去年SDNLAB推出的《史上最全DPU厂商大盘点》系列文章受到了很多的讨论与关注,春风吹过,又是一年。国内自研DPU芯片发展突飞猛进,DPU应用也开始逐渐落地。根据赛迪顾问发布的数据,预计到2025年全球DPU产业市场规模将超过245.3亿美元(约1771亿人民币),DPU市场有望实现跳跃式增长,迎来黄金发展期。
在DPU全球千亿市场面前,厂商们今年又整出了什么花活?
以下排名不分先后,按公司简称拼音排序: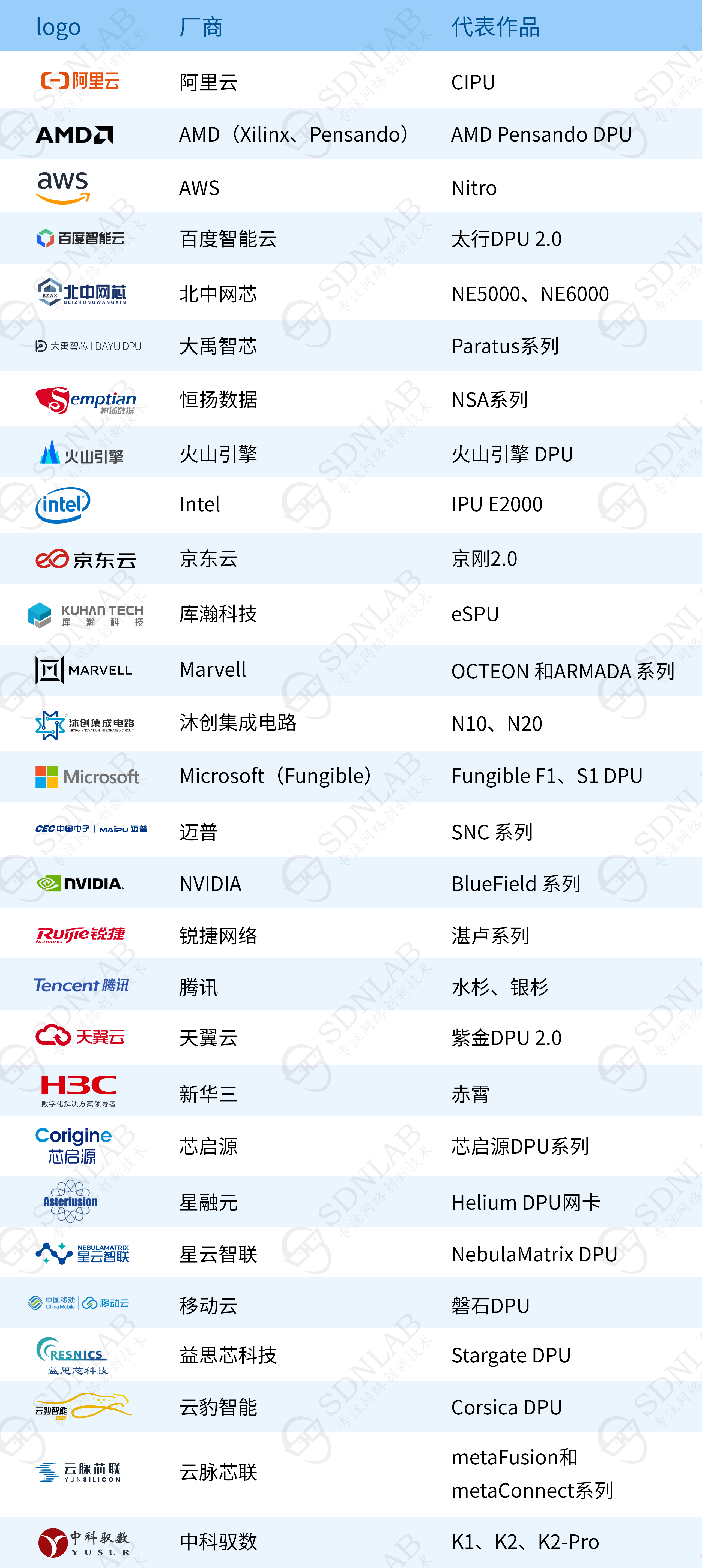
阿里云:CIPU
2017年10月阿里云推出了神龙架构,2022年发布了一款全新的云数据中心专用处理器——CIPU,不同于传统的以CPU为中心的架构设计,CIPU被定义为云计算的控制和核心性能加速中心。
CIPU向下云化管理数据中心硬件,加速计算、存储和网络资源;向上接入飞天云操作系统,将全球上百万台服务器变成一台“超级计算机”。目前,CIPU已经在阿里云内部有较大规模的应用,为双11、阿里集团业务等内部客户和最新实例提供支撑。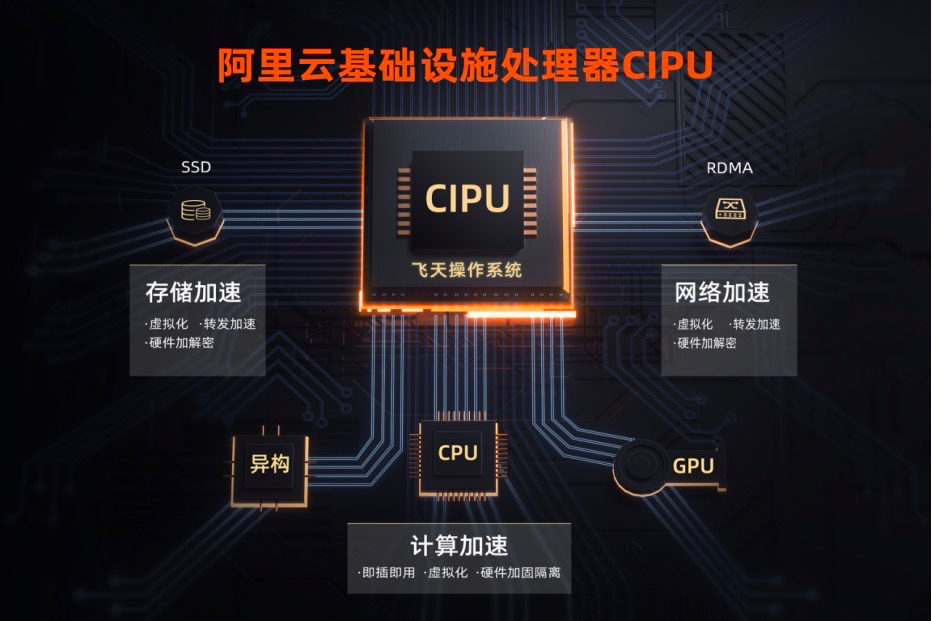
总体来说,CIPU有两大功能:一是具备对底层基础设施资源的虚拟化管理能力,二是能承载飞天对这些资源的编排和调度需求,并具备存储、网络、计算、安全等硬件加速能力。
- 存储方面,其对存算分离架构的块存储接入进行硬件加速,提供超高性能的云盘。
- 网络方面,其对高带宽物理网络进行硬件加速,通过建设大规模的弹性RDMA分布式高性能网络,实现RDMA技术的普惠化,客户无需修改代码,即可享受CIPU的加速红利。
- 计算方面,CIPU快速接入不同类型资源的神龙服务器,带来算力的“0”损耗,以及硬件级安全的加固隔离能力(可信根、数据加解密等)。
AMD:AMD Pensando DPU
2022 年,AMD以19亿美元收购了Pensando,进入DPU赛道。AMD Pensando 平台的核心是完全可编程 P4 数据处理单元 (DPU),采用与超大规模服务系统相同的底层技术。 经过专门优化,通过软件堆栈实现以云级别提供云服务、计算、网络、存储和安全服务,并尽可能地降低延迟、抖动和能源需求。
AMD Pensando DPU 将强大的软件堆栈与“零信任安全”和领先的可编程数据包处理器相结合,打造出更为智能、性能更强的 DPU。AMD Pensando DPU 现已在 IBM 云、微软Azure 和甲骨文云等云合作伙伴中大规模部署。在企业中,它被部署在 HPE Aruba CX 10000 智能交换机中,与领先的 IT 服务公司 DXC 等客户合作,作为 VMware vSphere Distributed Services Engine 的一部分,为客户加速应用程序性能。

