

作者简介:黄玉栋,北京邮电大学网络与交换国家重点实验室博二在读,研究方向为网络体系架构,确定性网络,邮箱地址: hyduni@163.com.
今年4月谷歌在NSDI顶级会议上发表了Aquila架构方案[1],随后8月,阿里在SIGCOMM顶级会议上发表uFAB架构方案[2],均提出了要将数据中心网络从从“低时延大带宽”演进到“确定性可预期”的目标,开启了确定性数据中心网络研究的新纪元。那么,数据中心网络为什么需要确定性可预期?他们的实现方法又各自有什么异同和优缺点?有趣的是,两者恰好采用了不同的底层QoS技术路线,但都实现了兼容现有以太网的核心主旨。本文将从科普的角度分析其保证“确定性可预期”的关键思想与原理,共同探讨前沿工作进展。
数据中心为什么需要确定性可预期?
1)云数据中心的由来:二三十年前,人们对互联网的需求还十分简单,比如搭建一个展示企业信息的网站,开发一个管理员工信息的系统,这些应用往往只需放到一台服务器上,给服务器配一个公共IP或局域IP地址,让他人能够访问即可。其后,随着接入用户的海量增长,需要的计算和存储资源也指数增长,互联网公司不得不购买大量的服务器来支撑应用服务,便出现了从服务器到“云数据中心”的转变。
2)计算密集型应用:同时,传统的数据密集型应用,比如信息网页和视频传输等,只需要低时延和大带宽,而新型的计算密集型应用,比如Web搜索、深度学习、场景渲染、MapReduce、城市大脑、气象超算等,需要将任务放到上百台服务器中,只有当所有服务器都输出结果才算任务完成,中间任意一处的长等待时延或者网络拥塞丢包都可能造成极差的用户体验,因此,这种分布式计算对数据中心网络提出了极高的“确定性可预期”的要求。
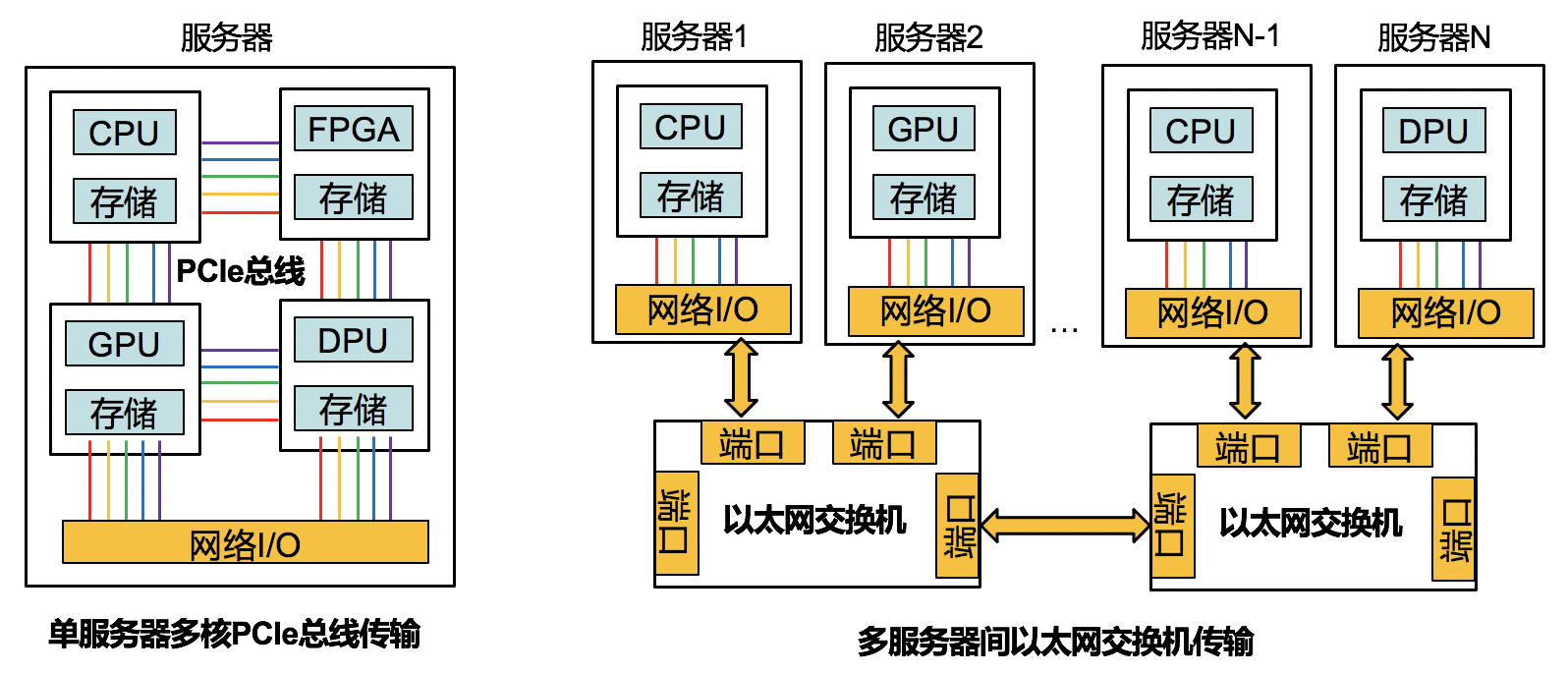
3)算力提升方案:如图1所示,为提升单体算力,CPU从单核发展到多核,且可以与FPGA、GPU、DPU等结合,通过PCIe总线实现服务器内的高性能计算;但这只是锦上添花,真正雪中送炭还得靠多服务器并行计算,因此如何提升服务器之间的网络传输性能,让服务器集群表现得像“一台”超级服务器是未来数据中心算力提升的关键。