

计算机网络通信中两个重要的衡量指标是带宽和延迟,AI 网络也是如此。在向百亿级及以上规模的发展过程中,影响AI计算集群性能的关键并不只在于单个芯片的处理速度,每个芯片之间的通信速度也尤为重要。
目前GPU卡间互联的主要协议是PCIe和NVlink,服务器间互联则是RDMA和以太网。本文将主要介绍PCIe和NVLink两种互联技术。
PCIe :高带宽扩展总线
总线是服务器主板上不同硬件互相进行数据通信的管道,可以简单理解为生活中的各种交通道路。总线对硬件间数据传输速度起着决定性的作用,目前最流行的总线协议为PCIe(PCI-Express),最早由Intel于2001年提出。

PCle主要用于连接CPU与各类高速外围设备,如GPU、SSD、网卡、显卡等。与传统的PCI总线相比,PCIe采用点对点连接方式,具有更高的性能和可扩展性。伴随着AI、自动驾驶、AR/VR等应用快速发展,计算要求愈来愈高,处理器I/O带宽的需求每三年实现翻番,PCIe也大致按照3年一代的速度更新演进,每一代升级几乎能够实现传输速率的翻倍,并有着良好的向后兼容性。
2003 年PCIe 1.0 正式发布,可支持每通道传输速率为 250MB/s,总传输速率为 2.5 GT/s。
2007 年推出PCIe 2.0 规范。在 PCIe 1.0 的基础上将总传输速率提高了一倍,达到 5 GT/s,每通道传输速率从 250 MB/s 上升至 500 MB/s。
2022 年 PCIe 6.0 规范正式发布,总带宽提高至 64 GT/s。
2022年6月,PCI-SIG联盟宣布PCIe 7.0版规范,单条通道(x1)单向可实现128GT/s传输速率,计划于2025年推出最终版本。
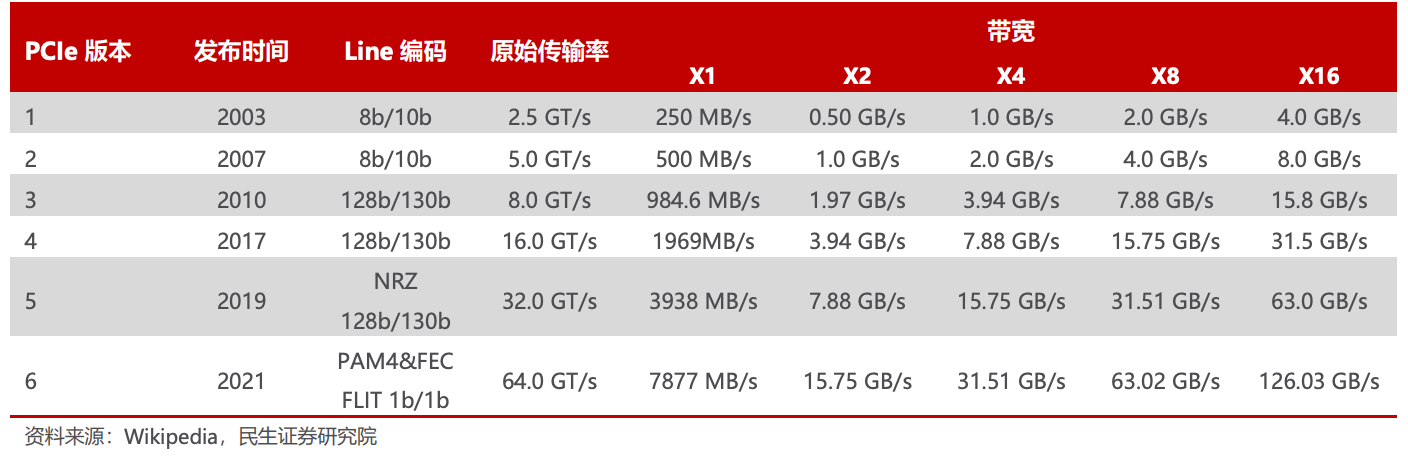
PCIe 1.0 到 6.0 不同 Lane 下的带宽变化
Retimer
在PCIe标准的迭代过程中,随着通信速率的逐步提高,信号质量也会���受到影响,为应对愈演愈烈的信号衰减问题,PCIe从4.0时期开始引入信号调理芯片:
PCIe Retimer:Retimer是一种数模信号混合芯片,功能主要为重新生成信号。Retimer 先恢复抖动的时钟信号,再生成新信号并重新发送,从而有效解决信号衰减问题,为服务器、存储设备及硬件加速器等应用场景提供可扩展的高性能PCIe互联解决方案。
PCIe Redriver:Redriver是一种信号放大器,通过发射端的驱动器和接收端的滤波器提升信号强度,从而实现对信号损耗的补偿。
从工作原理来看,Redriver通过放大信号来恢复数据,而Retimer 则重新建立一个传输信号的新副本。与 Redriver 相比,Retimer 恢复信号的效果更好,能够实现比Redriver更优的降低信道损耗效果,但由于增加了数据处理过程,时延有所增加。
PCIe Switch:PCIe 的链路通信是一种端对端的数据传输,每一条PCIe链路两端只能各连接一个设备,在需要高速数据传输和大量设备连接的场景中连接数量和速度受限。因此需要PCIe Switch提供扩展或聚合能力,从而允许更多的设备连接到一个 PCle 端口,以解决 PCIe 通道数量不够的问题。
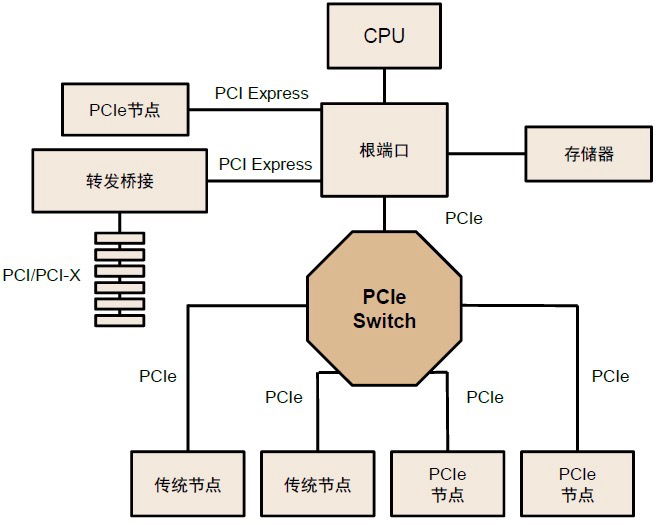
PCIe Switch连接多条PCIe总线
PCIe Switch兼具连接、交换功能,具有低功耗、低延迟、高可靠性、高灵活性等优势,能够将多条PCIe总线连接在一起,形成一个高速的PCIe互联网络,从而实现多设备通信。从PCIe Switch内部结构看,其由多个PCI-PCI桥接构成,实现从单条线到多条线的发散。PCIe Switch 芯片与其设备的通信协议都是 PCIe。
NVLink:高速 GPU 互连
算力的提升不仅依靠单张GPU卡的性能提升,往往还需要多GPU卡组合。在多GPU系统内部,GPU间通信的带宽通常在数百GB/s以上,PCIe总线的数据传输速率容易成为瓶颈,且PCIe链路接口的串并转换会产生较大延时,影响GPU并行计算的效率和性能。
