

本文转载自“zartbot ”
DPU最近真的火,就连我那些做金融的小伙伴都来问我. 其实回想起SDWAN刚出来的时候,和现在DPU不也差不多么?很多时候大家只看到了一个很片面的刚需,就匆忙的进入战局了. 只想说国内做DPU的这几家创业公司都有点**…
DPU不是什么
DPU的出现最早应来自于Azure为了解决自身Bing的一些工程难题,利用FPGA bump-in-wire搞了一些优化,紧接着是AWS/阿里云在公有云上实现果金属降低资源消耗,然后就是Pensando为了解决自己在ACI中遇到的问题,也就是它们常说的长号流的问题,以及Fungible更多的案例是在存储上。最后被黄教主收购卖螺丝给点爆了。
所以DPU是什么?大家都在花很多口舌去解释, 都是有侧重的去解决自己遇到的一系列问题,所以我们先谈谈DPU不是什么。
01不是交换机的线卡
随着SR-IOV和Host-Overlay的出现以及公有云两家的实现,包括Pensando的实现,有很多人误认为DPU就是将原来ToR交换机延拓到主机上,即构成一个交换机的LineCard,几乎所有做网络的人都会这样认为。诚然公有云和Pensando都发现了原来的安全组和Overlay等一系列实现在ToR上会变得越来越复杂,再加上容器网络的出现,CPU的核心越来越多,HostOverlay成了必然选择。所以在25Gbps时代卖螺丝能火也是必然的,但是这样的考虑是不完善的,因为这个东西充其量叫做SmartNIC,因为DPU还肩负着更多的任务。
02不是PCIe交换机
这是Fungible看到的,但是JNPR出来的人吧,总是比市场早一拍,然后前浪死在沙滩上… 例如以前的QFabric,到后面思科的ACI… Fungible的问题也就是早了一拍,最后DPU被老黄家的卖螺丝发扬光大,你说可怜不可怜…
但是问题来了,老黄搞DPU的目的是为了HPC,在分布式AI训练或者其它并行计算场景中,NvLink解决了机箱内的跨卡通信问题,而机柜内和机柜间的通信问题如何解决呢?机柜内随着PCIe5.0和CXL会逐渐成为一个趋势,而机柜之间的选择只能是以太网或者IB。
所以很多人只盯着机柜内的CPU/内存/GPU/NVMe互联的场景,本质上又错了。
03不是Offload PU
DPU本身这个词太空洞…以至于樱桃把它定为IPU…开玩笑的说还不如叫OPU,对于DPU的最关键的一个词或许是Offload 但是都忘记了另一个关键的词成本.最近和很多人都在聊到这样一个问题,优点大家都明白,但是在一个服务器上加装一块DPU是否值得?特别是边缘计算场景下。
很多人看到Sidecar又想把它Offload给DPU处理,果断在上面搞TLS TCP ,哈哈哈~~
04不是NPU
