

作者简介:
谢高畅,北京邮电大学网络与交换技术国家重点实验室在读博士研究生,研究方向为未来网络体系架构、边缘计算、算力网络、无服务器计算等,邮箱地址:xiegaochang@bupt.edu.cn
IEEE INFOCOM 2022(International Conference on Computer Communications,国际计算机通信会议)于5月2日至5日以线上会议的形式举行。IEEE INFOCOM是通信网络领域的顶级会议,也是CCF A类会议,它由IEEE Communications Society组织举办。IEEE INFOCOM侧重于通信网络领域的基础理论研究与系统设计实现,并为研究人员提供发布创新性成果和交流合作的机会。

会议概览
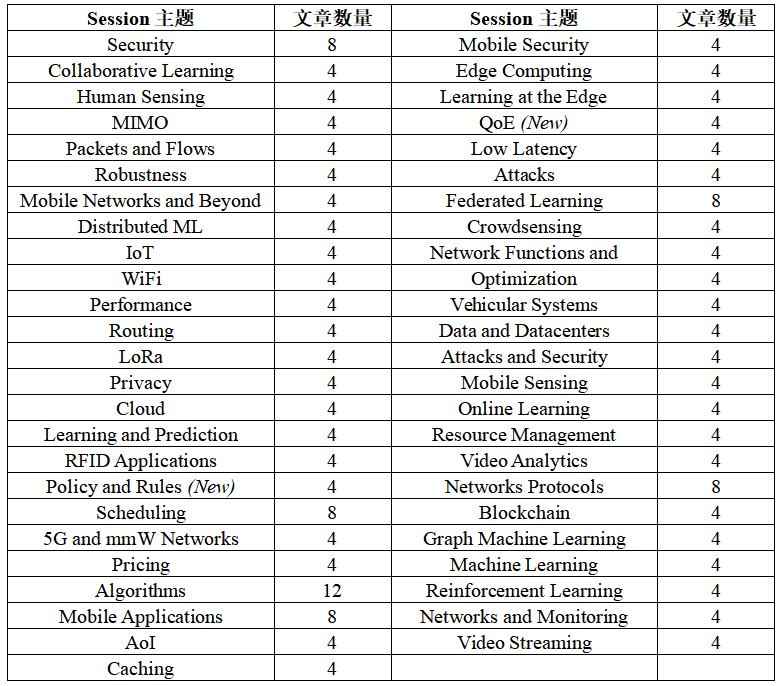
INFOCOM 2022共设有主会议(main technical program)、研讨会(workshops)、主题演讲(keynote speech)、讨论(panels)、演示(demo)和海报(poster)等环节。其中,INFOCOM 2022主会议共收录224篇论文,分为49个Session:
热门论文解读
- Constrained In-network Computing with Low Congestion in Datacenter Networks

