

5月24日,由“科创中国”未来网络专业科技服务团指导,江苏省未来网络创新研究院主办,SDNLAB社区承办的2022网络开源技术生态峰会盛大开幕,在下午的P4技术与应用分论坛,阿里巴巴技术专家、哈佛大学博士高佳琦为大家带来了《太玄:阿里云自主研发的可编程网络编译平台》主题演讲。
可编程交换机在学术界和工业界受到了广泛关注,凭着其可定制化及高性能在多个场景中都有显著的性能提升。比如说共识算法、负载均衡、网络检测、存储、拥塞控制算法等,几乎所有的主流交换机厂商都推出了自己的可编程芯片,比如说博通生产的Trident 4和Jericho 2 芯片,思科推出了Silicon One,英伟达和英特尔也推出了自己的可编程芯片。

高佳琦表示,在众多的云厂商中,阿里巴巴是可编程网络的先行者。阿里巴巴在边缘云和数据中心网关中都部署了可编程交换机,包含负载均衡、流量控制、调度、DDoS防御等功能。以边缘云为例,阿里将新闻、视频、游戏等应用部署在了离用户更近的位置,使用户能够享受到更高质量的服务。阿里巴巴在超过1000个节点中部署了可编程设备,为全球的客户提供了高质量的网络服务。

可编程网络的开发仍然处于萌芽阶段
在部署过程中,阿里巴巴发现可编程网络的开发仍然处于萌芽阶段,这个问题在开发、优化和测试的各个阶段当中都有体现。
在开发阶段,程序员使用的编程语言和指定芯片强绑定,不具有跨芯片的移植性、扩展性以及组合性。
在优化阶段,程序员需要依赖编译器提供详细的报错信息,以及先进的自动优化工具,来提升程序的资源利用率,减少浪费在手动优化上的时间。
在测试阶段,需要形式化验证和自动化的测试工具,辅助程序员验证程序的正确性,这些能力在当前的可编程网络开发环境中都不具备,开发效率受到了很大的影响。