基本上还有几个做NetworkPU的厂家也混进来了,芯启源基于Netronme,云豹基于RMI的几个人,还有Marvell基于Cavium搞的CN10,前两个对于市场的定位真的有差距, 而Marvell怎么说呢,当然它的架构上有很多好玩的东西,Neoverse 2的核心和SVE 再加上新的片上网络有很多值得去把玩的东西,等过几个月拿到开发板了好好玩一下。只能说某个基于RMI的直接就晚了一两代,而芯启源面临的则是编程环境的生态。其实很多传统的NPU厂商都是想继续用微码或者魔改的指令集去搞事情,但是这早就过了NPU的年代了,没有客户会为specific的东西去写大量的代码。
而Marvell可是老老实实的把自己不行的东西全干掉了,cavium以前的开发环境全干了,现在基于ARM的DPDK使得它在很多场景的吸引力甚至强过几个基于P4的网卡。
DPU是什么
通信的本质是共享内存,而冯诺依曼架构的瓶颈在内存,这才是DPU需要解决的本质问题。
01Disaggregated Computing
如果说这个行业谁看的最清楚,我想是Victor Peng吧,当然还有Jim Keller的Tenstorrent。当然还有Google在悄悄玩的Cloud PU,下图是Victor Peng在ISSC 2021讲的一张ppt:
DPU的场景本质上是从CPU Centric->Offload Computing的过程,因此整个过程中伴生出了基于GPU的异构计算、基于网络的计算(In-Network-Computing)或者基于内存(In-Memory-Computing)或者基于存储的(In-Storage-Computing),都是将计算逐渐的Offload到各个扩展卡上处理。
但是最终的目的是为了什么呢?让计算在最靠近数据的地方发生从而降低通信量进而规避冯诺依曼架构的瓶颈,而且整个过程是不计成本的…
下半张图Victor画的非常好,不知道我们跟Xilinx签NDA的某个东西是否影响了他,本质的过程是Adaptive Network for Dissagregated Computing,这才是解决冯诺依曼架构缺陷的关键。加一个新的东西,要剪掉另外好几个东西才是成功的根本原因。
从通信上来看,Linux里面TCP的问题就不多说了,光是底层的mbuf和skb都有好多可以抛弃的地方,最近为了解决某个在研东西的可靠传输看了一下TCP的源码,真的不知道为啥还有人基于它来…算了,某两家点到为止吧…
02DPU=Data PU
控制面和数据面分离是DPU最好的定位。
