

作者:Chaobowx
来源:软硬件融合
编者按
硬件定义软件?还是软件定义硬件?这是个宏大的命题。本文篇幅有限,也自认能力有限,很难完整而准确的把握。只为抛砖引玉,期望能有更多的朋友一起探讨。(期待未来能优化更新本篇文章)
从软件到硬件,从硬件到软件;硬件定义并驱动软件,软件定义并驱动硬件;软硬件系统的发展,是个螺旋上升,不断深化的过程。
未来,随着设计规模逐步扩大,各种处理引擎及其生态持续丰富,软件和硬件,更像是相互博弈相互协同的共生系统,这应该算是“软硬件融合”吧!
软件和硬件
软件和硬件的定义
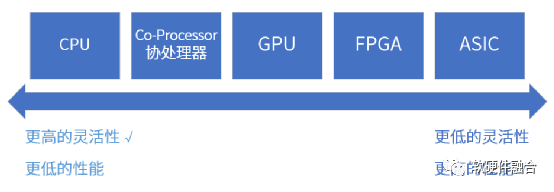
指令是软件和硬件的媒介,指令的复杂度决定了系统的软硬件解耦程度。
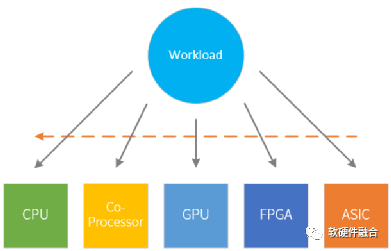
按照单位计算(指令)的复杂度,处理器平台大致分为CPU、协处理器、GPU、FPGA和ASIC。从左往右,单位计算越来越复杂,灵活性越来越低。
任务在CPU运行,则定义为软件运行;任务在协处理器、GPU、FPGA或ASIC运行,则定义为硬件加速运行。
“硬件定义软件”和“软件定义硬件”的定义
软件定义是当前非常热门的话题,比如软件定义网络、软件定义数据中心、软件定义汽车等等。软件定义的范畴非常大,不仅仅涉及到底层的软硬件技术,也涉及到系统的运行管理、监控、更新等,甚至还涉及到商业上的一些考量。
系统是由软件和硬件组成。当我们说软件定义XX的时候,其实说的是软件定义XX系统。本文篇幅有限,从最底层的软件和硬件相关的技术以及两者之间的相互关系和影响来阐述系统中软件定义和硬件定义。
“硬件定义软件”定义为:
- 当一个系统的主要业务逻辑是在硬件中实现,协同的软件是为辅助。
- 相关的软件是依赖于硬件提供的接口构建。
对应的,“软件定义硬件”定义为:
- 当一个系统的主要业务逻辑是在软件中实现;系统中没有硬件引擎,或者硬件引擎是软件可编程的;硬件引擎按照软件编程的逻辑执行操作。
- 相关的硬件依赖于软件提供的接口构建。
CPU,软件和硬件解耦

CPU是最灵活的,原因在于运行于CPU指令都是最基本粒度的加减乘除外加一些访存及控制类指令,就像积木块一样,我们可以随意组合出我们想要的各种形态的功能。
很多人会认为,CPU可以自动的执行非常复杂的计算机程序,这是CPU最大的价值所在。其实不然,CPU最大的价值在于提供并规范了标准化的指令集,使得软件和硬件从此解耦:
- 硬件工程师不需要关心场景,只关注于通过各种“无所不用其极”的方式,快速的提升CPU的性能。
- 而软件工程师,则完全不用考虑硬件的细节,只关注于程序本身。然后有了高级编程语言/编译器、操作系统以及各种系统框架/库的支持,构建起一个庞大的软件生态超级帝国。
在桌面和服务器领域,X86是最流行的处理器架构。而在手机等移动端,ARM则占据绝对的统治地位。开源RISC-v符合未来技术和商业发展的趋势,其在MCU领域已经占据重要地位,并且在向桌面和服务器领域发起冲锋。
软件的庞大生态,是构建在特定的CPU架构之上的。但是,我们一般来说,CPU作为指令足够细粒度,计算足够通用的计算平台,其是软件和硬件解耦的:
- 一方面,特定架构下,每种CPU架构“基本”保证了向前兼容,这样可以认为,在特定架构,软件硬件完全解耦各自发展。
- 另一方面,(理想状态下,)OS、编译器等越来越成熟之后,能够保证,同样的高级语言程序,在不同的CPU架构平台,其运行行为是一致吧。这样就可以脱离具体的CPU架构凭条,构建完全无差别的软件生态。
从长期发展的角度,RISC-v应该会是未来更好的选择:
- 开放性。RISC-v最大的特点是其指令集开源,这样任何厂家就可以根据自己情况设计自己的RISC-v CPU,然后大家共建一套开放的生态,共生共荣。
- 标准化。标准化是最关键的价值。所有的架构(x86/ARM/RISC-v)都可以认为是标准的,但因为RISC-v的开放性,其标准化未来的价值就会非常大。上面说过,“理想”情况下,我们可以把程序无缝的从一个平台迁移到其他平台,但实际上,许多商业的软件,我们并不能拿到源码。而且,许多时候,一些细节问题,都可能导致平台迁移失败。这种迁移对用户来说是非常大的挑战和风险。当标准的RISC-v足够流行之后,基于RISC-v构建的整个生态会迸发强大的生命力。
- 其他。如RISC-v没有历史包袱,指令集更高效;更灵活的扩展能力(确保不碎片化);等等。
CPU的软硬件定义
CPU和软件程序的交互接口是指令集,是最细粒度的加减乘除等指令,像积木块一样,随意组合出任意想要的各种程序。
CPU到底是软件定义还是硬件定义,从不同的角度有不同的看法:
- 软件和硬件并行发展。CPU,通过ISA,“完美”实现了软件和硬件的标准化解耦。因此,可以认为,在这个时候,不存在硬件定义软件或软件定义硬件,软件和硬件各自并行不悖的快速发展。
- 硬件定义软件。基于CPU构建的庞大软件生态,这可以算作是“硬件定义软件”:先有CPU硬件,再有编译器,再有OS、应用等。
- 软件定义系统。但是,站在软件的角度,所有的系统实现均可以通过编程实现,根本不需要考虑运行的CPU平台的“差一些”,因此又可以看做基于CPU运行的系统是“软件定义”的。
硬件定义软件
系统从软件逐步到硬件
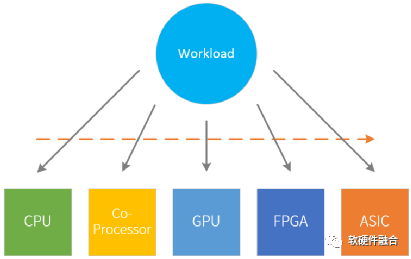
一个系统,必然经过前期快速迭代,后期逐渐稳定的过程。因此,系统运行的处理器平台选择也必然有如下的一些规律:
- CPU通用软件平台:当一个新的应用出现的时候,最早出现的一般是软件实现。一来实现所需要的代价较少,可以快速实现想法;二来CPU所提供的灵活性,不考虑性能的情况下,使之几乎可以处理任何场景的任务。
- 协处理器扩展指令加速平台:随着技术的演进,对性能提出了一些要求。这个时候,可以针对一些比较消耗CPU资源的程序进行一定的编程和编译优化。
- GPU向量及并行加速平台:更进一步的,技术广泛应用,并且我们能从算法中寻找到更多的并行性。这个时候,我们就可以找一些专用的处理器,如GPU、DSP、NPU等,来处理。通过特定的并行优化以及支持向量(SIMD)、多指令并行(MIMD/VLIW)等复杂指令编译优化的方式,深度的优化性能。
- FPGA硬件可编程加速平台:随着技术越来越成熟,应用的规模越来越大。也越来越消耗资源。这个时候,我们值得花费更多的精力,提炼出复杂度非常高的算法(或者可以当作一个非常复杂的“指令”)然后通过硬件逻辑实现。再通过FPGA硬件可编程的方式快速落地。
- ASIC定制加速平台:再进一步的,技术更加成熟稳定,应用规模足够庞大,这个时候就非常有必要为此场景定制开发ASIC,来达到最优的性能、最低的成本、最小的功耗。
当需要面向一个新领域开发的时候,要快速实现,或者应用的场景不够确定,需要硬件平台有足够多的适应性,这些情况使用CPU比较合适。当需要极致的效率,并且成本敏感、功耗敏感,而且规模足够庞大,那么选择定制开发ASIC会更合适一些。如果折中的,需要有一定的灵活性,又要保证一定的性能加速,并且应用有足够的并行度,这个时候GPU则更合适一些。
从软件到硬件的一个经典的例子就是比特币,其激烈而快速的完成了从CPU到ASIC的过渡。比特币使用的技术区块链核心算法是SHA-256,它在各个平台上的性能对比如下:
- CPU:最开始的时候,大家使用CPU挖矿,一台高端个人电脑,处理速度大概20MH/s(H/s, Hash per second);
- GPU:后来有人用GPU加速挖矿,SHA-256可以继续拆分成普通的算术逻辑运算,而GPU具有超级多的算术逻辑运算单元,一个高端显卡的处理速度可以达到200MH/s;
- FPGA:再后来出现了定制SHA-256算法硬件逻辑的FPGA加速卡来挖矿,精心设计的定制电路的FPGA,可以使运算速度达到1GH/s;
- ASIC:而比特大陆公司2015年发布的ASIC矿机芯片BM1385,其性能达到单颗芯片算力可达32.5GH/s。
上述CPU、GPU、FPGA性能数据来自于《区块链:技术驱动金融》,数据为2013年前后的性能数据。
硬件架构决定了软件设计
1)ASIC的硬件定义

SOC是CPU、GPU、各种加速处理引擎(ASIC)以及接口模块(ASIC)的集成。
智能手机使用电池供电,同时又要提供足够强大的性能。如此苛刻的应用条件,使得智能手机处理器通常都选用集成度非常高的SOC。上图是高通手机SOC处理器骁龙810芯片,可以看到此芯片主要包括:
- 通用CPU:ARM Cortex-A57和Cortex-A53,CPU主要用于运行Android等智能手机操作系统以及APP程序;
- 特定场景处理器:Adreno 430 GPU、Hexagon DSP、ISP、多媒体处理器等,GPU主要用于3D游戏等场景,DSP主要用于传感器算法处理;
- 特定功能子系统:支持4G LTE的通信基带处理、GPS/北斗等的定位模块等;
- WiFi、USB、蓝牙等连接模块;
- 安全处理模块;
- 其他一些外围模块。
于是,手机系统就形成了如下表格的分层:

2)GPU的硬件定义

GPU由数以千计的CUDA核组成,要想对数以千计的CPU内核进行编程,把这么多核的计算性能发挥出来,是非常大的挑战。
GPU编程有一个最重要的约束是在同一个并行线程组里运行的是相同的程序,也称之为“齐头并进”。即使如此,GPU的编程难度依然相当的大。
于是,为了提升GPU编程易用性和快捷性的CUDA编程框架应运而生了。
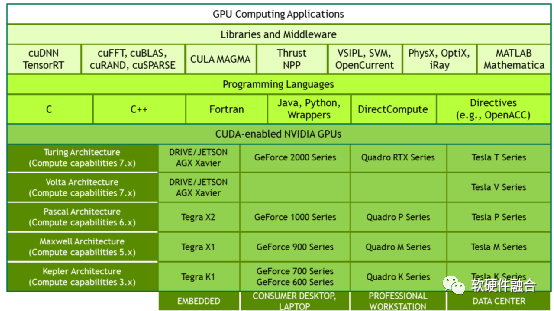
2006年NVIDIA推出了CUDA,这是一个通用的并行计算平台和编程模型,利用NVIDIA GPU中的并行计算引擎,以一种比CPU更高效的方式解决许多复杂的计算问题。CUDA提供了开发者使用C++作为高级编程语言的软件环境。也支持其他语言、应用程序编程接口或基于指令的方法,如FORTRAN、DirectCompute、OpenACC。
CUDA是NVIDIA成功的关键,它极大的降低了用户基于GPU并行编程的门槛,在此基础上,还针对不同场景构建了功能强大的开发库和中间件,逐步建立了GPU+CUDA的强大生态。
总结
1)系统业务逻辑的实现形式,决定了软硬件定义
三类典型的平台:
- CPU,因为是完全细粒度的指令,可以非常灵活的组织出来想要的程序。
- ASIC,ASIC是把系统的业务逻辑固化到硬件中。优势在于,完全定制ASIC实现了最精简的晶体管资源占用,实现最极致的性能。当一个系统功能非常固定,并且未来也不会有非常频繁的更新的情况下,ASIC是几乎最优的选择。
- GPU,则介于CPU和ASIC之间,具有一定性能的同时,具有一定的灵活性。
根据系统业务逻辑的具体实现:
- CPU是一个完全灵活无约束的可编程平台,系统运行于CPU,则说系统是完全软件定义的。也既是说,可以通过软件编程的方式,完全自由的定义自己需要的系统业务逻辑。
- 系统运行于ASIC,则说系统是完全硬件定义的。也即是说,ASIC的整个系统逻辑都是硬件写死的,软件只是一些简单的初始化配置和运行控制。
- GPU,则是介于软件定义和硬件定义之间。
2)软件依赖于硬件平台而存在
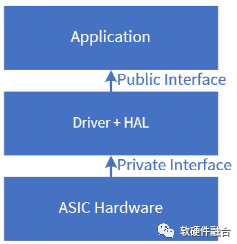
ASIC实现的是整个SOC大系统中的一个子系统,整个子系统的业务逻辑基本上是在ASIC模块硬件中完成(有时候需要控制面软件来控制ASIC模块的运行),因此,其性能相对CPU和GPU较高。
当我们设计一个ASIC硬件模块或加速器的时候,需要提供相应的驱动,如果是要接入OS等标准接口,还需要有一层HAL层负责把不同接口映射到OS的标准接口。应用程序根据ASIC硬件提供的功能接口使用硬件。
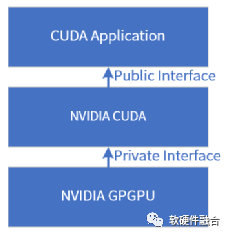
GPU平台,硬件的GPGPU提供接口给CUDA,CUDA再提供接口给应用。每一代具体的GPU,给上层提供的是不同的访问接口, CUDA框架有特定的驱动和HAL屏蔽不同GPU的实现细节;并且CUDA为了向前兼容和维护生态,最终映射到标准的库。这些标准的库,提供了标准的接口给上层的CUDA应用程序。
即使CUDA映射成标准的库API接口,CUDA程序依然是要依赖于CUDA提供的接口来设计应用软件。

总结一下,软件依赖于硬件平台存在,体现在两个方面:
- 软件只能根据硬件提供的功能来完成系统实现,系统的业务逻辑是在硬件实现;
- 软件依赖硬件提供的接口访问硬件,硬件提供什么样的接口,软件就使用什么样的接口,主动权在硬件。
软件定义硬件
系统又开始从硬件逐步到软件
上一节我们讲到,系统从起始发展,到逐步稳定,系统的运行平台逐步从CPU演进到ASIC。那么,ASIC是不是所有系统最终的运行平台?
答案是否定的。原因主要如下:
- 软件更新换代很快。新的热点技术层出不穷,已有的技术领域的更新迭代速度仍在快速增加。硬件的迭代周期过长,无法跟上软件迭代的节奏。
- 定制的ASIC设计,把所有功能都在硬件实现。在复杂的云计算、自动驾驶等场景,芯片公司对用户的场景理解可能不够深入,会导致设计偏差。另一方面,也会限制用户自身的主观能动性,让用户有想法也很难在ASIC平台去实现自己想要的功能。
- ASIC因为功能固定,为了适配更多场景,确保芯片的大量出货,势必需要实现功能超集。例如,某ASIC芯片支持10个功能,但实际用户场景,都是只需要2-3种功能。这样,ASIC实现实际上也是低效的。并且,这些功能因为紧耦合的缘故,系统复杂度反而更高。
这样,在许多场景,我们根据实际的场景需求,除ASIC,也开始选择DSA、FPGA、GPU甚至CPU等处理引擎。
软件定义网络
最典型的一个案例就是SDN(Software Defined Network)的发展。经过几十年的发展,网络芯片已经演进到了完全ASIC的实现,这意味着基于ASIC芯片的网络设备其功能是确定的,用户只能根据厂家实现的确定功能来使用网络设备。
然而,随着云计算、4G/5G移动通信等的发展,新的网络协议和网络功能层出不穷,纯ASIC实现的网络系统遇到了挑战。

如上图所示,IETF(Internet Engineering Task Force,互联网工程任务组)的RFC(Request for Comments,请求意见稿,即网络协议)数量一直在爆炸式的增长,应用于各种新型网络场景的新协议层出不穷。但是,传统的网络处理芯片都是封闭的、特定的设计,用于特定协议处理。想要增加新的协议非常困难,并且对新协议的支持受到不同供应商的约束。定制的网络处理芯片,对新协议的支持不足以及缺乏有效的灵活性,这使得要想在网络系统增加新的功能非常困难,限制了客户的网络创新能力。
客户希望能够快速便捷的对网络进行配置和管理;客户希望能够快速的进行网络协议创新。这样,ASIC的功能固定越来越成为网络创新的约束。于是,SDN开始了两个方面的创新:
- 第一步,网络控制面和数据面分离,控制面可编程。把网络控制面从数据面分离处理,形成了控制面可编程的Openflow协议。
- 第二步,进一步的,网络数据面也可以编程,用户可以定义自己的协议。形成了数据面可编程的P4语言和P4交换机相继出现。
1)运行于CPU的软件虚拟交换机
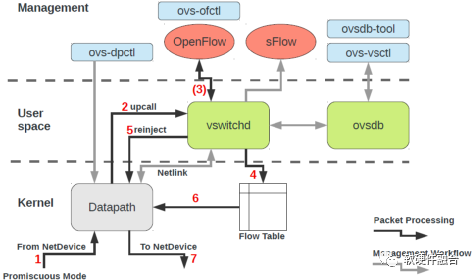
OVS(Open Virtual Switch)是Apache 2许可下的开源的软件交换机。OVS的目标是实现一个生产环境的交换机平台,支持标准管理界面,并为程序扩展和控制开放转发功能。OVS非常适合在VM环境中用作虚拟交换机,除了向虚拟网络层公开标准控制和可见性接口之外,它还旨在支持跨多个物理服务器的分发。OVS支持多种基于Linux的虚拟化平台,包括Xen、KVM等。
最新的OVS版本支持以下功能:
- 具有主干和接入端口的标准的802.1Q VLAN模型;
- NIC绑定在上行交换机上,可以支持LACP也可以不支持;
- 通过NetFlow,sFlow(R)和镜像来增强可视性;
- QoS(服务质量)配置以及策略;
- Geneve, GRE, VxLAN, STT和LISP隧道;
- 802.1ag连接故障管理;
- OpenFlow 1.0以及众多扩展;
- 支持C和Python的事务配置数据库;
- 基于Linux内核的高性能转发模块。
如图,OVS答题可以分为三层:
- 管理层,即:ovs-dpctl、ovs-vsctl、ovs-ofctl、ovsdb-tool。
- 业务逻辑层,即:vswitchd、ovsdb。
- 数据处理层,即:datapath。
2)数据面可编程的网络交换机DSA
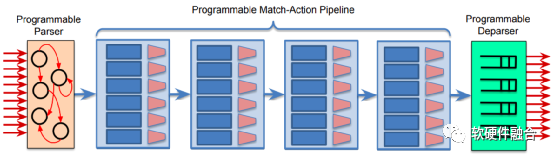
上图为PISA(Protocol Independent Switch Architecture,协议无关的交换架构)架构交换机的流水线,PISA是一种支持P4数据面可编程包处理的流水线引擎架构,通过可编程的解析器、多阶段的可编程的匹配动作以及可编程的逆解析器组成的流水线,来实现数据面的编程。这样可以通过编写P4程序,下载到处理器流水线,可以非常方便的支持新协议的处理。
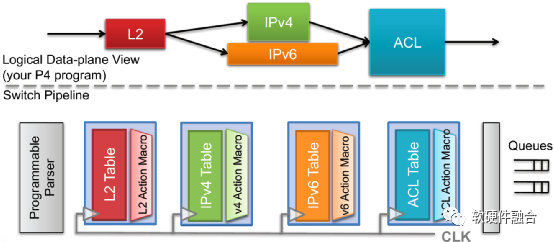
当实现了完全可编程的流水线之后,在P4工具链的支持下,就可以通过P4编程的方式来实现自定义的流水线,来达到对自定义协议的支持。
如图所示,P4定义的Parser程序会被映射到可编程的解析器,数据、包头定义、表以及控制流会被映射到多个匹配动作阶段。图 6.25中把L2处理、IPv4处理、IPv6处理以及访问控制处理分别映射到不同的匹配动作处理单元进行串行或并行的处理,来实现完整的支持各种协议的网络包处理。
软件定义接口:Virtio
Virtio旨在提供一套高效的、良好维护的通用的Linux驱动,实现虚拟机应用和不同Hypervisor实现的模拟设备之间标准化的接口。Virtio作为类虚拟化的I/O设备接口,广泛应用于云计算虚拟化场景,某种程度上,Virtio已经成为事实上的I/O设备的接口标准。
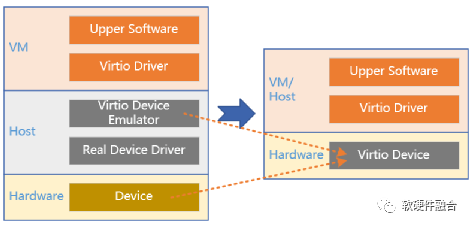
因为软件定义了标准化的Virtio接口,因此,如上图所示,在SmartNIC和DPU中,offload虚拟化和Workload的最关键部分就是要把Virtio硬件化。
如上图所示,站在虚拟化角度,把Virtio卸载,可以看做是从软件到硬件。但是,如果从硬件接口的角度,从一个完全硬件定义的接口(例如NV自定义的SR-IOV接口)过渡到软件定义的接口(Virtio接口),则可以算是从硬件到软件。
可跨平台的软件定义:Intel oneAPI

英特尔oneAPI是一个开放、可访问且基于标准的编程系统,支持开发人员跨多种硬件架构参与和创新,包括 CPU、GPU、FPGA、AI 加速器等。这些处理引擎具有非常不同的属性,因此用于各种不同的处理——oneAPI试图通过将它们统一在同一个模型下来简化这些操作。
即使在今天,开发人员面临的一个持续问题是我们日益数字化的世界提供的编程环境的数量。不同的编程环境使代码重用等节省时间的策略失效,并成为软件开发人员的真正障碍。作为其软件优先战略的一部分,英特尔在 2019 年的超级计算活动中推出了oneAPI。该模型标志着英特尔的雄心是拥有统一的编程框架作为限制专有编程平台的解决方案。oneAPI 使开发人员能够在不厌倦使用不同语言、工具、库和不同硬件的情况下工作。
Intel oneAPI可以实现:设计一套应用,根据需要,非常方便的把程序映射到CPU、GPU、FPGA或者AI-DSA/其他DSA等不同的处理器平台。
扩展:软件定义“一切”
软件定义是一个非常宏大并且非常热点的话题,除了软件定义网络之外,还有很多软件定义的热点领域:
- 软件定义存储,是一种能将存储软件与硬件分隔开的存储架构。不同于传统的网络附加存储(NAS)或存储区域网络(SAN)系统,SDS一般都在行业标准系统上执行,从而消除了软件对于专有硬件的依赖性。
- 软件定义数据中心,把数据中心基础设施通过抽象化、资源池化以及自动化来实现基础设施即服务(IAAS)。软件定义的基础设施可让IT管理员使用软件定义的模板和API轻松配置和管理物理基础设施,以定义基础设施配置和生命周期运维,并实现自动化。
- 软件定义无线电,是一种无线电广播通信技术,它基于软件定义的无线通信协议而非通过硬连线实现。频带、空中接口协议和功能可通过软件下载和更新来升级,而不用完全更换硬件。
- 软件定义汽车,通过软件实现新的车载体验和功能,并通过无线 (OTA) 提供更新和服务。从而使得汽车从高度机电一体化的机械终端,逐步转变为一个智能化、可拓展、可持续迭代升级的移动电子终端。
软件定义存储和软件定义无线电还主要是技术的范畴,而软件定义数据中心和软件定义汽车,则是把软件定义的思路和理念更加深化和拓展,应用于更广阔的领域。
软硬件相互定义
软件定义也存在一些挑战
1)基于CPU的摩尔定律失效
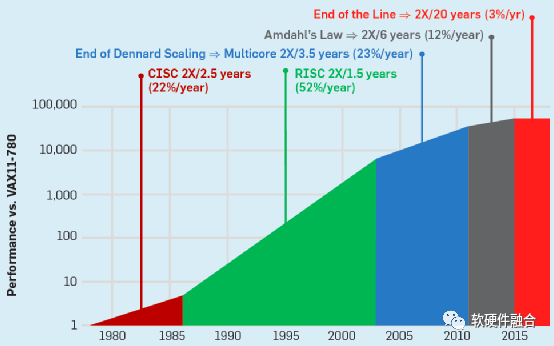
软件定义XX,最本质的做法还是把整个系统重新从硬件实现变成偏软件的实现。随着这势必对CPU的性能提出了更高的要求。
然而,如上图所示,随着CPU的性能提升逐渐停滞,已经无法满足数字经济时代对算力持续提升的要求。
因此,还是要再轮回,“硬件”加速。
2)DSA只解决了部分问题
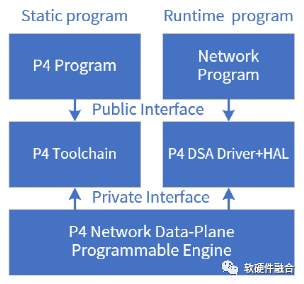
支持P4的网络数据面可编程引擎,属于DSA的范畴,专门用于网络包处理的加速,性能跟ASIC相当,但其具有非常好的软件可编程能力。
标准的P4程序,有P4前端编译器把P4程序编译成一个中间态的程序(类似Java编译器)。然后特定硬件实现的后端编译器负责把中间态的程序映射到具体的硬件实现(有点像Java虚拟机,但P4是静态)。
P4 DSA引擎预先配置好P4程序之后,P4-DSA就成了执行特定协议处理的网络包处理引擎。然后需要和已有的网络程序进行适配,实现网络任务的数据面offload。
P4的整个系统栈跟之前CPU、GPU、ASIC最大的不同在于先定义了标准的P4,然后各厂家根据标准的P4去实现各自不同的P4处理引擎。

CPU虽然现在有三大架构(x86、ARM和RISC-v),但就具体的架构而言,其定义的ISA是非常明确的。特别是在RISC-v生态下,大家遵循一致的ISA,已有的程序可以非常方便的在不同Vendor的RISC-v CPU上运行。
但是在DSA领域,目前还看不到这一点。
可以说,当前所有的DSA,包括P4 DSA,都还没有实现接口的软件定义,接口依然是硬件定义的,可以说是不完全的软件定义XX。
更理想的跨平台框架
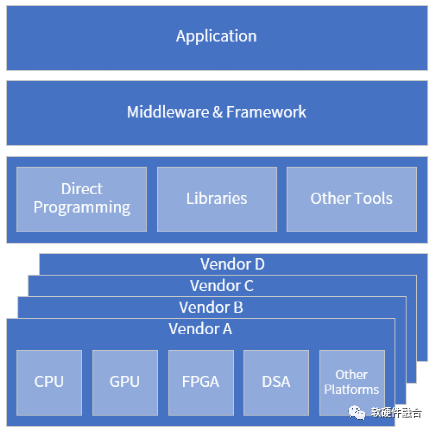
我们把oneAPI模型框架再增强一下,如上图所示。这样,跨平台,不仅仅是在CPU、GPU、FPGA和DSA的跨平台,更在于是不同Vendor的不同处理器的跨平台。
接口的软硬件互相定义

不管是软件定义硬件还是硬件定义软件,接口(这里接口是泛指,ISA是接口,IO设备的数据访问接口也是接口,GPU等加速器呈现的访问接口也是接口)都是非常关键的角色,因为是通过接口给对方呈现自己的功能和如何访问。
我们来总结一下软硬件之间的接口类型:
- 第一类,定义好硬件,软件依赖于硬件而定义。通常都是这样,CPU、GPU、ASIC等等,都是这种接口定义。
- 第二类,软件定义的情况下,现有软件,硬件设计要进行适配。比如,Virtio的硬化,比如要兼容OVS的TC-Flower/RTE-flow接口等。
- 第三类,软件定义和硬件定义各自的接口,然后中间通过转换层适配。比如,通过HAL层把硬件驱动适配到OS;例如高级语言程序通过编译器生产特定处理器架构的Binary程序。
- 第四类,软件定义,并且跨越软硬件的接口也是软件定义的,但是在硬件里有一层转换层。比如,前面提到的Virtio接口,在很多解决方案里的具体实现是在硬件侧的嵌入式软件里,这样,软件模拟的Virtio成为性能的瓶颈。
- 第五类,软件定义,并且跨越软硬件的接口也是软件定义的,硬件直接实现的软件定义接口。原生支持软件定义接口。硬件不仅仅要实现自己的编程范式,还需要把编程范式映射到标准接口的能力。
总结
“硬件定义软件”是传统的思路。新的技术发展很快,已有的技术仍在快速迭代;而硬件系统越来越复杂,更新迭代也越来越慢。系统如果是硬件为主,软件依赖于硬件。则势必限制技术的快速发展。
“软件定义硬件”代表了一种趋势:要从系统层次,主动的来定义个体的硬件。但“软件定义硬件”的描述更多的强调系统,容易忽略个体的特点。站在系统层面,可以“站得高,看得远”,代表了宏观的、整体的思考,能够更好的资源统筹,更好的定义系统功能。而站在个体的层面,个体是本源,代表了事物本质的特征。事物受客观规律的约束,具有特定的发展规律。并且,个体具有差异化,如何更好的体现这些差异化优势,是系统持续不断创新的本源驱动。
“软件和硬件相互定义”,可以更好的协同系统和个体的关系,既能够实现软件定义的宏观统筹,又能够兼顾硬件个体的特点和优势,把两者有机的结合起来,实现软硬件更加协同的更优的系统。
(全文完)








