

作者:Liu Xiaodong
文章来源:DPDK与SPDK开源社区

背景
SPDK以轮询方式高效的处理请求,能够最大化的利用CPU达到高性能的目的。
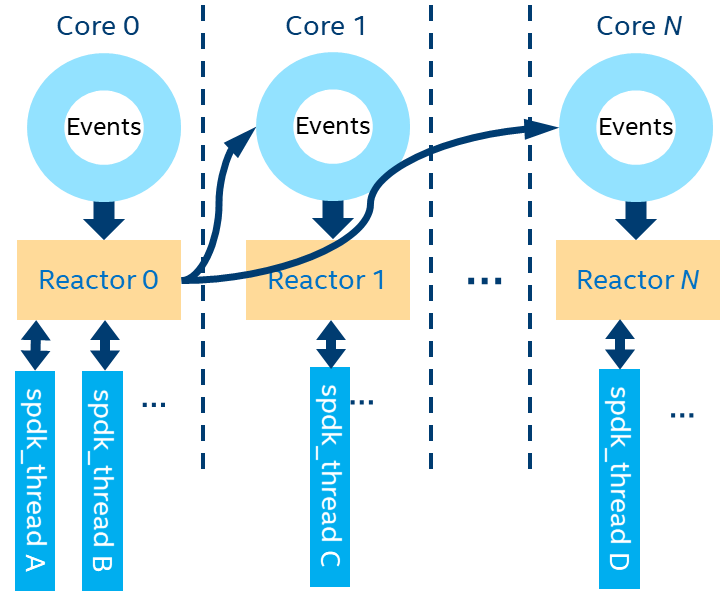
当SPDK应用需要提供大量vhost设备,iSCSI或NVMe-oF服务时,默认情况下,如图1,SPDK内承载各个存储服务工作的协程(基于spdk_thread 结构)会均匀分布在SPDK绑定的CPU核心上。这样的设置能够满足SPDK涉及的大多数工作场景。
但是,每个存储服务的工作协程负载大小会有不同,而且会随时间变化;单个CPU核心上轮询执行的几个存储服务的工作协程,它们的负载总和有可能会超过该CPU核心的计算能力。上述两种条件同时发生时,会出现一种情形,如图2:在某一时刻,SPDK使用的一部分CPU核心承担的负载超过它的计算能力,其上的IO负载会有过高的时延,同时吞吐量也有可能下降;而同一时刻,SPDK使用的另一部分CPU核心,对应工作协程的负载不高,存在一定量的空闲计算能力。
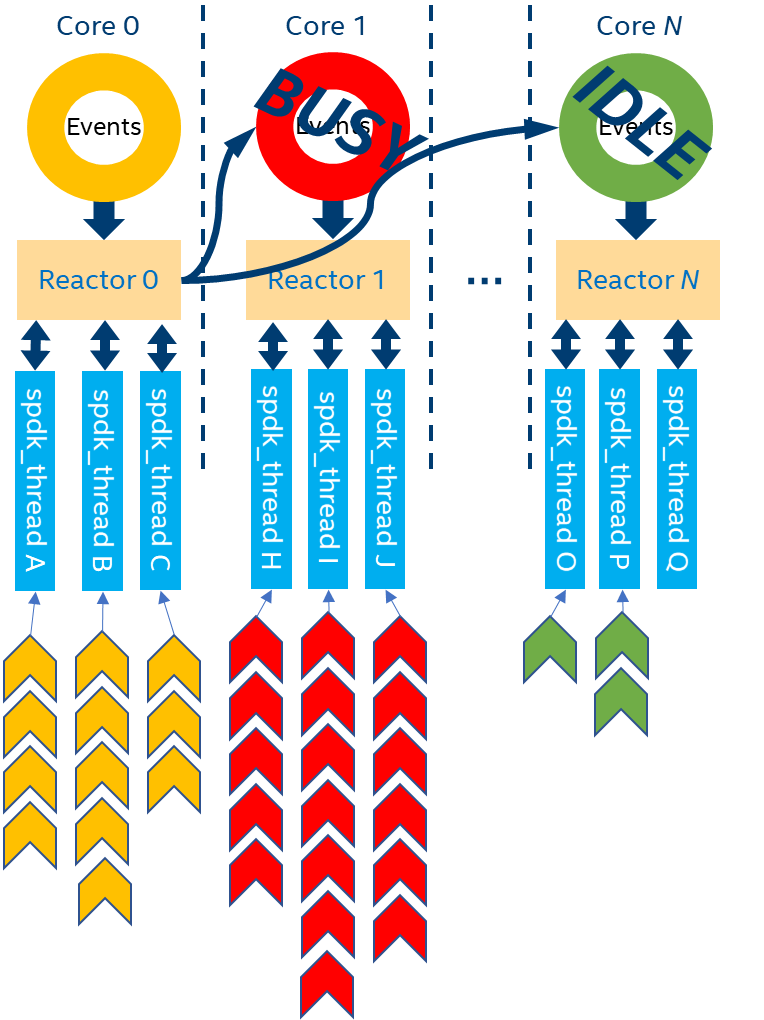
对于追求性能极致的用户来说,希望能够监测到SPDK上各种负载的分布情况,更进一步,可以采取一定的手段减轻或避免负载不均。
这篇文章将以一些SPDK监控和设置命令的实践,来初步介绍SPDK的负载均衡。
基础
SPDK在其绑定的每一个CPU核心上,会创建一个对应的执行实体Reactor, Reactor(如图1-3中所示)。一个Reactor即对应一个pthread,亲和绑定在一个CPU核心上。它始终运行在亲和绑定的CPU核心上,不会被调度去其他CPU核心。所以Reactor与pthread和CPU核心的对应关系为1:1:1。
SPDK在处理存储服务时,会创建一些轻量级协程spdk_thread。根据不同存储服务的特点,SPDK会将某个负载单元完全交给一个spdk_thread去处理,比如一个vhost设备对应一个spdk_thread,该vhost 设备的所有IO请求都会由此spdk_thread处理完成。
spdk_thread需要被放到一个Reactor上去执行,具体到哪一个Reactor是由spdk_thread的CPUMASK决定。如图3,spdk_thread A, C, D的CPUMASK分别在Core0,1,2的bit位上置位,它们分别被放置在Core0,1,2上,spdk_thread B的CPUMASK对Core0,1,2的bit位上均有置位,代表它可以被放置到Core0,1,2任何一个上。在执行过程中,spdk_thread可以动态地从一个Reactor上迁移到另一个Reactor上,如果将spdk_thread A的CPUMASK更改为2,它将会被从Core0,调度到Core1上去执行。

