

二十年前,英特尔开创了PCIe(PCI Express)技术,但存储成本不断增加、数据爆炸式增长、计算和带宽开始失衡,PCIe逐渐乏力。2019年,英特尔又提出一种开放性互联协议——Compute Express Link(CXL),能够让CPU与GPU、FPGA或其他加速器之间实现高速高效的互联,从而满足高性能异构计算的要求。
在异构计算大行其道的当下,CXL标准被提出之后,迅速成为服务器市场热捧的发展趋势之一。
为什么需要新型互连?
数据的爆炸式增长促使计算行业开始突破性的架构转变,从根本上改变数据中心的性能、效率和成本。为了继续提高性能,服务器正越来越多地转向异构计算架构。在特定任务中,专用ASIC可以使用更少的晶体管提供超过10倍的性能。
服务器内的芯片连接通常是用 PCIe 完成的,该标准最大的缺点是缺乏高速缓存一致性和内存一致性。从性能和软件的角度来看,使用 PCIe,不同设备之间通信的开销相对较高。此外,连接多台服务器通常意味着使用以太网或InfiniBand,这些通信方法存在着相同的问题,具有高延迟和低带宽。
2010 年代中期,CCIX协议成为了潜在的行业标准,得到了AMD、Xilinx、华为、Arm 和 Ampere Computing 的支持,但它缺乏足够的行业支持,并未发展起来。
2018 年,IBM 和 Nvidia 带来了解决PCIe与NVLink缺陷的解决方案,应用在当时世界上最快的超级计算机Summit上。AMD在Frontier超级计算机中也有类似的专有解决方案,名为Infinity Fabric。但可以预想到,没有任何的行业生态系统可以围绕这些专有协议而发展。
之后,英特尔制定了自己的标准,并于 2019 年将其专有规范作为CXL1.0 捐赠给了新成立的 CXL 联盟。该标准得到了半导体行业大多数买家的支持。

基于业界大多数参与者的支持,CXL 使向异构计算的过渡成为可能。
CXL 简介:什么是 Compute Express Link?
CXL是一种开放式行业标准互连,可在主机处理器与加速器、内存缓冲区和智能 I/O 设备等设备之间提供高带宽、低延迟连接,从而满足高性能异构计算的要求,并且其维护CPU内存空间和连接设备内存之间的一致性。CXL优势主要体现在极高兼容性和内存一致性两方面上。
CXL 联盟已经确定了将采用新互连的三类主要设备:
类型 1 设备:智能网卡等加速器通常缺少本地内存。通过 CXL,这些设备可以与主机处理器的 DDR 内存进行通信。
类型 2 设备:GPU、ASIC 和 FPGA 都配备了 DDR 或 HBM 内存,并且可以使用 CXL 使主机处理器的内存在本地可供加速器使用,并使加速器的内存在本地可供 CPU 使用。它们还位于同一个缓存一致域中,有助于提升异构工作负载。
类型 3 设备:可以通过 CXL 连接内存设备,为主机处理器提供额外的带宽和容量。内存的类型独立于主机的主内存。