为了解决上述问题,阿里巴巴自主设计研发了太玄可编程网络编译平台(这里只介绍开发和优化阶段)。
太玄可编程网络编译平台——开发阶段
高佳琦介绍,在开发阶段我们遇到的挑战是与芯片强绑定的编程语言带来的诸多挑战,这些挑战类似于程序员使用汇编语言在CPU上编写软件程序,
以网络排序器为例,排序器为一致性的算法(如Paxos)提供了线性化的服务,可以提升一致性算法收敛的速度。
排序器有三个组成部分,第一部分是过滤表,根据网络报文的源IP过滤出需要添加的序列信息的流量,第二部分为添加序列号的动作。第三部分是路由表,根据目的IP将报文发送到对应的存储节点当中。
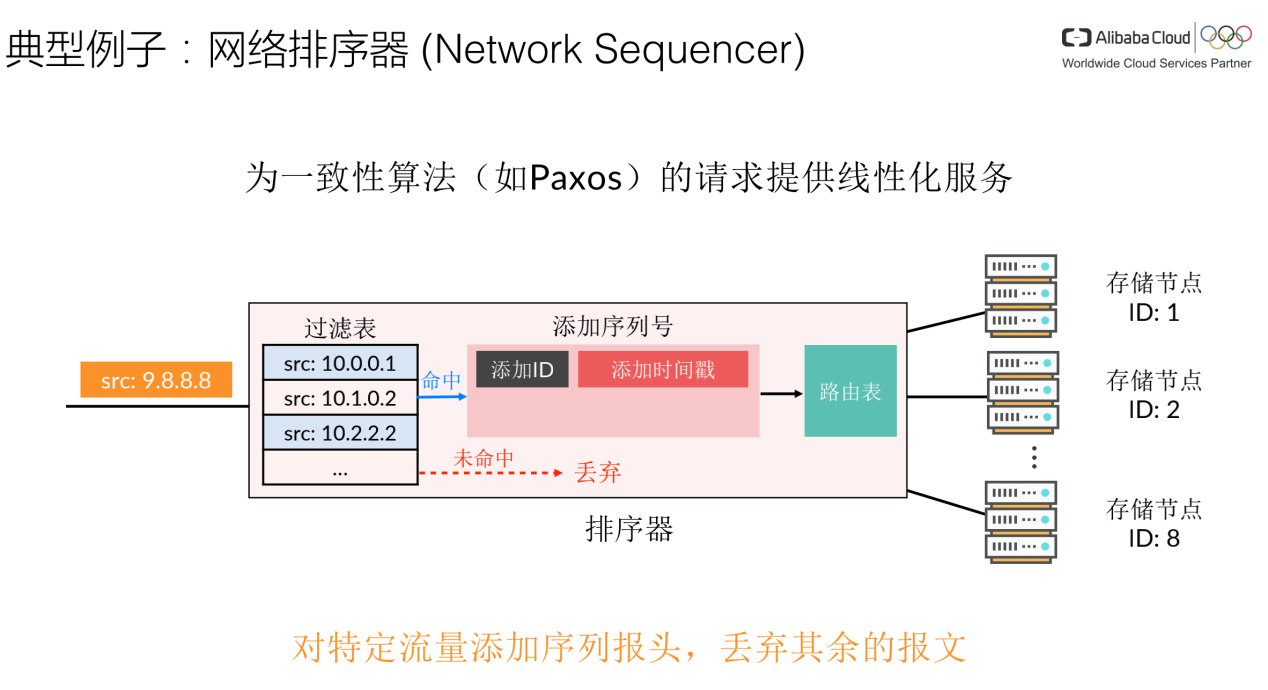
具体来说,当一个网络报文到达时,如果它命中了过滤表,那么排序器会添加序列报头,包括对应的请求ID以及报文到达的时间戳,并且依据转发表将其发送到对应的存储节点上。
如果流量没有命中过滤表,那么排序器会将其直接丢弃。
在开发上述排序器的时候,首先遇到的一个问题就是移植性,开发程序使用的语言是交换机强绑定的,在一种交换机上通过了编译可以运行的程序不能直接在另一种交换机上运行。此外,不同的可编程芯片提供了不同的API,甚至要求了不同的编程范式。对于开发人员来说,不同平台之间的迁移成本过高,极大影响了开发效率。
第二个问题是扩展性,当前的开发环境都是针对单个可编程设备,不支持跨机编程,缺乏扩展性带来的问题就是,一个很小的需求变更,因为资源限制等原因会导致大量的程序改写。
第三个问题是组合性,同一个可编程设备上会部署多个程序,如何在已经部署的程序中添加新的程序,保证正确性,同时确保各个程序之间互不影响,这是一个非常值得考虑的问题。现有的工具不足,只能依赖开发人员进行手动调整。

总的来说,开发可编程网络程序的核心问题有三点:移植性、扩展性和组合性,现有的开发环境并不具备这三个特性,开发人员就像使用汇编语言在CPU上开发软件一样,需要处理繁多的开发细节,显著降低了开发效率。
阿里云自主研发的太玄可编程网络编译平台,其中的核心组件太玄编译器可以自动将输入程序编译在多种交换机上运行,符合交换机要求的语言和API,同时确保多个程序可以互相配合又互不干扰。

太玄编译器有三个核心算法,语言生成器将输入程序编译到不同的平台上,提供不同芯片之间的移植性;芯片资源编码判断是否可以在指定交换机上成功编译,确保组合性;拓扑感知的代码编排算法,保证程序的正确部署,提供扩展性。

语言生成器:不同的可编程交换机有不同的编程语言,不同的编程语言有不同的编程范式。比如说p4语言的核心是匹配动作表,而NPL语言更类似于C语言是面向过程的编程范式。
这里我们介绍如何生成p4语言。p4程序本身是表的集合,p4语言定义的表以及表之间的先后顺序,这里面每一个表都要定义它要匹配的内容和根据匹配结果需要执行的动作。在每一个动作中都包含了若干的语句,每个语句都是并行的,互相之间没有依赖性。
那么如何将一个程序改写成p4语言呢?太玄编译器发现这里生成算法的核心是谓词块(Predicate block)。谓词块是所有具有相同执行条件的,没有依赖关系的一组语句。