即便是在CPU设计中,我们也有译码、分支预测等大量控制面的东西,真正的数据面的超标量计算也是需要和控制电路做好分离的,所以在DPU时代,本质上我们应该把CPU更多的解释为ControlPU,而DPU则是处理大规模Data的PU. 这才是DPU设计关键。设计专门处理DPU的指令集或许是一个非常好玩的场景,但是要把自己局限在分离DataPath上。
基础设施的池化资源通常简单可看做:CPU 内存 存储 网络的按需组合。
拆分->虚拟化
例如一个CPU几十个核,拆分了卖也就是对应的虚拟化架构,例如以Nitro为例,AWS最早基于Xen的虚拟化I/O路径太长,消耗太大,因此逐渐的开始进行优化,例如C3开始使用SR-IOV ,然后C4开始将远端的存储(EBS Volumes)通过新收购的Annapurna以NVMe的形式呈现给虚机。然后X1开始将VPC的一些功能加入,同时也负责磁盘的监控、加密和QoS等业务。最后到了2016~2017这个时间段,唯一的问题就是原来的hypervisor了,最终裸金属出现了.然后到了这个时间段,基本上网卡、存储、各种加速卡、外设都可以虚拟成PCIe设备了。所以你会看到最近AWS发布的基于Apple M1的虚机,直接一根雷电线查到MAC mini上。
融合
将多个CPU socket连接在一起,并附加内存和存储按需构建,也就是Fungible一直在强调的概念。本质上是在一个Rack-Level的自组织结构: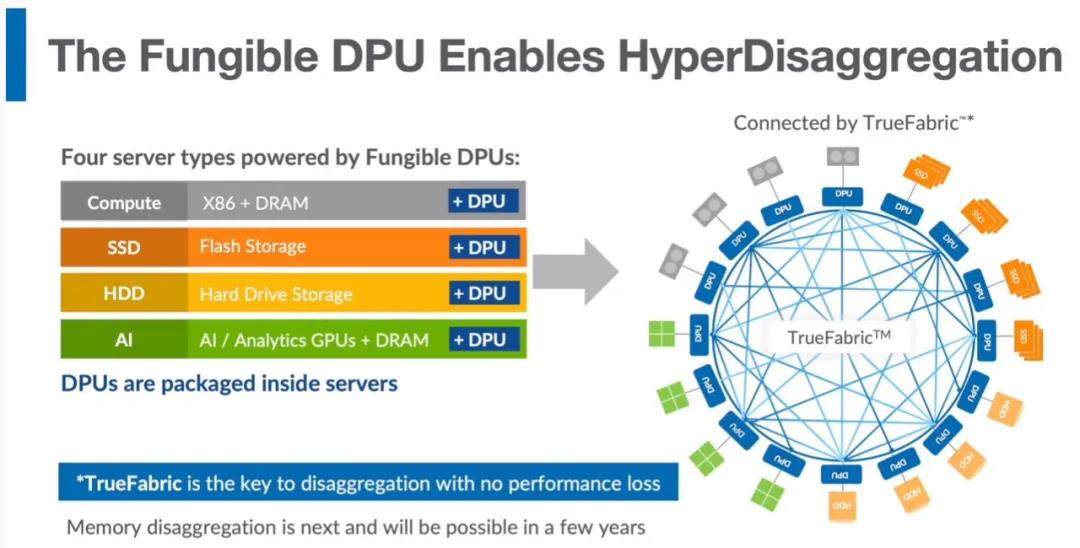
这样的设计很可能又一次要把刀片服务器带回来,特别是一些小型数据中心,多个刀箱DPU连接是一个不错的解决方案,这次刀片的回归并不是为了密度,更多的是为了通信的带宽而考虑的,例如Cisco最近发布的UCS-X和Intersight是一个趋势。
主机的路由器
随着CPU上核心越来越多,吞吐越来越大,有人戏言现在是把一个数据中心封装在一个服务器里,那么DPU自然就是DCI的路由器了。
正如前文所述,DPU本质上是在数据通路上实现加速处理,它的最基本的一个设计就是如何快速解析、封装、转换报文格式, 因此以交换机的视角来做的都是**。
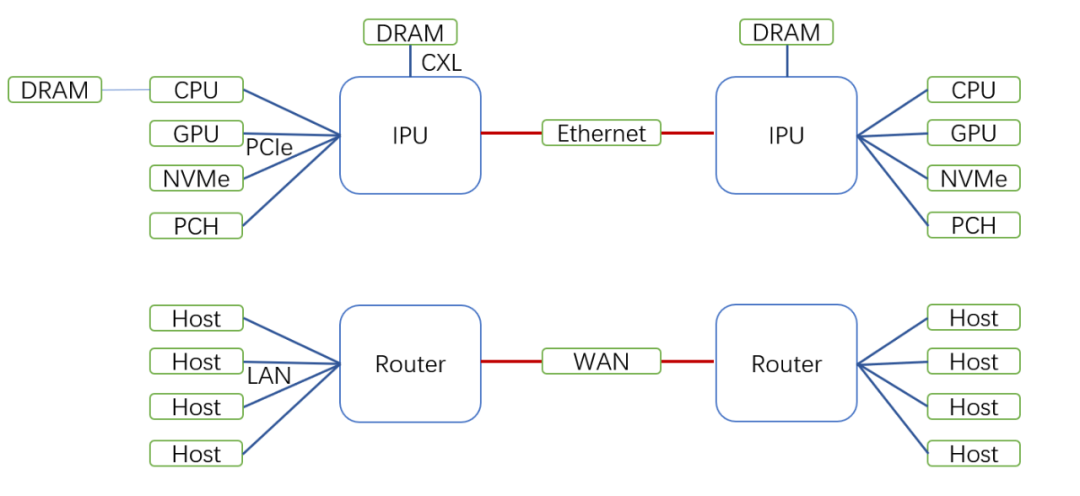
- 局域网是PCIe/CXL连接各种CPU、GPU、DRAM、Nvme、PCH,主要负责In-Rack的通信;
- 广域网是Ethernet,主要负责Cross-Rack或者Cross-Pod、Cross-AZ的通信,在边缘计算节点替代传统路由器构建SDWAN的方式;
- SRIOV是路由器的子接口,果金属类似于VRF/NFV构建虚拟的控制平面(BIOS、TPM、键盘鼠标、VGA等等);
- DPU池化资源是port channel/VPC/FEX这些聚合技术把多个板卡组装成一台大机器;
- QoS和拥塞控制:任何传输协议栈都需要