CXL 协议和标准
CXL 标准通过三种协议支持各种用例:CXL.io、CXL.cache 和 CXL.memory。
CXL.io:该协议在功能上等同于 PCIe 协议,利用了 PCIe 的广泛行业采用和熟悉度。作为基础通信协议,CXL.io 用途广泛。
CXL.cache:该协议专为更具体的应用程序而设计,使加速器能够有效地访问和缓存主机内存以优化性能。
CXL.memory:该协议使主机(例如处理器)能够使用load/store命令访问设备附加的内存。
这三个协议共同促进了计算设备(例如 CPU 主机和 AI 加速器)之间内存资源的一致共享。从本质上讲,通过共享内存实现通信简化了编程。用于设备和主机互连的协议如下:
- 类型 1 设备:CXL.io + CXL.cache
- 类型 2 设备:CXL.io + CXL.cache + CXL.memory
- 类型 3 设备:CXL.io + CXL.memory
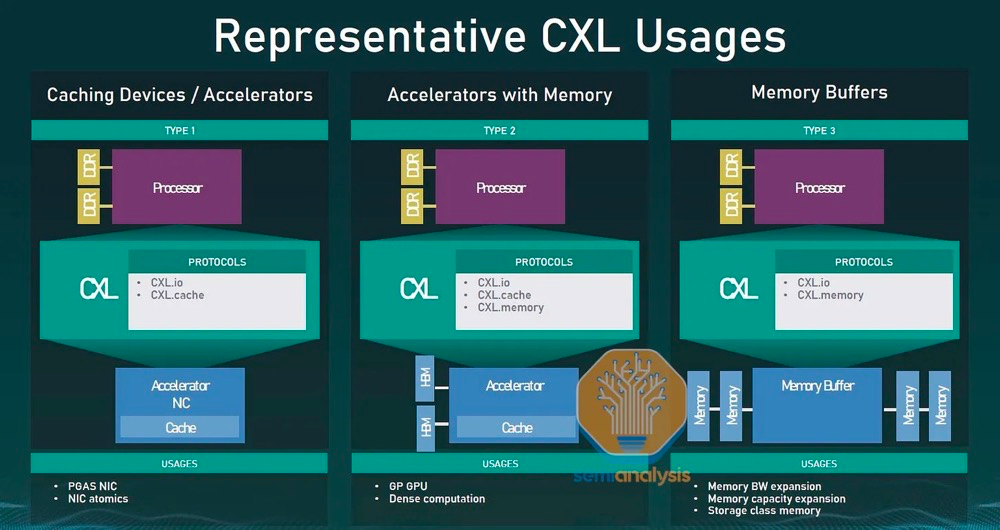
| 代表的CXL用例
CXL 的特点和优势
前面我们主要讨论的是异构计算,CXL 还可以有效解决内存墙和IO墙的瓶颈。
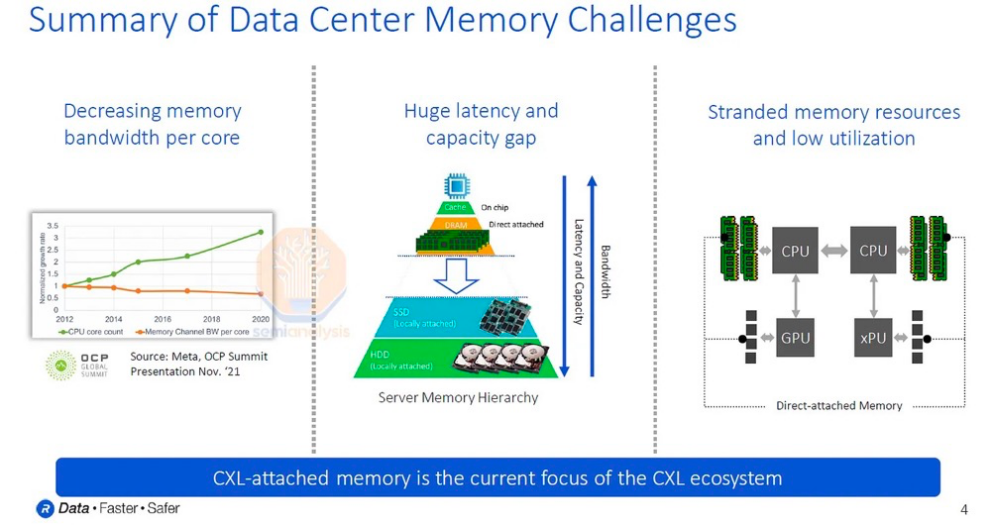
数据中心存在着严重的内存问题。自 2012 年以来,核心数量迅速增长,但每个核心的内存带宽和容量并没有相应增加,内存带宽反而有所下降,并且这种趋势还在持续。此外,直连 DRAM 和 SSD 之间在延迟和成本方面存在巨大差距。
最后还有一个致命的问题,昂贵的内存资源往往利用率很低。对于资本密集型行业来说,低利用率是一个重大问题,而数据中心业务是世界上资本密集程度最高的行业之一。
微软表示,服务器总成本的 50% 来自 DRAM,成本巨大。尽管如此,还有高达25% 的 DRAM 内存被闲置了!简单来说,微软 Azure 的服务器总成本中有 12.5% 是闲置的。
想象一下,如果这个内存可以驻留在连接的网络上并跨多个 CPU 和服务器动态分配给 VM。内存带宽可以根据工作负载的需求增加或减少,这将大大提高利用率。

总的来说,CXL 的内存缓存一致性允许在 CPU 和加速器之间共享内存资源。CXL 还支持部署新的内存层,可以弥合主内存和 SSD 存储之间的延迟差距。这些新的内存层将增加带宽、容量、提高效率并降低TCO (总拥有成本)。此外,CXL 内存扩展功能可在当今服务器中的直连 DIMM 插槽之上实现额外的容量和带宽。
通过 CXL 连接设备可以向 CPU 主机处理器添加更多内存。当与持久内存配对时,低延迟 CXL 链路允许 CPU 主机将此额外内存与 DRAM 内存结合使用。大容量工作负载的性能取决于大内存容量,例如 AI。而这些是大多数企业和数据中心运营商正在投资的工作负载类型,因此,CXL 的优势显而易见。
CXL与 PCIe:这两者有什么关系?
