

作者简介:朱龙隆,福州大学数计学院2018级计算机科学与技术(实验班)本科生,目前研究方向为网络测量,邮箱1614864145@qq.com
一、 背景
网络测量是SDN发展的基础,是优化网络结构、改善网络服务质量、实现网络故障诊断和恢复的重要手段。在SDN网络中, 网络管理员通过网络测量及时了解、监控、掌握网络状态,调整网络的性能参数,及时发现可能存在的DDOS攻击、网络入侵等状况。

基于Sketch的网络测量与SDN结合具有天然特性[1]。大量部署的SDN云数据中心拥有每秒成千上万的并发流,需要sketch提供海量流量下的高速网络测量;SDN控制器的全局视野有助于全网调度、策略制定,实时提供网络信息,有利于Sketch的应用实施;Sketch在较小内存下对重流(heavy flow)(如heavy hitter(大流)和heavy changer(突变流))的快速检测有助于SDN云数据中心的大量部署。
二、 Sketch介绍
什么是Sketch?Sketch是一种紧凑的用于流量数据统计亚线性数据结构。其使用哈希将数据映射到Sketch中,将大量网络流压缩至小部分的内存空间中,无需存储所有网络流,以达到节约内存的目的,并通过查询操作获得流量统计数据。
为什么要使用Sketch?网络流主要依据五元组分类,每流检测为每个网络流都分配一个计数器,保证了测量的零误差,但空间复杂度极高。抽样技术选取部分报文来推断网络流量总体的性能参数,减少了测量的数据量,但其数据的不完整性对测量结果的准确性造成了很大影响。数据流技术通过哈希的方法把庞大的数据映射到小的存储空间内,其中以基于Sketch的方法应用最广泛。Sketch将具有相同哈希值的流存入相同的桶内,可以在保证准确度的同时大大减少存储空间。
本文所介绍的MV-SKetch[2]可以在小内存下实现对重流的快速检测。通过对重流的检测,网络管理员可以实时掌握网络的状态、及时发现并应对可能出现的网络入侵等状况,此举大大提高了运营网络的鲁棒性。
三、 MV-Sketch概述
MV-Sketch是一种高效、紧凑、可逆的Sketch,使用较小静态内存空间即可实现重流检测。MV-Sketch主要利用MJTRY算法(主票选算法)[10],在Sketch中保留重流候选,只需较小的空间即可支持更新和查询操作,从而实现了小内存下的重流检测。同时,相较于动态分配流存储空间的方式,静态分配方式有助于降低内存管理开销,且可以利用SIMD加速MV-Sketch。
四、 现有问题与解决
1.现有问题1:传统的Sketch虽然高效但不可逆
传统的Sketch举例:
Count-Min_Sketch[4]:使用多个哈希函数,选取计数器的最小值来保证高准确率。
存在问题:传统的Sketch高效却不可逆,他们无法从本身中恢复所有重流,只能通过遍历所有流的方式查询是否存在重流,这样的方法将带来大量查询开销。
MV-Sketch的解决:MV-Sketch将重流候选保存于Sketch数据结构本身,从而保证了可逆性。
2.现有问题2:现有Sketch保证可逆但更新开销高
现有的可逆Sketch举例:
①带有额外数据结构的Sketch
Count-Min-Heap[3]:Count-Min-Heap通过在Count-Min上增加一个堆以记录重流。