GPU发出的信号需要先传递到PCIe Switch, PCIe Switch中涉及到数据的处理,CPU会对数据进行分发调度,这些都会引入额外的网络延迟,限制了系统性能。

为此,NVIDIA推出了能够提升GPU通信性能的技术——GPUDirect P2P技术,使GPU可以通过PCI Express直接访问目标GPU的显存,避免了通过拷贝到CPU host memory作为中转,大大降低了数据交换的延迟,但受限于PCI Express总线协议以及拓扑结构的一些限制,无法做到更高的带宽。此后,NVIDIA提出了NVLink总线协议。
NVLink的演进
NVLink 是一种高速互连技术,旨在加快 CPU 与 GPU、GPU 与 GPU 之间的数据传输速度,提高系统性能。NVLink通过GPU之间的直接互联,可扩展服务器内的多GPU I/O,相较于传统PCIe总线可提供更高效、低延迟的互联解决方案。
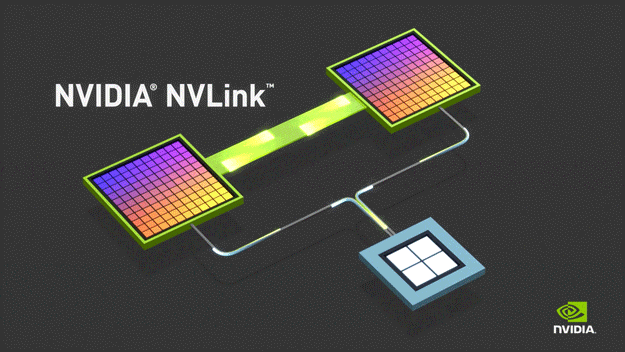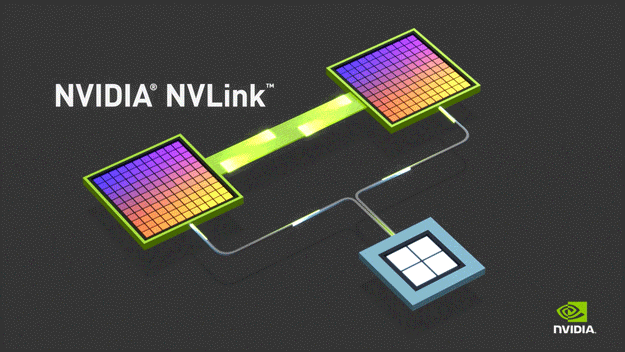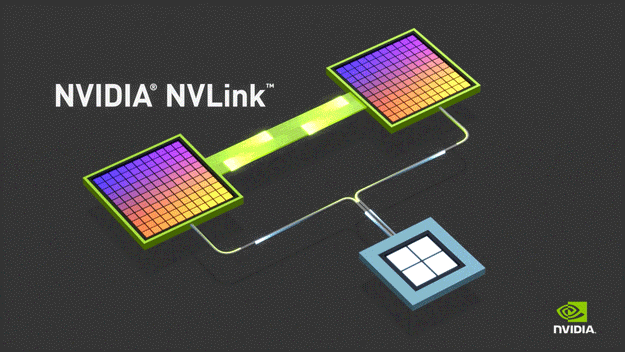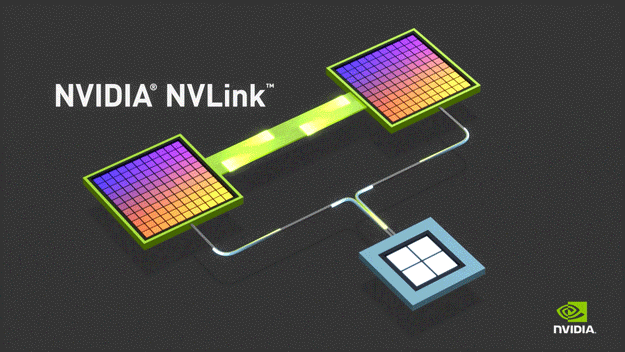
NVLink的首个版本于2014年发布,首次引入了高速GPU互连。2016年发布的P100搭载了第一代NVLink,提供 160GB/s 的带宽,相当于当时 PCIe 3.0 x16 带宽的 5 倍。V100搭载的NVLink2将带宽提升到300GB/s ,A100搭载了NVLink3带宽为600GB/s。目前NVLink已迭代至第四代,可为多GPU系统配置提供高于以往1.5倍的带宽以及更强的可扩展性,H100中包含18条第四代NVLink链路,总带宽达到900 GB/s,是PCIe 5.0带宽的7倍。

四代 NVLink 对比
目前已知的NVLink分两种,一种是桥接器的形式实现NVLink高速互联技术,另一种是在主板上集成了NVLink接口。