CXL 建立在PCIe的物理和电气接口之上,通过协议建立了一致性、简化了软件堆栈,并保持与现有标准的兼容性。具体来说,CXL 利用 PCIe 5 特性,允许备用协议使用物理 PCIe 层。
CXL引入了Flex Bus端口,可以灵活的根据链路层协商决定是采用PCIe协议还是CXL协议。CXL具有较高的兼容性,更容易被现有支持PCIe端口的处理器(绝大部分的通用CPU、GPU 和 FPGA)所接纳,因此,英特尔将CXL视为在PCIe物理层之上运行的一种可选协议,并且英特尔还计划在第六代PCIe标准上大力推进CXL的采用。
当支持 CXL 的加速器插入 x16 插槽时,设备以默认的PCIe 1.0传输速率(2.5 GT/s)与主机处理器端口协商。只有双方都支持 CXL,CXL 交易协议才会被激活。否则,它们将作为 PCIe 设备运行。
CXL 1.1 和 2.0 使用 PCIe 5.0 物理层,允许通过 16 通道链路在每个方向上以 32 GT/s 或高达 64 GB/s 的速度传输数据。
CXL 3.0 使用 PCIe 6.0 物理层将数据传输扩展到 64 GT/s,支持通过 x16 链路进行高达 128 GB/s 的双向通信。
CXL 2.0 和 3.0 有什么新功能?
作为一项新兴技术,CXL发展非常迅速,过去几年时间CXL已经发布了1.0/1.1、2.0、3.0三个不同的版本,并且有着非常清晰的技术发展路线图。
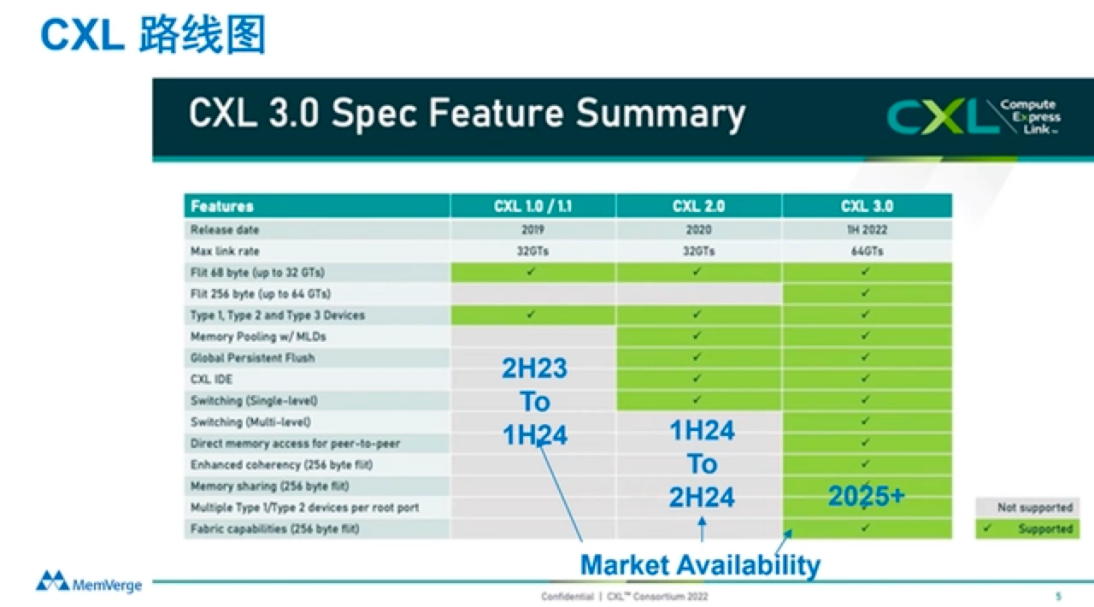
CXL 3.0是2022年8月份发布的新标准,在许多方面都进行了较大的革新。CXL3.0建立在PCI-Express 6.0之上(CXL1.0/1.1和2.0版本建立在PCIe5.0之上),其带宽提升了两倍,并且其将一些复杂的标准设计简单化,确保了易用性。
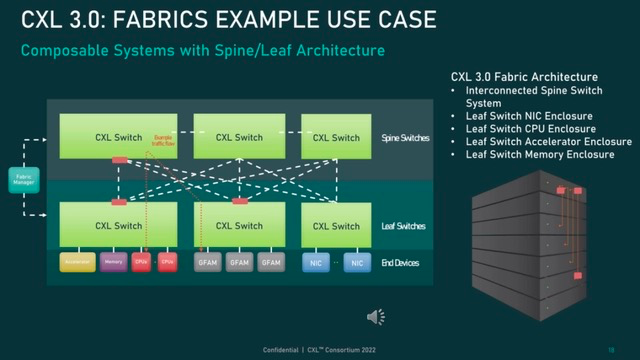
内存池
CXL 2.0 支持切换以启用内存池。使用 CXL 2.0 交换机,主机可以访问池中的一个或多个设备。主机必须支持 CXL 2.0 才能利用此功能,但内存设备可以是支持 CXL 1.0、1.1 和 2.0 的硬件的组合。在 1.0/1.1 中,设备被限制为一次只能由一台主机访问的单个逻辑设备。然而,一个 2.0 级别的设备可以被划分为多个逻辑设备,允许多达 16 台主机同时访问内存的不同部分。
例如,主机 1 (H1) 可以使用设备 1 (D1) 中一半的内存和设备 2 (D2) 中四分之一的内存,以将其工作负载的内存需求与内存池中的可用容量完美匹配。设备 D1 和 D2 中的剩余容量可由一台或多台其他主机使用,最多可达 16 台。设备 D3 和 D4 分别启用了 CXL 1.0 和 1.1,一次只能由一台主机使用。