比如说左边是一份排序器的程序,我们将其进行了一些处理,写成了执行语句和其执行条件的形式。可以看到这里一共有两个条件,第一个条件p1有4条语句,第二个条件p2有一条,在第一个条件中,第四条语句使用了第二三条语句的执行结果,因此依赖于这两条语句。
在生成谓词块的时候,p1的前三条语句可以被放置到同一个谓词块当中。第四条语句,因为它和前三条语句存在依赖,所以说只能生成一个新的谓词块,对于p2来说也是同理需要生成一个新的谓词块。
我们可以看到谓词块和p4的匹配动作表之间有相似之处,接下来我们就需要通过谓词块生成p4程序,下一步就要进行的操作是分析谓词块之间的关系。
我们发现谓词块一共有两种关系,当两个谓词块包含的语句之间存在读写依赖关系的时候,我们认为这两个谓词块之间存在依赖关系。这里两个蓝色的谓词块之间就存在我们说的依赖关系。
第二种是互斥关系,也就是说这两个谓词块的执行条件是互斥的,他们两个不能同时被执行。这里蓝色和红色的谓词块,因为他们执行条件互为否定关系,所以这两个谓词块是互斥的。
对于互斥的谓词块,我们可以将它们合并成一个p4语言中的动作匹配表,这里我们需要确定表的匹配域和动作域。

