

目前,许多 HPC和 AI工作负载的最大瓶颈就是带宽——网络带宽、计算带宽和内存带宽。无论单个芯片能以高精度进行多少万亿次浮点运算,一旦工作负载超出单个加速器、节点或机架,带宽很快就会成为制约因素。
芯片制造商正试图从多个层面上解决带宽问题,他们在芯片上封装了更多的高带宽内存,提高互联速度,并使用Chiplet来突破限制。
从SoC走向Chiplet
我们所熟知的SoC(片上系统)是将数个不同芯片经过重新设计并集成于单一芯片上。在SoC中,因为是在一个芯片中进行集成的,所以各个功能模块必须采用同一工艺制程。
Chiplet,俗称芯粒,也叫小芯片。与SoC相反,Chiplet将原本SoC中的每个功能模块单独分拆出来,做成具有单独功能的一个个小芯片单元。这些小芯片可以使用相同或者不同的制程工艺进行制造,再通过跨芯片互联和封装技术进行封装级别集成。

与传统的单片芯片设计相比,Chiplet具有多种优势:
- 能够给不同的模块分配不同的制造工艺,甚至分配给不同的制造商;
- 能够在小芯片集成之前对其进行分类或预测试,从而提高最终器件和大型芯片的良率;
- 能够在不重新设计整个单片芯片的情况下升级处理器的一部分。
在摩尔定律已经百尺竿头,“难”进一步的情况下,像乐高积木一样的Chiplet正在成为芯片巨头延续摩尔定律的共同选择之一。
2022年3月,由英特尔、AMD、ARM、ASE、谷歌、 Meta、微软、高通、三星和台积电等企业联合开发和制定的Die-to-Die互连标准——UCIe 1.0正式推出。UCIe标准的初衷和目标,是建立一套Chiplet技术相关的设计和制造等各个环节的参考标准,从而使得不同设计和制造厂商的芯片可以无缝集成,从而打造封装层级的完整灵活的芯片开发生态系统。

UCIe的问世,对Chiplet 的发展也起到了助推作用。据Omdia报告,2024年Chiplet的市场规模将达到58亿美元,2028年将超过160亿美元,2035年则会超过570亿美元,也就是近10年10倍。
随着技术的不断进步和应用场景的不断扩大,Chiplet技术在AI芯片中的应用前景也将更加广泛。机构表示,有将近30%的高性能CPU和GPU采用了Chiplet技术设计,包括英特尔、AMD、英伟达、海思、Marvell、亚马逊等等。
