

作者:李勇坚, 曹嘉伦,中国科学院 著。人工智能开放创新平台(chinaopen.ai)联合学者

一、背景
带参系统存在于许多应用领域中,比如缓存一致协议等。因为它的研究价值,验证这样的系统的也就吸引来了形式化验证、模型检测和定理证明等社区的关注。要想验证带参系统的正确性,就必须验证任意实例大小的系统中的正确性,而这被证明是一个无法判定的问题。
尽管这样的难度,但是很多方法仍然被提出来试图解决这个问题。CMP方法是其中最成功的方法之一。它用模型检测的方法来验证Intel、flash等大型的协议。通过保留m个节点, 并用一个抽象的节点NOther来替代其他所有剩余节点的行为。通过这样的抽象,一个原始的协议就被抽象成了一个由m+1个节点组成的抽象写意。然后通过分析模型检测器提供的反例,循环构造一系列引理来限制抽象节点NOther的行为,使得协议可以收敛,且不会违反原有性质。如果最终原始性质和引理都能在抽象协议中被检验通过,那么就能推导出原始协议在任意大小的实例下也都能成立。但是,CMP方法是在模型检测机给出反例之后,采取的是被动补救措施。这样的被动方法由于依赖于人工理解和指导,而无法自动化。而且“寻找反例-卫式加强”这样的循环,所需要的次数未知,这也就使得可达集是否能收敛、抽象协议能否满足安全性质成为未知。
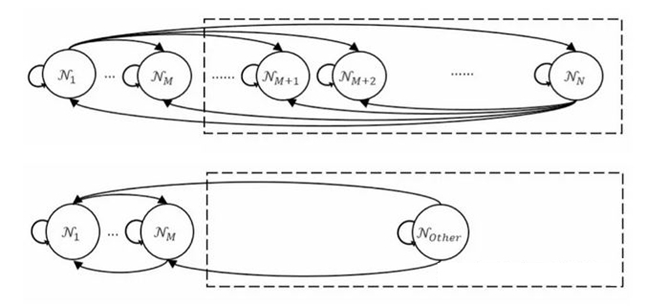
CMP存在的缺点启发我们去更深入地思考:是否能够通过主动地探索满足上述条件的可达集边缘,以使可达集收敛,并满足安全性质?如果能够主动的限定可达集能到达的范围,则可以更主动地搜索辅助不变式,从而更精确地加强抽象系统。
因此,在这篇论文中,我们提出了L-CMP,一种自动的学习框架,通过较小实例可达集学习/挖掘辅助不变式,并且自动的用这些辅助不变式对抽象协议进行限制,最终,抽象协议的可达集可以被收敛在合理范围,安全性质也就能够保证。
二、关联规则学习
在本文中,我们巧妙地将关联规则学习(Association rule learning)与卫式加强做结合,成功达到了寻找辅助不变式及自动卫式加强的目的。
关联规则学习是Agrawal等人提出的基于规则的机器学习方法。它的目的是利用一些有趣性的量度来识别数据库中发现的强规则。基于强规则的概念,Rakesh Agrawal等人引入了关联规则以发现由超市的POS系统记录的大批交易数据中产品之间的规律性。许多有效的关联规则算法,如Apriori,Eclat和FP-growth。在本文中,我们使用Apriori作为关联规则的学习算法进行学习。
给定由一组事务组成的数据集D,记为D = {t1,t2,…,tm}。 设I = {i1,i2,…,in}是一组包含许多项目的项集。 每个交易t包含一个项目子集。 一个关联规则的形式是X→Y,其中X,Y∈ I. X被称为前件,Y是规则的后件。 此外,还有一些约束条件来衡量规则的重要性。 在本文中,我们重点关注两个标准:支持度和置信度。
支持度: 它测量在同一事务中发生的项目集的频率。 K频繁项目集是频繁集合中包含K个项目的项目集。 可以将支持计算为在同一事务中出现多个项目的概率。 支持价值的最低阈值被称为最小支持度。
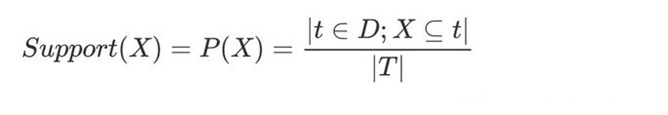
置信度: 它表示出现X时同时Y出现的概率。
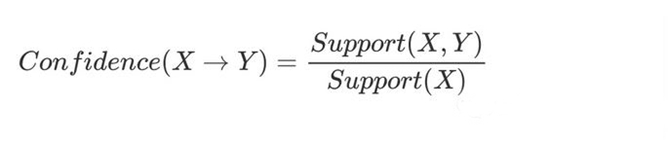
三、框架
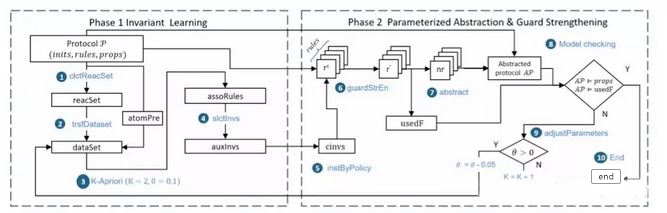
L-CMP可以分为以下两个阶段:
学习不变式:这个阶段旨在通过学习算法寻找出辅助不变量。在这个阶段,我们首先收集协议的一个小实例 m(通常是m = 2)的可达状态集合(步骤1)。然后,我们直接从协议描述中提取原子谓词,并将它们看作项目集以指导数据集的转换(步骤2)。这一步对于第二阶段是必要的,第四节解释了背后的原因。接下来,通过关联规则学习,可以学习一组关联规则(步骤3)。值得注意的是,我们使用的数据集由一个小型的协议实例进行转换,因此由于实例的大小有限,无法表示整个参数化协议的行为。此外,我们已经应用了对称减少技术来使一些大协议中的可达状态最小化,导致数据集的不完整性。因此,需要额外的步骤(步骤4)。我们将这些关联规则视为候选不变量并将它们输入模型检查器Murphi。如果他们持有协议的一些小实例(大于m),则它们被视为辅助不变量。如果某些失败,失败的将从候选不变集中消除。最后,左边的候选不变量作为辅助不变量。
