

转载自DPDK与SPDK开源社区
- 内容速览 *
本文在存储的大背景下,对SPDK加速NVMe SSD后端存储应用的原理进行了简单分析,并对其主要应用场景进行了总结。同时,本文给出了SPDK相关的性能测试、项目开发、论坛交流等介绍,适宜初学者快速了解SPDK项目。
1从hello world开始
Hello world基本是大部分程序员写下的第一个小程序。
include
int main()
{
FILE *fp = NULL;
fp = fopen(“/home/test.txt”,”w”);
if(fp)
{
fprintf(fp, “hello world\n”);
}
fclose(fp);
return 0;
}
上述程序会在/home/目录下创建test.txt文件,并写入hello world字符,那么程序是怎样完成这一工作的。
我们知道home目录本质是我们挂载到计算机中的一种存储设备,这种文件目录的层次结构存储,称为文件存储。操作系统中的文件系统会负责把用户文件持久化地保存在磁盘中,即使断电,存储的内容也不会丢失,实际上文件系统可以理解为对存储设备中的文件进行组织管理,组织的方式不同就会存在有不同的文件系统。为了完成对数据的管理,文件系统分配了两个数据结构:索引节点(index node)以及目录项(directory)。索引节点记录了inode编号、数据的大小、权限、位置等信息,称之为元数据(metadata);目录项则用来存储索引节点指针、目录的层级关系,多个目录项关联起来就形成了文件系统。
需要指出的是,元数据持久化存储在磁盘中,占据一定的存储空间。在Linux系统中,基于一切皆文件的设计理念,不仅仅是普通文件受到文件系统的管理,其他例如socket,块设备等也是交由文件系统进行管理,因此在Linux系统中存储系统可以简单地分为本地存储系统和基于网络的远程存储系统,因为远程存储系统本质是通过socket,返回了一个文件描述符。
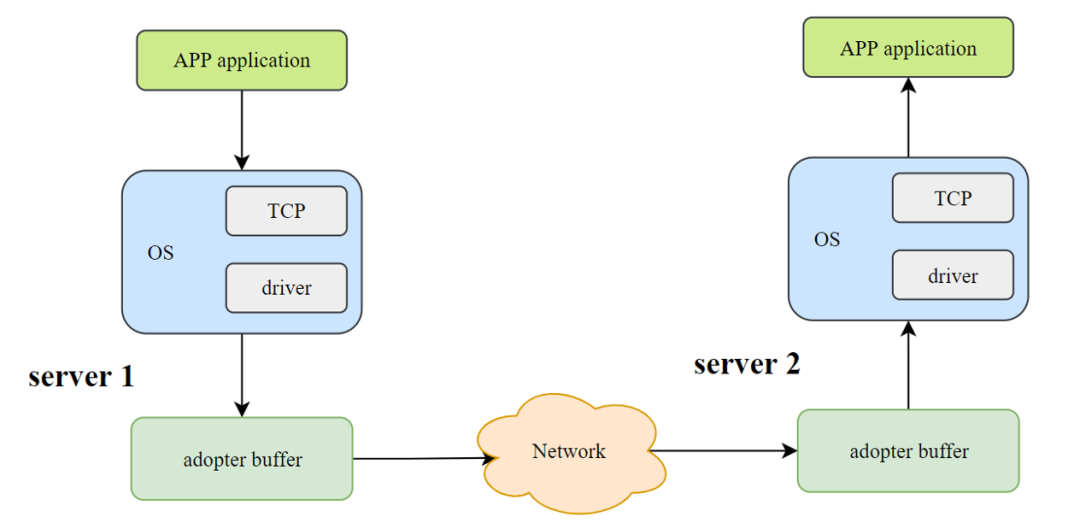
在现代操作系统框架下,程序运行在目态和管态,也就是用户态和内核态,显而易见,我们编写的用户程序运行在用户态,而挂载在计算机中的存储设备属于外设的一种,操作存储设备的行为则需要进入到内核态,因此运行在用户态的程序本身不具备操作外设的条件,尽管某些技术会提供直接操作的接口,但一般说来,为了访问到外设进行读写操作(I/O),用户态程序需要通过系统调用(system call)进入到内核中,上述代码中,fopen(),fclose()是C库函数暴露给用户的接口,在打开了一个文件以后,返回了文件描述符。
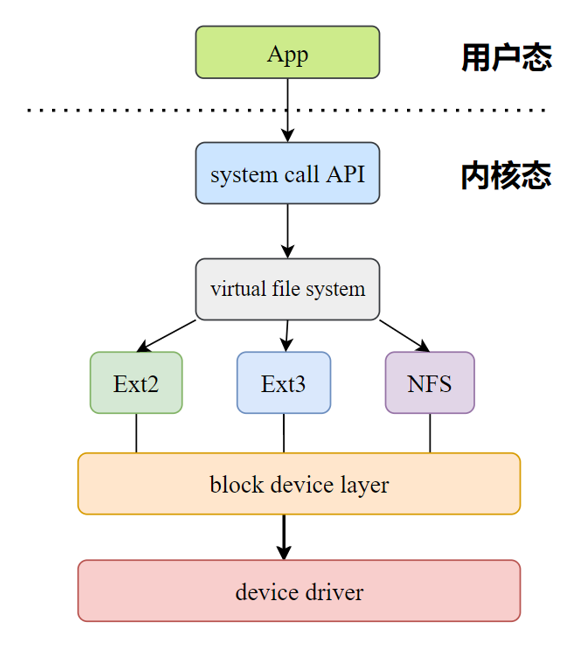