LD-Sketch[5]:通过动态变化长度的数组记录重流的候选者,驱逐其他流,以达到节约存储空间的目的。
存在问题:由于依靠额外的数据结构来存储重流,更新时易导致高内存访问开销,且随着候选重流数目的增加而增加。此外,LD-Sketch动态分配流存储空间,增加了开销,且难以利用硬件实现。
②基于分组检测的Sketch
Deltoid [6]:将流关键字(一般是五元组或源目的IP)映射到计数器组的一个子集中,使用多个计数器来记录流。
Fast Sketch[7]:与Deltoid 相似,而它将流关键字的商映射到Sketch中。
存在问题:由于计数器的数量随着流关键字长度的增加而增加,Deltoid 和Fast Sketch都有很高的更新开销。
③结合枚举的Sketch
Reversible Sketch[8]:通过削减流关键字的枚举空间来查找重流。
SeqHash[9]:与Reversible Sketch设计类似,但它将不同长度的关键字前缀哈希到诸多较小的Sketch中。
存在问题:Reversible Sketch和SeqHash的更新成本随着流关键字的长度的增加而增加,也很容易导致过高内存占用。
现有可逆Sketch存在问题总结:现有的可逆Sketch:LD-Sketch、Fast Sketch、Reversible Sketch……,虽然通过各种方式来保存重流(如依靠额外的数据结构),但在实施更新操作时,易导致高内存访问开销,从而使性能大打折扣。
MV-Sketch的解决:MV-Sketch使用较小静态内存空间进行构建,限制了每个数据包更新的内存访问开销,避免更新时过高内存占用的风险,且与使用动态内存相比,减轻内存管理开销且可利用SIMD实现硬件加速。
五、 MV-Sketch 具体介绍
设计思路
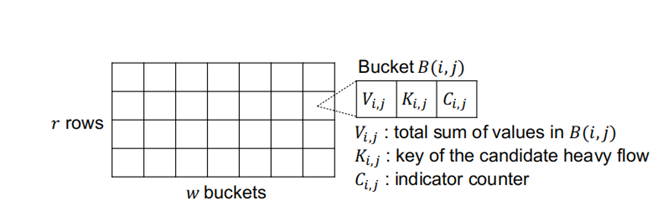
如图1[2],MV-Sketch的数据结构和Count-Min-Sketch类似,由 r 行 构成,每一行有 w 个桶,每个桶中记录三个元素Vi,j 、 Ki,j 、 Ci,j 。Vi,j 表示哈希到这个桶内所有流的总和, Ki,j表示当前桶内的重流候选, Ci,j 记录当前桶内重流候选的计数值,用于判断是否继续保留此重流候选。
当数据包到来时,MV-Sketch利用 r 个独立的哈希函数,将数据包分别映射到1 - r 行,所映射列序j由哈希值hi(x)决定。哈希到某个桶之后,根据MJRTY算法来更新重流候选。查询时,根据新流和桶内重流候选是否一致来决定估计值,最后返回所有行中估计值最小值。在一个周期结束时,MV-Sketch以是否大于设定的阈值为标准来判断重流。
如何利用MJRTY算法
MJRTY算法用于确定任意数量的候选人中,哪一个获得了多数选票,所拥有票数高于总票数一半者,一定是主要候选人。以一个例子介绍其大体思路:
假设有三位候选人A、B和C,并假设按以下顺序对代表进行了投票:A A A C C B B C C C B C C
记录完第三张选票后,A以3票领先。在处理接下来的三张选票时,将三张A票与三张其他票(两张C票,一张B票)配对(抵消)。记录所有选票之后,C成为主要候选人。