AMD还公布了代号为“Giglio”的下一代 DPU 路线图,与当前一代产品相比,该路线图旨在为客户带来更高的性能和能效,预计将于 2023 年底上市。
AWS :Nitro
AWS 是早期自研DPU的云厂商之一。2015年,AWS收购了芯片厂商Annapurna Labs,2017年正式推出Nitro芯片。AWS Nitro DPU 系统目前已经成为了AWS 云服务的技术基石。AWS 借助 Nitro DPU 系统把网络、存储、安全和监控等功能分解并转移到专用的硬件和软件上,将服务器上几乎所有资源都提供给服务实例,极大地降低了成本。
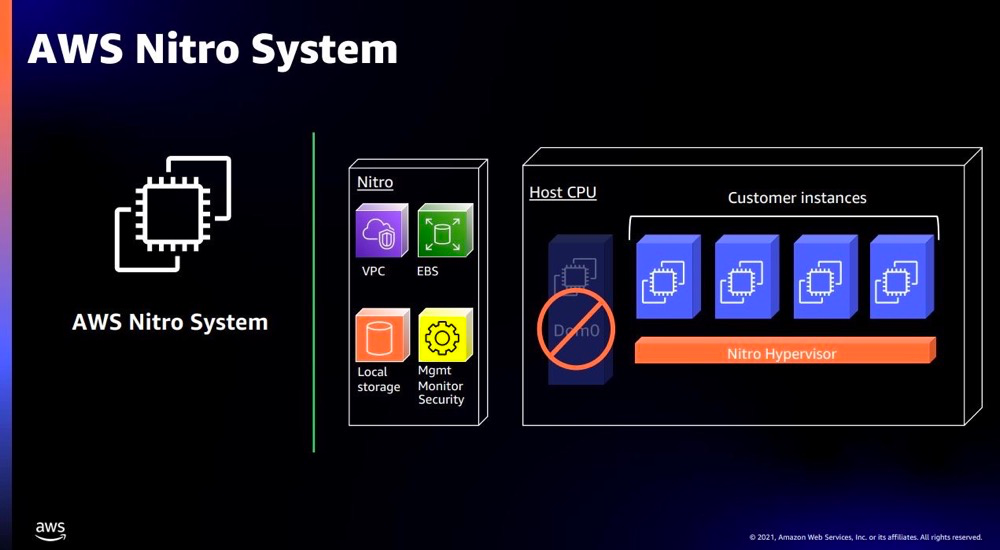
Nitro DPU 系统主要分为以下几个部分:
- Nitro Hypervisor是一个轻量级虚拟机监控程序只负责管理 CPU 和 Memory 的分配,几乎不占用 Host 资源,所有的服务器资源都可用来执行客户的工作负载。
- Nitro Cards是一系列用于卸载和加速的协处理外设卡,承载网络、存储、安全及管理功能,使得网络和存储性能得到了极大提升,并且从硬件层提供天然的安全保障。
- Nitro Security Chip提供了面向专用硬件设备及其固件的安全防护能力,包括限制云平台维护人员对设备的访问权限,消除人为的错误操作和恶意篡改。
- Nitro Enclaves基于 Nitro Hypervisor 进一步提供了创建 CPU 和 Memory 完全隔离的计算环境的能力,以保护和安全地处理高度敏感的数据。
- Nitro TPM(可信平台模块)支持 TPM 2.0 标准,Nitro TPM 允许 EC2 实例生成、存储和使用密钥,继而支持通过 TPM 2.0 认证机制提供实例完整性的加密验证。
百度智能云:太行DPU 2.0
在第五届Create AI开发者大会上,百度重磅发布了新一代计算架构——百度太行DPU2.0,全新太行DPU2.0具备多平台、多场景、多协议、多业务四大核心能力,支持Intel、AMD、ARM平台,同时支持计算、存储、网络、虚拟化等功能。
百度智能云对 DPU2.0的核心定位是“Cloud Native IO Engine”。云架构下的核心问题就在于数据中心东西向流量大增,IO 的负担太大。因此重点需要解决在多租户、细粒度算力形态、后端解耦的硬件资源池架构下,海量的 IO 数据搬移、通信、处理、安全等等问题。重新定义软硬件边界。
百度太行 DPU2.0主要包含5大关键技术:
- 软件定义虚拟化,支持万级虚拟设备;
- 网络硬件加速,由软件转发变成硬件转发;
- 高性能的 RDMA 网络,用自研协议解决流控留空、拥塞等问题;
- 存算分离硬件加速,通过超大资源池打平本地和远程的区别;
- 云管控硬件通道,保证各形态计算实例共池,实现热迁移、热升级、热插拔等特性,支持千亿级模型训练。
百度太行DPU发展路径如下所示: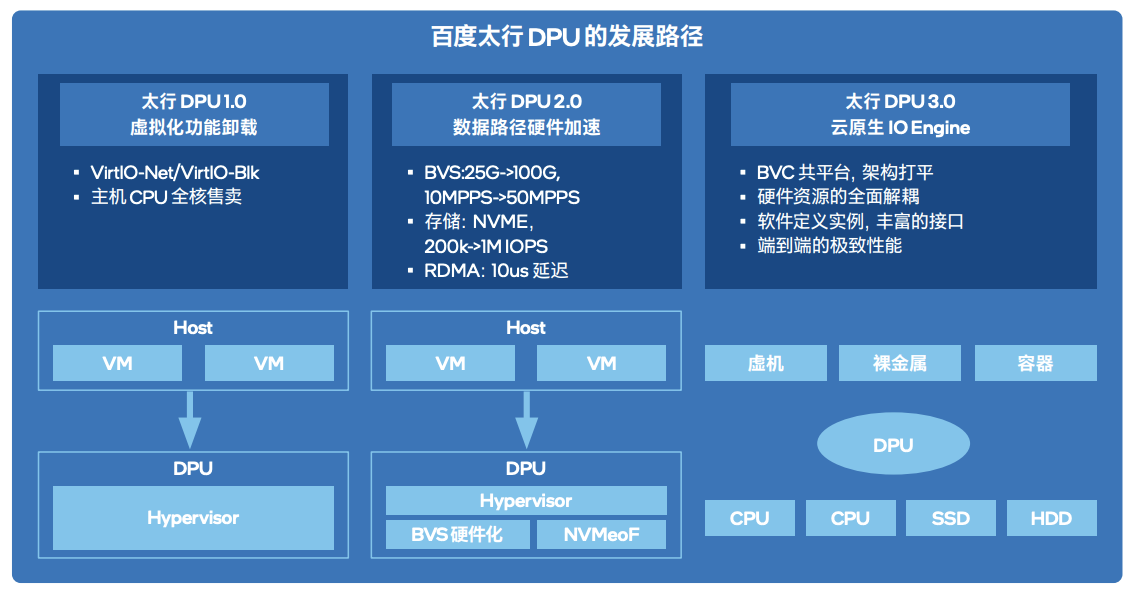
北中网芯:NE5000、NE6000
成都北中网芯科技有限公司于2020年4月成立,专注于网络通信和安全领域的芯片设计和开发。经过研发团队长期的技术攻坚,公司率先推出基于SOC-NP可编程架构NE6000 DPU芯片、NE5000 DPU芯片,并基于自研芯片推出2100GbE智能网卡、225GbE智能网卡、VPN和DPI等一系列技术研发成果。
北中网芯鲭鲨系列首款网络数据处理DPU芯片NE6000于2022年11月13日流片成功,这款芯片基于专用的NP可编程芯片架构,采用28nm工艺制程,兼具高性能、可编程、低延时、低功耗等特点,具有双向200Gbps的处理能力。
NE6000专注于网络数据处理和安全防护功能,可实现网络协议处理、交换路由、安全检测等高性能和高效率的任务,具备25GE和100GE网络接入能力。NE6000通过微码编程升级,可根据最终用户需求灵活进行网络报文协议解析和编辑,适应任何网络协议的变化。
NE6000芯片所特有的级联特性可实现表项扩展和性能扩展,进一步增强系统的灵活性和可扩展性。级联接口传输带宽可达100Gbps,传输延时小于1us。NE6000在灵活性、可编程性、性能、功耗、流片条件等多个维度取得了很好的平衡。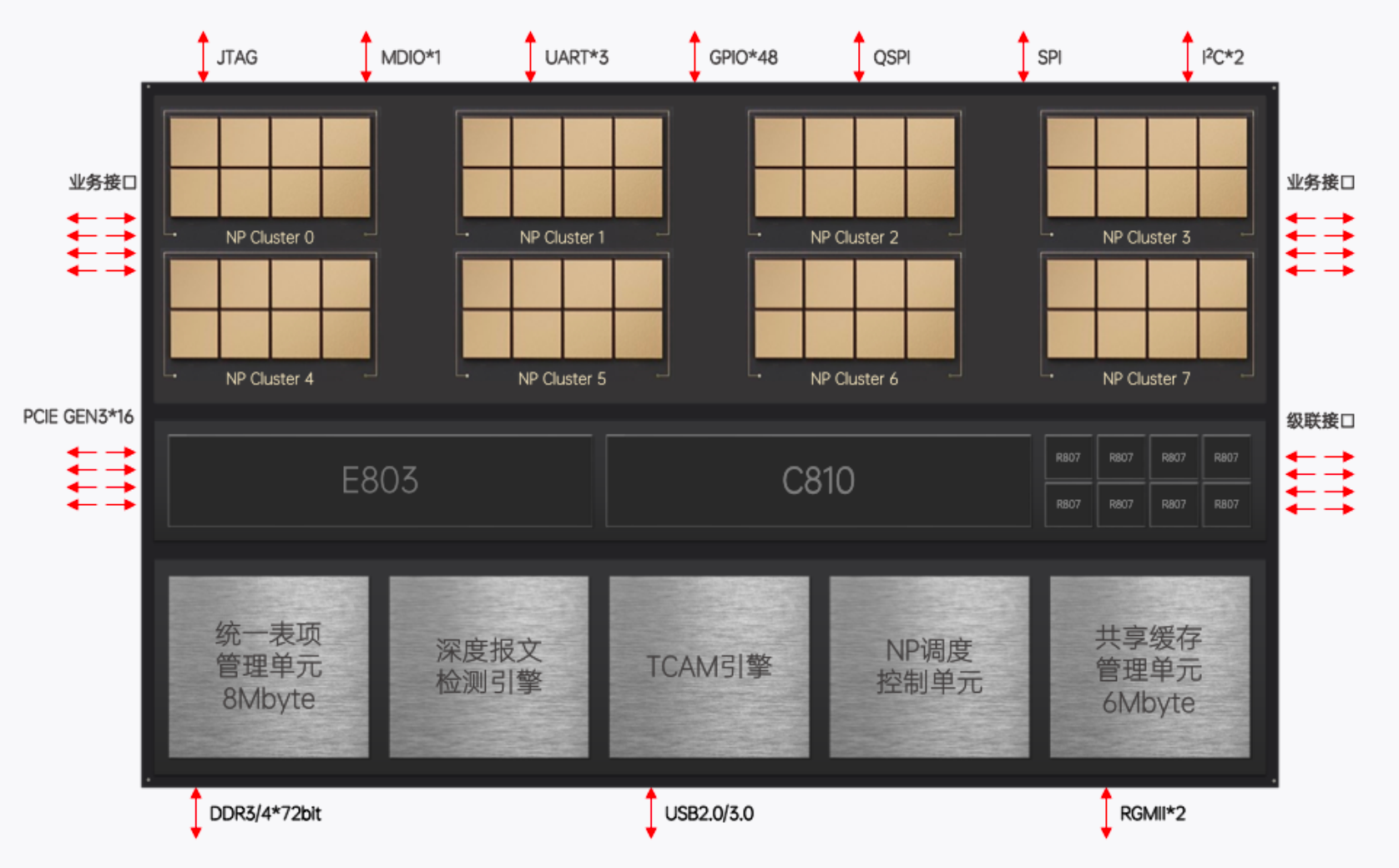
NE6000芯片的应用范围广泛,可以满足云计算、数据通信、网络安全、5G、边缘计算、人工智能等领域的需求,适应数据中心、物联网、车联网等不同业务场景,以及满足负载均衡、VPN网关、下一代防火墙、智能网卡等不同产品形态的要求。
大禹智芯:Paratus系列
大禹智芯是一家专注于提供DPU产品设计、研发与服务的国家高新科技企业。为满足不同客户及不同场景的DPU使用需求,大禹智芯坚持从贴近用户需求的场景出发,遵循明确的产品规划路线,提供Paratus系列DPU产品,目前已推出2个产品序列:
1.0序列产品——Paratus 1.0、Paratus 1.5
Paratus 1.0和Paratus 1.5是大禹智芯的第一款DPU产品。通过运行在ARM SoC上的Linux操作系统及DPDK、SPDK开发套件,用户可将原先运行在主机侧的功能方便的下沉到DPU上运行,实现主机侧算力资源的释放。基于相同的DPU开发运行环境,大禹智芯也提供了虚拟化网络组件,存储客户端组件以及与开源云管平台Openstack和Kubernetes集成所必要的相关组件。用户通过Paratus1.0构建高性能的裸金属云、虚拟机云及容器云等服务。Paratus 1.0可广泛应用于公有云,边缘云,企事业内部私有云及其他复杂网络流量处理等场景。
2.0序列产品——Paratus 2.0
Paratus 2.0是大禹智芯在1.0序列产品基础上,通过增加FPGA组件而打造的全新DPU产品。采用ARM SoC + FPGA的硬件架构,在保持了与第一款DPU产品相同的软件开发运行环境的同时,提供了基于FPGA的网络数据处理通路,大幅提升了网络流量处理能力。在此基础上,Paratus 2.0还具有一些独特的功能:大禹智芯自研高性能网络协议HPRT™的实现可充分释放RDMA应用的潜力;无感知端到端网络数据加密功能可最大化保证数据网络传输可靠性,其功能及性能均为业界领先水平;网络上层应用行为分析功能可为网络入侵行为判断提供实时可靠的数据支撑。
恒扬数据:NSA系列
深圳市恒扬数据股份有限公司成立于2003年,通过灵活多变的客制化定制方式,为客户提供个性化DPU加速产品及异构计算加速方案的设计、研发及生产,满足用户在机器学习、视频转码、图像识别、语音识别、自然语言处理、基因组测序分析等多种应用场景的加速需求,实现高性能、高带宽、低延迟、低功耗的智能化计算加速。
恒扬数据DPU产品面向数据中心设计,为服务器提供高带宽IO,为数据中心算力提供高性能卸载,产品在网络、存储、安全、计算领域得到广泛批量应用。基于FPGA的设计方式,可极大地利用FPGA自身丰富的逻辑单元,实现对数据的快速并行处理,通过较小的能耗开销,实现数据中心性能的大幅跃迁。
恒扬数据NSA系列DPU产品及解决方案依托FPGA、FPGA+CX、FPGA+CPU等多种架构设计,其中FPGA单元主要基于Xilinx Zynq系列、KU系列、VU系列、VP系列,CX系列(包括CX5、CX6)芯片研制开发,产品可广泛应用于互联网数据中心的网络、存储、安全、计算等加速场景,是集高速IO带宽和高性能计算处理为一体的异构数据处理加速单元。
NSA系列DPU产品
产品方案可广泛应用于云数据中心网络、存储加速,网络虚拟化卸载、RDMA网络加速及资源池化等多种场景,助力客户在云数据中心的算力加速,包括图片/视频的处理分析、目标识别与追踪、基因测序、版权保护、传播影响力监测、素材管理等领域的算法加速。
火山引擎:火山引擎 DPU
火山引擎是字节跳动于2021年6月推出的云服务业务板块,至今逐渐完善了IaaS+PaaS+SaaS云服务体系。在2023火山引擎原动力大会上,火山引擎全栈自研核心组件——火山引擎DPU重磅登场。
火山引擎基于自研DPU推出了新一代服务器实例,整体性能大幅提升。在Intel全新一代SPR CPU平台上,通过引入火山引擎DPU,整机性能最高提升93%,单核性能最高提升13%。≤16c小规格实例性能最高提升6倍以上。
在AMD全新一代Genoa CPU平台上,通过引入火山引擎DPU,整机性能最高提升138%,单核性能最高提升39%。≤16c小规格实例性能最高提升10倍以上。而在Nvidia A800 裸金属上,拥有火山引擎DPU的加持,跨节点提供800Gbps RDMA网络带宽,更加适用于大规模集群分布式训练场景,提高集群并行效率,相较于上一代实例集群性能最高提升3倍以上。
据悉,火山引擎 DPU 整体网络性能升级到 5000 万 pps 转发能力,20us 延迟。目前,字节内部已经实现上万台 DPU 的部署,并且将持续提升渗透率。基于自研 DPU 的各类计算实例性能也有显著提升,例如适用于大模型分布式并行训练场景的 GPU 实例,相较上一代实例集群性能最高提升 3 倍以上。
Intel:IPU E2000
Intel在 2021 年 6 月正式提出了IPU,目的是改善资料中心效率与管理简便度,并强调这是唯一与超大型云端客户合作构建的加速与卸载解决方案。
E2000是Intel和谷歌共同设计的新型定制IPU芯片,代号为“Mount Evans”,以降低数据中心主 CPU 负载,并更有效和安全地处理数据密集型云工作负载。特性如下:
- 2 个 100 GbE 或 1 个 200 GbE 连接
- 多达 16 个 Arm Neoverse N1 核心
- PCIe 4.0 x16
- 支持高达 48 GB DRAM