方法
SPDK已经有诸多的状态监控和设置相关的RPC方法,关于负载均衡的手动实践,这里我们主要涉及这几个RPC 调用: thread_get_stats
获取所有spdk_thread的运行状态,包括每个spdk_thread的名称,ID,CPUMASK(指示该spdk_thread可以被放置到哪些Reactor上去执行),忙碌工作与空闲空转的CPU累积周期数, 以及它的poller信息。
执行与输出示例:./scripts/rpc.py thread_get_stats

设置ID对应spdk_thread的CPUMASK,即指定一个spdk_thread可在哪个或哪些CPU上执行。参数 -i 指定spdk_thread ID; 参数 -m 指定它可运行Reactor的CPUMASK。
Note: thread_set_cpumask设置的CPUMASK被SPDK视为建议值,而非强制值,所以有可能设置了新的CPUMASK,但是spdk_thread并未被调度到对应的Reactor或CPU上。
执行示例与解释:./scripts/rpc.py thread_set_cpumask -i 10 -m 0x4
将ID为10的spdk_thread,设置成可在CPU2上执行(CPUMASK 0x4,置位位数对应CPU2).
framework_get_reactors
获取所有Reactor的运行状态,包括每个Reactor的序号,忙碌工作与空闲空转的CPU累积周期数,列举其上运行的spdk_thread。
执行与输出示例:./scripts/rpc.py framework_get_reactors

实践
1)当一个spdk_thread在一个时间间隔的busy 周期数远大于idle周期数的时候,可以认为它现在有较大的负载需要处理。如果此时这个spdk_thread在一个忙碌的Reactor上运行,那么Reactor能分配给该spdk_thread的可用周期,很可能不能满足此spdk_thread负载的需求。
2)当一个Reactor在一个时间间隔的busy 周期数远大于idle周期数的时候,可以认为对应CPU核心处在满负荷的状态,即该Reactor负载过高。如果有其他Reactor空闲,可以考虑将某个spdk_thread调度到空闲Reactor上。
3)framework_get_reactors的返回结果也反映出spdk_thread实际运行哪个Reactor上。
结合thread_get_stats和framework_get_Reactors的输出结果可以判断出该时间间隔内SPDK上的负载分布情况,并决定是否应该将一个spdk_thread 从一个Reactor调度到另一个Reactor上。如果有需要,可以:
- 通过thread_set_cpumask命令,指示SPDK在Reactor之间调度spdk_thread。
- 通过framework_get_reactors命令,确认spdk_thread是否实际被调度到指定的Reactor上。
结语
对大多数应用场景,SPDK默认设置稳定高效,不需要额外做手动负载均衡。如无特别需要,应尽量避免手动负载均衡。
SPDK在v21.01版本后逐步提供并增强了两个特性:监测工具spdk_top和调度器scheduler:
-
监测工具spdk_top可以方便快捷的反映出SPDK内各个负载的分布情况,其内部也是通过文中介绍的thread_get_stats和framework_get_reactors两个方法作为信息来源。
-
调度器scheduler是上述手动过程的自动化模块,SPDK在逐步添加并完善调度器功能。负载均衡应尽可能由调度器自动完成。
在了解了SPDK负载均衡后,非常推荐SPDK‘er去尝试使用spdk_top和scheduler。