这篇文章来自“Data and Datacenters”这一Session。
1)研究背景:在分布式网络环境中,网内计算通过将计算任务从服务器转移到智能网络设备处理的方式以减少网络的数据传输压力,并提高应用性能以及资源使用效率,例如最先进的智能交换机可以实现近似线性速率的计算处理和数据聚合功能,能够为大规模分布式机器学习提供加速和性能改进。然而,考虑到智能网络设备的部署成本,网内计算不会在整个网络中无处不在,也不适用于每个工作负载。因此,在网络内合理部署计算能力有限的智能网络设备,并精简化执行各类网络操作以最大限度地减少拥塞是实现高性能网内计算的关键。
2)设计方案:将网络模型描述为完全二叉树,叶子节点则代表机架上级交换机连接到产生负载的服务器/工作节点。在此模型中考虑四种聚合交换机的部署方案:
Top策略:将聚合交换机部署在靠近网络根节点的位置,通过减少在网络最顶端传输的消息数量以避免拥塞。
Max策略:将聚合交换机部署在网络叶子节点,以实现“在萌芽阶段”减少链路拥塞。
Level策略:聚合交换机遵循将网络划分为大小相似的子树的原则部署,使得其中每个子树中的所有消息都被聚合。
SMC(搜索网络最小拥塞)策略:提出使用动态规划方法对网络进行异步扫描并求得满足拥塞约束的聚合交换机的最优部署策略。
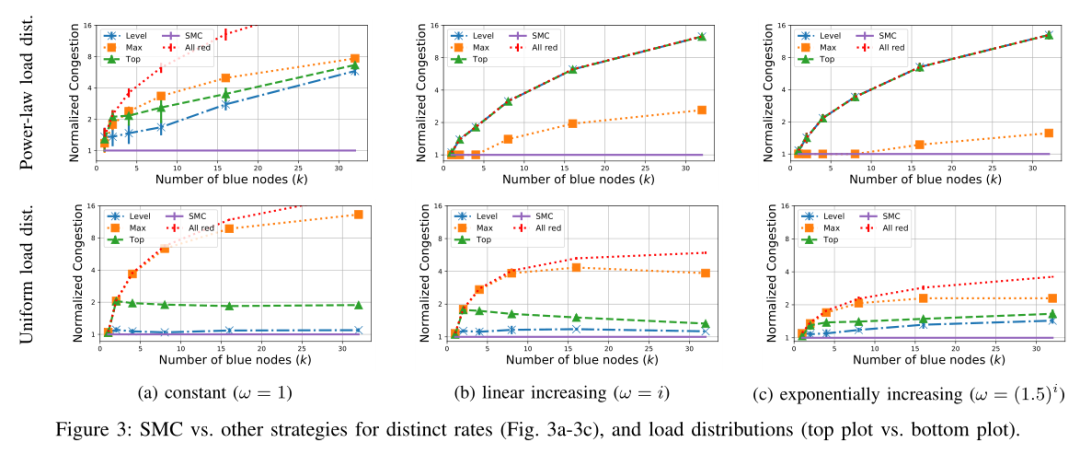
3)实验结论:在网络内使用少量聚合交换机就可以实现显著的减少网络拥塞;在不同的工作负载分布方式和网络连接速率下,提出的SMC策略减少网络拥塞的性能明显好于其他三种策略,无论负载分布或链路速率如何,使用SMC都能确保健壮性,在最好情况下SMC策略可以实现13倍的性能改进;另外,SMC策略可以以更小的交换机容量实现最佳的聚合性能。
- VSiM: Improving QoE Fairness for Video Streaming in Mobile Environments