用户程序通过系统调用进入到内核中的虚拟文件系统(virtual file system,VFS),虚拟文件系统的本质是对各个文件子系统的封装,封装以后方便对不同的各个文件子系统进行统一的管理,VFS在收到了某个文件系统的I/O命令以后,通过对应的文件系统下发到统一的块设备层,再借由各个设备的驱动,实现相关的I/O操作。在上述代码中,我们将hello world字符进行存储,其存储大小在字节(B)量级。然而,如果以字节作为每次读写的操作单元的话,读写的效率会非常的低,因此,文件系统另一个重要的工作是屏蔽这种差异。实际上,Linux系统中的文件系统是基于逻辑块(4KB)也称数据块作为最小的读写单元,用来提高效率。
du -sh /home/test.txt // 打印文件大小
4.0K /home/test.txt

通过前文的描述,整个write过程首先从用户态通过系统调用进入到了内核态,再由VFS去访问具体某一个文件系统的write方法,最后通过相关驱动写入到磁盘中,当写入操作完成以后,还会通过内核来通知用户程序。因此,整个I/O操作需要借助操作系统中内核的帮助,而系统调用陷入到内核中的行为,在一定程度上带来了CPU的损耗,降低了性能。
2SPDK 定义
在前文的简介中,我们发现I/O操作需要操作系统内核的处理,而通过内核处理的一系列操作降低了性能。我们可以将从用户程序到完成I/O操作之间,内核参与完成的事情概括起来主要有两件:
-
支持虚拟文件系统、各个存储子系统以及各个驱动的管理;
-
用户程序和文件系统之间的系统调用。
尽管操作系统的内核为了完成I/O操作背后做了许多工作,但在之前的机械硬盘存储方案中,这并不是影响存储性能的主要因素和瓶颈。然而,随着存储设备的更新,基于NVMe协议的SSD固态硬盘逐渐成为了新的存储解决方案,而替换了机械硬盘。这就使得我们不得不考虑,在I/O请求密集型的场景下,由于系统内核所做的工作对存储性能的影响。显然,一种容易想到的方法就是对内核进行优化。io_ring项目提供了一套新的系统调用,它基于系统调用路径的优化,在一定程度上提升了内核对I/O操作的性能。而另一种更为直白的方案,就是绕过内核(kernel bypass),整个I/O操作不需要陷入到内核中,SPDK就是这样的一种存储加速方案。Intel对其定义是利用用户态、异步、轮询方式的NVMe驱动,用于加速NVMe SSD作为后端存储使用的应用软件的加速库。