| 直连的CXL内存池
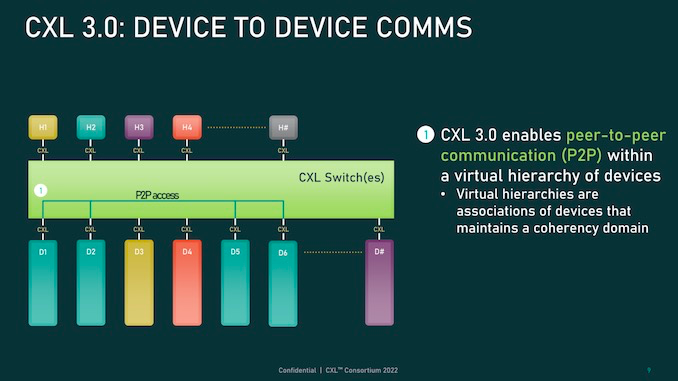
CXL 3.0 引入了点对点的直接内存访问和对内存池的增强,其中多个主机可以在CXL 3.0设备上一致地共享内存空间。这些特性支持新的使用模型并提高数据中心架构的灵活性。
Switching
通过转向 CXL 2.0 直连架构,数据中心可以获得主内存扩展的性能优势,以及池内存的效率和TCO 优势。假设所有主机和设备都支持 CXL 2.0,那么“switching”将通过 CXL 内存池芯片中的交叉开关集成到内存设备中,这样可以保持较低的延迟。通过低延迟直接连接,附加的内存设备可以使用 DDR DRAM 来扩展主机主内存。
CXL 3.0 引入了多级交换,允许单个交换机驻留在主机和设备之间,并允许多级交换机实现多层级交换,对网络拓扑种类和复杂性有更好的支持。即便只有两层交换机,CXL 3.0也能够实现非树状拓扑,比如环形、网状或者其他结构,对节点中的主机或设备没有任何限制。

按需内存
与拼车类似,CXL 2.0 和 3.0 在“按需”的基础上为主机分配内存,从而提供更高的内存利用率和效率。该架构提供了为工作负载配置服务器主内存的选项,能够在需要时访问内存池以处理高容量工作负载。
CXL 内存池模型可以支持向服务器分解和可组合性的转变。在此范例中,可以按需组合离散的计算、内存和存储单元,以有效地满足任何工作负载的需求。
完整性和数据加密 (IDE)
分解或分离服务器架构的组件增加了攻击面,这也是为什么 CXL 包含了安全设计方法。具体来说,所有三个 CXL 协议都通过完整性和数据加密 (IDE) 来保护,IDE 提供机密性、完整性和重放保护。IDE 在 CXL 主机和设备芯片中实例化的硬件级安全协议引擎中实现,以满足 CXL 的高速数据速率要求,而不会增加额外的延迟。需要注意的是,CXL 芯片和系统本身需要防止篡改和网络攻击的保护措施。
信令扩展到 64 GT/s
CXL 3.0 对标准的数据速率进行了阶梯式的提高。如前所述,CXL 1.1 和 2.0 在其物理层使用 PCIe 5.0 电气:32 GT/s 的 NRZ 信号。使用 PAM4 信号将 CXL 3.0 数据速率提高到 64 GT/s。
CXL标准诞生并不久,据透露,支持 CXL 的英特尔、AMD 的新一代 CPU 正在部署中,预计将在今年下半年增加。这意味着 CXL 部署将在年底开始,并在 2024 年扩大规模。总的来说,CXL协议的出现解决了CPU和设备之间的数据传输问题,提高了应用程序的性能、降低延迟、提供更高的数据传输速率。随着不断发展和普及,CXL协议的将成为数据中心和高性能计算领域的一个重要趋势。






