目前,数据中心网络正在面临着快速创新,但与此同时,成本问题却成了超大规模和主要的云基础设施服务提供商(后文简称云建设者)面临的一大难题。
他们对带宽的集体需求推动着网络ASIC、交换机和收发器制造商的发展,而他们的吝啬正在迫使这些供应商连续降低了几代产品的成本。
如果网络成本没有大幅下降,超大规模和云建设者是不会新购买技术,而用户也不会考虑当他们停止购买新技术时会发生什么。这对计算,存储和网络来说是一件非常糟糕的事情。摩尔定律起作用并不是因为晶体管和存储介质越来越便宜,而是因为有人在这些介质变得便宜时购买新技术。
超大规模制造商和云建设者有一个相似之处,他们不会为高端技术支付额外费用。他们希望技术能够以摩尔定律的速度进步,并且在每单位产能成本远低于现有技术成本之前,他们不会升级到新技术。
这是我们从市场数据中综合得出的教训,也是非常有见地的观点,网络和计算行业的杰出人物Andy Bechtolsheim在英特尔总部举办的热点互连26会议(Hot Interconnects 26 conference)也分享了这一观点。
Bechtolsheim是Sun Microsystems的创始人之一,也是第一个商业上成功的Unix工作站的创建者。1995年,该工作站为他创立千兆以太网交换机公司Granite Systems提供了资金。在Granite Systems成立一年之后,路由器制造商思科系统公司以2.2亿美元的价格收购了Granite,并进入了交换机市场。David Cheriton是Granite的联合创始人之一,他和Betcholsheim一样,也是搜索引擎巨头Google的早期天使投资人,他与Bechtolsheim合作创办了Kealia,这家公司开发了高性能的聚合超级计算机,代号为“Constellation”。该计算机是基于Opteron服务器,密集SATA存储和大规模InfiniBand导向器交换机而设计的。在21世纪初当Sun发展到一定阶段时,Sun收购了Kealia,此时Bechtolsheim发现自己又回到了Sun。不久之后,Bechtolsheim和Cheriton组建了Arista Networks公司,这家公司在2009年以Broadcom和Fulcrum Microsystems的商用交换机芯片为基础的10GB/sec以太网交换机和一个本土的、由Linux衍生的可扩展操作系统引起了巨大轰动。Arista现在是增长最快的数据中心交换机制造商,也是除少数白盒交换机制造商外,思科唯一真正的竞争对手。此外,Arista还销售基于商业交换机芯片的软件。
多亏了微软、谷歌、商业交换机芯片制造商Broadcom和Mellanox Technologies以及Arista Networks的早期努力,IEEE不得不着推出25 GB/sec的信令,使得100 GB/sec的以太网足够便宜。超大规模和云建设者甚至可以考虑采用它。IEEE的早期标准适用于使用10个10 GB/sec的通道来制作100 GB/sec的交换机,但这种交换机产生的热量太多了,体积大和价格也昂贵。因此,超大规模和云建设者坚持他们的立场并且一直和IEEE僵持,迫使采用了他们的标准。几年后,我们将PAM-4调制技术添加到了通信服务器上,在去掉编码开销后,这些服务器现在以50 GB/s的速度运行,每通道的速率也能达到100 GB/s。因此,我们正处于数据中心中以太网的400GB/s的开端。
根据Bechtolsheim提供的数据,2016年40 GB/sec以太网交换机的销量达到峰值,而100 GB/sec的端口出货量在2017年底超过了40 GB/sec的出货量,并且仍在攀升,预计在2020年某个时候将达到更高的曲线峰值,并持续数年。400 GB/sec以太网将于今年开始,而800 GB/sec以太网预计将于2021年开始增长,这在很大程度上要归功于商用交换机ASIC制造商采用先进的芯片制造工艺。芯片制程工艺的进步使得更多的功能可以添加到交换ASIC中,例如更大的缓冲区和路由表,以及更快的SERDE来增加带宽。