针对SPDK的定义,我们对其关键字进行解析。SPDK是一个加速库,为了其通用性,采用C进行编码,项目地址: https://github.com/spdk/spdk。加速的方案主要利用了用户态、异步以及轮询的思想;加速对象是基于NVMe SSD作为后端存储的应用软件。NVMe协议是一种为了SSD固态硬盘和主机通信的速度更快而定义的规范,将其本地存储性能推广到网络有NVMe-oF协议,用来支持InfiniBand、光纤或者以太网等。在针对网络存储解决方案中,当前主要有DAS、NAS以及SAN。
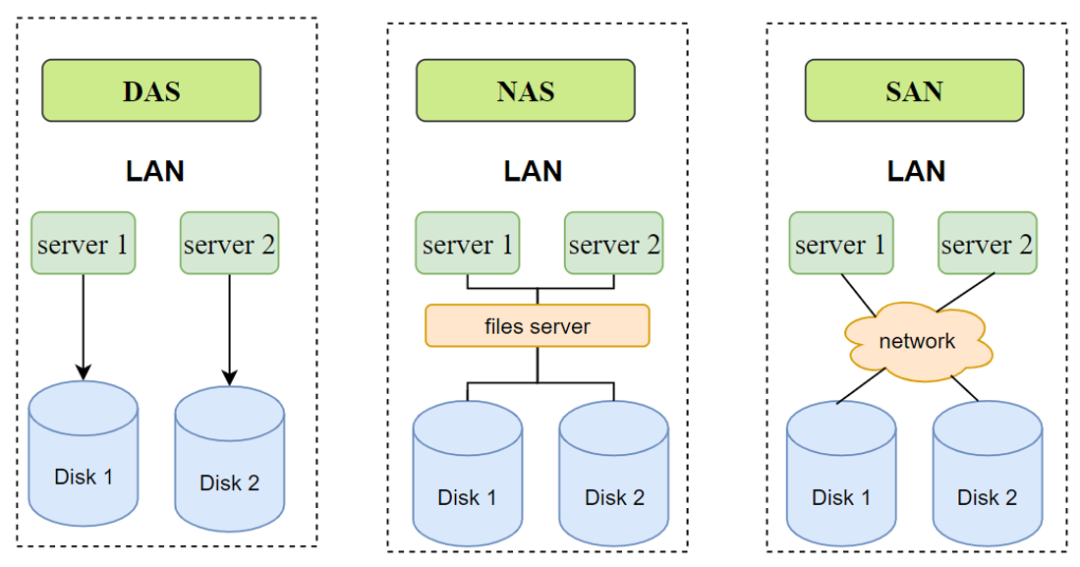
从解决方案上看,DAS对于分布式系统来说不利于扩容,NAS方法则会受到中心节点files sever的网络带宽的限制,而基于搭建独立存储网络的SAN方案,具备极强的扩容性,传输的数据可以是SCSI数据。为了降低SAN的成本,利用普通网络传输的iSCSI技术应运而生,其核心思想就是利用普通的TCP/IP网络来传送SCSI数据块,降低了搭建专用网络的成本。在SAN方案中,存储过程如下:

数据的发送方称为initiator,数据存储方称为target。SCSI设备具有一个target id来表示设备地址,具有多个LUN(logical unit number)对应一个逻辑设备。
3SPDK方案设计
用户态驱动、轮询以及异步
正如前文所述,I/O操作需要用户程序从用户态陷入到内核态,需要系统调用的参与,而SPDK采用kernel bypass的方案,避免了系统调用。为了实现用户态驱动,在内核中所涉及到的存储设备驱动也一并放置在用户态。
SPDK基于UIO或VFIO的支持直接将存储设备的的地址空间映射到应用空间的方式,并利用NVMe规范来初始化NVMe SSD设备,实现基本的I/O操作,从而构筑用户态驱动,所以整个过程不需要陷入到内核中。在常规内核驱动阻塞的I/O操作完成以后,还需要利用CPU,来通知用户程序I/O操作的结果。在SPDK用户态驱动的方案中,这一行为被异步轮询所取代,通过CPU不断轮询的方式,一旦查询到操作完成,则立马触发回调函数,给到上层用户程序,这样用户程序可以按需发送多个请求,以此提升性能。移除系统中断另一个显而易见的好处是避免了上下文的切换。
在理解了SPDK的用户态驱动以后,我们再回顾一下原本内核中的I/O操作的逻辑:当通过系统调用陷入到了内核态以后,每一个块设备都需要在自己的内核中调用各自的驱动。显然,直接暴露给各个驱动的接口到上层应用并不是一个好的方案,这不利于引入新的硬件设备。为此,Linux内核抽象出了通用设备块,用来支持上层应用与各个设备驱动的交互,隐藏了不同硬件设备的特性,并为这些I/O操作进行了一个统一的管理,避免硬件设备去支持较高的I/O并发量。同样在SPDK中,引入了用户态驱动以后,与之对应的,我们也需要用户态通用块来支持底层不同的存储需求。