Oak Springs Canyon是Intel第二代基于 FPGA 的 IPU 平台,该平台采用Intel Xeon-D和Agilex FPGA 构建。
在 2022 年的 Vision 全球用户大会期间,公布了其最新的IPU路线图,展示了从2022年至2026年IPU的整体规划。英特尔将继续 ASIC + FPGA IPU 设计,其IPU路线图如下:
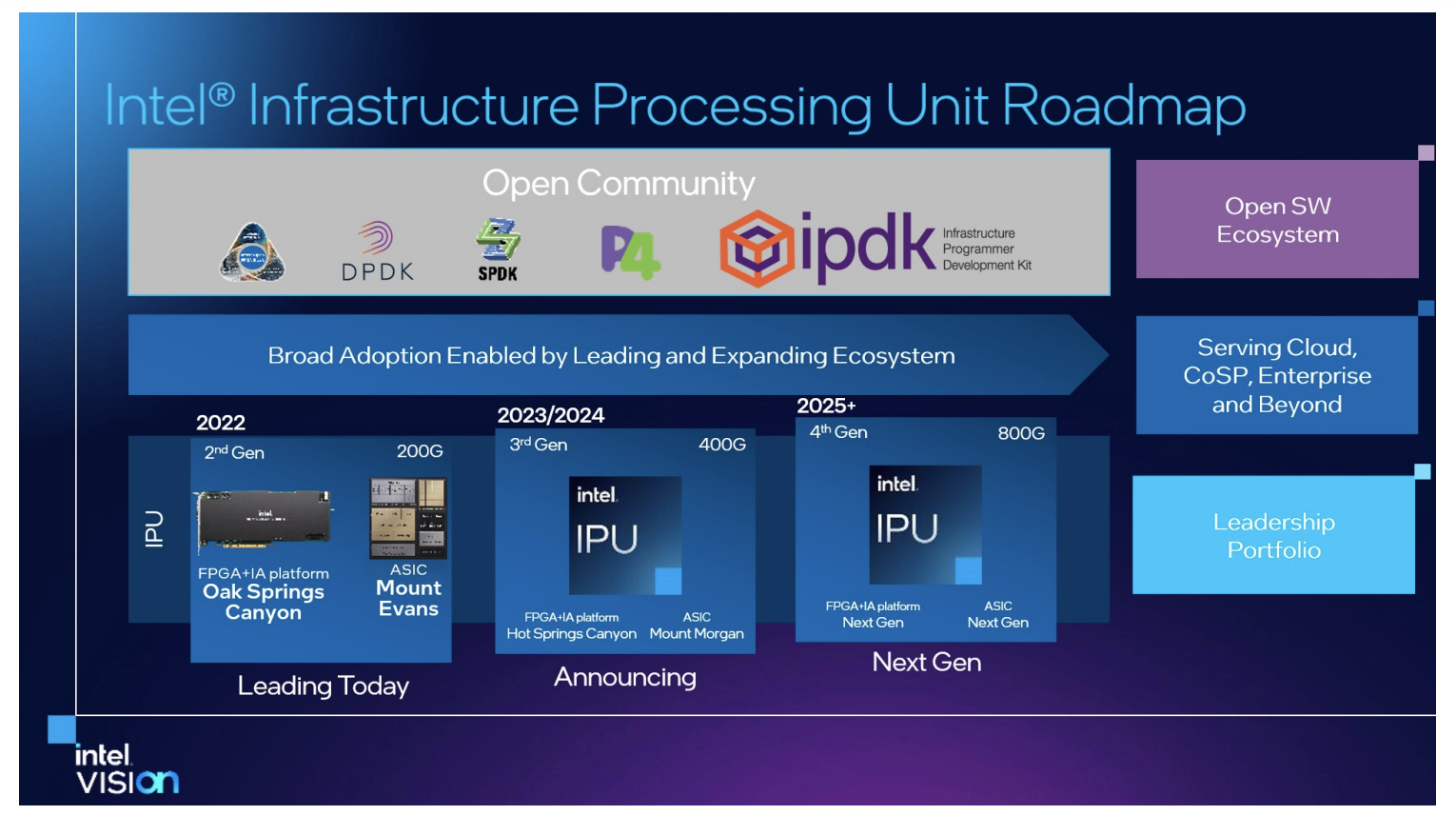
- 2022年:推出了200 Gbps IPU,代号为Mount Evans和Oak Springs Canyon。
- 2023/2024年:推出 400 Gbps IPU,代号为Mount Morgan和Hot Springs Canyon。
- 2025/2026 : 推出800 Gbps IPU。
京东云:京刚2.0
京刚是京东云自主研发的行业领先的全业务软硬一体虚拟化引擎,包括京刚智能网卡和完整的计算、存储、网络虚拟化协议栈和管理软件。在2022京东云峰会上,京东云正式发布了京刚2.0。
作为数据中心级DPU引擎,京刚2.0存储IOPS、网络转发性能均提升50%,效能提升立竿见影。基于存算分离技术自主研发的统一存储平台云海,打破了存算一体限制,使计算资源利用率提升30%。京刚2.0+云海软硬融合,存储性能提升10倍,极大提升了资源利用率,目前已经全面应用于京东618、京东11.11等大规模复杂场景。
京刚智能网卡的核心为基于FPGA的京刚DPU芯片,使用硬件替代软件完成虚拟化工作,极大提升了资源利用率。京刚智能芯片卸载网络转发和存储IO功能,让硬件性能不受损,支持了业界标准的SRIOV虚拟化技术,保证设备虚拟化无开销;同时,芯片级的硬件隔离技术,实现了用户负载和云管理负载的完全隔离,大幅提升了云计算平台的安全级别。
此外,京刚2.0还做到了更广泛的适配,同时支持x86架构下Intel、AMD处理器,及ARM架构下安培、飞腾等处理器,应用场景进一步扩大。
库瀚科技:eSPU
苏州库瀚信息科技有限公司是从事国产RISC-V低功耗、高性能数据IO管理/存储/网络基础设施芯片和解决方案的江苏省人工智能领军企业,定位为数据中心以及新型智算中心中低碳、全国产IaaS芯片和解决方案提供商。
库瀚eSPU单颗芯片以低功耗融合了存储及AI专用服务器CPU、智能网卡、PCIe Switch的IO功能,以及高性能RDMA网络技术,实现全可编程设计,可广泛应用于智算中心、数据中心的计算、存储、网络基础设施,处理I/O密集型任务。