这篇文章来自于本届会议新增的Session:“QoE”。
1)研究背景:移动视频流和用户需求的快速增长对移动网络中的带宽分配提出了更高的要求,在移动网络中,多个用户可能共用一条瓶颈链路。这为内容提供商提供了一个联合优化多用户服务体验的机会,但高移动性的用户往往会遇到连接持续时间短和频繁切换的问题,这将显著降低QoE(用户体验质量),还会造成不同用户的体验质量差异较大的不公平问题。然而,QoE和QoE公平性是评估客户端视频流性能的两个关键指标。QoE是单个客户满意度的重要指标,视频内容提供商则更为看中衡量所有用户满意程度的QoE公平性。因此,需要优化模型来实现最大或可接受的QoE,同时确保不同用户的移动视频流应用在共享链路资源过程中的公平性。
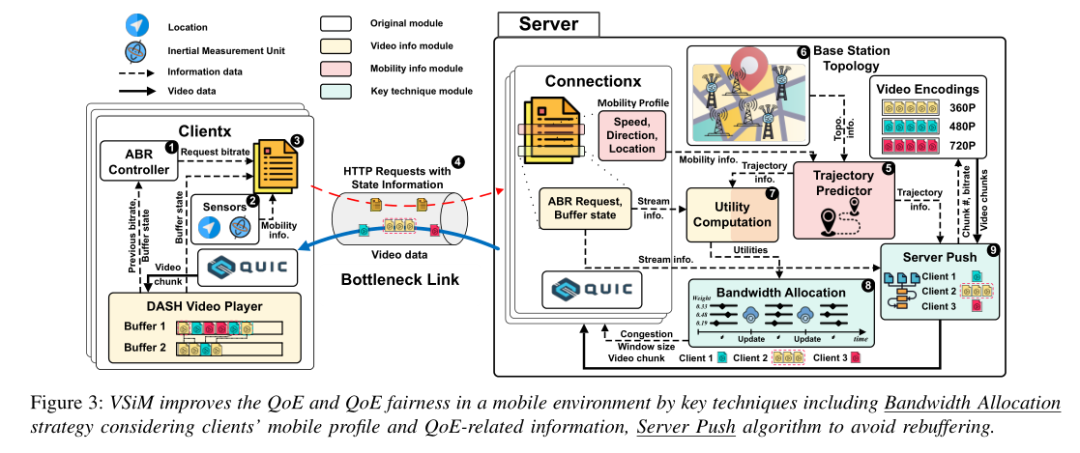
2)设计方案:设计了用于解决移动视频流应用共享瓶颈带宽过程中中的QoE公平性问题的端到端解决方案——VSiM。该方法包括两个关键技术,首先利用每个客户端收集移动设备的移动概况信息(例如速度、位置和方向),以及与QoE相关的信息,然后这些收集到的状态信息分组、加密,并与HTTP请求一起发送,用于以特定比特率将视频块(chunk)下载到服务器。。提出了一种基于分析上述信息及基站信息以实现为每个客户端选择最佳分配的带宽的带宽分配技术,以在移动环境中动态地针对实时视频流应用实现最大化的客户端QoE公平性;另一方面,考虑到一些客户端可能由于移动性而对播放缓冲区大小更敏感,并且客户端与单个基站连接时间短导致可能无法收到特定请求比特率的视频块,提出了一种基于HTTP/3协议的新型服务器推送算法SDFR,服务器可以根据客户端的当前驻留时间、切换时间和剩余缓冲区大小等信息识别遭受高频重缓冲的客户端,并为其激活服务器推送功能的同时不影响现有的带宽分配策略和其他客户端的视频观看质量。
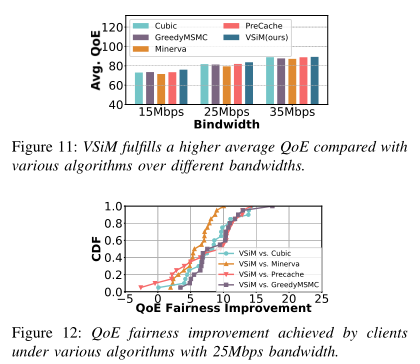
3)实验结论:与当前先进的Cubic、PreCache、GreedyMSMC、Minerva方案相比,提出的VSiM方案的平均QoE最优;VSiM在不同的带宽条件下都实现了良好的QoE公平性,VSiM的客户端QoE公平性提高了40%以上,即VSiM中客户端的观看质量可以从720p提高到1080p;VSiM方案还可以将平均QoE提高约20%。
- Dyssect:Dynamic Scaling of Stateful Network Functions

这篇文章来自“Network Functions and Tasking”这一Session。
1)研究背景:网络功能虚拟化(NFV)通过按需动态扩展以保证更好地利用计算资源。然而,大多数网络功能(NFs)都是有状态的,需要根据每个数据包进行状态更新。在扩展操作期间,内核需要同步对共享状态的访问以避免出现争用情况,并确保NFs根据数据包的到达顺序处理。然而,传统用锁(locks)控制对共享状态的并发访问的方法无法满足当前的吞吐量和延迟等性能要求。此外,网络流量高度倾斜导致仅使用切分(sharding)的方法来划分网络功能状态的系统中会出现负载不平衡的问题。
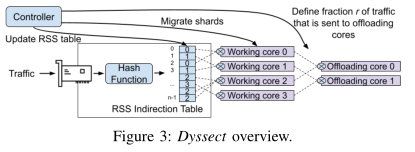
2)设计方案:提出一种通过分解网络功能的状态来实现有状态NFs动态扩展的系统Dyssect。通过内核和集中控制器之间的协作,Dyssect在内核之间迁移分片(shards)和流,以实现负载平衡或流量优先级,而无需使用锁或重新排序数据包。具体来说,首先它使用硬件将数据包引导到分片,并在内核之间传输分片,避免了单核调度所有数据包的性能瓶颈;其次,Dyssect使用一种允许数据包记录其所在流的状态的数据结构将状态与网络功能分离。这种机制对于实现在内核之间对独立的流进行细粒度迁移,从而在不引入竞争条件的情况下优先处理流量或实现更均匀的负载分配至关重要。通过协调内核和集中控制器之间的迁移操作,Dyssect可以防止数据包重新排序和死锁;再次,Dyssect可以在流(flows)级别管理流量,因此它可以使用比其他方案更少的分片以避免频繁的分片传输。最后,Dyssect使用优化模型将分片和流分配给内核,该优化模型在长时间和短时间两种尺度捕获系统的行为,以实现操作人员指定的SLO(服务级别目标)需求。

3)实验结论: Dyssect可以使用相同数量或更少的内核处理与RSS相同或更高的流量负载,而不会在迁移分片和流时造成流量中断,Dyssect还可以实现RSS没有的优先处理某些流以降低延迟的能力;在所有情况下Dyssect与RSS、RSS++、State Disag等方案相比都可以通过更少的分片迁移实现更高的吞吐量;当DySect使用SmartNIC时平均查找时间会显著减少,同时还提高了每周期指令数、缓存命中率等CPU性能指标。
- Midpoint Optimization for Segment Routing

这篇文章来自“Optimization”这一Session。
1)研究背景:为了应对不断增长的互联网流量,互联网服务提供商使用分段路由(SR)方法精确规划数据包在网络中转发的路径。然而,现有的SR策略只用于在一对起点与终点之间路由流量,而在传输过程中访问它们的需求将不会被SR策略所引导。虽然这种策略可以实现精确的流量转发,但是会造成网络中产生巨大数量的策略配置,造成链路利用率较低的问题。通过将SR策略集成到内部网关协议中,允许一个策略同时路由多个需求的中点优化(MO)方法可能大幅减少需要在网络中配置的策略的数量并提高链路利用率。
2)设计方案:将MO方法引入到SR策略中,即将SR策略整合到IGP中以便将各种需求引导到其中。这将允许使用单个策略路由多个需求,从而显著减少所需配置的策略数量。具体来说,如果某策略终点位于从策略起点到数据包目的地之间的IGP最短路径上,则数据包将被引导到该策略中。基于以上思想,首先提出了Shortcut 2SR (SC2SR)算法,该算法基于IGP Shortcut并使用最多两段的策略,以优化最大链路使用率。其次为了有效地减少已部署策略的数量提出了基于线性规划的SC2TLE算法,首先计算最优的最大链路使用率,然后在第二个后续步骤中最小化获得它所需的策略数量。
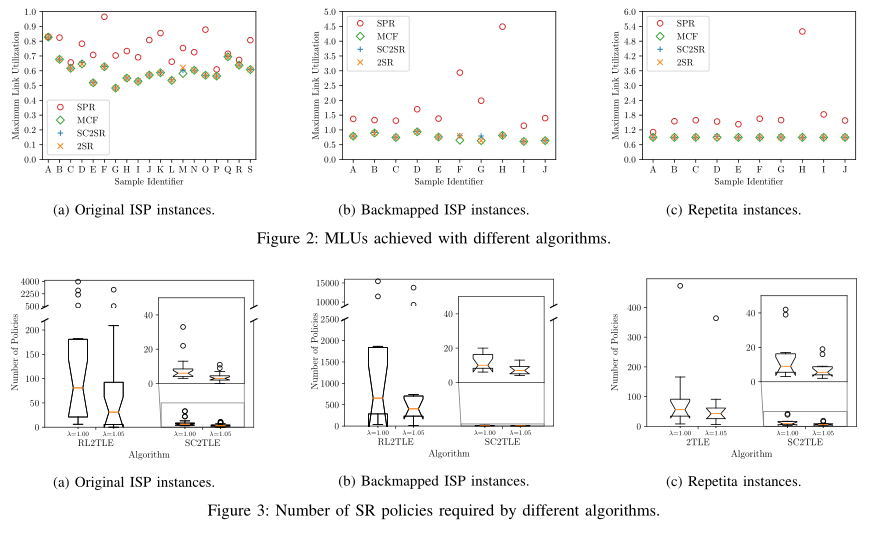
3)实验结论:SC2SR算法与现有的SPR、MCF、2SR算法相比,几乎能够在所有场景中获得最佳链路利用率;SC2TLE算法与现有的RL2TLE、2LTE算法相比能够大幅减少策略配置数量,在最佳情况下可以实现超过99%的减幅;SC2TLE对资源和计算时间要求较高,在大型网络中可能需要几个小时和几百GB的RAM才能求得最佳方案,这意味着这种算法适用于每周/每天主动优化网络,而不适合进行亚秒级优化或在故障场景中实现快速重新优化。
- Computing Power Network: A Testbed and Applications with Edge Intelligence