第一个表的匹配域是源IP,这里面每一个谓词块都会转换成一个独立的动作,我们确定动作1还会有一个输入叫做server_id。类似的我们可以将第二个蓝色的谓词块翻译成一个独立的表,成为过滤表2,这时候还是有一个依赖关系,这样就将输入的程序翻译成了p4语言。
编码芯片资源:判断一份程序是否可以在指定的交换机上编译。如果程序可以编译,那么我们可以直接将其生成出来,如果不可以编译,那么我们需要将超出的部分放到其他的交换机上。
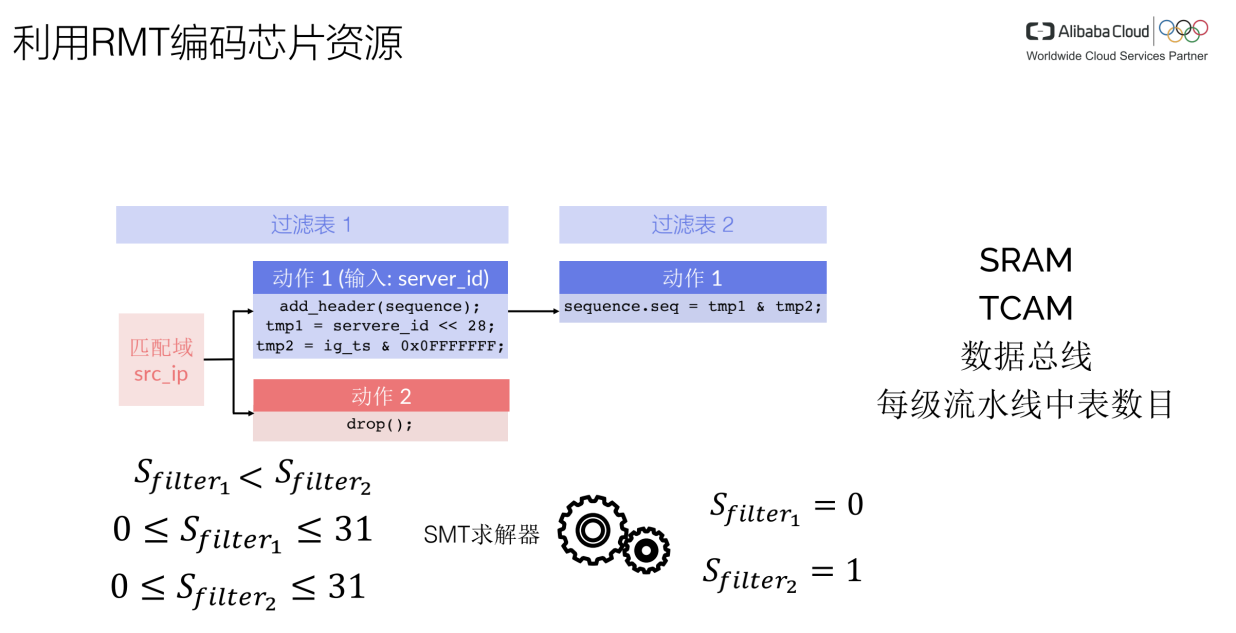
上图是在第一步生成的谓词块,需要将其使用的资源进行编码,我们利用SMT编码器进行编码。以流水线级数为例,因为表1和表2之间存在依赖关系,这里分别用S filter1和S filter2来代表表1和表2在流水线中的级数,由于有依赖限制,因此表1必须放在表2的前面,同时表1和表2必须存在在流水线的某一级当中。
通过SMT求解器,一个可行的方案是把表1放在流水线的第0级,表2放在流水线的第1级,通过类似的方式可以编码其他的资源,比如说SRAM、TCAM、数据总线等。这样通过SMT求解器就可以知道输入的程序是否可以满足当前交换机的资源限制,从而是否可以成功编译。
代码编排:保证部署代码的正确性。其中一个难点就是如何在交换机之间传递信息。这里采用的方案是让上游的交换机将信息打包进报文头部传递给下游交换机。
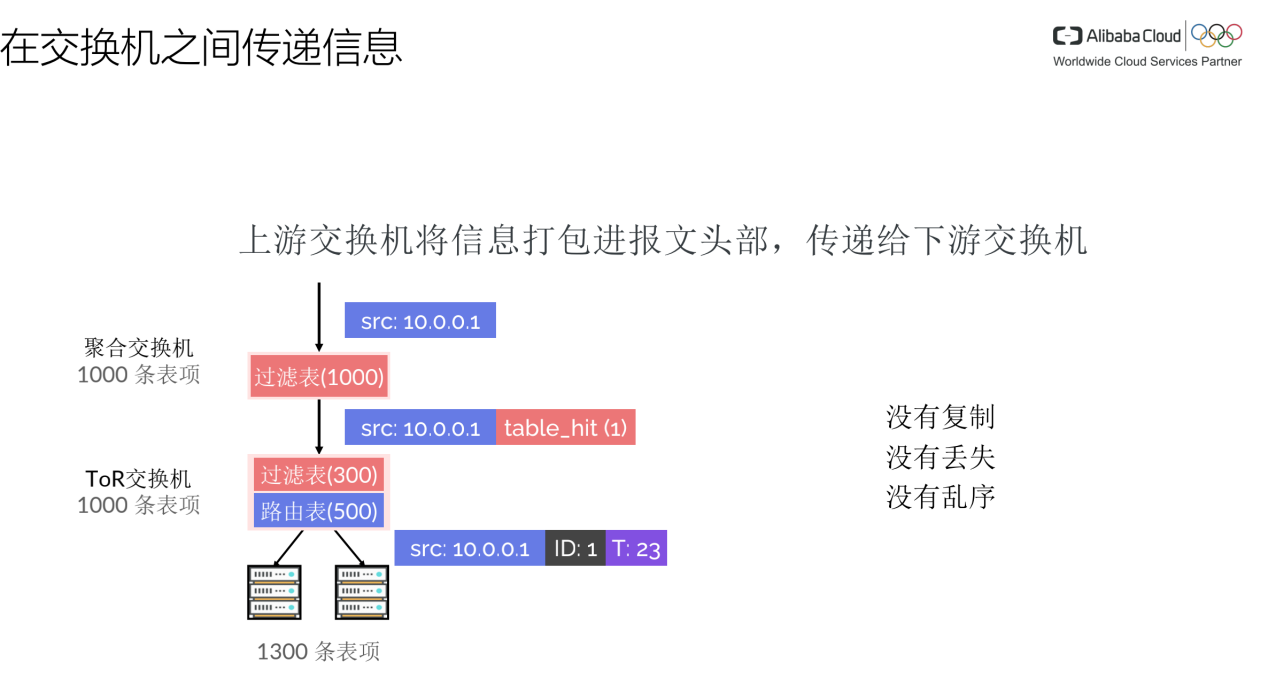
如图,处在上游的聚合交换机需要将是否命中第一个表的这个信息放到报文头部中,这样下游的ToR交换机就可以根据是否命中来判断需要是否需要查找第二个过滤表。类似的还需要确保代码中的每一条语句没有被复制,没有丢失,也没有乱序。
总之,在太玄编译平台中,太玄编译器使用三个组件语言生成器、芯片资源编码和代码编排算法来给可编程网络的开发提供移植性、组合性和扩展性。
太玄可编程网络编译平台——优化阶段
传统上,程序员将大量的时间消耗在了调试程序上,而不是开发程序。一个典型的痛点就是资源匹配问题。在可编程交换机中,为了同时实现高性能和高灵活性,有很多种组件,下图展示了一种可编程交换机入端的流水线,在流水线的两端有报文的解析器和逆解析器,流水线中有很多级,每一级中有内存和运算单元,各级流水线之间还有数据总线,每一种组件都提供了一种资源,每种资源也都是有限的。