eSPU(elastic Service Processing Unit)基础设施服务处理器
库瀚eSPU在覆盖常规DPU定义的网络能力外,可实现更强大的存储及IO能力。eSPU可实现IO路径更为精简的创新架构的AI服务器、存储服务器、新型存储盘框及智能网卡,尤其存储服务器场景可实现无CPU、无网卡、无PCIe Switch极简主板架构。
功耗:常见的双路配置下,相比传统配置双网卡、双CPU和 PCIe Switch的存储服务器方案,主板核心芯片功耗从500多瓦降低至约200瓦;
性能:存储方面,单颗eSPU存储/IO处理能力达到约1000万IOPS ,读写能效大于等于100K IOPS/W;双路2U存储服务器容量支持弹性扩展到1PB (32*32TB);网络方面,通过弹性扩缩算力和网络功能,网络带宽最大400Gbps ,网络处理功耗低于20W/100Gbps
Marvell:OCTEON 和 ARMADA 系列
Marvell 的 OCTEON 和 ARMADA 系列设备用于 5G 无线基础设施和网络设备,包括交换机、路由器、安全网关、防火墙、网络监控和 SmartNIC(智能网络接口卡)。
OCTEON 10 DPU 针对具有挑战性的超大规模云工作负载、5G 传输处理、5G RAN 智能控制器 (RIC) 和边缘推理、运营商和企业数据中心应用以及无风扇网络边缘盒进行了优化。OCTEON 10 DPU采用 Arm Neoverse N2 内核,5nm 工艺,与前几代 OCTEON 相比计算性能提高 3 倍,功耗降低 50%。