SPDK整体架构分为四层,自上而下,最上层的应用协议层指代SPDK对外支持的协议以及相关的存储应用,包含有网络存储NVMe-oF,iSCSI Target以及虚拟化vhost-blk/scsi Target等;第二层为存储服务层,他提供了对块或者文件的抽象,用来支持更多的存储业务,例如提供了Blobstore;第三层抽象了通用的块存储设备bdev,用来支持后端不同的存储方式,例如NVMe,NVMe-oF,Ceph RBD等,并支持自定义的存储设备;底层则是驱动层,在这一层上,SPDK实现了用户态驱动用来加速各类存储应用。右侧例举了一些SPDK可集成的服务以及应用场景。

除此之外,SPDK利用CPU的亲和性,将线程和CPU核做绑定,设计了线程模型,应用程序从收到这个核的I/O操作到运行结束,都在该核上完成,这样可以更高效的利用缓存,同时也避免多核之间的内存同步问题。与此同时,在单核上的内存资源的管理,利用了大页存储来加速。需要说明的是,SPDK借助了DPDK对基础内存资源的管理,比如大页分配(大页配置说明: https://www.kernel.org/doc/Documentation/vm/hugetlbpage.txt),因此需要DPDK相关库作为依赖,另外DPDK也为SPDK提供了一些基础数据管理结构,例如内存池,无锁队列等等。因此,SPDK的使用首先需要对系统进行一些配置,具体配置可参考: https://spdk.io/doc/system_configuration.html。
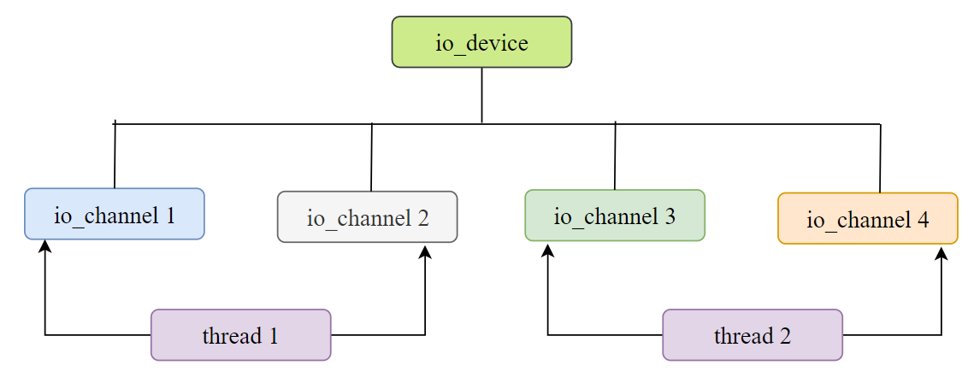
在SPDK中的线程模型架构上,每一个CPU核中拥有一个内核线程,会初始化一个reactor。每一个reactor下可持有零到多个SPDK抽象出的轻量用户态线程spdk_thread。为了提高在reactor间通信与同步的效率,SPDK放弃了传统加锁的方式,而是通过向每个reactor的spdk_ring来发送消息。在抽象得到的spdk_thread下拥有poller,用来注册用户函数。基本的框架图如下:
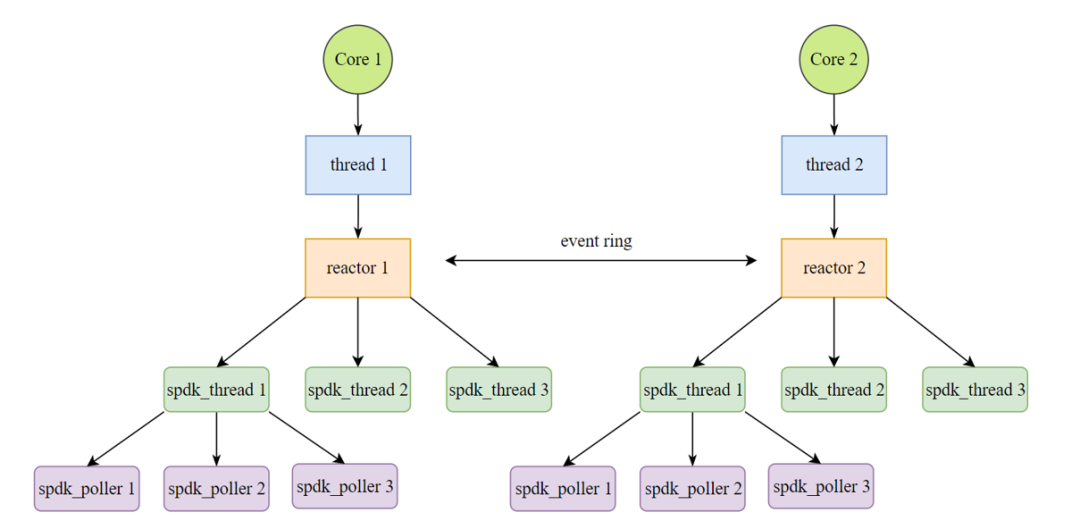
另外,SPDK抽象出了io_device以及相应的spdk_io_channel。用来保证一个channel只能被一个spdk_thread所使用,其他线程不能访问到。更多SPDK的线程模型分享可阅读[3]。
4SPDK场景应用
SPDK作为针对NVMe SSD存储设备的软件加速库,其应用场景主要是针对块存储的加速。设计了bdev层,spdk_bdev的目的是为了抽象,统一了各种存储设备的调用方法,我们知道后端存储有基于NVMe SSD,也有远端存储的NVMe-oF等等,抽象出的bdev用于绑定各类业务,并暴露一个接口给到用户。总结下来,其应用主要有以下几个方面:
- 块设备接口网络存储应用,例如NVMe-oF target或者iSCSI target
显然,网络存储中使用NVMe-oF协议的后端块设备存储是SPDK加速存储性能的直接应用,存储路径为NVMe-oF——>NVMe到盘。另一个更为通用的方案则是iSCSI target,其路径为iSCSI——>SCSI——>NVMe到盘。SPDK官方网站(https://spdk.io/and https://spdk.io/cn/for Chinese) 针对以上两个场景都给出相应的使用说明文档。
iSCSI example: https://spdk.io/doc/iscsi.html
NVMe-oF example: https://spdk.io/doc/nvmf.html
需要指出的是,NVMe-oF是NVMe协议在以太网传输网络的扩展,而iSCSI是SCSI在以太网上的扩展,两者均是为远程网络存储技术服务。另外,对于网卡可以具备RDMA的支持,也可以不具备,即采用TCP
- 利用SPDK对虚拟机中的I/O进行加速,主要针对在Linux环境下,基于QEMU作为hypervison的场景
通常来说,虚拟化方案有三种:纯软件模拟、半虚拟化以及硬件虚拟化,虚拟化方案经历了从纯软件到半虚拟化的历程,事实上,存储I/O虚拟化也经历了类似的过程,为了减少I/O路径,出现了基于完全虚拟化的半虚拟化I/O技术—virtio(virtual I/O device)。作为Host Kernel模块的VHost技术则是一种优化后的半虚拟化技术,在这种方案中,I/O操作需要和Host Kernel的配合,避免不了从用户态到内核态的切换。
因此,针对块设备提供给虚拟机的场景下,借助SPDK可以实现完全基于用户态的I/O操作。不同的设备device对应了不同的驱动,其I/O链路也不相同: virtio-scsi/blk,NVMe,SPDK对其三种方案进行了整合,针对I/O密集型场景,形成了vhost target: https://spdk.io/doc/vhost.html。
- 集成进存储引擎,基于SPDK的用户态I/O栈进行加速
SPDK提供了非易失性存储Blobstore系统,用来支持更高层级的存储业务。由于SPDK将整个I/O操作从内核态切换至用户态,缺少了内核所支持的文件系统,但与之相对应的实现了简易的文件系统Blobstore File System,当前BlobFS系统实现了对RcoksDB的支持: https://spdk.io/doc/blobfs.html。通过在下层使用Blobstore对I/O性能进行加速,并不会影响上层业务逻辑,因此这可以很方便的集成到MYSQL,RocksDB等,他们可以是基于SAN,NAS或者其他分布式存储方案。
