

作者简介:周栋,北京邮电大学 未来网络理论与应用实验室博士生,研究方向为未来网络体系架构、可编程网络。邮箱: hardworkzd@163.com
最近ChatGPT可以说是火爆各大圈子,不同于以往的对话AI,ChatGPT能够更好地理解人类的意图——生成的内容是根据历史对话信息生成的,并不只是局限于当前问题;而且能够完成的事情更加丰富——可以帮助你写代码、想文案、改论文、做PPT等等。
如此之大的AI表现力的突破究竟来自哪里?当然,模型算法的不断优化改进是重中之重,但我们也很难一时半会从浩如烟海的算法技术细节中整理出思路。我们可以从另一个更为直观的角度来理解这种进步,那就是模型参数的规模。ChatGPT源自于OpenAI推出的GPT系列模型,仅GPT-1就有上亿的参数量,到ChatGPT所使用的GPT-3.5更是膨胀到夸张的万亿参数。这种大模型其实并不是独一份,腾讯的混元模型参数规模也是达到万亿级别 [1],阿里达摩院的M6模型参数更是突破10万亿[2]。
表 GPT系列模型参数和数据规模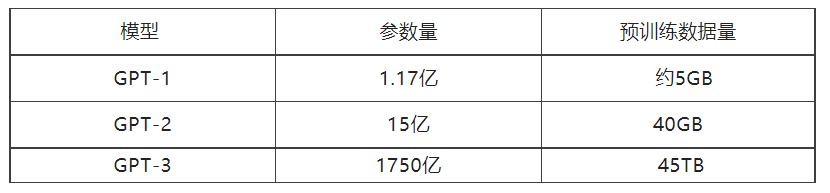
神经网络越深,参数越多,模型的能力就越强,就能解决更复杂的问题。基于此,AI大模型层出不穷,但是同时也伴随着一个问题——大模型+大数据该如何进行训练?不论是模型还是数据,规模大到一定程度就无法在单机上存储,而且单机训练的时间开销也是难以接受的,这时就需要在一个集群上进行训练,这也是大规模AI训练的必经之路——分布式机器学习。
什么是分布式机器学习?
分布式机器学习使用计算机集群对训练任务进行并行计算,从而摆脱单机的存储和计算上的限制,加速训练任务的完成。从训练流程上来看,分布式与单机都是迭代式的,但不同的是,分布式在每轮迭代中需要进行任务的划分、节点并行计算、结果的聚合等步骤,然后继续下一轮迭代。
大规模AI训练的主要难题就在于“大”,参数规模大,数据集大,无法单机存储,计算时间太长。因此,将任务按照数据或者模型进行划分,并行执行以加速整体训练,成为两种基础的任务划分方式或者说并行模式。