OCTEON TX2 是 64 位 ARM SoC 处理器,将多达 36 个内核与可配置和可编程硬件加速器模块相结合,支持高达 200G 的数据路径。
OCTEON MIPS64 多核DPU是唯一采用定制设计的 64 位 cnMIPS 内核并可扩展至 48 个内核的 DPU 系列。它结合了网络 I/O 以及先进的安全性、存储和应用程序硬件加速,提供高吞吐量和可编程性。
ARMADA DPU经过定制设计,可提供最佳性能、低功耗和高集成度。ARMADA DPU 系列针对计算、网络和存储平台中的成本优化应用进行了优化。
Marvell 为所有 OCTEON 和 ARMADA 系列提供统一软件开发套件 (SDK)。DPU系列设备的功能通过开源数据包和安全应用加速 API 得到增强。Marvell还提供行业标准控制、管理和数据平面软件堆栈,针对最新一代基于 ARM 的 OCTEON 处理器进行了优化。
沐创集成电路:N10、N20
无锡沐创集成电路设计有限公司成立于2018年12月,专注于可重构可编程系统芯片的研发和销售,主要产品包括密码安全芯片和智能网络控制器芯片。
2021年,沐创首款纯国产化智能网络控制器芯片N10顺利推出。N10系列智能网络控制器芯片是基于清华大学可重构技术开发出来的网卡芯片,拥有完全自主知识产权;支持八口10G,双口25G,双口40G 以太网接口,内置可重构处理器内核,支持网络协议卸载处理,同时还支持高效的密码算法加速,通过可重构实现40Gbps 的密码算法处理,支持国际密码(AES/SHA/RSA)和国内商用密码(SM2/3/4)等数十种算法,实现高效的IPSec/TLS 加速。RNP N10智能网络控制器芯片具有高安全、高性能、可编程等特点。截至当前,N10系列芯片已与百余家客户完成适配,并在众多客户的不同应用场景中落地生根。
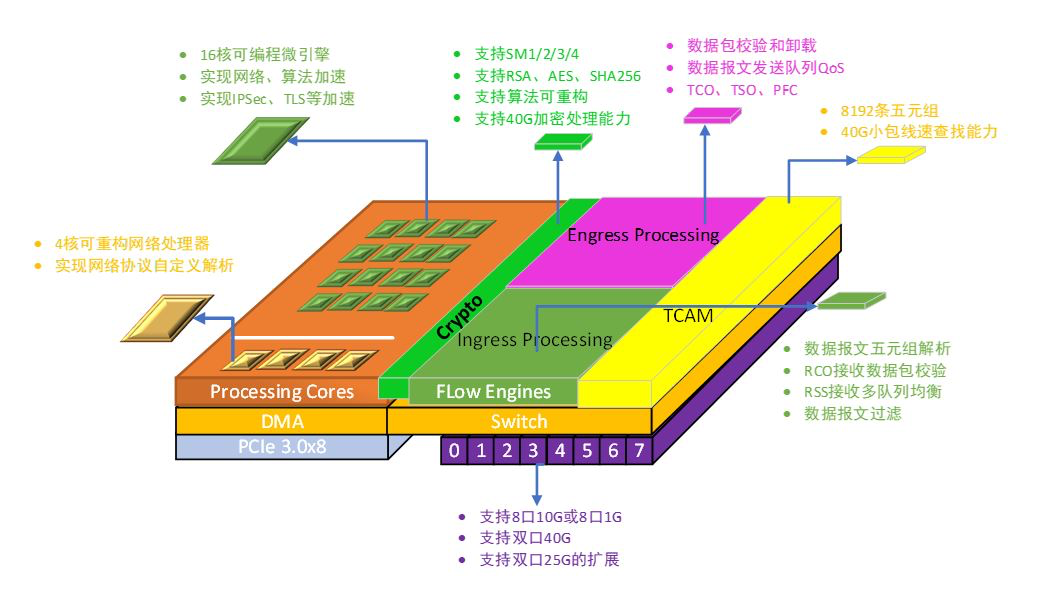
N10架构图
N20是沐创在研的第二代智能网络控制器芯片,是一款25G/100G的智能网卡芯片,具备高速网络协议卸载,RDMA,网络可编程,虚拟化等能力。主要面向国产服务器、网络安全设备、云厂等厂家,为其提供100G网卡芯片产品。
沐创公司的产品路线图如下:
- N10:2021年,第一代智能网络控制器,10G/40G,支持基础的网络协议卸载能、安全卸载和可编程能力;
- N20:2023年,第二代智能网络控制器,25G/100G,支持RDMA、OVS,更高性能的网络协议卸载、安全卸载、可编程能力;
- N30:2025年,第三代智能网络控制器,100G,多核ARM架构,数据平面和控制平面的全面卸载。
Microsoft(Fungible):F1、S1
2023 年1 月,微软宣布收购 DPU 技术提供商 Fungible。Fungible 曾经是最热门的半导体初创公司之一,自 2015 年以来已筹集了超过 3.7 亿美元的资金。Fungible 是第一家针对云级 DPU 的商业芯片公司,先于Intel、Nvidia、Pensando (AMD) 和 Marvell。
Fungible DPU 平台包括硬件和软件,按需拆分或组合计算和存储资源。它包括两个核心部分:一是可编程数据路径引擎,它可以高速执行以数据为中心的计算,并提供比通用 CPU 更大的灵活性。二是实现 Fungible 专有 TrueFabric 端点的网络引擎。可提供确定性的低延迟、高带宽、拥塞和错误控制以及从数百到数十万个节点的高安全性。
Fungible 有两款DPU芯片。Fungible F1 DPU 是一款 800 Gb/s 芯片,专为高性能存储、分析和安全平台而设计。Fungible S1 DPU 是一款 200 Gb/s 芯片,针对主机端用例进行了优化,包括裸机虚拟化、存储启动器、NFV 基础设施/虚拟网络功能 (VNF) 应用程序和分布式节点安全性。
Fungible S1 DPU 经过优化,可在服务器节点内组合以数据为中心的计算并在节点间高效移动数据。以数据为中心的计算的特点是高速数据流的有状态处理,通常是通过网络、安全和存储堆栈。S1 DPU 通过其 TrueFabric技术促进服务器节点之间的数据交换。
迈普:SNC 系列
迈普通信 SNC 系列智能网卡是迈普公司面向新一代云数据中心推出的智能化网络接口控制器。该系列智能网卡为公有云/专为云、高性能计算、人工智能和超大规模计算等应用而设计,提供强大的网络和应用平台能力,用于应对现代云和数据中心在网络性能、软件定义网络(SDN)、业务卸载、计算加速以及定制化解决方案等方面的挑战。

SNC4000-2S
该产品型号为 SNC4000-2S,该系列产品在满足传统的弹性裸金属及虚拟化场景下,追求高性价比以及提供强大的场景化定制能力,可灵活适应于客户特定的应用场景和服务器类型,可按需打造满足客户特定要求的高价值解决方案。

SNC5000-2S
该产品型号为 SNC5000-2S,该系列产品技术架构先进,根据不同的业务应用场景,提供基于 CPU+FPGA 芯片的智能网卡解决方案,国内技术领先。可针对数据中心计算/网络/存储等基础设施,提供区别于传统网卡的强大优化能力,如网络加速、OVS 卸载、存储标准化、加解密、安全卸载、裸金属管理、可编程能力等。从芯片到硬件到软件的全方位提供安全可控、稳定、可靠、开放的高性能智能网卡软硬件平台。

SNC5000-2H
该产品型号为 SNC5000-2H,具备 100G 的接口能力以及标准的 BMC 管理能力,致力于 打造高吞吐转发性能以及高 IOPS 存储性能的产品。除传统裸金属和虚拟化场景智能网卡的 能力外,还提供适用于容器等场景对 SRIOV 有极致虚拟化要求的能力,以及提供硬件国密加解密算法能力。
NVIDIA:BlueField 系列
NVIDIA是一家以设计显示芯片和主板芯片组为主的半导体公司,总部位于美国加利福尼亚州圣克拉拉市。2020 年 4 月,Nvidia 以 69 亿美元的价格收购了网络芯片和设备公司 Mellanox,随后陆续推出 BlueField 系列 DPU。
NVIDIA BlueField-3 DPU 延续了 BlueField-2 DPU 的特性,是首款为 AI 和加速计算而设计的 DPU。BlueField-3 DPU 提供了最高 400Gbps 网络连接,可以卸载、加速和隔离软件定义网络、存储、安全和管控功能,从而提高数据中心性能、效率和安全性。

BlueField-3 DPU 能够满足苛刻的应用基础设施需求,在I/O路径中提供强大的计算能力和广泛的可编程加速引擎,同时通过NVIDIA DOCA软件框架提供完整的软件向后兼容性。
BlueField-3 DPU 将传统的计算环境转变为高性能、高效和可持续的数据中心,使组织能够在安全的多租户环境中运行应用程序工作负载。BlueField-3 DPU 将数据中心基础设施与业务应用分离,增强了数据中心的安全性,简化了操作并降低了总拥有成本。
锐捷网络:湛卢系列
锐捷网络结合对云数据中心方案和运营商数据中心业务的理解,推出了智能网卡产品,面向裸金属、虚拟化和存储卸载三大场景,整合运营商大云方案开发智能网卡解决方案,在提升服务器内网络性能同时,实现网络Overlay、混合Overlay过渡到统一的主机Overlay架构,简化了运营商云数据中心的逻辑组网模式,支持裸金属、虚拟化环境,实现统一的网络架构,并且具有更强的转发性能和可编程特性,可灵活扩展有状态安全组、QoS流控和SDN网络功能,同时Underlay层面的物理交换机不再与SDN方案绑定,增加了运营商云数据中心网络设备选择的灵活性。
锐捷网络支持 2x100G和2x25G智能网卡:

RG-SMARTNIC-2000 双口100G智能网卡(左)、RG-SMARTNIC-1810双口25G智能网卡(右)
锐捷网络湛卢系列智能网卡基于FPGA+SOC增强架构,支持裸金属和虚拟化两种模式,通过FPGA实现OVS快路径的转发功能卸载,通过SOC实现OVS DPDK慢路径转发和存储SPDK控制功能卸载,因此支持转发和控制功能的网络全卸载。
锐捷智能网卡基于FPGA+SOC架构,可以根据用户将来需求不断迭代新功能。支持裸金属、虚拟化和存储卸载三大场景功能,支持OVS 转发和控制功能全卸载。锐捷智能网卡方案可以实现与运营商云平台全面对接,可在 SOC 上部署裸金属插件、存储插件、虚拟火墙等应用。
腾讯:水杉、银杉
2020年9月,腾讯第一代基于FPGA的自研智能网卡正式上线,命名为“水杉”。水杉投入应用后,“银杉”的研发工作也紧锣密鼓地启动,并于2021年10月正式上线。

在网络方面,银杉提供2*100G网络带宽、高达5000万PPS的超高网络性能;存储方面,提供高达100万IOPS,存储延迟低于40微秒;同时,银杉具备弹性RMDA支持,可为业务提供Bypass kernel和零拷贝的网络传输能力,网络延迟低于5微妙,满足企业高性能计算和集群训练场景的高性能需求。
目前,腾讯自研DPU已经支撑公有云外部客户,以及微信、QQ、腾讯会议等自研业务上云。
2021 年 11 月,腾讯发布了玄灵智能网卡芯片,腾讯表示其定位于云主机的性能加速,结合CVM/BM/容器等场景优化芯片架构,将原来运行在主CPU上的虚拟化、网络/存储IO等功能下移到芯片,实现了主CPU的零占用,相比业界产品性能提升了4倍。这一芯片的目标或许和云计算有关,更进一步或许和云游戏相关,游戏业务对腾讯至关重要,而云游戏则面向未来,通过玄灵智能网卡芯片,腾讯或将进一步完成其在云游戏领域的深入布局。
天翼云:紫金DPU 2.0
天翼云紫金DPU 2.0采用FPGA+SoC架构,依托于FPGA超高的性能和灵活的可编程特性,将数据面全卸载到FPGA,实现业务的直接硬件卸载加速,支持网络虚拟化、存储虚拟化、IO虚拟化、RDMA、高可用等关键技术。相较于传统数据中心,搭配紫金DPU的新一代数据中心,具有多个方面的领先优势。
1.软硬协同卸载加速。充分发挥软件“功能全”,硬件“速度快”的优势。让硬件专注解决主要矛盾,发挥极致性能;软件则提供完整功能,负责整个系统的兜底。整个系统软硬协同,通力合作,从而达到1+1>2的协同效果。网络转发性能超过5000万PPS,存储读写性能超过200万IOPS。
2.SF-STACK超融合协议栈。打造内核态TCP/用户态TCP/RDMA三栈合一的传输层。内核态TCP主打高可用,用于故障切换。用户态TCP和RDMA主打高性能,分别用于跨AZ和AZ内的数据传输。传输层对上提供统一接口,动态选择传输协议,真正做到简单易用,高可靠,高性能,可大规模部署。
3.一云多芯、即插即用。紫金DPU实现了主机CPU环境与虚拟化环境的物理隔离,主机不同CPU芯片架构的服务器实现了“即插即用”。紫金架构更加开放、灵活、兼容,提升了算力资源使用效率和国产化平台性能,架构适配上做到了又快又稳。
天翼云紫金DPU主要为天翼云自身产品提供底层和技术支撑,通过弹性裸金属、云主机、容器等产品进行整体售卖。紫金DPU支持弹性裸金属、云主机、容器等场景,目前已经在天翼云部分资源池推广部署2000+台服务器,后续将在整个云数据中心全面推广部署。
天翼云将坚持DPU核心技术自主研发,持续演进,产品路线图如下:
- 2022年:DPU1.0。
- 2023年:DPU2.0,支持25G网络,支持SF-STACK超融合协议栈等核心技术。
- 2024年:DPU3.0,支持100G网络,并适配更多的业务场景。
新华三:赤霄
新华三自研的赤霄智能加速卡实现了网络无损、存储无损、计算无损和安全无损的全无损能力。基于赤霄智能加速卡,实现一卡即一个完整的超融合系统,在任意UIS认证的一体机上即插即用,结合内置UIS 软件系统,可实现计算、存储、网络、安全能力的全卸载,主机资源完全让给用户业务使用,实现主机业务的零损耗,为CPU减负20%,网络延迟从ms级降低至us级,存储Kernel Bypass IO性能提升100%。
UIS赤霄智能加速架构的核心是实现了网络加速和存储加速。采用加速卡加速以后,在主机上仅需运行虚拟化平台,承担CPU、内存及少量外设的虚拟化,而网络访问,存储访问及存储的处理逻辑全部下沉到加速卡上去处理。
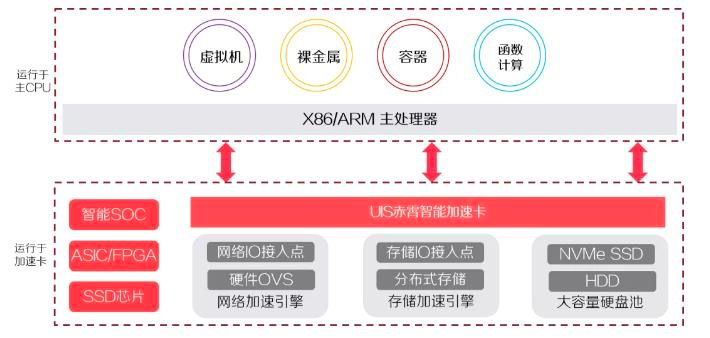
UIS赤霄智能加速架构具备如下优势和特点:
智能加速:新型虚拟化技术,主机侧虚拟化损耗为零,提供等同于物理机的CPU性能;
全运行态:支持对虚拟化、裸金属、容器、函数计算的加速能力,实现统一的超融合计算架构;
ABC能力:支持云计算(Cloud)、大数据(Big Data)和AI的深度融合,提供智能化超融合架构,广泛应用于各种云数场景。
UIS赤霄智能加速架构的应用场景将会十分广泛,对于所有的云数场景都适用,支持数据和计算分离,提供各种性能加速和增值能力,作为“为云原生而生的超融合架构”将有力的支撑客户在各种场景的存算需求。
芯启源:芯启源DPU系列
芯启源智能网卡是基于SoC架构的成熟DPU解决方案,具备完全的自主知识产权并已成熟量产,可以提供从芯片、板卡、驱动软件和全套云网解决方案产品,同时具有可编程、高性能、低功耗、低成本、节能减排等独特优势,可以为5G通讯、云数据中心、大数据、人工智能等应用提供极有竞争力的解决方案,满足当前快速迭代的新技术、新应用不断对基础设施提出的新需求。
芯启源下一代DPU架构基于Chiplet技术,极大的提升了自有网卡产品的性能;同时通过支持与第三方芯片的Die-To-Die互联,还可以集成更多的特定专业领域芯片。除了在性能和功能丰富度有飞跃式提升外,基于下一代DPU芯片的网卡产品将为客户提供更多业务场景的支持能力。
芯启源下一代DPU智能网卡是基于DPU芯片的新一代智能网卡,采用NP-SoC模式进行芯片设计、多线程的处理模式,使其可以达到ASIC固化芯片的数据处理能力。在高性能数据处理的同时,芯启源DPU智能网卡还具备灵活高效的可编程能力,支持P4/C语言等高级编程语言的混合编程能力,支持基于XDP的eBPF卸载,帮助客户实现贴合自身业务的定制化功能。兼具了FPGA高效、灵活可编程和专用处理器芯片(ASIC)低成本、低功耗的优势,致力于为客户提供高性能、低成本、产业化、生态化的解决方案。
芯启源DPU产品路线图如下: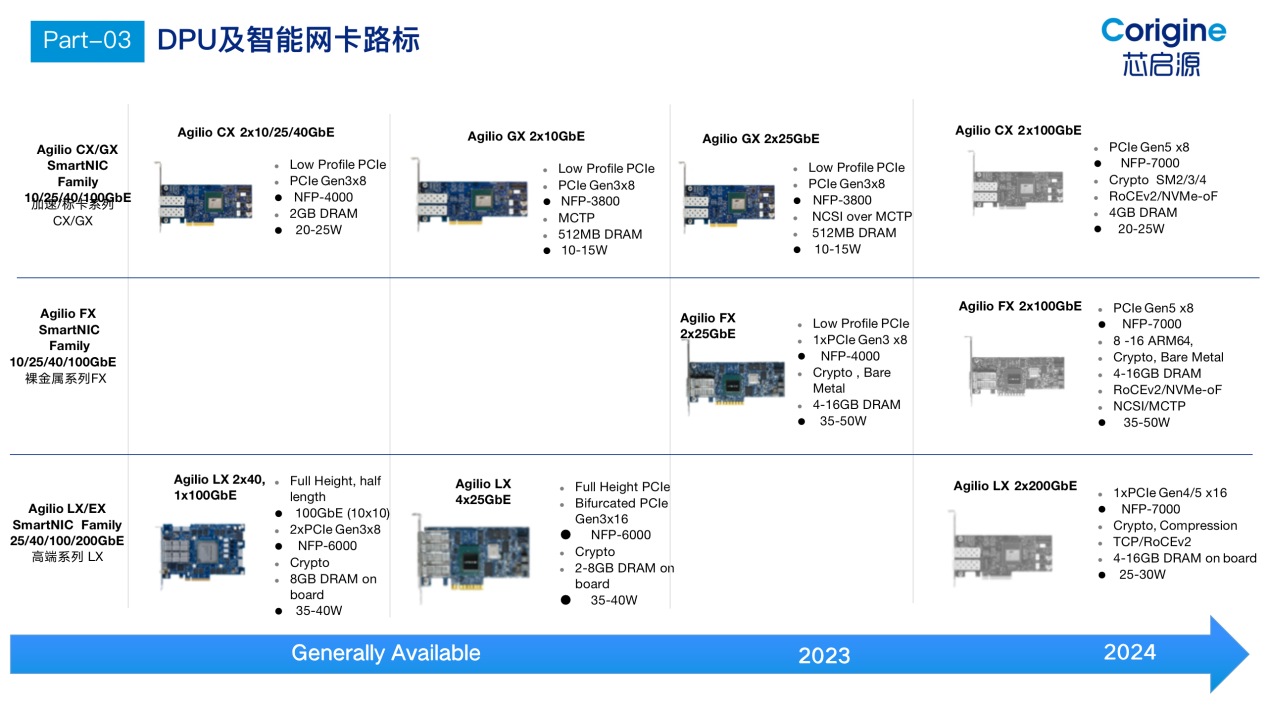
星融元:Helium DPU网卡
Helium智能网卡是星融元Asterfusion自主研发的一款基于高性能DPU芯片的25GE/100GE以太网智能网卡。星融元为客户提供了软硬一体的一站式综合开发环境,除了高性能硬件平台外,还提供了底层基座操作系统和开发套件。这使得客户可以专注于上层应用程序的开发,而无需关注底层支撑框架,从而可以加速开发和移植进度。客户原来跑在x86服务器上的各种DPDK应用和VPP应用,仅需要简单编译就可以迅速移植到Helium智能网卡上。