传统IP数据包交换采用尽力而为转发,存在大量时延抖动、拥塞和丢包,无法保证如PCIe总线一样的实时无阻塞传输性能,因此人们提出了InfiniBand网络标准,采用与以太网不同的协议架构,把网络中交换和路由的概念引入到I/O子系统中,并能够保证单个链路带宽保持在大于PCIe总线数据速率的水平,从而消除服务器之间的网络限制,达到“无限带宽”的效果。
4)不可撼动的以太网:InfiniBand虽然性能极佳,但并未得到广泛部署,因为IP/以太网具有不可撼动的市场地位,以太网不仅协议简单、技术成熟、成本低廉,而且具有极好的兼容性、灵活性和可扩展性,能够实现异构组网、任意多点互联互通。当前,任何想要干掉IP/以太网另起炉灶的技术都无法成为主流。
那么,基于以太网实现确定性可预期行不行?行!下面分析阿里的uFAB架构方案和谷歌的Aquila架构方案。
uFAB架构方案
uFAB为虚机对(VM-pairs)提供可预期的网络服务质量,主要包括:保证最小带宽,全力工作(work conservation),和有界尾部时延。其QoS方法依旧沿用了传统以太网相关的带宽分配、发送速率控制、基于窗口的流量接入控制、以及路径迁移。
1)带宽分配:带宽分配用于初始化时满足应用的最小带宽需求。如图2所示,比如交换机链路带宽为10Gbps,有两条流A、B分别需要4Gbps和3Gbps的最小带宽,那么通过计算令牌(Token)的方式,可以为每流预留4Gbit和3Gbit的令牌资源。令牌简单讲就是在出端口放置一个计数器模块统计流传输的bit数,每传输1bit流就消耗1bit令牌。因此,每当有新流要接入链路时,需要计算其所需的带宽令牌数,如果所有流的令牌数加起来小于链路带宽,则可以接入,否则不能接入。
2)发送速率控制:把所有发送端的速率控制在最小带宽很安全,但不够高效。因为有的发端有时没有流发送,有的带宽需求又会增加,这就需要在以不超过链路带宽容量的前提下动态改变发送端的发送速率。比如流A当前有更多的数据需要发送,则其可以增大发送速率到7Gbps,从而实现链路的“全力工作”,即充分利用链路的带宽传输能力。