从明年开始,随着400GB/sec的推出,网络ASIC的进度将与CPU持平,这使得网络创新的速度似乎比CPU更快。然而现实情况是,网络还处于落后的状态,因为从10 GB/sec到100 GB/sec以太网交换机演进过程中,40 GB/sec交换机耗时较长,在一定程度上损害了分布式系统的设计。未来随着以太网交换机和CPU的发展,都会遇到摩尔定律“失灵”的问题。
每次芯片制程的进步都很重要。在2015年、2016年,采用28纳米工艺制造的交换ASIC是当时最先进的。随着制程工艺的进步,以28纳米为参考对象,在制程达到16纳米时,晶体管密度是28纳米的3倍,7纳米时(这将发生在2020年到2021年),晶体管密度将增加14倍,达到5纳米(2022年到2023年)时,晶体管密度将是28纳米的30倍。这是将以太网从100 Gb /sec到400 Gb /秒再到800 Gb /sec的重要驱动因素。
以下是显示以太网通道速度随时间变化的图表:
![]()
以下是商用交换机总带宽和通道速度的映射图

正如您所看到的,当前的50 Gb / sec时代将会很短,因为业界将在7纳米设备上采用100Gb /sec 信令,2021年每个ASIC的总带宽达到25.6 Tb / sec,到2023年将翻一番,达到51.2 Tb / sec。
但这问题是,芯片的设计成本呈指数级增长,能够在先进工艺中蚀刻芯片的代工厂数量正在减少,风险也在不断上升。因此,随着越来越少的交换机制造商蚀刻自己的ASIC,商业ASIC制造商正在崛起,这也分散了部分风险。
这意味着,随着每一代新以太网的出现,降低成本变得越来越困难,但不幸的是,这种降低成本是每一代所要采用的一个必要条件,因为正如Bechtolsheim所指出的那样,超大规模和云建设者都面临着每年50%的带宽需求增长。他们无法再为此支付更高的价格。
Bechtolsheim解释说:“企业采用的速度很大程度上取决于相对价格/性能。在2000年至2010年这段黑暗时期,2000年有一个10GB/sec的标准,但设备非常昂贵,很少有人愿意花费如此高的金额来证明部署它的合理性。直到花了近十年的时间,费用才降下来,后来才有人采用。在云计算领域,这是根本行不通的,因为除非它在第一天就便宜,否则企业永远不会采用这项技术。”
这正是从40Gb/s过渡到100Gb/s所面临的情况。当适合的100Gb/s交换机出现时,端口的带宽为2.5倍,每个端口的增量成本约为25%,但每比特传输的成本却大大降低了。尽管最近几个季度服务器和交换机支出有所下降,但随着网络的蓬勃发展,超大规模和云建设者开始向100Gb/的网络转移,预计他们将会有很大的需求。如图:
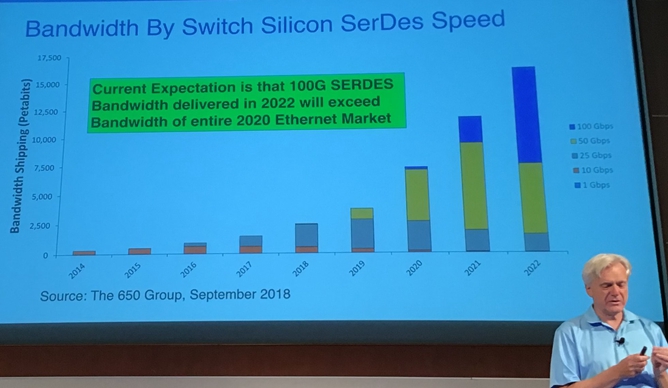
去年9月The 650 Group预测,使用50 Gb / sec SERDES的交换机将在未来几年内将大量带宽容量推向数据中心。但无论SERDES速度如何,2022年基于100 Gb / sec SERDES的机器的总带宽将超过2020年数据中心内出售的总带宽。在2017年至2022年间,传输的总带宽将增加一个数量级以上。
但只有当传输的每比特成本持续下降时,这种情况才会发生,因为仅剩的几个晶圆厂可以继续缩小晶体管,并从他们在晶圆厂上花费的100亿美元中获得回报。基于这些100 Gb / sec SERDES的400 Gb /sec交换机的所有功能都取决于超大规模和云建设者,如下图所示:

根据Dell’Oro估计,全球前四的云服务提供商在2019年几乎占到400 Gb /s端口出货量的全部,而从这之后大约一半的端口出货量将由他们承担,其余另一半的大部分将由云占据。现在大部分企业仍然主要依靠10 Gb /s的交换机。
我们希望企业不要落后太多,但它们往往远远落后于超大规模和云建设者,而且差距越来越大。不久之后,迁移到云端可能是大型企业在不花费大量资金的情况下获得当前技术的唯一途径。