| 数据并行(左)和模型并行(右)示意
数据并行是指训练集群中的机器使用不同的数据进行并行计算,数据的划分可以是直接划分也可以是随机采样。
模型并行则是将不同的模型参数划分到不同的机器上,根据模型结构的依赖关系进行计算和通信。
在分布式机器学习中,网络能做什么?
相比单机的学习,分布式机器学习涉及多个计算节点的协作,网络通信既是差别所在也是最为关键。值得一提的是,随着AI训练中最开始使用的通用计算CPU被更为专业快速的GPU、TPU取代,端侧的计算能力越来越强,这进一步加剧了网络通信的瓶颈问题,更随着大规模AI的爆火,网络通信方面的优化已经刻不容缓。
网络通信在分布式机器学习中的作用具体涉及哪些方面呢?又该如何去优化?
首先是逻辑通信拓扑,在AI模型训练的每轮迭代中,各个计算节点完成自己的计算任务后,需要通过某种逻辑通信拓扑进行结果的聚合,完成一轮次的学习。根据计算节点的功能逻辑是否相似,可以划分为两类:
去中心化:在去中心化的拓扑中,各个计算节点的工作逻辑大致相同,完成计算后会通过某种分布式机制或协议完成节点间计算结果的同步和聚合,拓扑的形状也是各异的,有环状、树状、星形等等。典型的例子为Ring Allreduce架构。
中心化:在中心化的拓扑中,计算节点存在功能角色的差异。一部分是工作节点,主要负责计算;另一部分是中心节点(或者服务器节点),负责模型全局更新聚合、下发最新参数等管理职责。拓扑一般是中心节点和工作节点相连,工作节点间不相连而互不干扰。典型例子为参数服务器架构(Parameter Server)。
| 去中心化拓扑(左)和中心化拓扑(右)
相较而言,去中心化的拓扑能够更充分利用带宽,但存在可扩展性不高的问题。中心化的拓扑扩展性较好,但是随着规模上升,中心节点反而成为通信瓶颈。因此,需要根据模型训练任务和计算集群的特性对拓扑进行选择和搭配。
除了通信拓扑,通信步调也是制约分布式机器学习整体性能的关键。通信步调关乎每轮迭代后模型全局更新的方式,分为异步和同步两种基本方式:
同步:每轮迭代中,当所有节点完成计算后,才能完成一次全局的模型更新。
异步:每轮迭代中,先完成计算的节点不必等待未完成的节点,而是上传模型更新,并直接开始下一轮的迭代。
同步方式的优势在于逻辑简单、理论性能有保障,但是在节点性能有较大差异的情况下会导致集群资源闲置,可扩展性不高。异步方式的优势在于能够更好地利用集群计算资源,扩展性强,但是由于参数不同步会影响模型的收敛速度,理论上性能保障较差。两种基本方式都有一定的局限性,因此也有一些改进的算法被提出,比如延迟同步并行算法SSP假设一个相对同质化的集群,刚开始采用异步的方式,但是会控制迭代次数的极差不超过预设阈值,如果超过阈值则进行等待或丢弃等处理。
以上是分布式机器学习领域中有关网络部分的经典问题,而近几年随着网络领域在软硬件方面的发展,对于分布式机器学习的优化加速,也有一些令人眼前一亮的方向和应用成果。
在减少通信的处理延迟的方面,学术界和产业界聚焦于高性能通信库和通信协议。高性能通信库的代表是NCCL,它是NVIDIA为了更好地支持多GPU的使用、提高集群通信效率而提出的,包括单机多卡和多机多卡的使用场景。NCCL实现了很多用于GPU之间进行并行协作计算的基本通信原语(Communication Primitives),并在实现上进行各种优化以达到高性能。比如下图所示的All-Reduce原语,是将多个节点上的数据进行加和,同步到每个节点,最终每个节点的数据都是原来数据的加和。这种操作在分布式机器学习中十分常见:每个节点的更新也需要总体进行加和平均,然后同步到每个节点。
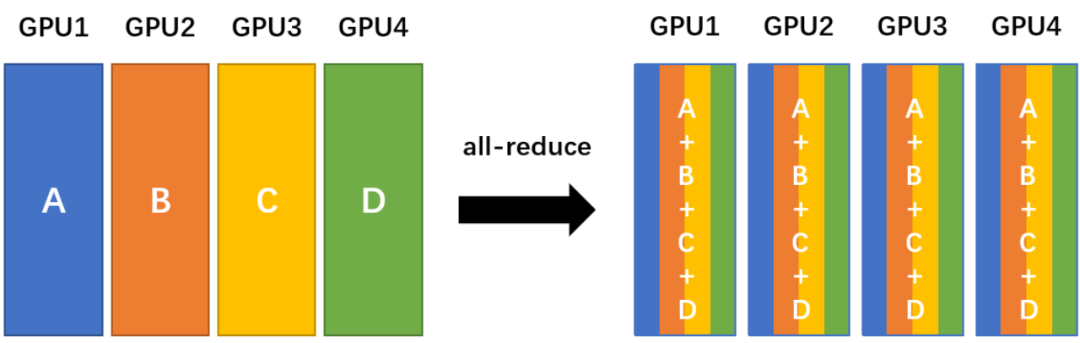
| All-Reduce过程示意图
对于网络通信协议,越来越多的理论分析和实践经验认识到,主机端网络通信相关的处理也占了很大一部分时延,于是针对协议栈处理和协议本身的优化也被应用在分布式机器学习领域。零拷贝、内核旁路、CPU卸载等优化思想被广泛地使用在各种通信技术当中:比如RDMA/RoCE/iWARP可以绕过远程主机内核直接存取访问内存,能够应用于多GPU之间的数据传输;协议栈卸载技术在硬件网卡上实现部分甚至全部的协议处理过程,解放了CPU资源,并且能够绕过内核直接与用户空间的应用交互数据,大大减少了主机侧的网络处理时延。
在减少传输的数据量方面,传统的方法是模型的分解压缩、参数的低精度量化等与模型和优化算法耦合的方法。而近年来一些工作利用新兴的可编程网络设备,在网络中内置处理函数,处理一些关键的通信步骤,能够从另一个维度减少数据传输量,从而降低整体的传输时延。比如barefoot、微软参与提出的SwitchML架构[3]以及清华团队提出的ATP架构[4],针对深度神经网络的分布式训练,通过在可编程设备上实现模型更新聚合并广播分发的步骤,大大减少了整体的数据传输量,实现了很好的加速效果。

| 网内聚合原理示意图
结语
当然,在大规模AI的实际训练过程中,往往需要综合考虑多个方面进行系统性的设计,比如在设计通信拓扑时需要考虑优化算法的性质、更新方式是异步还是同步,选择并行模式时要针对模型和数据的特性进行切分等等。以上所列举的方向和技术方法并没有面面俱到,只是抛砖引玉。相信随着大规模AI的火热,分布式机器学习技术会得到更进一步的发展,而网络作为分布式的关键,也将在软件和硬件等方面迎来进一步的发展空间。
参考:
[1] https://m.thepaper.cn/baijiahao_20908780
[2] https://m6.aliyun.com/
[3]https://www.usenix.org/conference/nsdi21/presentation/sapio
[4]https://www.usenix.org/conference/nsdi21/presentation/lao