3)基于窗口的流量接入控制:由于流量不是恒定速率一成不变的,其具有突发性,导致短期内的数据累积,所以仅靠带宽分配是不够的,还需要基于窗口的流控机制。简单地说,带宽是个秒级单位,7Gbps统计的是1s内应用传输的数据量不超过7Gbit,这7Gbit在不同的流量到达曲线下,会在每个微秒级(比如10us)时隙单位表现不同的数据累积量。网络需要在带宽分配的基础上根据不同的往返时延改变发送数据量。假设在链路空载时测得往返时延为1RTT,比如当前为2RTT,则可以增大窗口(每RTT大小的时隙)的发送数据量,若往返时延增大到6RTT,则说明排队时延增大,需要减少窗口的发送数据量。此外可以设置当往返时延大于某一阈值(比如8RTT)时,默认网络发生了拥塞丢包。需要注意的是,文中还提出两步流量接入策略,以保证在所有发送端同时突发流量时,能够在2RTT的时间内学习到初始突发的大小并减少发送速率,最终保证所有发送流量小于3倍的带宽时延积,实现有界尾部时延的目标。
4)路径迁移:若当前总流量需求超过了路径的带宽容量上限,或者有其他空闲轻载的路径可以使用时,可以进行路径迁移。路径迁移需要避免震荡和乱序的问题。因为路径一会空闲、一会拥塞,流量负载时时刻刻都在变化,反复路径迁移会导致网络震荡,难以快速收敛到预期的发送速率;为解决震荡的问题,uFAB在随机的[1,N]个RTT窗口时隙内只允许1次路径迁移,保证在上一次路径迁移之后uFAB有至少1个RTT的时间来观察负载变化。为解决数据包乱序的问题,uFAB可以设置迁移到新路径后第1个RTT不发送数据,从而允许老路径上的数据被清空后再发送数据。

这些方法以前也有人用,uFAB最厉害的还是解决了一个关键问题:如何获得这些决策的前提,即感知到网络内部丰富复杂的变化信息?
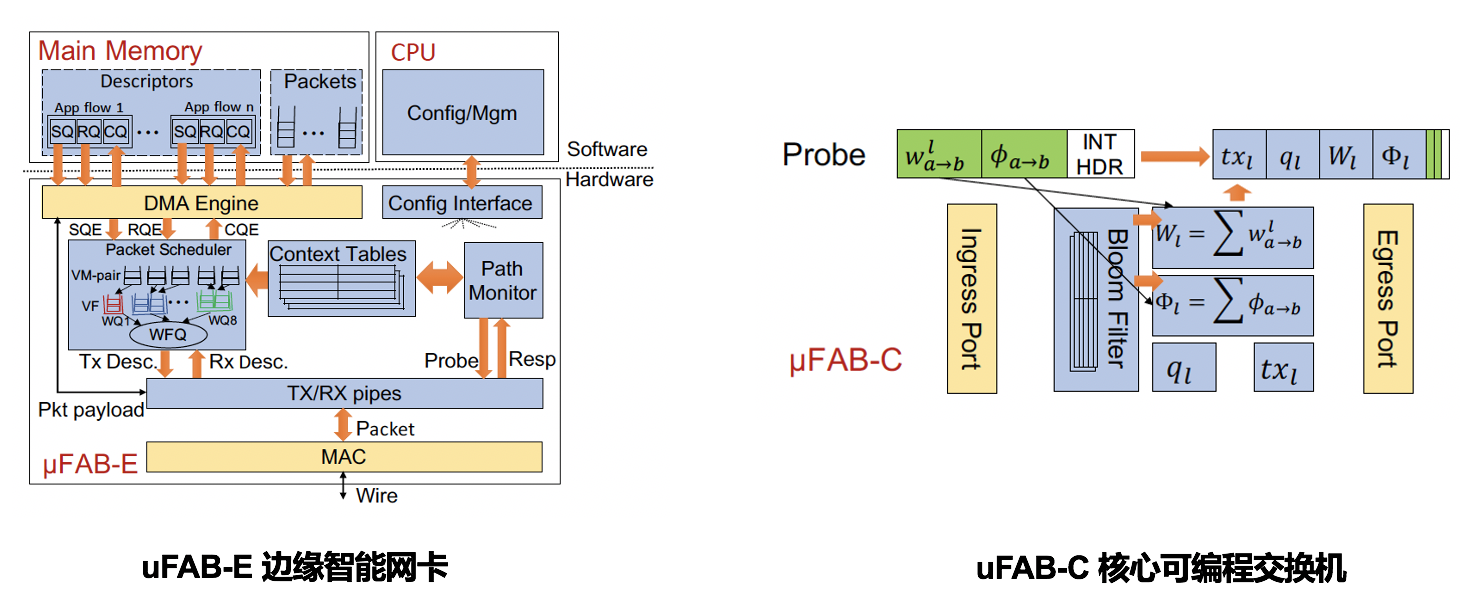
基于测量的边缘核心融合方案:如图3所示,uFAB提出了基于测量的“边缘核心融合”的解决方案,即融合边缘智能网卡(uFAB-E)和核心P4可编程交换机(uFAB-C),利用带内遥测机制持续发送探测包来测量网络信息,包括链路容量C、队列大小q、发送速率tx、总带宽预定量、以及总发送窗口。特别是核心交换机使用布隆过滤器来检测并添加边缘发来的探测数据包信息,然后计算并维护两个寄存器和W,即总带宽预定量和总发送窗口。具体细节实现可查阅uFAB论文,在此略过。