程序编译的过程,即为将程序映射到芯片的每一种资源上,一个可编译的程序需要满足所有的资源限制,那么开发问题就变成了一个资源匹配问题。
程序员开发的程序必须要匹配交换机提供的资源,但是由于编译器自身的问题,有些时候程序和资源的映射不是显然的,虽然交换机仍然有资源剩余,但是程序仍然不能通过编译,同时由于编译器的自身限制,提供的错误信息又不是很明确。此时程序员就会微调编写的程序,让编译器进行新一轮的尝试,这样程序员就陷入了一个“改写-编译-改写”的循环,极大降低了开发效率。
另一方面,在生产环境中,开发程序往往和交换机提供的资源是不匹配的,这进一步加剧了资源匹配问题。经过分析我们发现生产程序有一个特点,就是具有很长的依赖链。可编程网络的编程语言,比如p4,是以表为基本单元的,表之间如果有读写关系,那么它们之间会存在依赖。通过分析生产程序中的各个表的依赖关系可以得到一张依赖图。

这张依赖图中很多个依赖链,我们将最长依赖链中表的数量称为这个程序的直径。那么根据依赖关系,这个程序的直径应该需要小于或者等于流水线的级数。
这里展示了1个服务于CDN场景的可编程网络程序,它包含了不6个不同的功能模块,比如ACL、负载均衡、包转发、流控制、调度以及DDoS防御,这个程序的直径是10。同时我们统计了一些其他的生产程序,直径都在8以上。

