在NSDI2022会议上,谷歌发布了数据中心分布式交换架构Aquila。
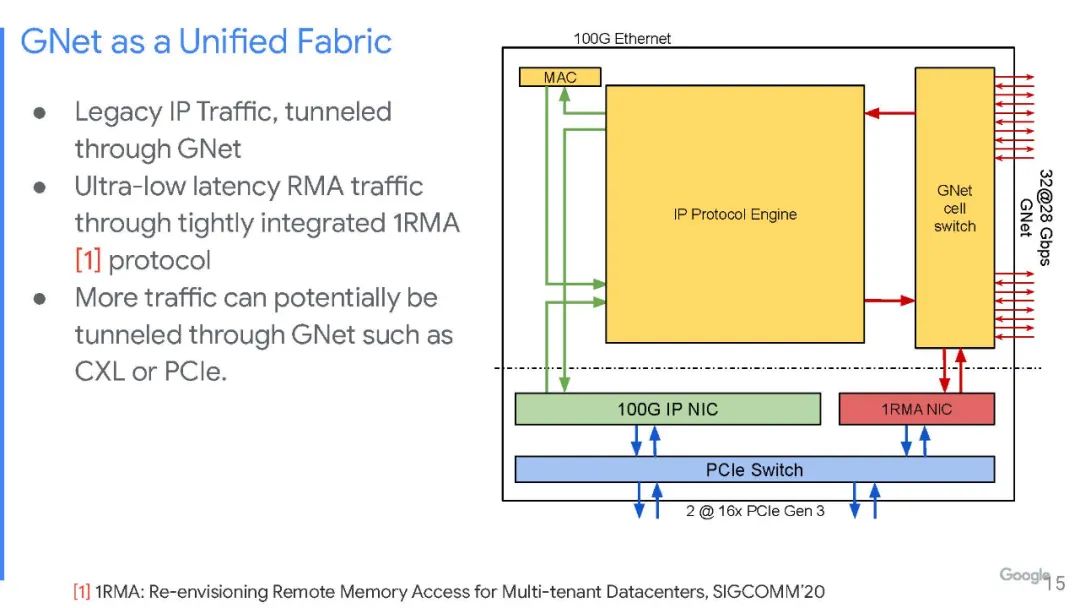
Aquila是一种实验性的数据中心网络架构,将超低延迟作为核心设计目标,同时也支持传统的数据中心业务。Aquila使用了一种新的二层基于单元的协议、GNet、一个集成交换机和一个定制的ASIC,ASIC和GNet一同设计,并具有低延迟远程存储访问(RMA)。
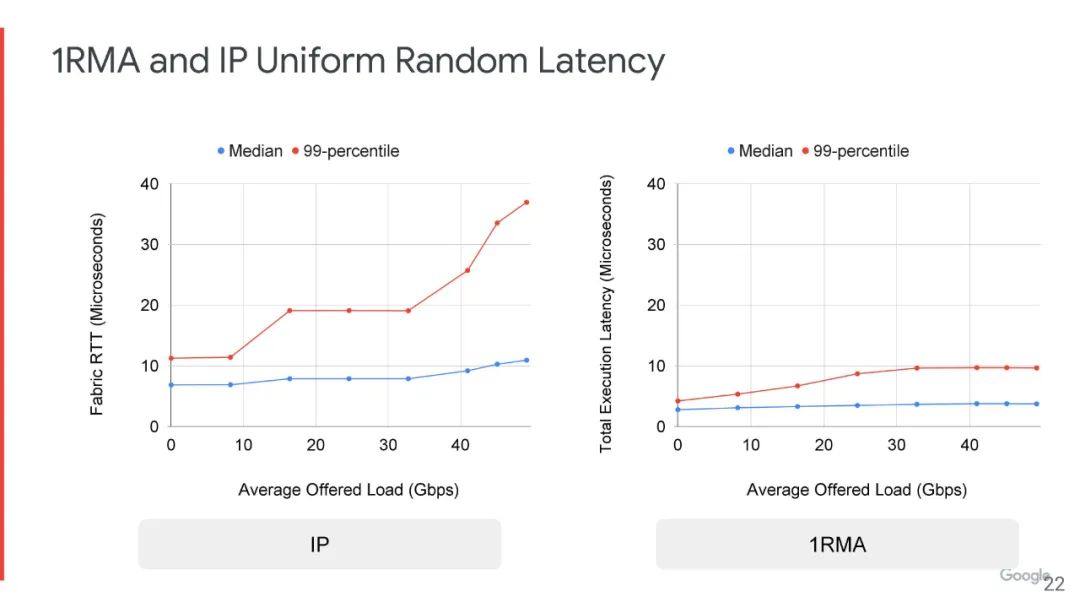
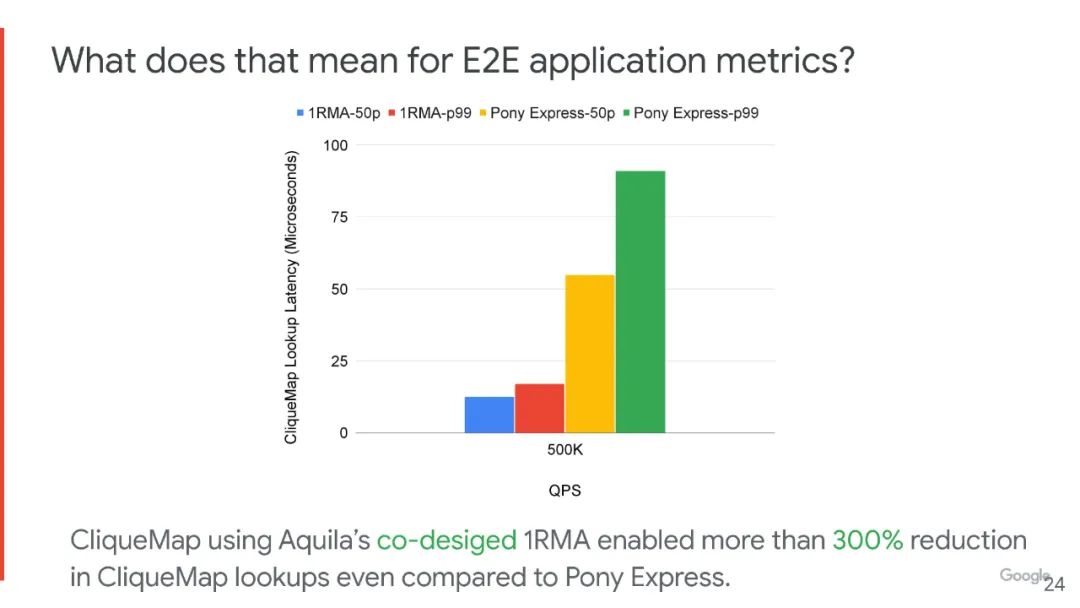
Aquila 能够实现 40 µs 以下的IP 流量拖尾结构往返时间 (RTT) 和低于 10 µs的跨数百台主机的 RMA 执行时间,甚至在存在面向吞吐量的后台 IP 流量的情况下。这意味着对于运行在Aquila原型网络上的产品质量键值存储,尾部延迟减少了 5 倍以上。
多年以来,谷歌的每一次重大发布都值得所有IT人思考学习。
- 2003 年的Google 文件系统(GFS,Google File System)。
- 2004 年的MapReduce分析平台。
- 2006 年的BigTable NoSQL 数据库。