Aquila架构方案
在分析Aquila方案前,不得不讲一下异步传输模式(ATM,Asynchronous Transfer Mode)技术。ATM是一种融合了电路交换和分组交换优点的交换技术,其采用异步时分复用代替电路交换的同步时分复用,解决了电路交换信道利用率低和不适用于突发业务的问题;相对于分组交换,其采用固定分组的方式,可以大大降低交换时延。具体地,ATM包含基于信元(cell-based)交换、建立虚连接、资源预留三种主要的服务质量保障技术。
1)基于信元的交换:网络的本质是将一堆数据从一个地方转移到另一个地方,其物理层的单位是比特流,即一个一个的bit。在以太网传输中,比特流被封装成二层数据帧(frame)和三层数据包(packet),因此以太网传输的最小的单位是数据包,由于数据包可以是64字节到1500字节间任意大小,于是也叫可变长分组。而在ATM中,传输的最小单位是信元(cell),也叫固定长度分组。比如规定一个单位长度(比如64字节)作为信元,所有的数据包都会被切割封装成多个信元来进行交换传输。那么为什么要提出信元这个概念呢?如同在十字路口小轿车必须等待长长的卡车转弯,可变长分组容易在交换设备中引起通信延迟,而固定分组的信元好比一节节地铁车厢,不仅能实现小包的快速交换,更有助于简化接入控制、资源预留等机制。
2)建立虚连接:不同于IP/以太网中的逐跳查找转发方法,ATM要求在传输前建立虚连接,即在任意两个节点间可以实时建立/拆除虚电路。虚连接引入了“虚通路”(VP)和“虚通道”(VC)的概念,一条物理链路可以复用多条虚通路,每条虚通路又可以复用多条虚通道,一旦通道建立,好比开启了直达路由,可以省去中间逐跳的查找转发开销。
3)资源预留:流量在接入网络时,首先需要发送信令请求,沿路径预留所需的带宽和缓冲资源,一旦预留成功,则可以严格保证业务的带宽、时延、抖动、丢包率等服务质量指标。位于三层的ATM适配层(AAL)负责针对不同的业务采用不同的适配方法,大致可分为恒定比特率业务、实时可变比特率业务、非实时可变比特率业务、尽力而为业务。