作为高性能的25GE/100GE以太网智能网卡,它可以提供高达100Gbps的混合业务处理能力,符合PCIe及以太网协议,并提供PCIe*8 Gen3.0/Gen4.0主机接口。该网卡可广泛应用于网络加速、安全加速、存储加速等领域,包括但不限于OVS卸载/VTEP、TCP卸载、5G UPF加速、IPSec、SSL、XDP/eBPF、vFW/vLB/vNAT、NVMe-oF(TCP)、压缩/解压缩等场景。
Helium DPU网卡具有高性能、易移植、多应用场景等特点。目前,星融元基于Helium DPU网卡,提供了NAT、DPI等方案,助力客户构建高性能、智能化、可编程的业务网络。该网卡能够充分释放服务器内宝贵的计算资源,节约用户的建设和运营成本。
星云智联:NebulaMatrix DPU
星云智联成立于2021年3月,是一家专注于数据中心通信架构和DPU芯片研发的创新企业。星云智联致力于构建数字世界算力的智能连接和开放生态,旨在让云计算和数据中心成为构建未来数字社会的坚实基础。
星云智联在2022年推出的全系列DPU产品已全面实现技术落地,在互联网、运营商、行业云、中小云等各行业的典型客户完成系统测试和灰度测试,检验了星云智联DPU在客户系统被集成的全流程适配,客户灰度测试完成后即将迎来大规模的部署和商用。

星云智联产品族包括:
- DPU:2x100G,2x25G
- SNIC:2x100G,2x25G,4x10G,2x10G
- RNIC:1x400G,2x200G,2x100G
SNIC(2x10 GbE/4x10 GbE/2x25 GbE)在机器视觉、互联网、行业云、信创等客户市场实现规模销售和商用部署。2x100G DPU产品将于2023年下半年推出,相对25G DPU在全面增强功能和大幅提升性能的同时降低延时,RDMA功能得到全面加强,采用自研NBL-CC拥塞控制算法,实现5us的超低延时,支持万台节点规模。
1x400G/2x200G RNIC 即将于2023年下半年推出,采用星云智联成熟的RDMA技术,助力高性能、大规模、低时延的GPU集群网络互联,可广泛应用于AI大模型、云计算GPU池化、HPC高性能网络互联等场景。2023年下半年即将完成 DPU&SNIC芯片流片,并围绕自研芯片推出系列化DPU产品、SNIC产品和RNIC产品,功能全面覆盖上述产品,性能和功耗全面优化升级,软件生态完全兼容,可快速在客户系统完成适配和部署,为客户提供更低成本更低功耗的互联解决方案。
移动云:磐石DPU
磐石DPU由移动云计算团队自主设计和研发,是中国移动强化芯片自主可控、布局算力网络的重要载体。基于移动云算力迭代需求,结合业界首推的COCA(Compute on Chip Architecture)开放生态,实现“算力+连接”的高性能、高效率、集群化算力架构。

