

在AIGC迅猛前进的道路上,智能算力作为AI网络的基石,是支持AI大模型训练和推理的关键;高性能网络则是AI网络基础设施的纽带,推动更高性能的网络互联成为业界重要的探讨方向。本文整理了部分单位公开发表的技术白皮书,这些白皮书不仅记录了AI网络的最新趋势和进展,还提供了各家企业在网络设计、部署和管理等方面的宝贵见解。
*本文对每本白皮书作了简要介绍,文末可获取下载链接。
01
《面向 AI 大模型的智算中心网络演进白皮书》

近年来,随着 ChatGPT 等生成式人工智能的突飞猛进,全球范围内的经济价值预计将达到数万亿美元。尤其在中国市场,生成式 AI 的应用规模有望在 2025 年突破 2000亿元。这一巨大的潜力不仅吸引着业内领军企业竞相推出万亿、10 万亿参数量级别的大模型,而且对底层 GPU 支撑规模提出了更高的要求,达到了万卡级别。然而,如何满足如此庞大规模的训练任务,对网络的规模、性能、可靠性和稳定性等方面提出了前所未有的挑战。
在这种情况下,寻求提供极致高性能网络已成为人工智能领域的重要研究方向之一。该白皮书从 AI 大模型发展情况、AI 大模型下智算中心网络的需求、当前技术与需求的差距及技术演进四个方面,开展了相关研究,
AI 大模型对网络的需求主要体现在规模、带宽、稳定性、时延/抖动以及自动化能力 5 个方面。从当前数据中心网络的实际能力来看,完全匹配 AI 大模型的需求在技术上仍然有一定的差距。智算中心网络作为连接 CPU、xPU、内存、存储等资源重要基础设施,贯穿数据计算、存储全流程,算力水平作为三者综合衡量指标,网络性能成为提升智算中心算力的关键要素,智算中心网络向超大规模、超高带宽,超高稳定性、超低时延、自动化等方向发展。
02
《星河AI网络白皮书》

全球智能化如火如荼,AI大模型蓬勃兴起。然而,大模型训练是个复杂的系统工程,需要更高的计算能力和更多的数据传输需求,网络基础设施在AI大模型中将会扮演关键角色。我们需要提供极致的通信性能、计算能力和稳定性,以支撑万亿级甚至更高规模参数的模型训练。如何通过网络技术突破来满足训练任务的规模、效率需求,已成为一个非常关键的研究方向。
该白皮书旨在深入分析 AI 大模型训练对网络的新需求,探索网络技术发展新方向,为构建面向 AI 大模型的高性能训练网络提供参考,从大模型训练的发展历程和业务需求角度出发,分析网络与其应用之间的差距,并探索如何通过技术创新优化网络,以便更好地服务于大模型训练。
星河AI网络打造AI时代最强算力,以网强算,释放AI生产力。具体体现在以下几方面:
(1)网络高性能:端口高吞吐和网络高吞吐;
(2)高可靠:故障链路亚毫秒级快速切换;
(3)可运维:通信异常一键诊断;
(4)大规模:超大规模算力集群;
(5)开放性:标准以太RoCE高效开放。
03
《中国移动NICC新型智算中心技术体系白皮书》

当前各国政府已全面布局 AI,作为 AI 技术发展的关键底座,智算中心的建设和部署在全球范围内提速。然而,早期建设的智算中心,以承载中小模型、赋能企业数智化转型为主要目的,在技术标准、生态构建、业务发展和全局运营等各方面仍有待提升。当追逐大模型成为行业标准动作,面向大模型的新型智算中心(New Intelligent Computing Center,NICC)成为新时期关注的焦点。
区别于早期建设的智算中心,NICC 新型智算中心是以高性能 GPU、AI 加速卡等集群算力为核心,集约化建设的 E 级超大规模算力基础设施,具备从硬件设施到软件服务的端到端 AI 全栈环境,支撑超大规模、超高复杂度的模型训练和推理业务,最终赋能行业数智化转型升级。

NICC 技术体系由“三层两域”构成,分别是基础设施层、智算平台层、应用使能层、智算运维域和智算运营域。其中基础设施层提供计算、存储、网络等硬件资源;智算平台层作为资源管理的核心,提供裸金属、虚机和容器等多样化实例以及细粒度的资源池化能力,在此之上搭建算力原生平台提供应用跨架构迁移能力;应用使能层集成行业主流 AI 开发框架以供应用开发调用。智算运维域主要负责对底层 IaaS资源进行管理维护,确保系统的稳定运行;智算运营域对接外部客户,提供计量计费、访问、交易等界面,对内根据上层任务进行资源编排调度。
04
《智算中心网络架构白皮书》

近期,大模型的发展成为 AI 领域最重要的热点趋势,而训练超大参数规模的大模型也给智能计算基础设施带来了前所未有的挑战。大模型的训练过程需要数千张 GPU 卡协同计算数周或数月,这就要求智能计算网络能够提供更强大的性能和更高的稳定性与可靠性。因此,提供一种高速、低延迟且可扩展的网络互联方案成为了智能计算领域的重要课题。
通常,大中型政务、金融及企业客户对网络安全与数据隐私保护有着更严格的要求,需要通过私有云建设模式在自有数据中心中构建自主可控的智能计算资源池,为人工智能的创新服务提供底层算力支持。智算网络作为智算中心基础设施的重要组成部分,其选型、设计和建设方案是非常关键的环节,网络架构设计的合理性直接影响智算集群的性能、可靠性与稳定性。智算网络的选型和建设阶段的典型问题包括:
(1)智算网络是复用当前的 TCP/IP 通用网络的基础设施,还是新建一张专用的高性能网络?
(2)智算网络技术方案采用 InfiniBand 还是 RoCE ?
(3) 智算网络如何进行运维和管理?
(4)智算网络是否具备多租户隔离能力以实现对内和对外的运营?
本白皮书将分析智算业务对网络的核心需求,深入介绍智算网络的架构设计以及智算中心高性能网络的运维和运营管理方案,并结合典型实践,提供智算网络选型建议,为客户建设面向大模型的智算中心提供网络建设、运维和运营参考。

05
《全调度以太网技术架构(GSE)白皮书》

分布式并行计算是实现 AI 大模型训练的关键手段,所有并行模式均需要多个计算设备间进行多次集合通信操作。另外,训练过程中通常采用同步模式,多机多卡间完成集合通信操作后才可进行训练的下一轮迭代或计算。智算中心网络作为底层通信连接底座,需要具备高性能、低时延的通信能力。面向未来智算中心规模建设和 AI 大模型发展及部署需求,中国移动联合多家合作伙伴推出了全调度以太网技术方案(GSE),打造无阻塞、高带宽及超低时延的新型智算中心网络,助力 AIGC 等高性能业务快速发展。
全调度以太网是具备无阻塞、高吞吐、低时延的新型以太网架构,可更好服务于高性能计算,满足 AI 大模型部署及训推需求。全调度以太网架构自上而下分为三层,分别为控制层、网络层和计算层,其中关键点在于创新的引入一种全新的动态全局队列调度机制。动态全局调度队列(DGSQ)不同于传统的 VOQ,其不是预先基于端口静态分配,而是按需、动态基于数据流目标设备端口创建,为了节省队列资源数量,甚至可以基于目标或途径设备的拥塞反馈按需创建。基于 DGSQ 调度以实现在整个网络层面的高吞吐、低时延、均衡调度。

06
《HPC无损以太和Al Fabric网络技术白皮书》

从业界以太网络基于从10GE向400GE 带宽增长的趋势来看,随着计算规模的不断扩展,原有很多基于 IB 建立的网络无论从带宽介质形态,端口密度等都需要扩容,相对于生态封闭的IB网络,业界倾向于采用无损以太网替换原有 IB 交换机以降低成本,无损以太网络技术的飞快进步成为趋势。
无损以太网络技术作为一种高吞吐、低延迟的网络解决方案,具有智能RDMA、网络级负载均衡等特征,实现转发零丢包、90%超高吞吐。在HPC和AI场景中得到了广泛应用。未来的无损以太网络将更加注重软硬件的融合,从而实现更灵活、更可扩展的网络架构。网络虚拟化技术也将在无损以太网络中发挥更重要的作用,使大规模的网络管理更加简便和高效。
此外,在AI大模型火热的今天,如何有效训练这些大模型成为各大企业关注的焦点。无损以太技术给大规模GPU集群带来了高质量的网络底座,助力超大模型的高效训练。AI技术将应用于网络管理、故障预测、负载均衡、安全防护等领域,提高无损以太网络的智能化水平。此外,AI技术还可以辅助进行网络规划、设计和优化,使网络资源得到更有效的利用,进一步提高网络性能。
07
《新型智算中心算力池化技术白皮书》

智算中心作为集约化建设的算力基础设施,以 GPU、AI 芯片等智能算力为核心,提供软硬件全栈环境,支撑千行百业数智化转型升级。然而传统智算中心的智算资源利用率较低,资源分布相对碎片化,不利于整体效能的提升,亟需一个可聚合各类型算力、实现敏捷化资源管理的平台,使能资源可以被极致利用,算力池化技术应运而生。
智能算力池化指依托云计算技术,整合 GPU/AI 芯片等异构算力资源,构建集中管理的资源池,并按上层智算业务的需求,对池化的资源进行统一调度、分配,实现智算业务生命周期管理的全套技术。为解决智算中心所面临的资源利用率问题,算力池化基于传统云计算技术有针对性地增强 GPU/AI 芯片池化能力,采用软件定义的方式,对 GPU/AI 芯片进行分时调度管理,实现按 GPU/AI 芯片的细粒度分配资源,并采用 GPU/AI 芯片 Runtime API 劫持、应用程序监视器等技术,实现资源跨节点远程调用、零散资源整合等,从而达到算力资源充分利用、碎片最小化效果,可有效提升资源效率,降低智算中心整体建设成本。
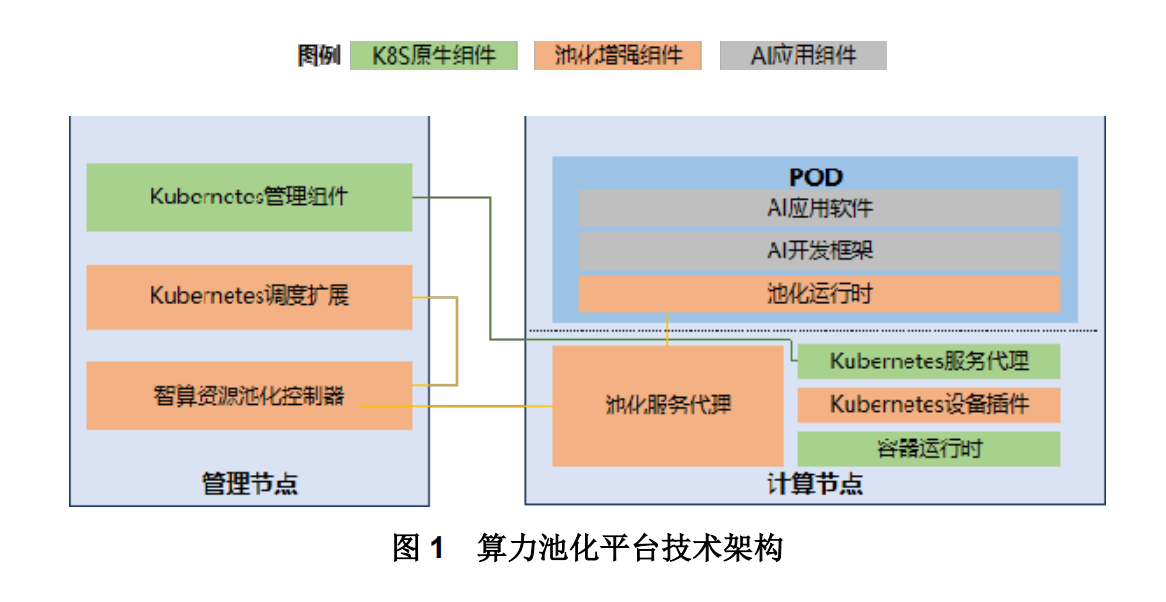
本白皮书分析了智能算力发展的趋势及面临的挑战,系统性介绍了算力池化的定义与目标、总体架构、关键技术和当前业界的探索实践,并呼吁业界紧密合作、加快构建算力池化统一的标准体系。
08
《新一代智算中心网络技术白皮书》

算力网络是联接算力供给端和需求端的重要桥梁,也是未来经济发展的重要衡量指标之一。“算力为中心,网络为根基”,网络贯穿算力的生产,传输和消费全流程,一张具有超大带宽、超低时延、海量联接、多业务承载的高品质网络是关键。
该白皮书主要研究智算中心发展情况、智算中心网络发展趋势以及满足智算中心发展需求的智算中心网络关键技术,通过在超大规模网络关键技术、超高性能网络关键技术、超高可靠网络关键技术以及网络智能化关键技术等方面的探索,为未来面向智算中心的新型网络架构提供参考。

传统数据中心,面向传统的计算处理任务,或离线大数据计算,以服务器/VM 为池化对象,网络提供 VM/服务器之间连接,聚焦业务部署效率及网络自动化能力。智算中心是服务于人工智能的数据计算中心,包括人工智能、机器学习、深度学习等需求,以 GPU 等AI 训练芯片为主,为 AI 计算提供更大的计算规模和更快的计算速度,以提升单位时间单位能耗下的运算能力及质量为核心诉求。智算中心将算力资源全面解耦,以追求计算、存储资源极致的弹性供给和利用,以算力资源为池化对象,网络提供 CPU、GPU、存储之间总线级的高速连接。
关注SDNLAB公众号,后台回复1009人工智能网络,即可获得白皮书下载链接。