5SPDK性能测试
SPDK每一个版本(yy-mm格式)都会发布对应的性能测试报告,主要包含NVMe Bdev,NVMe-oF TCP,NVMe-oF RDMA以及Vhost四个方面,每个方面都包含有具体测试场景及相关配置信息,相关测试报告可在: https://spdk.io/doc/performance_reports.html中找到。SPDK的性能测试借助了spdk的perf工具以及fio(https://github.com/axboe/fio.git),值得注意的是fio本身借助Linux中的fio进行测试,受限于架构原因,fio测试工具并不能完全发挥SPDK组件的优势,因此更为推荐采用perf工具进行性能测试。
性能测试一般有顺序读写、随机读写,前者往往反映了存储设备的最大吞吐量,而后者则更为接近我们的实际工作场景,在SPDK中采用的是随机读写的场景。IOPS(input,output per seconds),即每秒I/O请求次数,单独的IOPS指标难以完整描述整个存储性能,往往与延迟(latency)结合起来看,延迟代表了处理本次I/O请求所耗费的时间。此外,存储设备还引入了队列深度(queue depth),它描述了存储服务中等待处理I/O的数量,通过队列深度的引入,以并行优化的形式将I/O请求提供给存储子系统,虽然一定程度上牺牲了延迟,但提升了整个存储性能。基于这三个指标,进行调优,可以获得良好的存储性能。

(图片来源: https://ci.spdk.io/download/performance-reports/SPDK_nvme_bdev_perf_report_2110.pdf)
6SPDK Development
SPDK官方网站为用户提供了相关应用场景的开发文档以及测试用例,并提供了Slack以及Trello Board用于更新feature进度和问题分享。
Slack: https://spdk-team.slack.com/ssb/redirect
Trello Board: https://trello.com/spdk
同样SPDK也欢迎更多的人参与到项目中,可以在本地配置Gerrit以及GitHub账号,提交相关commit,再通过两名core maintainer的code review +2以后合入到master中。
Development: https://spdk.io/development/
参考文献
[1] 《Linux 开源存储全栈详解 ——从Ceph到容器存储》
[2] 《Linux 开源网络全栈详解 ——从DPDK到OpenFlow》
[3] SPDK线程模型