参数抽象和卫式加强:这个阶段是抽象协议,并使用辅助不变量加强抽象规则的卫式部分。首先,辅助不变量以及协议中的转换规则将通过分配具体索引来实例化(步骤5)。这一步为加强步骤提供了便利。接下来,通过以关联规则的形式添加辅助不变量的结果,递归地加强规则守护(步骤6)。然后,通过删除关于不可观察节点的局部变量来抽象加强的规则(步骤7)。值得注意的是,我们提出了一个映射操作,它建立了守卫与行动之间的关系,以便最大限度地加强规则。之后,加强和抽象的规则将附加到原始协议并送入模型检查器(步骤8)。请注意,用于加强守则规则的辅助不变量也需要验证将它们翻译成Murphi代码后。自动翻译的过程较为简单,所以我们在本文中就不赘述。如果抽象协议实例通过大小为$m + 1$的模型检测器,则结束框架(步骤10),否则就需要调整学习算法中的参数,并且框架开始下一轮学习(步骤9) 。
四、实验结果
我们将L-CMP应用于5个经典的带参协议上进行实验,实验结果如下表:
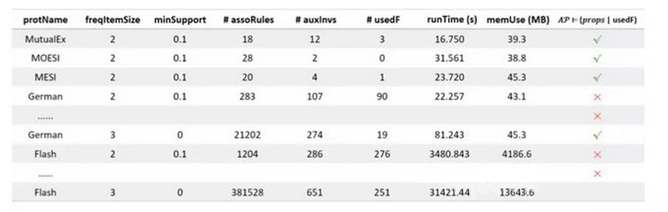
其中,列名分别为协议名称、频繁集个数、最小支持度、关联规则个数、辅助不变式个数、所用不变式个数、总运行时长、所耗内存峰值、抽象协议能否通过验证。
可以看到,我们的L-CMP能够很好地对包括Flash协议在内的各个协议进行很好的验证。
四、总结
在本文中,我们提出了一个自动框架L-CMP,它可以在一个统一的框架中自动学习辅助不变量,并进行抽象参数和卫式加强。 我们工作的创新性集中体现在于以下两个方面:
我们不是通过分析计数器例子来手动制定不同的变体,而是通过关联规则学习从协议的可达状态集合中导出不变量;
在反例生成之后,我们不再强化协议,而是根据自动学习的不变量直接进行卫式加强。
在未来的工作中,我们希望扩展L-CMP的验证能力,使其能证明一般的安全性质和活性性质,而不仅局限于不变式。
参考文献
[1] Lv, Y., Lin, H., Pan, H.: Computing invariants for parameter abstraction.In: Proceedings of the 5th IEEE/ACM International Conference on Formal Methods and Models for Codesign, IEEE Computer Society (2007) 29–38
[2] Apt, K.R., Kozen, D.C.: Limits for automatic verification of finite-stateconcurrent systems. Information Processing Letters 22(6) (1986) 307–309
[3] Chou, C.T., Mannava, P.K., Park, S.: A simple method for parameterized verification of cache coherence protocols. In: FMCAD. Volume 4., Springer (2004) 382–398
[4] Agrawal,R.,Imielin ́ski,T.,Swami,A.:Miningassociationrulesbetweensets of items in large databases. In: Acm sigmod record. Volume 22.,ACM (1993) 207–216
[5] Agrawal, R., Srikant, R., et al.: Fast algorithms for mining associationrules. In: Proc. 20th int. conf. very large data bases, VLDB. Volume1215. (1994) 487–499
转载自 人工智能开放创新平台
