英特尔的“Ponte Vecchio”Max系列GPU和AMD的“Antares”Instinct MI300X GPU就是使用Chiplet来突破带宽限制的典型例子。
AMD
2019年起,AMD从Zen2架构开始采用Chiplet技术。AMD基于自己的建构Chiplet生态系统,生产了Ryzen和Epycx86处理器。2022年AMD正式发布了采用RDNA3架构的新一代旗舰GPU,即RX 7900 XTX和RX 7900 XT。AMD表示,这是公司首度在GPU产品中采用Chiplet技术。
2023年6月,AMD发布了GPU“ Instinct MI300X”。据介绍,Instinct MI300X是AMD使用有史以来最先进的生产技术打造,是Chiplet设计方法的“代表之作”。这款基于Chiplet设计的加速器拥有8个基于3D堆叠的5nm小芯片,和4个基于6nm的小芯片,周围封装了8个128GB的HBM3显存芯片,共拥有1530亿个晶体管。最终成品功耗750W,包含304个计算单元、5.3TB/s带宽,以及高达192GB的HBM3内存。

英特尔
2023年1月,英特尔正式发布集成47块小芯片、包含有超过1000亿晶体管的英特尔数据中心GPU Max系列(代号为Ponte Vecchio)。

GPU MAX 系列利用英特尔自家的 Foveros 和 EMIB 技术构建,通过多达 47 颗小芯片的堆叠,为每个不同小芯片单元分配 5 种不同制程。其中,Base tile 和 HBM2e SerDes 使用 Intel 7 工艺,计算单元采用 TSMC N5 工艺。GPU MAX 系列具有多达408MB 的 L2 缓存和 128GB 的HBM2e 显存,提高了可吞吐量和性能,充分体现了 Chiplet 的理念。英特尔表示,使用 Max 系列 GPU 的大型二级服务器,其 AI 工作负载的性能获得了 2 倍提升。
但是在Chiplet逐步发展的过程中,随着小芯片数量的增加,芯片制造商必然会遇到带宽和延迟的挑战——电气连接的小芯片会增加更多的功耗和带宽/延迟。
硅光互连
为交换计算所需的数据,在单个封装中连接的小芯片越多,它们之间必须具有的互连就越多,这些小芯片以电信号的形式相互交换数据。电的速度很快,但光的速度更快。几十年来,光学一直致力于解决电气 IO 的瓶颈。
Lightmatter
2017年诞生于麻省理工学院(MIT)的初创公司Lightmatter 开发了一种晶圆级光子互联方案 Passage,它允许小芯片以光而不是电的形式共享数据。
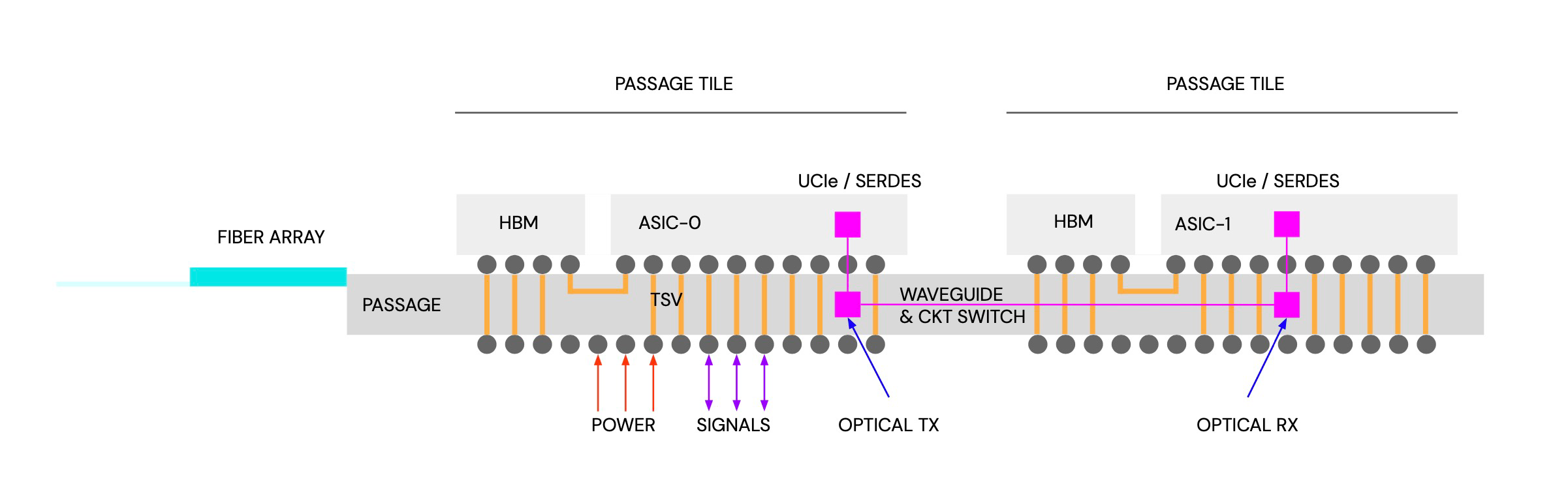
Lightmatter的核心思想在于,通过替代电信号,用光连接技术在芯片间更快速地传输数据,同时大幅减少因热量而造成的能量损耗。当前,Lightmatter提供三种产品:光子人工智能芯片Envise;晶圆级可编程光子互连系统Passage;允许硬件与标准的深度学习框架对话的软件层Idiom。三者构成了一套完整的硬件和软件解决方案,具有实现光子计算和互连技术的优势。
Passage方案基于硅光和共封装光学(CPO)方案,将Chiplet处理器互联在一起。就像英伟达HGX A100的PCB/电路方案一样,只不过把NVSwitch这样的互联方案换成了光子通路。Passage 没有使用光纤而是使用纳米光子波导将多个芯片互连,可以以极低的损耗和极高的带宽传输光子。
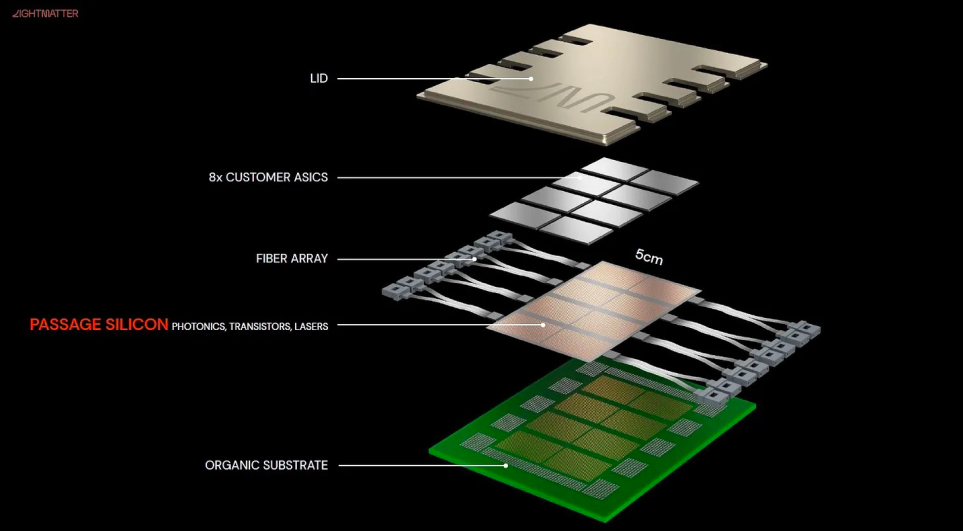
Passage 与硅之间的连接是电气连接,光电转换发生在中介层(interposer)内。这意味着 Passage 可以重新映射以适应新芯片,同时也无需将光子学集成到计算本身中。Lightmatter 首席执行官 Nick Harris 称 ,Lightmatter 现在有客户使用 Passage“扩展到 300000 个节点的超级计算机”。Harris没有透露这些客户是谁,但他表示,公司正在与“大量购买”的主要半导体合作伙伴和云提供商合作。
2023年12月,Lightmatter在 C-2 轮融资中筹集了 1.55 亿美元,估值为 12 亿美元。迄今为止,Lightmatter已经筹集了超过4.2亿美元的资金,估值目前已超过12亿美元。
当然,Lightmatter 并不是唯一一家利用AI炒作的硅光子初创公司。
Celestial AI
初创公司Celestial AI 去年7月完成了B轮融资,为其Photonic Fabric技术平台筹集了1亿美元。与 Lightmatter 的 Passage 非常相似,Celestial 的Photonic Mesh 涵盖了chip-to-chip、package-to-package和node-to-node 的连接。
