备提供商来说,也许并不是一个很好的消息。众所周知GAFATA因为自身体量巨大,已经在大规模的深度定制自己的计算和网络,蚕食原有的企业数据中心市场。同时,因为他们提供的云服务的易用性,今天的中小企业,更加方便的从云端敏捷的开启他们的业务。云一定会蚕食掉原来的中间链条:从基建、HVAC、安保、网络、计算、存储、操作系统、数据库。那么对于中间设计、实施这些链条的攻城湿们,也将是一个灭顶之灾。如果我们略过中间状态,但是会不会有这么一天:GAFATA总共几百人的团队,就可以运维全世界99.99%的数据中心基础架构?
回到今天,我们可以通过他们的架构,看看趋势压(jue)一个惊(wang)。选择facebook为切入点是因为脸书的公开化作的最好,所有的开源项目大家都可以在code.facebook.com找到。除了他们领导的安卓、web等软件的开源项目外,也可以看到OCP、TIP等硬件project的详细内容和进度。
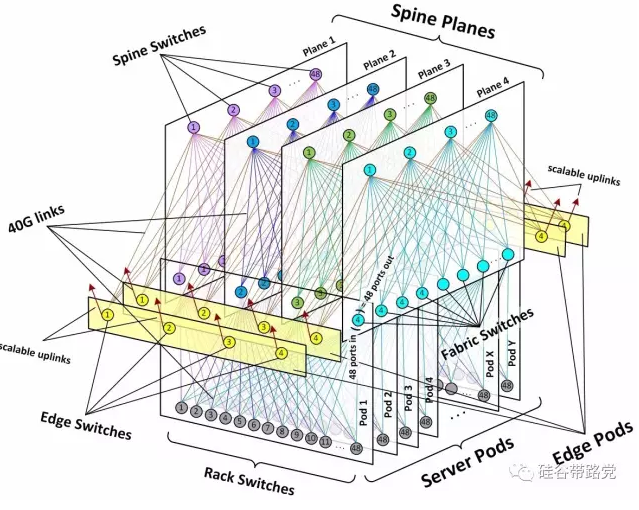
上图是一个facebook的网络架构,几个核心设计思想在:
Hyperscale。有两层含义、一个是可以支持超大规模、另一个是超弹性(scalability)、可以快速扩展容量。同时支持超强的容错能力。
Dis-aggregate。非汇聚,使用标准的“小盒子”网络设备替代超大汇聚网络设备(网络厂商泪点)。为适合大量的横向流量而设计的低超订率(oversubscription)网络。
Simple。从各个方面简化和模块化网络:布线、计算单元(pod)、部署上线、自动化。
为什么会有这些主导思想?Facebook并没有一步到位今天的设计,他们也一样进过坑,之前的design叫做《“4-post” Data Center》,如下图:
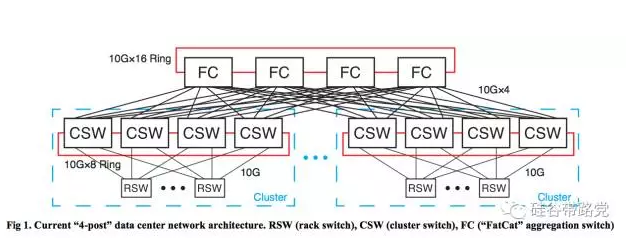
这个网络的特点:
每个Rack的机架交换机(RSW)有44条下行10G的链路连到最多44个服务器,4条10G上行链路,10:1的oversubscription超订率;
每个簇交换机(CSW)有4条 40G捆绑链路上行到FC“肥猫”核心交换机,大致是4:1的超订率;
4个CSW和几十个RSW以及连接的服务器们,组成了一个Cluster。
Facebook在使用中,发现了一些问题:
“4-post”可以直译为4根桩子、可以看到大量的机架交换机汇聚到4台CSW,然后大量的CSW汇聚到4台FC,这样就意味着,一旦有一台CSW或者FC掉线,那么网络传输能力立即降25%。
这些能力强的顶梁柱交换机,只有少数的供应商有能力提供。提高了成本:每带宽的CAPEX和OPEX都高一些。客观上被这些厂商的road-map lockin了,表现为修bug慢、不够开放店大欺客、监控管理各有不同平台有差异。