- 安全:可信计算环境和安全组(Security Group)。
这些都是一个标准的路由器该有的基本功能,也就是说Marvell的Oceteon、Tilera续命后的BlueField、IXP续命的Netronome和芯启源为什么突然都说自己是做DPU的了,而RMI XLR的团队也出来搞云豹, 也难怪为啥Fungible的构成是来自于路由器团队了,也明白为啥MPLS这次卖了两代Pensando还是没有什么起色了吧。
进一步从云原生的架构来看,DPU还要肩负一系列应用网关的功能,和高性能通信库的功能,鉴权、主机智能路由等功能。
03在CPU之外的SIMD
让一个只会做标量的家伙去拼命算矩阵是愚蠢的。
CPU诞生之初就是标量结构,而关于DPU本身,从另一个视角来看也很有趣,那就是Linus讲的,Intel要做的应该是趁早取消AVX512指令集,而不是指望着依靠“魔术指令集”在性能基准中取得好成绩。Linus批评说,英特尔的FP性能差强人意,AVX512占用了大量的晶体管,但是它只能在性能基准和HPC等少数情况下才能发挥作用。他宁愿要更多的核心、更高的单线程性能,也不要AVX512这样的“垃圾”。
也就是说以后的CPU应该尽量抛弃那些SIMD的东西,而更多的在单核心IPC上优化,更多的空间用于Cache和更多的核心。至于AVX512这样的指令集,更多的应该发生在靠近数据的地方。这些是樱桃打死都不承认的. 所以金坷垃离开樱桃去了Tenstorrent,然后直接用RISC-V的High-Performance Core在干一些有趣的事情,可以去看看去年Tenstorrent在HC上的ppt。
04DPU ISA
在CPU架构中,解析报文需要接近100个cycle,再加上数据流经PCIe和内存产生的延迟,这是DPU需要解决的问题。因此DPU本身需要一些特定的报文处理引擎。P4算是一种,特别是P4 MAU的实现是非常不错的一套电路:
但是P4本身又完全基于交换机的架构设计的, 针对路由器场景中有大量的分支预测的处理就力不从心了,这也是为什么Pensando和Fungible都要在上面添加ARM,而BRCM最早基于纯ARM多核性能遇到瓶颈的地方。而Marvell在设计Octeon CN10的时候考虑到了这个问题,具体内容设计它们家NDA就不多讲了,同样Mellanox在BlueField上也考虑这样的问题,需要一个Parser做前级和一个DeParser做后级. 这个也是我最近正在做的一个项目,即Data-Centric Computing ISA:
这个ISA的设计上需要兼顾报文在多协议接口上的封装, 片内总线、内存总线、PCIe总线、以太网等各种传输方式上的处理,同时需要考虑到原有的固定长度的AVX512一类的指令集的缺陷。Neoverse 2支持的SVE2是一个非常不错的概念,特别是变矢量长度编程模型(VectorLength Agnostic,VLA).它可以灵活的实现128bit~2048bits的可变长度处理. 当然我们在做的另一个项目实现了更长的处理:)
DPU架构的艺术
01带宽
最早智能网卡的诞生就是为了解决这个问题: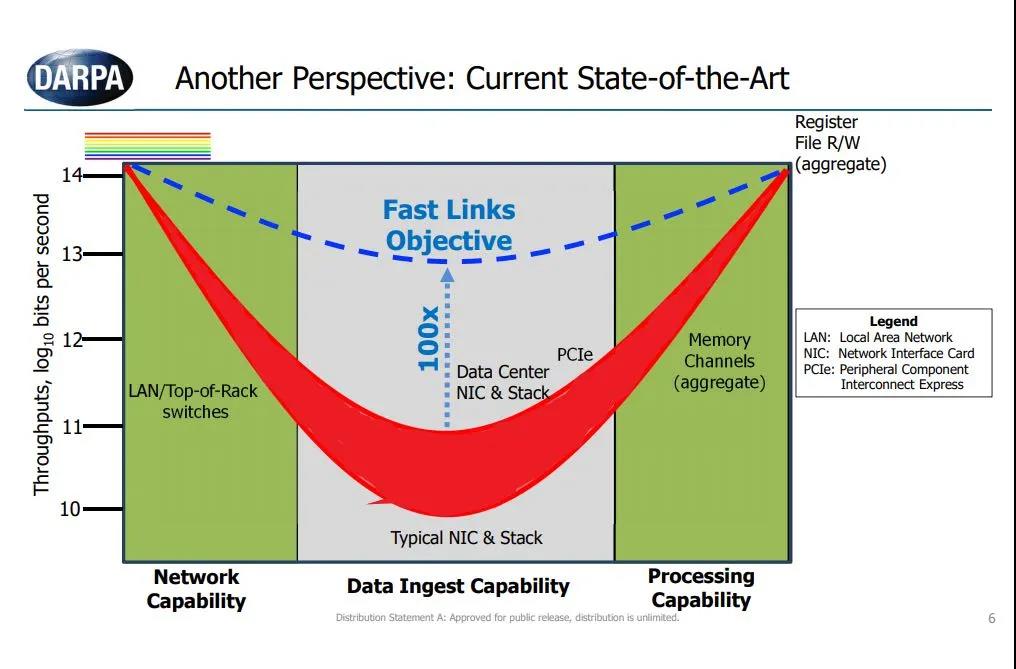
那么带宽多少才够呢?在PCIe 3.0时代和每颗CPU 24核以下的场景中, 25G~50G x 2其实就能满足,而100Gx2的CX5、CX6只是针对AMD支持PCIe4.0和更多核心的情况下才逐渐够用。未来的趋势是PCIe5.0会很快的解放CPU到网卡的瓶颈,而AMD和Intel也会很快的扩展到单颗CPU接近100核的容量,并伴随着封装HBM提升内存带宽,这样的视角下, 200Gx2 或者跨越200G直接400Gx2都是可能的。
那么在这样的容量下,那几个用ARM多核的阿猫,纯用FPGA的阿狗迟早会给自己带来麻烦。特别是用FPGA的那几家,布线会给你带来极大的痛苦,最终不得不高价去买Versal这样的有600G硬核的FPGA.成本就笑而不语了。
02低延迟交换是刚需
Marvell收购Innovium、Intel自己有Barefoot、Mellanox有自己的交换。DPU本质上有了太多的智能,那么连接他们的交换机一定是需要傻快傻快的,稍微带点Telemetry可以帮助实现拥塞控制就好了,可编程的交换芯片通常都在1us左右的延迟,而Innovium 大概460ns,最终大家都要挤着去买低延迟交换…
03兼顾云网融合
从架构设计上,DPU还需考虑到云网融合和边缘计算的场景,边缘上可能就100G以内的容量,因此可以用一个通用CPU核心来解决DPU场景遇到的问题。但是要记住这样的软件必须要和数据中心内的DPU融合,因此需要在传输层上进一步考虑。
04传输协议优化
在整个计算路径上来看,DPU增加了一个东西,那么势必就要从架构上减少一些东西来平衡。基于TCP去搞NVMeOF完全没有做到减法.本质上我们需要一种协议去连接广域网、数据中心网络,端到端构建ZTNA、然后尽量在数据payload上减少封装和解封装以及协议转换的东西。这也是为什么几个云都有一个高性能网络的部门,但是简单的SRv6+TCP/QUIC 本质上也并没有做到减法,因为在主机侧SRv6实现上还有一系列问题需要去处理,例如鉴权、加密、路径选择。Ruta的设计便是为了解决这一类的问题的可行方案。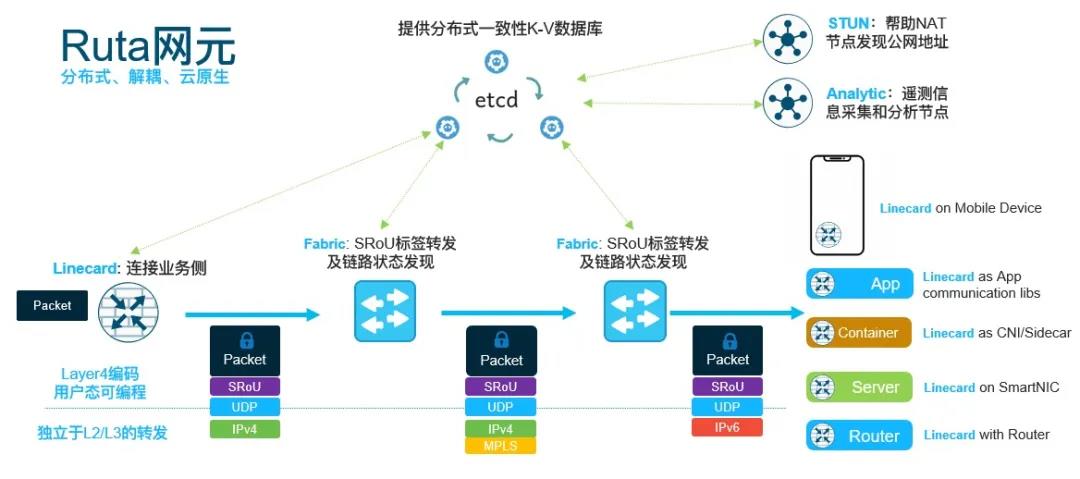
加上最近正在开发的ZaDNS实现边缘主机的ZTNA:
05软件架构的优化
DPU另一个常听到的名字是软硬件融合,软件上整个Linux的网络协议栈也需要进一步的修改,传统的Linux Kernel对于大规模数据处理遇到的瓶颈就不多讲了,DPU野鸡们把TCP Offload讲了好多次了。关注于TCP、UDP Offload本质就是错误的,因为Linux自身也在演进中,例如最早的UIO将设备的IO和中断能力暴露给用户态,但是又遇到了DMA的问题,因此出现了VFIO通过IOMMU来解决这个问题,然后便出现了VFIO-mdev(Mediated devices)的技术,这些都是回归到应用本质的解法:通信的本质是共享内存, 共享内存的最佳实践是通信。
通过vfio-mdev在软件层面上对DPU通信进行了很好的抽象和封装,应用最终要从Socket编程逐渐演化到其它形式的内存访问上。
06ML in DPU
Marvell的CN10, nVidia的morphis, Xilinx的Versal以及Intel的FPGA都不约而同的提到了ML推理的场景,从数据安全上来看,基于ML的Security Assurance和Performance Assurance都是必不可少的场景,因此在DPU上需要适量的向量引擎来做一些事情,将原始数据通过ML推理降维从而减少数据流,大概的架构演进正如我3年前构建一个分布式AI推理引擎时设计的:
某司两位大佬的评价:
结 语
其实我真为你们这些DPU创业的感到羞愧,NPU的创业被寒武纪的业绩基本上搞凉了,GPU的创业被璧仞把该投的钱都投完了,CPU的创业这群怂包又没能力干,于是捡了些DPU来弄,反正随便瞎折腾搞个25Gx2 或者100Gx2还是很容易的,故事嘛能讲就行,产品能不能用无所谓,甚至能不能卖都无所谓,毕竟有个A股几百亿的通信专网的雷在那里,只要干别人看不懂的行业就好…
一个合格的DPU架构师,从应用上来看,你要懂得分布式AI训练和HPC场景下对MPI的需求,另一方面是云原生场景下CNI和CSI需求,而果金属虚机只是几个云厂商需要考虑的问题,本质上DPU留一个管理口或者串口接上IPMI就好,更多的还是要在更底层的地方减少协议转换,降低成本和损耗, 片内总线、内存总线、PCIe总线、以太网等各种传输方式上的处理有太多的东西要去处理,很多架构师只是盲人摸象,要么看到很广但是不深,要么深入到一块又不知道一颗DPU需要涵盖那么多内容。
本质上,DPU解决的问题是内存的问题,顺带解决传输过程中的计算问题,里面的艺术大概只有从上到下全玩透的人才会明白。CPU架构、网络架构、计算范式、指令集和编译,这四者是一个合格DPU架构师的基本素养,只可惜都很精通的人太少了…
任何架构,加一个东西的时候一定要好好想想能否顺带减两个以上……