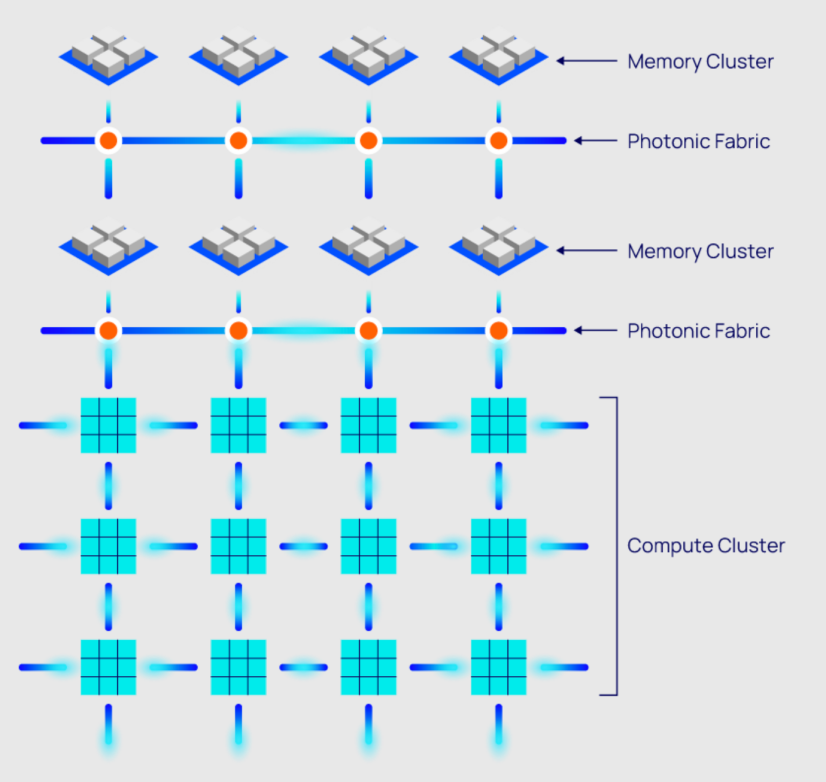
Celestial AI的首席执行官Dave Lazovsky表示:“未来的关键问题是大语言模型和推荐引擎工作负载的内存容量、带宽和数据移动(芯片与芯片之间的互连)。”随着数据中心内传输的数据量增加,数据传输速率也必须提高。随着这些速率的增加,电气互连会遇到诸如信号保真度损失和有限带宽的问题,无法随数据增长而扩展,从而限制了整体系统吞吐量。
Celestial AI表示,与传统电气互连相比,Photonic Fabric的低延迟数据传输促进了连接和解聚更多服务器的能力。这种低延迟还使得延迟敏感的应用可以利用远程内存,这在传统电气互连中以前是无法实现的。
Ayar Labs
当然,还有 Ayar Labs,该公司自 2015 年起就一直在开发硅光小芯片。Ayar Labs 的产品可以拆分为两部分:1. TeraPHY:光信号互联芯片,负责处理光电信号,完成信号之间的转换和收发;2. SuperNova:独立激光器,负责精准地发出多个波长的光子。在具体实践中,SuperNova 需要和 TeraPHY 组合使用,二者通常以下图中的链路互联:
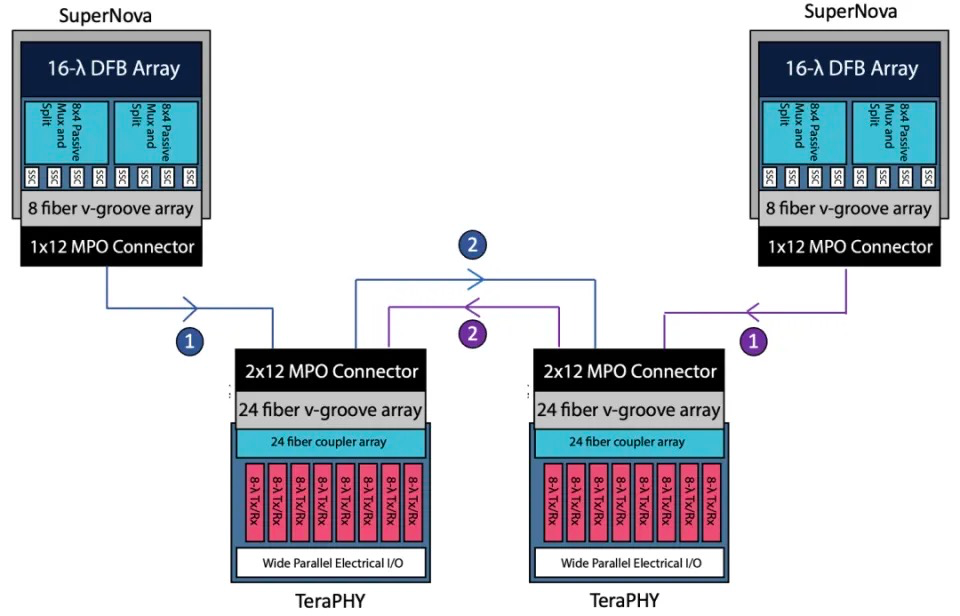
英特尔根据 DARPA 合同开发的并行图形处理单元使用了 Ayar Labs 扩展到数百万个线程。迄今为止,Ayar Labs已筹集约 2.2 亿美元,其中包括 2022 年初英特尔和英伟达注入的 1.3 亿美元现金。
除了初创公司外,AMD 也一直在探索光子技术,以实现其架构的信息传输。英特尔则专门开设了数据中心互连集成光子学研究中心。可以说,如今的硅光领域并不缺乏竞争,至于未来将如何发展,也要交由市场来验证。
参考链接
https://zhuanlan.zhihu.com/p/656275739
https://new.qq.com/rain/a/20230525A003D200/
https://www.nextplatform.com/2024/01/04/how-lightmatter-breaks-bandwidth-bottlenecks-with-silicon-photonics/