核心交换机的fabric内部也有超订率,意味着有时不能使用全部的端口性能;核心交换机的端口密度能力决定了扩展的能力;
脸书逐渐发现,数据中心中横向的“机器到机器”流量增长速度大大超越了垂直的“机器到人”的流量,如果横向流量在一个Cluster内,那还好,但是因为业务的扩展,流量常常是跨簇的。这时,如果上层应用要考虑到下层网络和计算连接的情况时,这种汇聚模型就不再适应业务的增长。
这时我们再回头来理解新的网络架构就轻松很多:
抛弃了由CSW定义的簇大小,改为由48个机架交换机上联到4台Fabric交换机定义的一个计算单元(pod)。
每个机架交换机有4条40G的上行链路,48条10G到服务器的下行链路。超订率减少到了3:1;

对于每一台Fabric交换机,可以上行到至多48台的Spine“脊柱”交换机。重点是:在任何pod之间,是没有超订率的,解决了横向流量的问题。
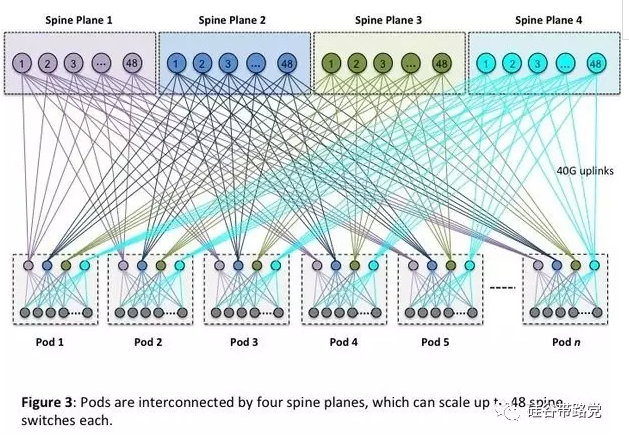
至此、这个网络在任何一点都可以随时、任意扩展:
如果需要更多计算能力,就加pod;
如果需要更多的fabric,可以增加和连接到edge switches;
如果需要spine的交换能力,就加spine switches。
这个网络的一个问题在于连接数和连接端口非常多,所以cabling也是一个问题,脸书用了BDF(Backbone Distribution Frame-我猜的)区域,在建数据中心时,部署大量直线相连的光纤可以清爽的部署连接,如下图:
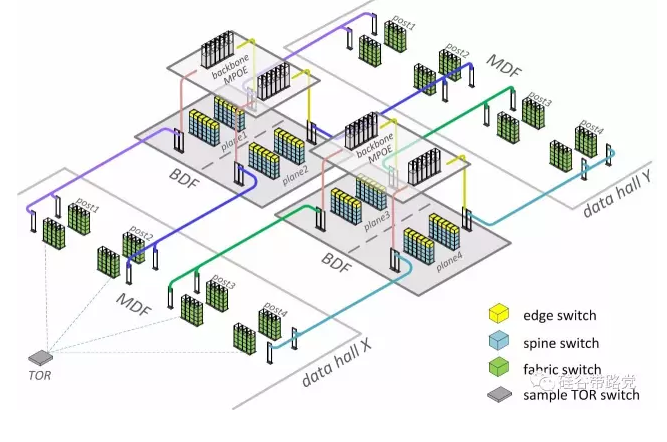
网络到了这个程度、有一点是肯定的:这个网络不再能被人来管理,自动化是已经成为刚需。
脸书的方法是把网络在整个fabric的层级进行管理。这些白盒交换机的硬件软件解耦,也可以让他们对特性进行简化和配置进行定制化,以支持fabric层面的整体配置。
同时,简化的网络和简化的计算单元也可以让网络具备自动发现、自动部署的能力。对于网络运维来说,可以做到并行部署、随时更换。
网络的架构师这样说道:在设计这个网络时,他们遵从的是美国海军的KISS原则:“保持简单、蠢”。这个原则最终让乐高积木似的整体设计简单又健壮、从设计到自动化都力图确保减少人为的维护量。
如果将这个架构zoom in,就会看到各种定制设备的踪影。至此也非常容易理解:无论是从成本、从业务、从可视性、从自动化,深度定制的硬件软件解耦设备的流行都是必然。机器也将接替运维团队接管网络。
各位攻城湿:何去何从?
转载自公众号“ 硅谷带路党”,作者“Frank同学”