这篇文章来自本次会议的演示环节(Demo Session)。
1)演示简介:CPN(Computing Power Network,算力网络)作为边缘计算的新发展趋势,有望以智能灵活的方式使用普适计算资源。此演示构建了一个CPN原型测试床,实现了包括计算感知、计算通告、计算建模和计算卸载等使能技术,并使用时延敏感型和计算密集型的智能推理互联网业务评估CPN测试床的性能。
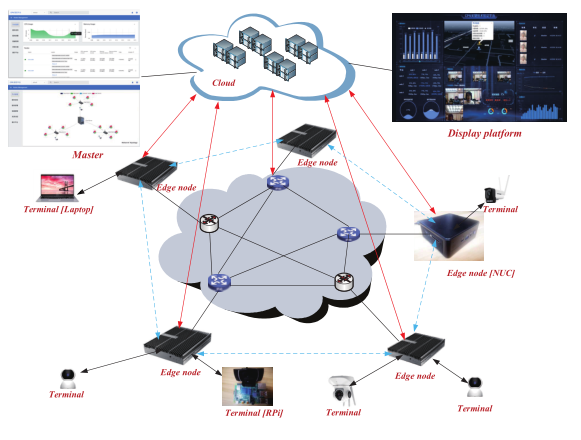
2)架构设计:CPN测试床由三层结构组成:终端、边缘和云。云负责集群管理、监控数据持久性和网络性能指标;边缘负责响应和处理终端的各种边缘智能推理请求。CPN试验床的主要微服务功能有:(1)计算感知:基于Prometheus定期收集每个边缘节点的节点资源和链路质量数据。(2)计算通告:通过ZeroMQ协议和分布式一致性算法,微服务聚合并同步其他边缘节点的计算能力信息。(3)计算建模:利用神经网络模型评估边缘节点为多个边缘智能应用提供的计算能力。(4)计算卸载:以最小响应延迟为优化目标,实现自适应的从请求到边缘节点多对多匹配。

3)实验性能:提出的计算卸载策略不仅比轮询调度策略减少了约25%的响应延迟,而且保持了与轮询调度策略类似的均匀节点负载,比贪婪调度策略要好得多;提出的计算感知策略能够智能地响应网络的动态拓扑,并及时纠正计算卸载的决策结果,在网络质量较差的情况下,测试床仍然可以提供优异的服务性能。
结 语
IEEE INFOCOM为研究人员提供了一个交流各自创新性工作和思考的平台,它不像SIGCOMM或NSDI等其他顶级网络会议那样要求必须兼具基础性贡献、领航性影响和坚实系统背景的工作才能登上展示舞台,而是对各类新颖且有价值的通信网络研究工作都展现出了极强的包容性和激励性。因此INFOCOM收录的文章主题众多,遍布通信网络相关的各个领域方向。本文选取了本届会议中的数据中心网络网内计算性能、视频流用户体验质量、网络功能扩容、分段路由策略这四个主题方向各简要介绍了一项创新性工作。另外,还关注到算力网络这一最早由国内提出的新型网络架构概念,正逐渐发展为全业界备受关注的潜力演进方向并已登上了国际通信网络顶级会议的舞台向全世界科研人员展示。