磐石DPU
磐石DPU聚焦算力服务,以100%自研安全、稳定、可靠、高性能硬件为措施,力图在算力、连接、效率等关键领域取得核心突破,主要创新点包括:
1.基于磐石DPU “PCIe Switch+PF/VF”动态封装算力服务接口,实现一套硬件满足移动云裸金属、云主机、容器等多种算力载体的业务需求,突破性能瓶颈,降低算力损耗的同时提升算力编排效率。
2.自研弹性裸金属虚拟化技术栈,以自主设计的可编程芯片磐石DPU和全新打造的轻量级Hypervisor为核心,突破传统技术架构极限,实现真正意义上的I/O虚拟化零损耗。
3.提出硬件多级流控QoS引擎,实现整机QoS、队列QoS、流级QoS的双向三级QoS精细调度,在高优先级业务带宽保证的同时具备更低时延、更小抖动。
4.自研RNIC算法,将RDMA路径管控逻辑全面开放,实现网络数据路径透明、智能、实时管控,场景化降低RDMA网络通信时延,减少连接路径上的网络抖动,以实现大规模场景下高效率、大容量吞吐和时延低至5微秒的网络数据传输。
5.存储卸载引擎通过全方位深度开发的虚拟化卸载技术NVMe-oF、RDMA等,结合用户态存储后端转发能力,实现云存储IO全链路零拷贝。
当前,磐石DPU已应用到移动云全系列计算产品中,并支持以容器为接口实现硬件级云原生的能力拓展,满足HPC、AI等高性能业务上云诉求。下一阶段,磐石DPU将通过COCA联动GPU、RDMA等技术体系,面向AI/HPC场景构建以AI大模型应用场景为代表的端到端技术能力支撑体系,构建AI抽象、AI池化、AI加速三大模块和自主可控的高性能算力连接核心技术,解决国产GPU生态“碎片化”和算力集群大规模扩展瓶颈问题。
益思芯科技:Stargate DPU
益思芯科技(上海)有限公司成立于2020年7月,团队由国内外网络、交换、存储领域的核心专业人员组成,在网络、交换、存储及高性能CPU等领域具有深厚的技术实力。公司致力于为通信、互联网行业提供领先的存储与网络芯片解决方案。
Stargate DPU智能网卡是一款具有自主知识产权的P4可编程云原生智能网卡。益思芯科技的P4网络加速引擎是针对vSwitch加速而设计的VLIW ISA P4可编程处理器,不依赖于FPGA的可编程性,支持千万级流表的同时性能可以做到数据包线速转发。NVMe-oF引擎基于全硬件逻辑实现,具有高性能、低延迟等特点,是对高速共享存储有较高要求的云计算、HPC、数据库等应用领域的最佳选择。
益思芯科技DPU智能网卡技术与产品创新点如下:
1.P4网络可编程:具有自主知识产权的DSA P4引擎,满足灵活的定制需求;具有高性能、低延迟、高灵活性、低功耗等特点。
2.NVMe-oF高速共享存储:NVMe-oF把NVMe协议在单系统中的高性能、低延迟和低协议负担的优势发挥到了基于高速网络的NVMe共享存储架构中。益思芯NVMe-oF技术采用全硬件加速的端到端解决方案,是数据中心下一代共享存储的最佳解决方案。
3.丰富的安全特性:支持完善的网络安全、存储数据安全处理;支持国密SM2/SM3/SM4加解密算法。
4.云原生软件开发平台:支持使用Host侧的云原生驱动。与开源DPDK、SPDK库无缝对接。
益思芯科技产品规划如下:
云豹智能:Corsica DPU
云豹智能是一家专注于云计算和数据中心DPU和解决方案的领先半导体公司。云豹智能自主设计研发的Corsica DPU芯片是云计算数据中心高性能软件定义数据处理器芯片,具备丰富的可编程性和完备的DPU功能,支持不同云计算场景和资源统一管理,优化数据中心计算资源利用率。
云豹Corsica DPU具有性能强大的“CPU+可编程硬件”,不仅能够保证硬件计算的高能效,还能提供灵活的软件定义的可编程能力,助力数据中心提供租户自定义高能效云计算基础设施服务。
云豹Corsica DPU具备层级化可编程、低时延网络、统一运维管控和适应云计算业务持续发展的加速卸载等特性,主要聚焦解决当前数据中心应用中消耗CPU、GPU算力资源的网络、存储、安全以及应用相关问题,诸如AI、数据库等性能要求敏感的数据处理任务。
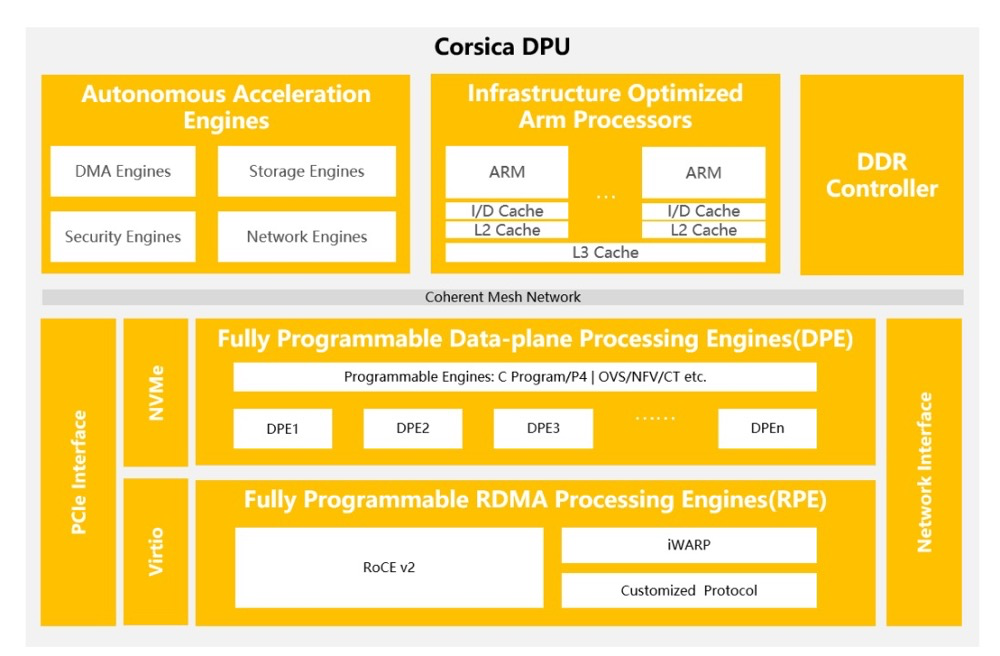
云豹Corsica DPU提供最高2*200G网络连接,搭载性能强劲ARMv9架构的通用处理单元,满足数据中心云计算基础设施层业务的卸载需求。云豹智能Corsica DPU还配备众多自主研发设计的可编程硬件加速处理引擎,实现网络、存储和安全的全面加速,具体情况如下:
数据面处理引擎提供高性能数据处理,具备灵活的软硬件多层级可编程能力。
RDMA处理引擎支持RoCE和iWARP等主流协议和可编程拥塞控制算法。
安全处理引擎提供SM2/SM3/SM4等国密和其他主流加密算法。
支持安全启动、机密计算、加解密的零信任安全解决方案,保护系统、数据、应用的安全。
支持DDP(Data Direct Path)数据直通技术,加速数据处理,提高 AI 训练效率。
云脉芯联:metaFusion、metaConnect系列
云脉芯联自2021年成立以来已经先后发布了面向云计算场景的metaFusion系列DPU产品和主打RDMA高性能网络的metaConnect系列智能网卡产品,能够提升用户计算集群整体的运算效率,释放更多CPU资源支持上层应用,满足数据中心云计算、智能计算、云存储等核心场景集群高性能互联和算力扩展的业务诉求。
云脉芯联第一款高性能DPU产品metaFusion-50基于自主知识产权硬核业务逻辑研发设计,重点针对当前云计算数据中心发展的新需求,解决云计算产品形态支持能力的问题,实现统一计算、网络、存储的管理方式,简化云计算平台的管理运维成本,提升新基建的综合业务能力。metaFusion-200高性能DPU为云计算基础设施提供了丰富的虚拟化能力、高性能的开放网络、灵活的存储解决方案,同时在RoCEv2网络还提供了自主创新的HyperDirect能力和可编程拥塞控制算法平台,实现高性能网络能力。

metaFusion-50(左)和metaFusion-200(右)
云脉芯联推出的高性能智能网卡产品metaConnect-200,提供了高性能RDMA网络能力,支持自主创新的HyperDirect技术,可以有效加速GPU和AI芯片的计算效率,可编程拥塞控制算法平台可以帮助用户根据不同的业务类型设计和应用适合的拥塞控制算法,提升端到端的网络性能和可靠性,主要应用于AI/ML、HPC和高性能存储场景。

metaConnect-200
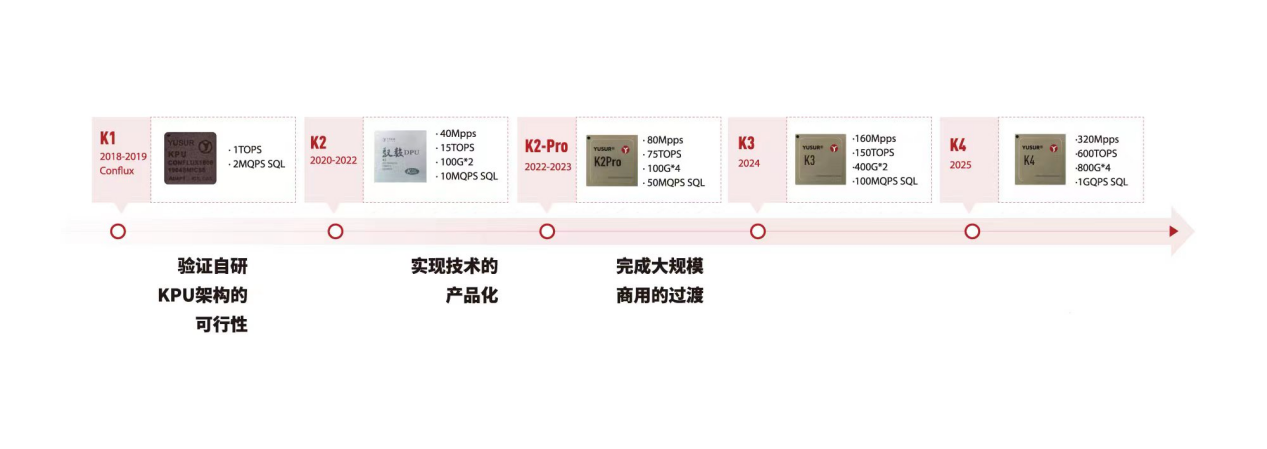
中科驭数:K1、K2、K2-Pro
中科驭数在网络、存储、计算等领域积累了TOE、RDMA、NVMe-oF、大数据处理等功能核,已开展三代DPU系列芯片的研发迭代工作。其自主研发的DPU产品可应用于超低延迟网络、大数据处理、5G边缘计算、高速存储等场景,助力算力成为数字时代的新生产力。
中科驭数自研的第二代DPU芯片K2采用28nm成熟工艺制程,可以支持网络、存储、虚拟化等功能卸载,具有成本低、性能优、功耗小等优势。尤其在性能上,其具有极其出色的时延性能,可以达到1.2微秒超低时延,支持最高200G网络带宽。在应用场景上可以广泛适用于金融计算、高性能计算、数据中心、云原生、5G边缘计算等场景。

K1(左)和K2(右)
在核心技术上,公司提出了创新性的软件定义加速器技术(Software Defined Accelerator),自主研发了面向领域专用计算(DSA)的芯片架构KPU(Kernel Processing Unit)和敏捷异构软件栈(HADOS)。基于中科驭数DPU芯片底层,搭载敏捷异构开发软件HADOS,公司面向高吞吐、低时延场景,打造了三大体系“思威(SWIFT)系列、功夫(CONFLUX)系列、福来(FLEXFLOW)系列”,性能表现优越。
此外,中科驭数还积极布局DPU产品矩阵,打造软硬一体化的高吞吐、低时延的产品生态,其中基于DPU研发的超低时延智能网卡、数据计算加速卡、以及面向金融计算领域的解决方案已经实现成熟规模化商用。
中科驭数DPU发展路线图如下: