

作者:陈乐
来源:华为产品资料
随着 5G、大数据、物联网、AI 等新技术融入人类社会的方方面面,可以预见,在未来二三十年间人类将迈入基于数字世界的万物感知、万物互联、万物智能的智能社会。数据中心算力成为新的生产力,数据中心量纲也从原有的资源规模向算力规模转变,算力中心的概念被业界广泛接受。数据中心向算力中心演进,网络是数据中心大算力的重要组成部分,提升网络性能,可显著改进数据中心算力能效比。
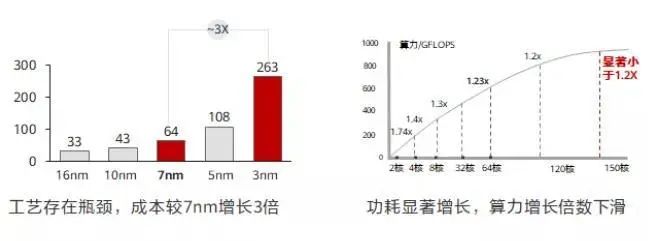
为了提升算力,业界在多条路径上持续演进。单核芯片的工艺提升目前止步于3nm;通过叠加多核提升算力,随着核数的增加,单位算力功耗也会显著增长,当128 核增至 256 核时,总算力水平无法提升 1.2 倍。计算单元的工艺演进已经逼近基线,每 18 个月翻一番的摩尔定律即将失效,为了满足大算力的需求,HPC 高性能计算成为常态。随着算力需求的不断增长,从 P 级向 E 级演进,计算集群规模不断扩大,对互联网络性能要求越来越高,计算和网络深度融合成为趋势。
HPC(高性能计算)是指利用聚集起来的计算能力来处理标准工作站无法完成的科研、工业界最复杂的科学计算问题,包括仿真、建模和渲染等。由于需要大量的运算,一台通用计算机无法在合理的时间内完成工作,或者由于所需的数据量过大而可用的资源有限,导致根本无法执行计算,此时一种方式是通过使用专门或高端的硬件进行处理,但其性能往往依然很难达到要求同时较为昂贵。目前业界使用较多的方式是将多个单元的计算能力进行整合,将数据和运算相应地分布到多个单元中,从而有效地克服这些限制。
HPC 高性能计算的计算节点之间交互对网络性能的要求也是不同的,大致可以分为三类典型场景:
松耦合计算场景:在松耦合场景中,计算节点之间对于彼此信息的相互依赖程度较低,网络性能要求相对较低。一般金融风险评估、遥感与测绘、分子动力学等业务属于松耦合场景。该场景对于网络性能要求相对较低。
紧耦合场景:紧耦合场景中,对于各计算节点间彼此工作的协调、计算的同步以及信息的高速传输有很强的依赖性。一般电磁仿真、流体动力学和汽车碰撞等场景属于紧耦合场景。该场景对网络时延要求极高,需要提供低时延网络。
数据密集型计算场景:在数据密集型计算场景中,其特点是计算节点需要处理大量的数据,并在计算过程中产生大量的中间数据。一般气象预报、基因测序、图形渲染和能源勘探等属于数据密集型计算场景。由于该场景下计算节点处理大量数据的同时又产生了大量中间数据,所以该场景要求提供高吞吐的网络,同时对于网络时延也有一定要求。
总结一下 HPC 高性能计算对网络的诉求,高吞吐和低时延成为两个重要的关键词。同时为了实现高吞吐和低时延,业界一般采用了 RDMA(Remote Direct Memory Access,远程直接内存访问)替代了 TCP 协议,实现时延的下降和降低对服务器 CPU 的占用率。但 RDMA 协议对网络丢包非常敏感,0.01 的丢包率就会使RDMA 吞吐率下降为 0,所以无损就成为网络的重要需求之一。
从TCP 到 RDMA
传统的数据中心通常采用以太网技术组成多跳对称的网络架构,使用 TCP/IP 网络协议栈进行传输。但 TCP/IP 网络通信逐渐不适应高性能计算业务诉求,其主要限制有以下两点:
限制一:TCP/IP 协议栈处理带来数十微秒的时延
TCP 协议栈在接收/发送报文时,内核需要做多次上下文切换,每次切换需要耗费 5~10us 左右的时延,另外还需要至少三次的数据拷贝和依赖 CPU 进行协议封装,这导致仅仅协议栈处理就带来数十微秒的固定时延,使得在 AI 数据运算和SSD 分布式存储等微秒级系统中,协议栈时延成为最明显的瓶颈。
限制二:TCP 协议栈处理导致服务器 CPU 负载居高不下
除了固定时延较长问题,TCP/IP 网络需要主机 CPU 多次参与协议栈内存拷贝。网络规模越大,网络带宽越高,CPU 在收发数据时的调度负担越大,导致 CPU持续高负载。按照业界测算数据:每传输 1bit 数据需要耗费 1Hz 的 CPU,那么当网络带宽达到 25G 以上(满载),对于绝大多数服务器来说,至少 1 半的 CPU能力将不得不用来传输数据。
为了降低网络时延和 CPU 占用率,服务器端产生了 RDMA 功能。RDMA 是一种直接内存访问技术,他将数据直接从一台计算机的内存传输到另一台计算机,数据从一个系统快速移动到远程系统存储器中,无需双方操作系统的介入,不需要经过处理器耗时的处理,最终达到高带宽、低时延和低资源占用率的效果。
从IB 到 RoCE
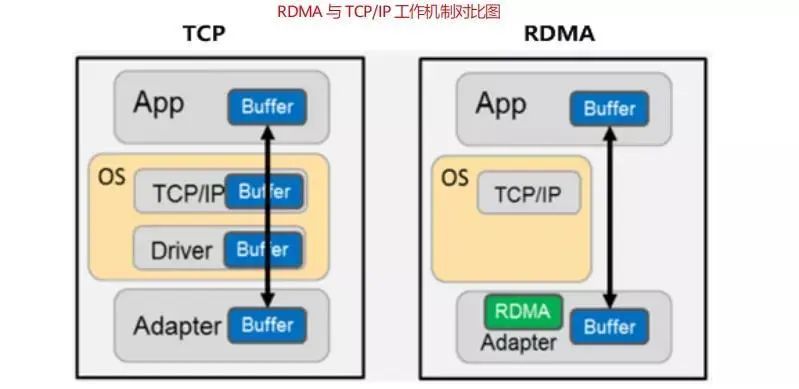
如下图所示,RDMA 的内核旁路机制允许应用与网卡之间的直接数据读写,规避了 TCP/IP 的限制,将协议栈时延降低到接近 1us;同时,RDMA 的内存零拷贝机制,允许接收端直接从发送端的内存读取数据,极大的减少了 CPU 的负担,提升CPU 的效率。
举例来说,40Gbps 的 TCP/IP 流能耗尽主流服务器的所有 CPU 资源;而在使用 RDMA 的 40Gbps 场景下,CPU 占用率从 100%下降到 5%,网络时延从ms 级降低到 10μs 以下。
目前RDMA 的网络层协议有三种选择。分别是 InfiniBand、iWarp(internet Wide Area RDMA Protocol)、RoCE(RDMA over Converged Ethernet)。
InfiniBand 是一种专为 RDMA 设计的网络协议,由 IBTA(InfiniBand Trade Association)提出,从硬件级别保证了网络无损,具有极高的吞吐量和极低的延迟。但是 InfiniBand 交换机是特定厂家提供的专用产品,采用私有协议,而绝大多数现网都采用 IP 以太网络,采用 InfiniBand 无法满足互通性需求。同时封闭架构也存在厂商锁定的问题,对于未来需要大规模弹性扩展的业务系统,如果被一个厂商锁定则风险不可控。