我们使用的可编程交换机一共只有12级流水线,这样的话直径大的程序带来的后果就是在可编程交换机中的部署时灵活性不足。
下图展示了前述CDN程序在每集流水线中的内存占用。
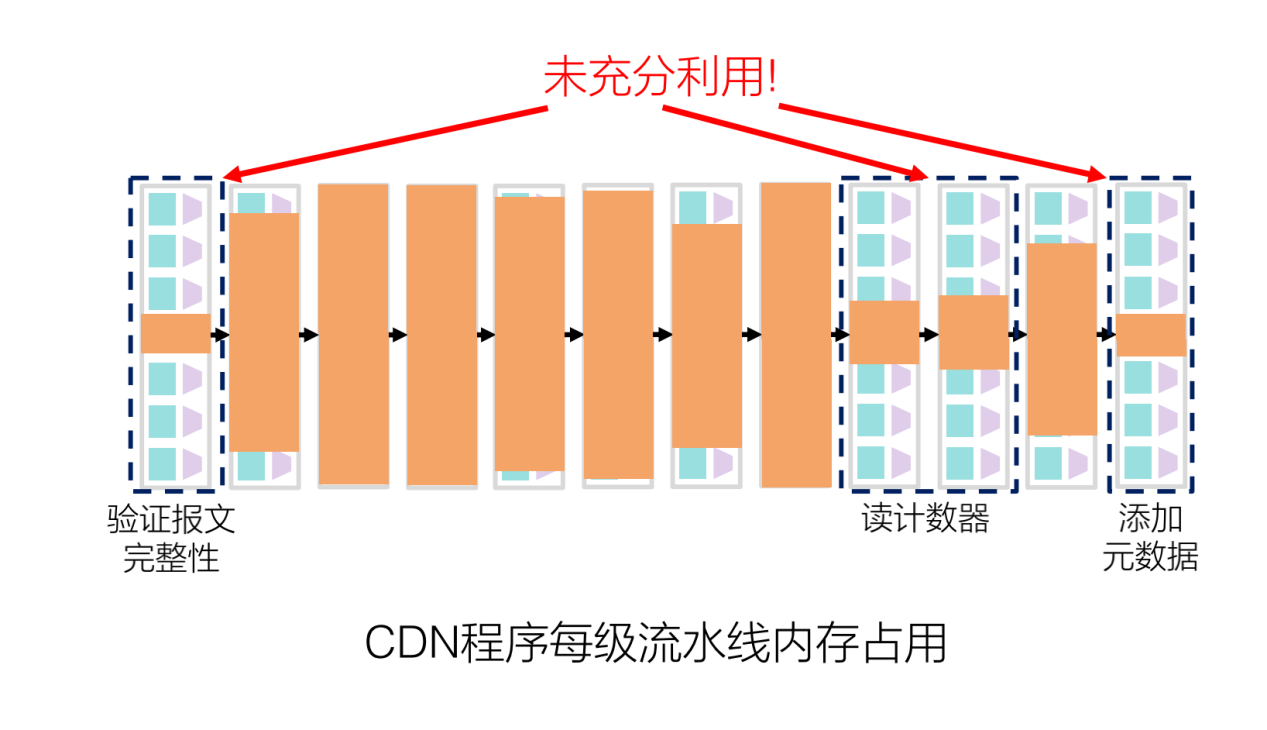
可以看到,在流水线的头部和尾部都产生了大量的内存浪费,在程序的头部和尾部中都会进行一些运算操作,比如说验证输入报文的完整性、读计数器、添加元数据等,这些操作对对内存的要求很低,但是又和其他表项产生依赖,导致其他表不能共用同一级流水线,从而浪费了内存资源。
对于其他种类的资源也观察到了类似的现象。为了解决该问题,在优化阶段,太玄提出了一系列的优化算法,这里优化算法的重点是移除程序中的依赖关系,从而减少程序的直径,提升资源的利用率。
仍然以p4程序为例,不同的匹配动作表之间有多种依赖关系,图中展示了一个示例程序,该程序中有5个匹配动作表,在这5个表之间有4种不同的依赖关系,可以看到表1和表2之间,表1的匹配域读取了变量a,同时表2的动作域写入了变量a,我们称这种依赖关系为读后写依赖。
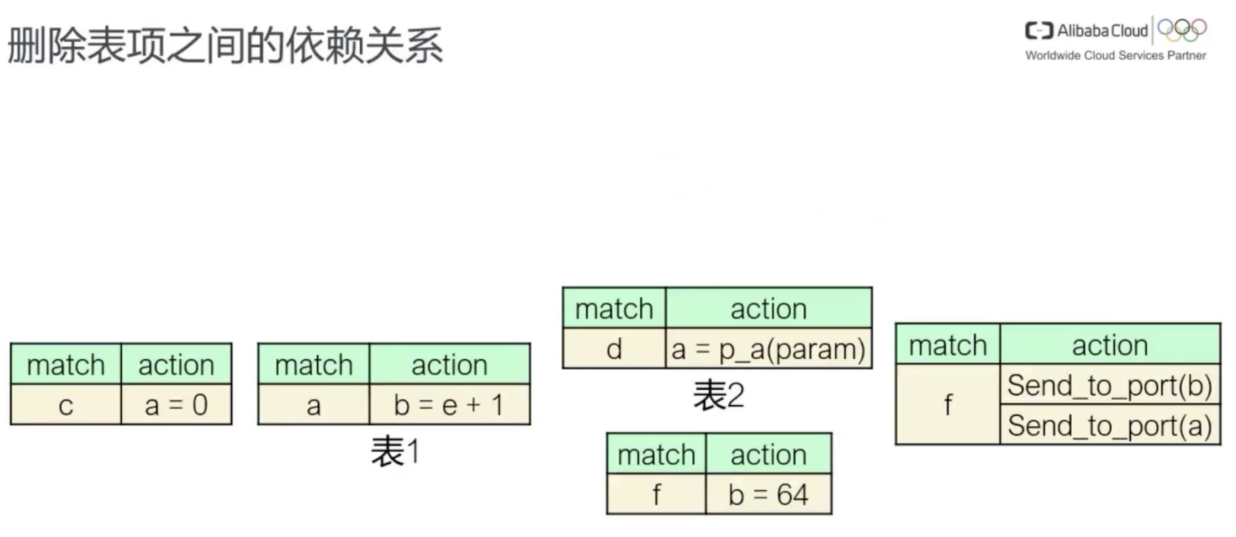