MV-Sketch借鉴MJRTY算法,在执行更新操作时(算法1[2]),先累加Vi,j = Vi,j + vx (Vi,j增加新流字节数),再将新流x与当前桶内重流候选Ki,j进行比较,若相同,那么计数器Ci,j增加新流的字节数,否则相应地减少;若减少至零下(即Ci,j <0),则x取代Ki,j,且Ci,j取绝对值。在实际中,由于少数重流所带流量在桶内所有流量中占主导地位,因而在一个周期结束时,MV-Sketch可以在桶内保持准确的重流候选。
改进及优势
使用较小静态内存:相比于LD-Sketch等使用动态内存分配的Sketch-based方法,MV-Sketch避免高内存访问的风险,且可利用SIMD加速。
在Sketch数据结构本身存储重流:不必依靠额外的数据结构来保证Sketch的可逆性,省去了额外的内存管理开销,也避免发生附加空间占用大量内存的风险。
引进MJRTY算法:在MJRTY算法的基础上加以改进(计数器加减1变为加减新流的字节数),从而在存储空间中保留准确的重流候选。
六、效果
在实际实验中,MV-Sketch相对于其他最先进的Sketch-based方法,总体来说表现出了更高的准确度、召回率、吞吐量(高达3.38倍[2]),以及更小的相对误差。
实验一:heavy hitter检测精度
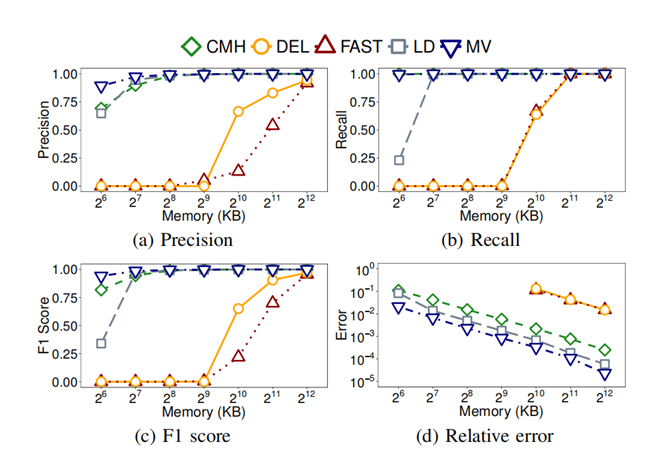
实验一[2]比较了在检测heavy hitter时MV-Sketch和其他Sketch-based算法的精度。如图2,当内存在512KB及以下时,Deltoid和Fast Sketch的精度和召回率都接近于零。Count-Min-heap和LD-Sketch的精度都很高,但当内存仅64KB时,它们不再保持高精度。总体而言,MV-Sketch的精度较高。例如,MV-Sketch的相对错误比LD-Sketch和Count-Min-Heap分别低55.8%[2]和87.2%[2]。
实验二:heavy changer检测精度
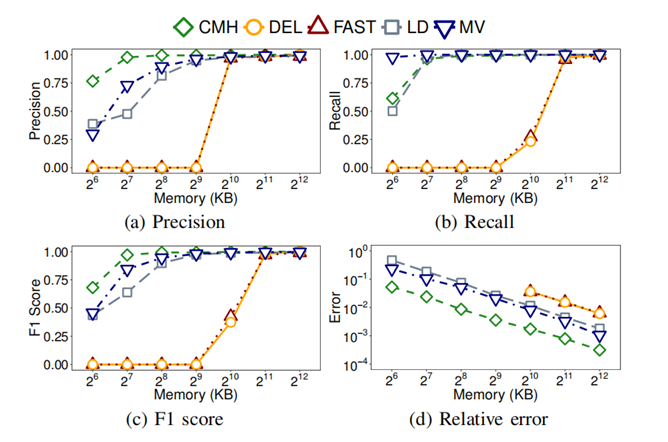
实验2[2]比较了在heavy changer检测中,MV-Sketch和其他Sketch-based算法的精度。如图3,当内存为512KB及以下时,Deltoid和Fast Sketch的精度和召回率都接近于零。Count-Min-Heap在几乎所有内存条件下,召回率都达不到1,而MV-Sketch在内存为64KB以上时,保持了100%的召回率。在内存为256KB及以下时,MV-Sketch精度较低,但当内存在128KB及以上时,MV-Sketch精度高于LD-Sketch。
七、 MV-Sketch试运行实验
环境:Ubuntu16.4,g++5.4,make4.1
文件说明:
- mvsketch.hpp, mvsketch.cpp: MV-Sketch的实现
- mvsketch_simd.hpp, mvsketch_simd.cpp: MV-Sketch的SIMD版本
- main_hitter.cpp: heavy hitter检测示例
- main_changer.cpp: heavy changer检测示例
- main_simd.cpp: SIMD优化heavy hitter检测示例
2.数据准备
作者提供的数据(十万流):https://drive.google.com/file/d/1WLEjB-w4ZlNshl1vUMb98rrowFuMBWuJ/view?usp=sharing
本文的数据准备(百万流):
3. 修改iptraces.txt文件:
十万流:

百万流:
4. 修改代码(以main_hitter.cpp为例):
十万流:
配置阈值、行数、桶数:

百万流:
配置阈值、行数、桶数:

更改数据路径:

强制类型转换(用源目的IP标识流):将数据中用五元组所标识流的源目的IP、length剥离出来,并以“源IP-目的IP 长度”形式标识流
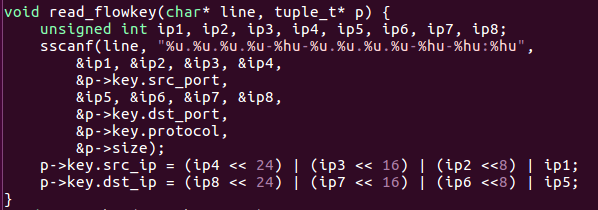
5. 环境要求
安装 g 和 make ,建议ubuntu14.04及以上,make 3.81及以上,g 至少4.8以上。
确保已经安装好了必要的库libpcap(可以通过apt-get install libpcap-dev在Ubuntu中安装libpcap)
6. 编译
使用make编译,命令如下
|
1 2 3 |
$ make main_hitter $ make main_changer $ make main_simd |
编译过程展示:
$ make main_hitter

$ make main_changer

$ make main_simd

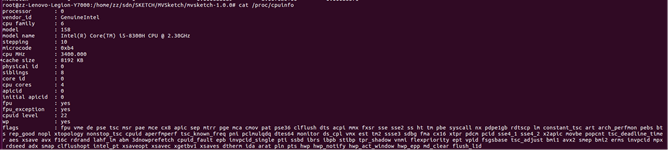
注意,要编译SIMD示例,需要确保CPU和编译器能够支持AVX和AVX2。
可用命令cat/proc/cpuinfo检查CPU,确保标记包含“avx”和“avx2”(倒二行):
7. 运行
-运行示例,程序将输出一些关于检测精度的统计信息。
|
1 2 3 |
$ ./main_hitter $ ./main_changer $ ./main_simd |
8. 输出结果展示:
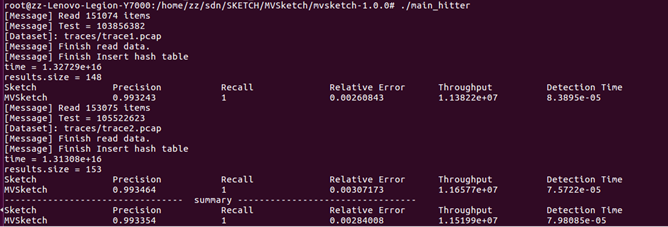
main_hitter输出结果展示
十万流:
百万流:

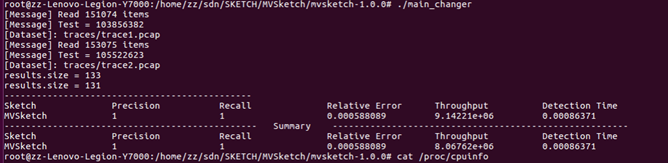
main_changer输出结果展示
十万流:
百万流:

9. 试运行实验小结:
MV-Sketch在十万流,百万流的数据规模下,其结果都表现出了高准确度、低相对错误、100%召回率。本文将所准备的流数据用源目的IP标识,不同于作者所提供数据以五元组形式,因而需要进行强制类型转换等对代码的修改及函数调用。
八、总结
快速增长的网络规模对当今的网络流量检测技术提出了更高的要求,现有Sketch保证可逆性时,易导致过高内存访问。MV-Sketch引进了MJRTY算法,在Sketch本身保持异常流量,保证可逆性的同时避免了对内存的过度依赖。
在MV-Sketch效果验证实验[2]中,其召回率一直都保持在高水平,但MV-Sketch在极小内存下的检测能力还有待加强,尤其是对于heavy changer的检测能力。或许我们可以根据不同应用场景、限制条件,选择性使用Sketch,或采取多种Sketch方法组合嵌套的方式,来进行异常流量检测。
参考文献:
[1]https://www.sdnlab.com/22685.html
[2]Lu Tang,Qun Huang,Patrick P. C. Lee,"MV-Sketch: A Fast and Compact Invertible Sketch for Heavy Flow Detection in Network Data Streams", Proc. of IEEE INFOCOM 2019 .
[3]G. Cormode, S. Muthukrishnan, "An Improved Data Stream Summary: The Count-min Sketch and its Applications", Journal of Algorithms, vol. 55, no. 1, pp . 58-75, 2005.
[4]G. Cormode and S. Muthukrishnan. An Improved Data Stream Summary: The Count-min Sketch and its Applications. Journal of Algorithms,
55(1):58–75, 2005.
[5]Q. Huang, P. P. C. Lee, "A Hybrid Local and Distributed Sketching Design for Accurate and Scalable Heavy Key Detection in Network Data Streams", Computer Networks, vol. 91, pp. 298-315, Nov 2015.
[6]G. Cormode and S. Muthukrishnan. What’s New: Finding Significant Differences in Network Data Streams. IEEE/ACM Trans. on Networking, 13(6):1219–1232, 2005.
[7]Y. Liu, W. Chen, and Y. Guan. A Fast Sketch for Aggregate Queries over High-Speed Network Traffific. In Proc. of IEEE INFOCOM, 2012.
[8]R. Schweller, Z. Li, Y. Chen, Y. Gao, A. Gupta, Y. Zhang, P. Dinda, M. Y. Kao, G. Memik, "Reversible Sketches: Enabling Monitoring and Analysis over High-Speed Data Streams", IEEE/ACM Trans. on Networking, vol. 15, no. 5, pp. 1059-1072, 2007.
[9]T. Bu, J. Cao, A. Chen, P. P. C. Lee, "Sequential Hashing: A Flexible Approach for Unveiling Significant Patterns in High Speed Networks", Computer Networks, vol. 54, no. 18, pp. 3309-3326, 2010.
[10]R. S. Boyer, J. S. Moore, "MJRTY -A Fast Majority Vote Algorithm", Automated Reasoning, pp. 105-117, 1991.