iWarp,一个允许在 TCP 上执行 RDMA 的网络协议,需要支持 iWarp 的特殊网卡,支持在标准以太网交换机上使用 RDMA。但是由于 TCP 协议的限制,其性能上丢失了绝大部分 RDMA 协议的优势。
RoCE,允许应用通过以太网实现远程内存访问的网络协议,也是由 IBTA 提出,是将 RDMA 技术运用到以太网上的协议。同样支持在标准以太网交换机上使用RDMA,只需要支持 RoCE 的特殊网卡,网络硬件侧无要求。目前 RoCE 有两个协议版本,RoCEv1 和 RoCEv2:RoCEv1 是一种链路层协议,允许在同一个广播域下的任意两台主机直接访问;RoCEv2 是一种网络层协议,可以实现路由功能,允许不同广播域下的主机通过三层访问,是基于 UDP 协议封装的。但由于RDMA 对丢包敏感的特点,而传统以太网又是尽力而为存在丢包问题,所以需要交换机支持无损以太网。

比较这三种技术,iWarp 由于其失去了最重要的 RDMA 的性能优势,已经逐渐被业界所抛弃。
InfiniBand 的性能最好,但是由于 InfiniBand 作为专用的网络技术,无法继承用户在 IP 网络上运维的积累和平台,企业引入 InfiniBand 需要重新招聘专人的运维人员,而且当前 InfiniBand 只有很少的市场空间(不到以太网的 1%),业内有经验的运维人员严重缺乏,网络一旦出现故障,甚至无法及时修复,OPEX 极高。因此基于传统的以太网络来承载 RDMA,也是 RDMA 大规模应用的必然。为了保障 RDMA 的性能和网络层的通信,使用 RoCEv2 承载高性能分布式应用已经成为一种趋势。
然而上文我们说过,RDMA 对于丢包是非常敏感的。TCP 协议丢包重传是大家都熟悉的机制,TCP 丢包重传是精确重传,发生重传时会去除接收端已接收到的报文,减少不必要的重传,做到丢哪个报文重传哪个。然而 RDMA 协议中,每次出现丢包,都会导致整个 message 的所有报文都重传。另外,RoCEv2 是基于无连接协议的UDP 协议,相比面向连接的 TCP 协议,UDP 协议更加快速、占用 CPU 资源更少,但其不像 TCP 协议那样有滑动窗口、确认应答等机制来实现可靠传输,一旦出现丢包,RoCEv2 需要依靠上层应用检查到了再做重传,会大大降低 RDMA 的传输效率。
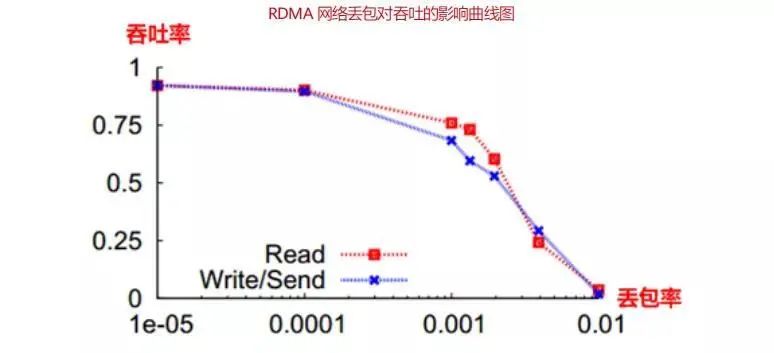
因此 RDMA 在无损状态下可以满速率传输,而一旦发生丢包重传,性能会急剧下降。大于 0.001 的丢包率,将导致网络有效吞吐急剧下降。0.01 的丢包率即使得 RDMA 的吞吐率下降为 0,要使得 RDMA 吞吐不受影响,丢包率必须保证在 1e-05(十万分之一)以下,最好为零丢包。
RoCEv2 是将 RDMA 运行在传统以太网上,传统以太网是尽力而为的传输模式,无法做到零丢包,所以为了保证 RDMA 网络的高吞吐低时延,需要交换机支持无损以太网技术。