- 2009 年的仓储级计算(Warehouse-scale computing)。
- 2012 年的Spanner分布式数据库。
- 2015 年的Borg集群控制器以及2016年的Omega scheduler插件。
- 2015 年的Jupiter数据中心Underlay 网络。
- 2017 年的Espresso边缘路由软件堆栈。
- 2018 年的Andromeda虚拟网络堆栈。
此次时隔数年的一篇长论文的到来,终于再次向世界展示了谷歌的技术实力。Aquila是一种低延迟的数据中心架构,它使用自定义交换机和接口逻辑以及一个称为 GNet 的自定义协议。与谷歌长期部署的基于以太网的、数据中心范围的 Clos 网络相比,Aquila提供了更低延迟、更可预测和显著降低的尾部延迟。
2012 年 4 月,英特尔从超级计算机制造商 Cray 购买了 Aries 互连,并计划将其部分技术与其 Omni-Path InfiniBand(2012年1月从QLogic收购)合并,但是最终并没有成功。
然而在近十年之后的现在,谷歌发布的Aquila架构借鉴了InfiniBand 和Aries互连的思想。
Aquila 数据中心架构有很多层,目前尚处于原型阶段,还不清楚它将如何与英特尔与谷歌共同设计的“Mount Evans”DPU进行交互和交互。
Aquila是拉丁词,意思是“鹰”,它不基于以太网、IP、TCP和UDP协议运行。
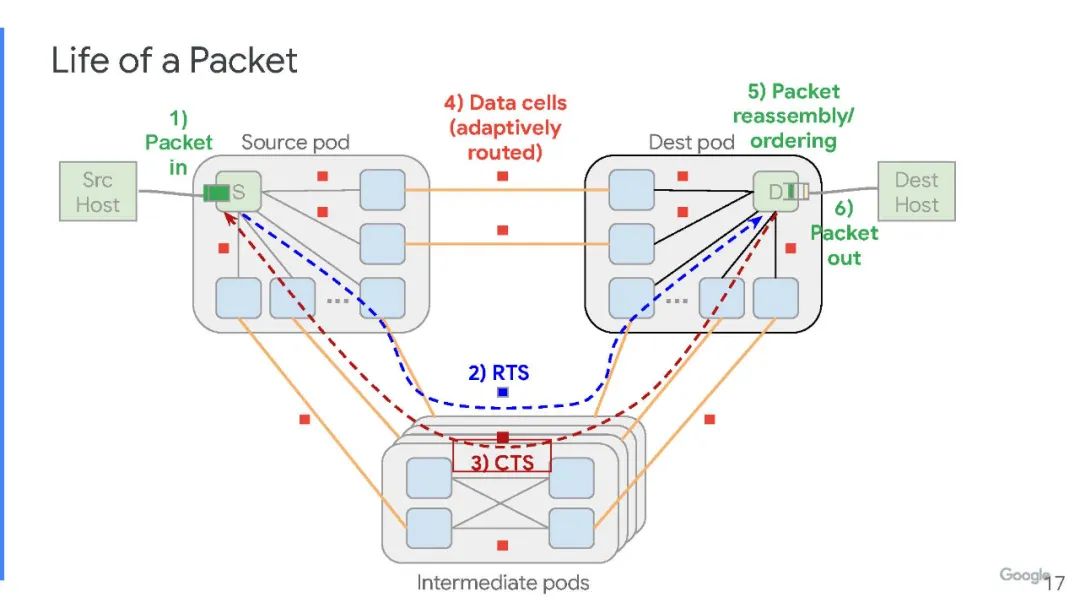
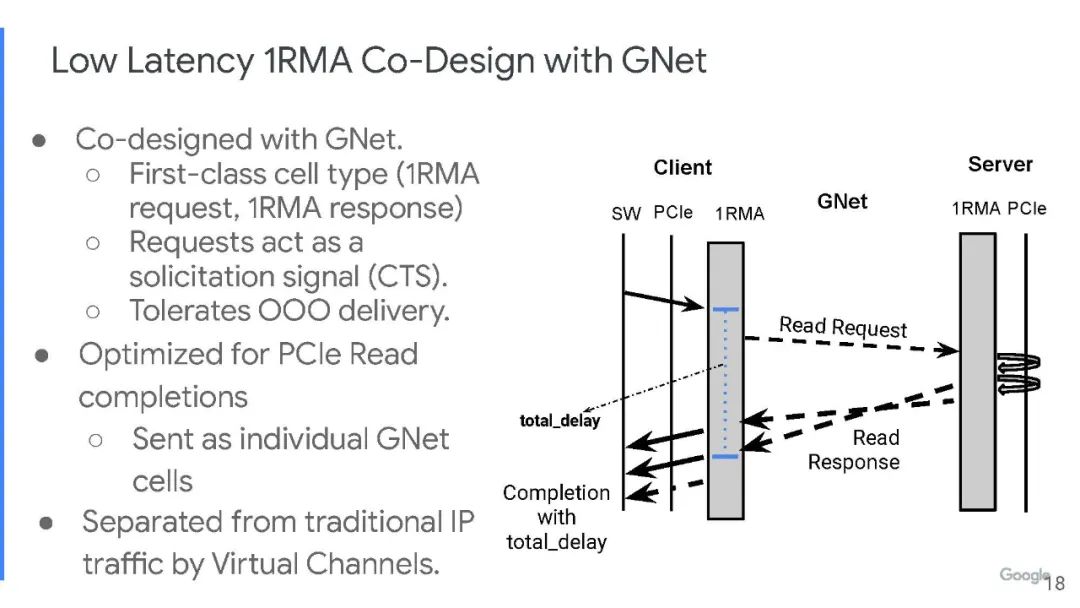
谷歌创建了基于单元的2层交换协议和相关的数据格式,而不是数据包。实际上,一个单元比一个数据包要小,这就是为什么谷歌可以通过Aquila架构在服务器节点之间获得更好的确定性性能和更低的延迟的原因之一。这种格式针对 RDMA 网络中常用的小数据单元进行了优化,并具有ToR交换机 ASIC 和NIC的聚合网络功能,可以实现在 Aquila 互连原型的 1,152 个节点范围以平均4微秒的时间内完成RMA读取。
我们先从Aquila的硬件开始看起。
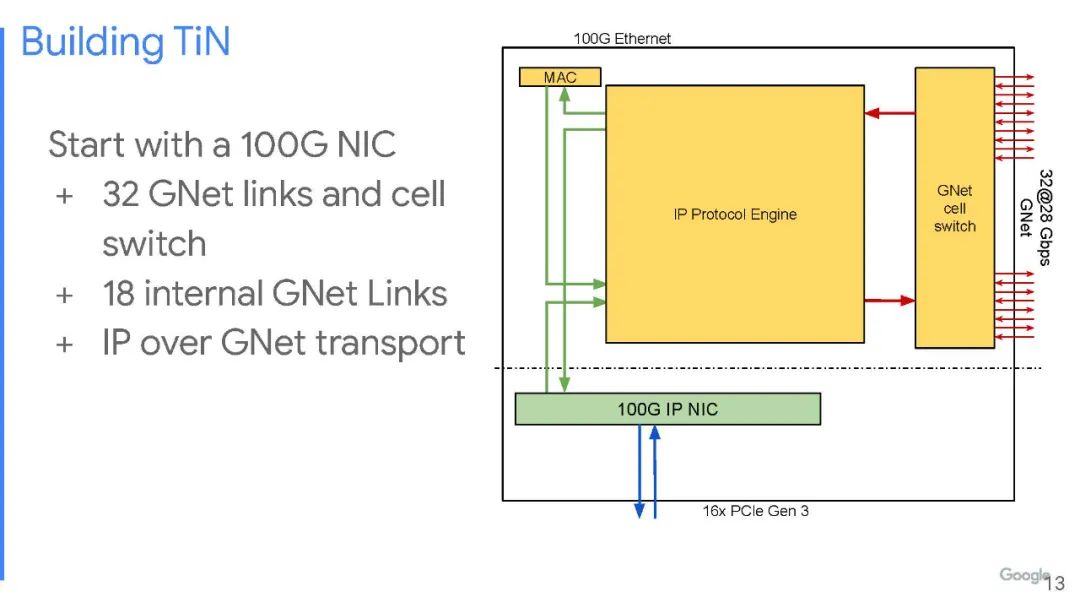
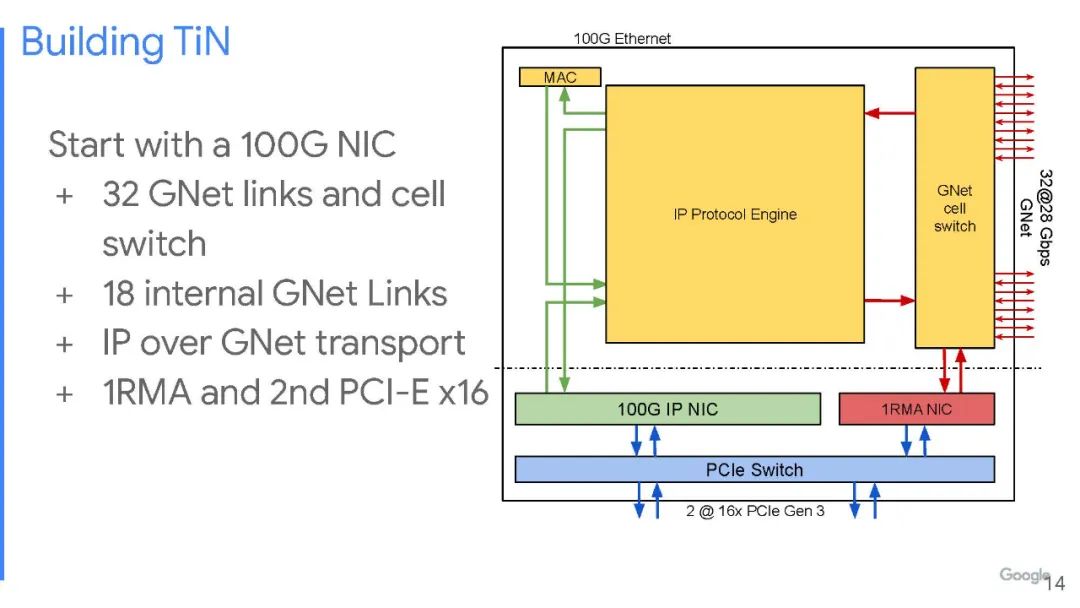
谷歌不想在这上面花太多钱。谷歌研究人员在论文中解释说:“为了让一个规模适中的团队继续进行硬件开发工作,我们选择在同一硅片中构建一个具有 NIC 和交换机功能的单芯片,我们的想法和出发点是,以适中的额外成本将中等基数的交换机集成到现有的 NIC 芯片中,并且由此产生的被称为ToR-in-NIC (TiN) 芯片的NIC/交换机组合可以通过 Pod 中的铜背板连接在一起。然后,服务器可以通过 PCIe 连接到 Pod 以实现其 NIC 功能。TiN 交换机将通过优化的第 2 层协议 GNet 提供与同一 Clique 中的其他服务器的连接,并通过标准以太网提供与其他 Clique 中的其他服务器的连接。”
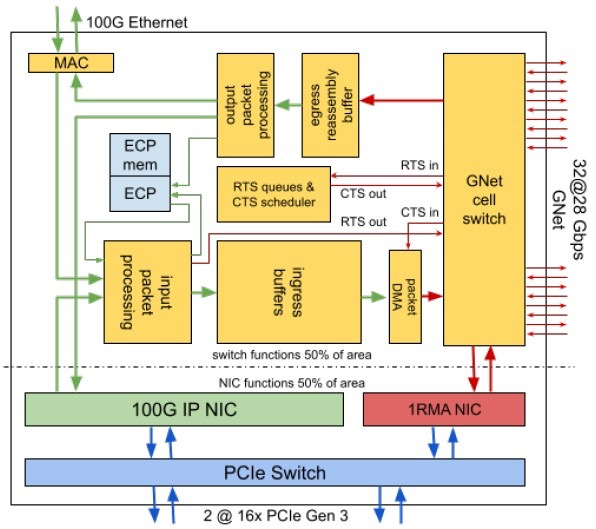
这个“torrinic”芯片上有很多东西。谷歌系统和服务基础设施团队工程研究员兼副总裁Amin Vahdat曾表示,SoC是新的主板,也是创新的焦点。每个 Aquila 芯片实际上都是一个复合体,其中两个 TiN 在同一个封装中。
如图所示,设备中有一对 PCI-Express 3.0 x16 插槽,允许将一个 256 Gb/s的胖管道(fat pipe)连接到单个服务器,或两个128 Gb/s的半胖管道(half-fat pipe)用于两台服务器。在这个 PCI-Express 交换机另一侧的是一对网络接口电路——一个是100 Gb/s IP ,通过芯片连接以太网,另一个是专有 1RMA 协议,连接到 GNet单元交换机。
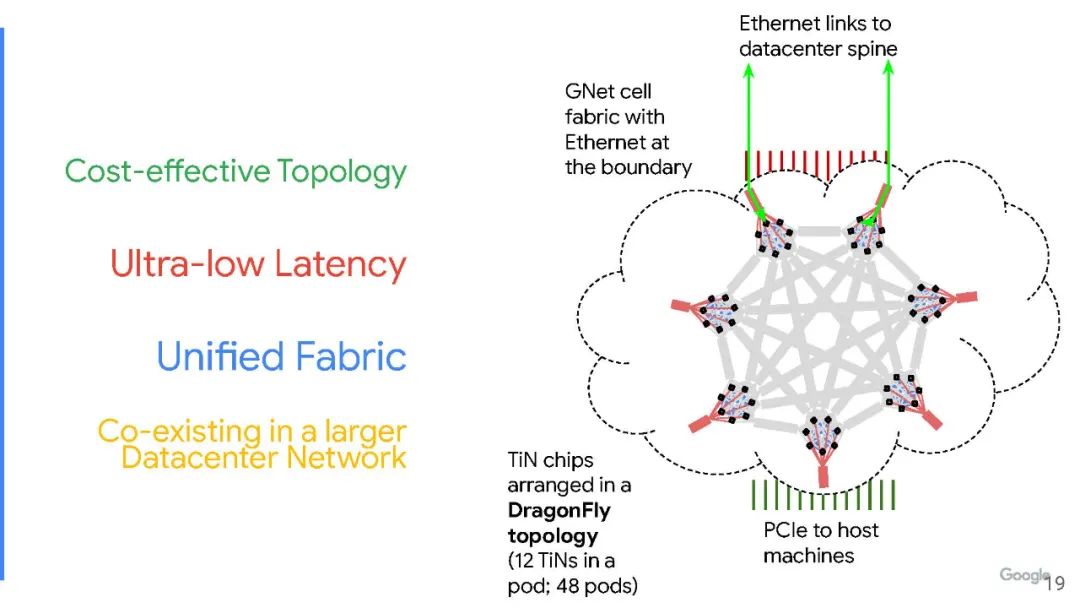
该单元交换机有 32 个端口,以 28 Gb/s的速度运行——正如谷歌说的那样,没有交换机那么多端口,也没有那么快。随着编码开销的减少,这些 GNet 单元交换通道以 25 Gb/s的速度运行,这与 IBM Power9 处理器上的“Bluelink”OpenCAPI 端口以及“Ampere”A100 GPU 和NVSwitch交换机的NVLink 3.0 通道运行速度相同。其中有24条通道用于通过铜线链路连接 pod 中的所有服务器节点,还有 8 条链路可使用光链路将多达 48 个 pod 互连到单个 GNet 结构中,称为“clique”。谷歌采用的 Dragonfly 拓扑结构限制服务器远程连接所需的光收发器和电缆数量。谷歌也为这些端口设计了自己的GNet光收发器。
Aquila TiN 具有输入和输出数据包处理引擎,如果来自单元交换机的数据需要离开 Aquila 架构并进入谷歌的以太网网络,则可以与 IP NIC 和以太网 MAC 连接。
谷歌表示,Aquila架构的单芯片设计旨在降低芯片开发成本,同时“简化库存管理”。这种融合网络架构的核心在于谷歌在其数据中心规模的 Clos 网络中嵌套了一个非常快速的Dragonfly 网络,该网络基于leaf/spine拓扑,不是all-to-all网络,能够以一种经济高效且可扩展的方式将所有东西互连。

光连接允许Aquila pod之间的距离达到100米,FEC(forward error correction)可减轻全局链路上的噪声,导致每跳延迟损失 30ns 和 6% 的带宽开销。
现在大多数交换机都内置了计算功能,谷歌表示,大多数交换机都有一个多核 64 位处理器,其主内存介于 8 GB 和 16 GB 之间。但是,通过使用外部 SDN 控制器并使用 Aquila 芯片封装上的本地计算作为每个 TiN 对的端点本地处理器,Aquila 封装可以使用32位单核 Cortex-M7 处理器和2 MB专用SRAM 来处理 SDN 堆栈的本地处理需求。运行 GNet 堆栈的外部服务器还没有公开。
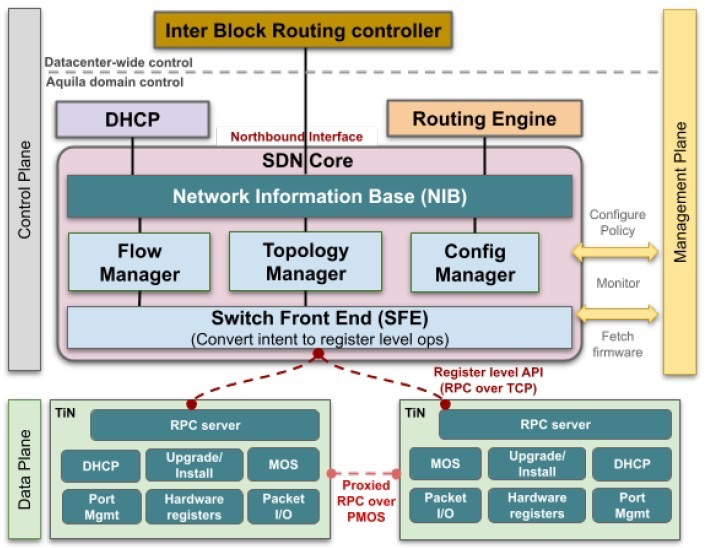
SDN 软件是用 C 和 C++ 编写的,由大约 10万行代码组成;Aquila 芯片运行 FreeRTOS 实时操作系统和 lwIP 库。该软件将所有低级 API 公开给 SDN 控制器,SDN控制器可以访问并直接操作设备的寄存器和其他元素。谷歌补充说,将 Aquila 的固件分发到控制器上,而不是设备上,TiN 设备可以启动 GNet 和以太网链接并尝试链接到网络上的 DHCP 服务器,并等待来自中央 Aquila SDN 控制器的进一步配置命令。
由于Aquila 网络是Dragonfly 拓扑,因此必须从一开始就配置网络中的所有节点,或者每次添加机器时都必须重新连接以获得网络的全部带宽. (这是all-to-all网络的缺点。)下图是服务器和网络的示意图:
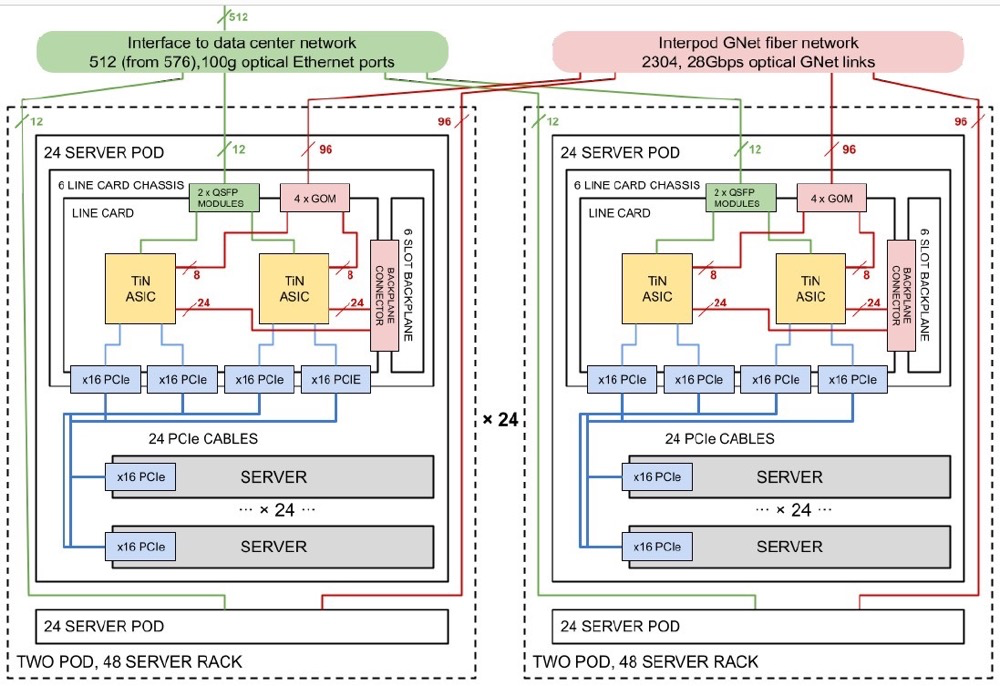
Aquila一个机架中有两个 24 个服务器的 Pod,在一个 clique 中有 24 个机架。谷歌使用的是其标准服务器机箱,其适配器卡上有 NIC,在这种情况下是一个 PCI 适配器卡,它链接到一个交换机机箱,该机箱的6个适配器卡上有12个 T1N ASIC。Dragonfly 网络的第一层是在机箱背板上实现的,从pod中伸出96条GNet光链路,将48个pod连接在一起,all-to-all,每个有两条路由。
使用多个ASIC 实现网络会伴随一定的副作用。如果两台服务器共享一个 T1N 并且 T1N 包有两个 ASIC,那么一个包的故障会导致四台服务器故障。如果一个由 48 台服务器组成的机架中,ToR交换机烧坏了,那么 48 台服务器就会停机。如果整个 Aquila 交换机机箱发生故障,只有 24 台机器被淘汰。
展望未来,谷歌正在研究在未来的 Aquila 设备中为 TiN 设备添加更多计算能力,以便它可以基于Linux,这将允许谷歌向网络添加更高级别的 P4 编程语言抽象层。
附:演讲ppt