相似的还可以总结出其他三种依赖关系,分别是基于匹配域的写后读依赖、写后写依赖,以及基于动作域的写后读依赖。
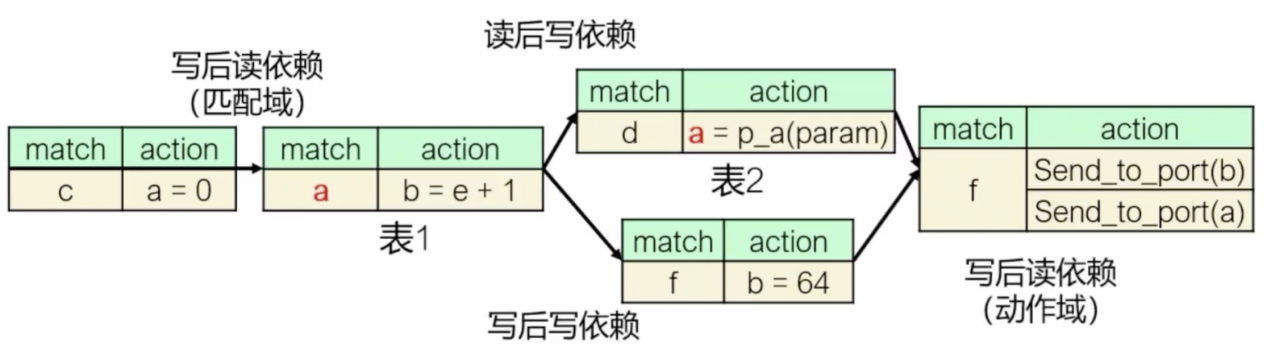
不同的依赖关系有不同的优化算法。以读后写依赖为例,即展示太玄如何删除表1和表2之间的依赖关系。总的来说,太玄通过引入临时变量来将依赖关系进行拆分。
比如在当前例子中,我们将表1读取的变量从a变成a_0,这样表1和表2之间就失去了依赖关系,但是因为我们又需要保证程序的正确性,我们需要找到上一个对a进行操作的表,比如表0,同时将a进行赋值,这样表1和表2同时依赖于表0,但是1和2之间就没有依赖关系。

我们可以用类似的思路移除其他三种依赖关系,程序的直径也会因此缩短,从而提高了程序的利用率。

最后,高佳琦表示,当前的可编程网络开发仍然处于萌芽阶段,在开发、优化和测试环节中仍然存在着各种问题,导致开发效率低下。阿里云自主研发的太玄可编程网络编译平台解决了开发过程中的痛点问题,提升了开发人员的工作效率,使得可编程网络可以快速迭代,从而提升网络的服务质量。