ATM能够提供严格的服务质量保障,但其技术复杂、价格昂贵,最麻烦的是,它采用独自的协议架构,无法与以太网兼容。因为大多数数据业务依然是走以太网的,运营商不可能建一张以太网,再建一张平行的ATM网络。巨大的建设成本和管理运营维护开销使得ATM难以走出困局。
那我就是又想用以太网又想要ATM,偏要把两张网当一张网使,行不行?行!把以太网交换芯片和ATM交换芯片做到一台交换机里不就可以了!这就是谷歌Aquila方案的厉害之处。
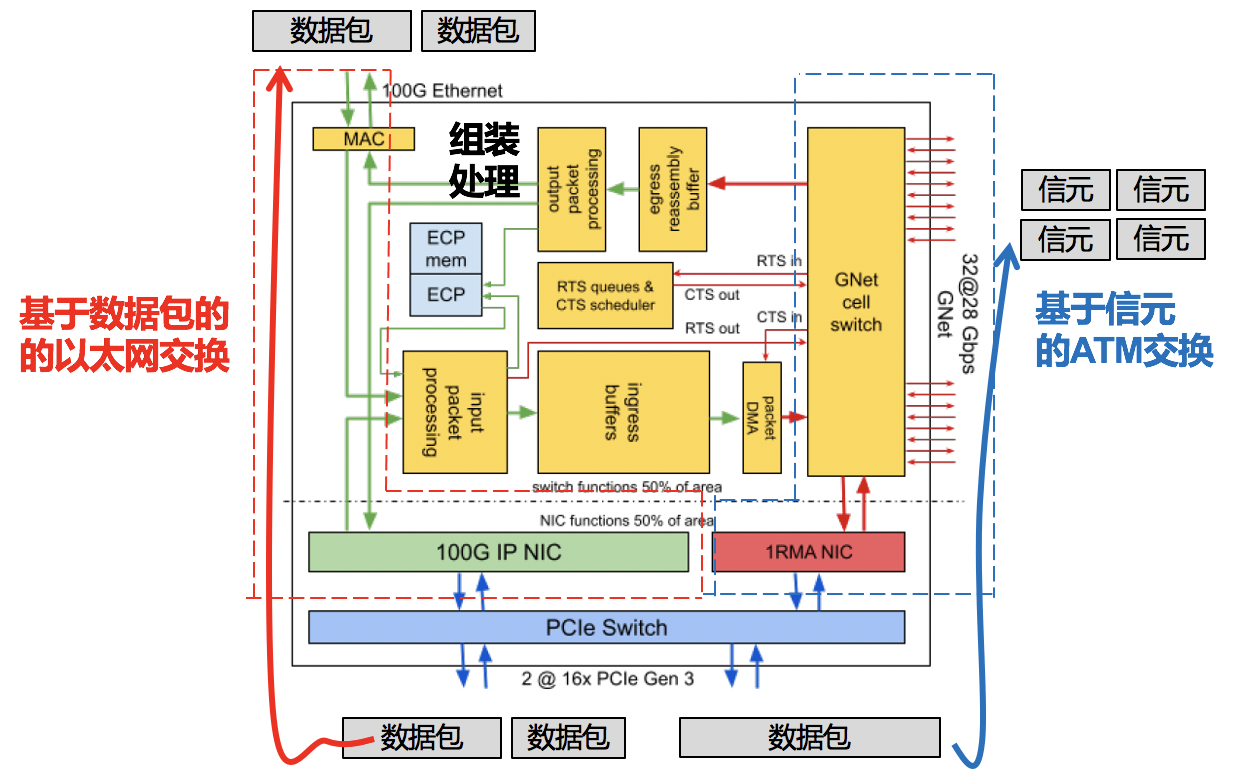
如下图所示,Aquila芯片架构包含100G的IP网卡、1RMA(Remote Memory Access)网卡、嵌入式控制处理器(ECP,Embedded Control Processor)、基于信元的GNet交换芯片、以及组装处理模块。当流量进入到交换机时,一部分可以通过IP网卡走传统的基于数据包的以太网交换,一部分可以通过1RMA网卡走基于信元的ATM交换。芯片中间的组装处理模块负责两种交换单位的转换,即将IP数据包切割处理为多个信元或者将信元重新组装为IP数据包。
当然,GNet交换只是借鉴了ATM的相关优点,并不能说GNet完全就是ATM交换。此外,Aquila还在其他方面有许多创新,比如采用全连接的蜻蜓(Dragonfly)拓扑,实现了Aquila控制平面和其他以太网控制平面的融合统一,实现了主机软件协议栈、网卡、交换机的垂直整合,使Cliques(可以理解为一种紧耦合、同质化、可增量式部署、兼容以太网、且具有超低传输时延的超级服务器集群)成为可能。更多细节可查阅Aquila论文,在此略过。
参考文献:
[1] Gibson, Dan, et al. “Aquila: A unified, low-latency fabric for datacenter networks.” NSDI, 2022.
[2] Wang, Shuai, et al. “Predictable vFabric on informative data plane.” SIGCOMM, 2022.