NVSwitch
为了解决GPU之间通讯不均衡问题,NVIDIA引入NVSwitch。NVSwitch芯片是一种类似交换机ASIC的物理芯片,通过NVLink接口可以将多个GPU高速互联到一起,可创建无缝、高带宽的多节点GPU集群,实现所有GPU在一个具有全带宽连接的集群中协同工作,从而提升服务器内部多个GPU之间的通讯效率和带宽。NVLink和NVSwitch的结合使NVIDIA得以高效地将AI性能扩展到多个GPU。
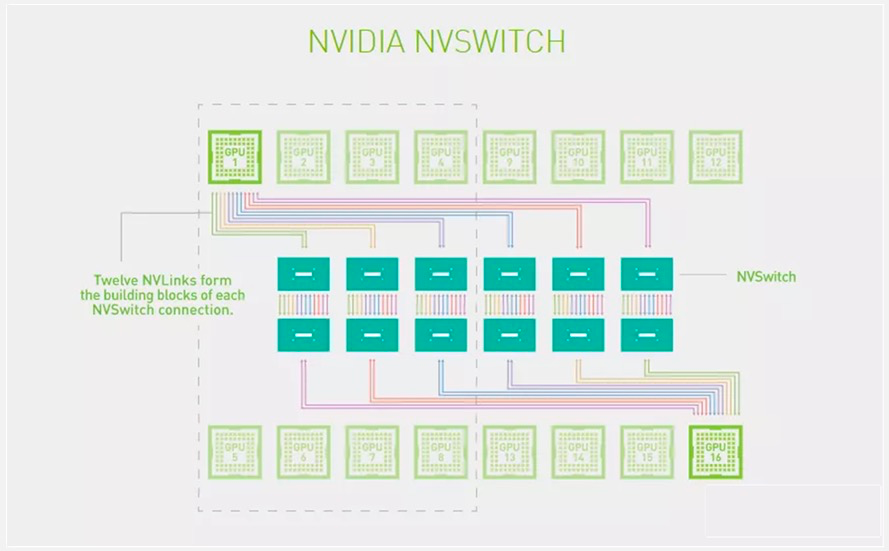
NVSwitch 拓扑图
第一代 NVSwitch于2018年发布,采用台积电 12nmFinFET 工艺制造,共有 18 个 NVLink 2.0 接口。目前 NVSwitch 已经迭代至第三代。第三代 NVSwitch 采用 TSMC 4N 工艺构建,每个 NVSwitch 芯片上拥有 64 个 NVLink 4.0 端口,GPU 间通信速率可达 900GB/s。

三代 NVSwitch 性能对比
2023 年 5 月 29 日,NVIDIA推出的DGX GH200 AI超级计算机,采用NVLink以及 NVLink Switch System 将256个GH200 超级芯片相连,把所有GPU作为一个整体协同运行。DGX GH200 是第一台突破 NVLink 上 GPU 可访问内存 100 TB 障碍的超级计算机。
AI时代下的网络互联
在逐步迈向AI时代网络互联的过程中,该选择PCIe还是NVLink?我们可以先看下NVIDIA 的NVLink版(SXM版)与PCIe版GPU的区别。
SXM架构是一种高带宽插座式解决方案,用于将 GPU连接到NVIDIA 专有的 DGX 和 HGX 系统。SXM 版GPU通过 NVSwitch 芯片互联,GPU 之间交换数据采用NVLink,未阉割的A100是600GB/s、H100是900GB/s,阉割过的A800、H800为400GB/s。PCIe版只有成对的 GPU 通过 NVLink Bridge 连接,通过 PCIe 通道进行数据通信。最新的PCIe只有128GB/s。
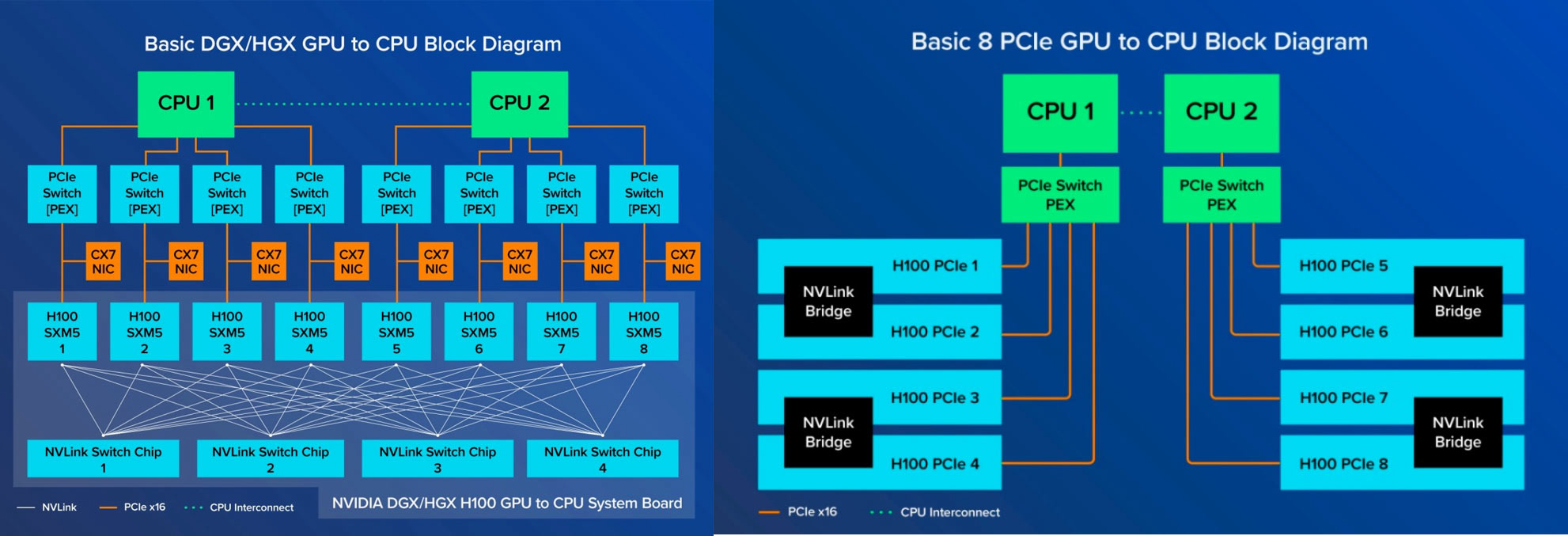
AI /HPC的计算需求不断增长,因此越来越需要在 GPU 之间提供更大的互联带宽。总的来说,NVLink的传输速度与时延都要优于PCIe,PCIe的带宽已逐渐无法满足AI时代数据互联的需求。但PCIe作为通用标准的互联技术,可广泛应用于各种场景,而NVLink为NVIDIA专有,是NVIDIA AI帝国的护城河,其他企业只能采用PCIe或者别的互联协议。
像谷歌是通过自研的OCS(Optical Circuit Switch)技术实现TPU之间的互联,解决TPU的扩展性问题。谷歌还自研了一款光路开关芯片Palomar,通过该芯片可实现光互联拓扑的灵活配置。也就是说,TPU芯片之间的互联拓扑并非一成不变,可以根据机器学习的具体模型来改变拓扑,提升计算性能及可靠性。借助OCS技术,可以将4096个TPU v4组成一台超级计算机。
据称,目前国外AI芯片初创公司Enfabrica和国内某些企业正沿着PCIe/CXL Switch方向在努力,结合CXL协议规范和PCIe接口的通用性,打造CPU-CPU直连交换芯片和系统方案。近期,NVIDIA还对Enfabrica进行了投资。有分析师表示,Enfabrica完全具备作为NVIDIA竞争对手的潜力,未来NVIDIA可能会考虑收购这家初创公司。
市场发展瞬息万变,未来具体将如何演变不仅取决于技术创新,也取决于市场需求和行业合作。在这个不断演变的AI网络互联时代,企业如何抉择将取决于自身对性能、成本、应用场景和未来发展趋势等多重因素的考量。
参考链接:
https://mp.weixin.qq.com/s/9G5SzKFTBqz8gT0ShMHbvw
民生证券电子行业专题研究:AI服务器元年,接口芯片核心受益
中金:AI大模型推动大算力,通信传输再升级








