

如今,分布式计算变得越来越分散,甚至有的人觉得它是混乱的。随着网络的发展,数据中心的网络结构已经成为决定应用程序是否能良好运行的最重要因素。如果数十台或数百台服务器在数据中心之间进行通信时,速度不可预测,带宽不够大,不能接收和发送数据,延迟还高,那么这些服务器将没有存在的意义。

因此,创建网络成了棘手的事情。就像当年Facebook一样,Facebook有一个巨大的分布式PHP应用程序(其中包含大量机器学习)——它可以将23亿用户通过全球15个数据中心的数百万台服务器连接在一起,并且该网络会随着时间的推移而发展,以满足社交网络业务所需的性能、弹性和成本目标。在10Gb/s和40Gb/s的以太网中,网络一直是Facebook整体IT预算中增长最快的部分,其主要原因是交换机ASIC上的带宽和端口计数都受到了限制,而不仅仅是带宽。但随着商用市场上最新一代的交换机ASIC的出现,端口数量和每个端口的带宽都呈上升趋势,Facebook现在有一个前所未有的机会来调整其网络,从根本上削减成本,并且可以拥有很多比上一代交换机更好的性能。
正如我们之前所指出的,数据中心成本的增加关键不在于带宽,而在于早期的100 GB/s交换机散热性能不好,价格昂贵,并且受端口限制。200 GB/s或400 GB/s端口的交换机ASIC的出现意味着每个交换机的端口数量可以比早期的100 GB/s交换机增加一倍到四倍,大企业无需在管道方面投入更多,只需减少网络层数和架构跳数,同时仍能在单个架构中跨越10万台服务器和存储服务器。
这种带宽的高基数使用——只是一个有趣的说法,交换机制造商利用芯片组进步所带来的额外带宽,使更多的端口能够以设定的速度运行。一年多前Broadcom宣布其“Tomahawk-3”StratusXGS ASIC,它可支持32个以400Gb/s运行的端口或128个以100Gb/s运行的端口。去年10月,Arista Networks 推出了基于Tomahawk-3的7060X交换机。
当时,Tomahawk-3的高基数实现还停留在理论上,但在圣何塞举行的OCP全球峰会上,Facebook展示了它是如何将该理论应用于下一代交换机(Minipack)以及与之协同工作的F16架构。
Facebook于2011年在Prineville开设了第一个数据中心时,它拥有定制的服务器和存储设备,并且仍在服务器机架和商用模块化交换机顶部使用商用固定端口交换机。当时街头巷尾都在说,Arista和思科系统公司当时是交换机的主要供应商,然而这些交换机并不便宜,因此当时网络支出在整个数据中心成本的占比高达25%并很快升至30%。如此高的成本在Facebook所需的规模上是不可接受的,更糟糕的是,在HPC中心或大型企业也会采用相同的方法构建网络。随后Clos叶脊网络从超大规模中脱颖而出,成为数据中心网络的主流架构。适合在超大规模数据中心中跨越10万台服务器的交换机和结构设计非常重要,它可以将数百、数千或数万台服务器捆绑在一起,并且能节省大量成本。
在最初的Facebook拓扑结构中,由四个集群交换机组成的pod是交叉耦合的,将一组服务器机架连接在一起,这就是那些商业核心交换机可拓展的管理域(我们不知道它们有多少端口),这限制了服务器pod的大小,从而限制了跨系统分配工作负载的方式。由于服务器之间的东西向流量占据了网络流量的主导地位,因此跳过pod会为应用程序增加不可接受的延迟,Facebook必须对应用程序进行分区并将它们分配到pod中。最好有一个可以跨整个数据中心的网络,从而将所有的计算服务器和存储服务器连接到一起,并且可以轻松地在一个区域内聚合数据中心。
早在2014年,新的F16架构推出之前,Facebook就在爱荷华州阿尔图纳(Altoona)首次推出了F4数据中心架构(Data Center fabric),但其如今已被弃用,被称为Classic Fabric。当时,Facebook在区域内和区域间跨数据中心的网络主干使用100 Gb/s的交换机,在叶脊层使用40 Gb/s的网络,连接到支持其应用程序的服务器和存储服务器。
2014年,Facebook首次开发了自己的交换机硬件:Wedge架顶(leaf)交换机和6-pack core/spine交换机。Wedge交换机有16个端口,运行速度为40Gb/s,外加一个“Group Hug”微服务器,6-pack模块化交换机在模块化系统中有12个Wedge板,其中八个为Wedge leaf交换机,提供128个下行链路,四个用于在spine交换机的Wedge模块之间创建后端非阻塞结构。使用Classic Fabric的基本网络连接是由四个主干交换机组成的群集,连接到一系列48个leaf交换机,在pod的leaf交换机之间创建许多路径,在spine交换机中有足够的额外端口跳过pod。正是这种硬件为Classic Fabric提供了基础,将Facebook数据中心中的所有服务器相互链接。以下是Classic Fabric的样子:

四个独立的spine平面,一个平面均可扩展至48台设备,而每个pod的每一台光纤交换机都会与所在平面的每一台骨干交换机互联。于是这些pod和plane就构成了一个模块化的网络拓扑,从而可以容纳几十万台10G带宽的服务器,整个数据网络的对分带宽最高可扩展至几个PB。同样(图中可能看不明显),该结构具有边缘网络pod,能够为Facebook使用的路由器主干提供7.68 Tb/s的带宽,以保证其区域间的连接、用户到数据中心的连接,以及区域内的数据中心间通信。
两年后,Facebook在2016年初推出了100Gb/s ASIC的Wedge 100 leaf交换机,并在2016年底推出了Backpack spine,这是Wedge 100的模块化版本,就像6-Pack spine交换机和Wedge 40。在这种情况下,有八个Wedge 100用作线卡,四个用作交换机内部的非阻塞结构,提供128个非阻塞端口,每个spine交换机以100 Gb/秒运行。Facebook已经逐渐在全球范围内将6-Pack交换机替换为Backpack交换机,并将Wedge 40s替换为Wedge 100s,但Classic Fabric的基本结构到目前为止还没有改变。
随着F16结构在Facebook数据中心的推出,Classic Fabric顶部和底部的压力不断增加,以及Facebook在特定区域内托管的数据中心的数量的增长,网络正在急剧扩张。在结构的最底层,应用程序利用需要高数据速率的视频和其他服务,带宽需求不断增加,再加上Facebook希望将一个地区由三个数据中心扩展到六个数据中心,顶层面临着许多压力。(完全加载,这意味着Facebook目前的15个数据中心理论上要容纳900万台服务器。)
在设计其Minipack spine交换机和使用F16结构时,Facebook做出了一个重要的决定,没有在结构上切换到400 Gb/s端口,因为光学电缆会消耗过多的功率,且不能够快速降低以防止网络的更多消耗。因此,Facebook决定在设备上保留100 Gb/s的端口,使用已建立的CWDM4-OCP光学系统,而不是将整个结构中的端口数量增加四倍,从而使进出机架的带宽翻两番。这很有趣,并再一次表明了,超级计算机总是能够寻求性能和成本之间的平衡,而不是像高性能计算中心和性能级超级计算机经常做的那样不惜任何代价地寻求性能。
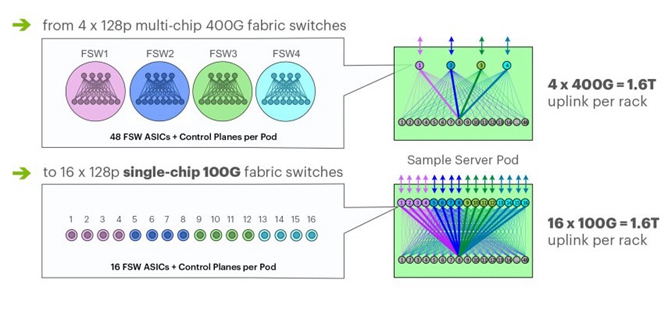
这一选择带来了许多积极影响,使得网络更简单、更扁平化、成本更低。新的F16网络可以保留Wedge 100 leaf交换机,并继续使用它们,延长其经济寿命。(很少有服务器需要超过100 Gb/s的带宽,而且其中的许多端口都被削减到25 Gb/s,在Facebook服务器机群中的“Yosemite”微服务器上共享I/O时)
F16的架构略有不同,因为Facebook正在扩展其spine平面,该平面使用了16个128端口、100 Gb /s 架构的交换机构建,而不是4个128端口、400 Gb /s交换机。Spine交换机也是基于Minipack交换机,这是固定端口和模块化交换机之间的一种混合(后文会详细介绍)。因此使用F16架构,每个服务器和存储机架都连接到16个不同的平面,达到单机1.6T的总容量。下面是F16架构的样子:

这些变化让Facebook能够在网络基础设施中大量减少芯片数量的投入,并且还不会牺牲带宽。为了说明这一点,下面展示了F4和F16不同的特性,F4使用了基于Tomahawk-3 ASIC的Backpack spine交换机和现有的基于Tomahawk-2 ASIC的Wedge 100 leaf交换机,F16架构则使用了Minipack spine交换机和基于Tomahawk-3(Minipack)、Tomahawk-2(Wedge 100S)ASIC的Wedge 100S交换机。

这是F16网络架构的关键所在,从一个区域或数据中心的任何一台服务器到另一个区域或数据中心的另一台服务器所需的芯片和跳数要少的多。Facebook网络工程师Alexey Andreyev,Xu Wang和Alex Eckert解释地很清楚:
“尽管在原理图上看,F16又大又复杂,但它实际上比我们之前的架构简单了2.25倍,将节点拓扑结构计算在内,从架顶(TOR)到该区域内交互网络(Fabric Aggregator)的顶层,最初的架构由9个不同的ASIC层组成。在一个架构中,从一个机架到另一个机架内最佳的网络跳数为6跳,最差的为12跳,而通过Fabric Aggregator从一个机架到另一个机架的路径在之前就高达24跳。对于F16,相同结构的网络路径始终是最佳情况下的6跳,而building-to-building flows需要8跳,这让网内跳数减少到之前的一半,服务器间网间跳数减少到之前的三分之一。”
这种新型F16架构的核心是Minipack 交换机,Facebook表示,与它在网络中取代的 Backpack交换机相比,Minipack交换机的能耗减少了50%。Minipack的底座带有8个端口,这些端口垂直安装在机箱中,如下所示:

这是Minipack交换机的原理图和一些细节:

严格来说,Minipack并不是一个固定端口交换机,通常一个盒子中有一个或多个ASIC,端口焊接在前面。Facebook希望采用模块化设计,允许它根据需要添加端口卡,但仍然需要一个Tomahawk-3 ASIC支持它们。这种不同模块化方法的有趣之处在于,Facebook正在使用反向变速箱来弥补支持NRZ编码的100 Gb /s光缆光学系统和支持PAM4编码的Tomahawk-3 ASIC通信SerDes之间的差距。Minipack端口底座还将支持传统的40 Gb /s电缆,现有的100 Gb /s电缆,以及将来的200GB/s或400GB/s电缆,这些电缆在成本效益较高时将与PAM4编码一起本地运行。
Arista Networks和Marvell都在开发Minipack交换机的克隆版,Facebook已经转向Edge-Core Networks推出自己的Minipacks,并且还与Arista合作开发了一些产品,它们都可以运行Facebook自己开发的FBOSS网络操作系统,但也可以使用其他网络操作系统,具体取决于供应商。
Minipack交换机不仅用于Facebook结构的架构层和主干层,而且现在也被部署在Fabric Aggregator层中(HGRID),HGRID具有足够的带宽和较少的跳数,Facebook可以将一个区域中的六个数据中心连接在一起,如下所示:

在全世界范围内,需要60万台服务器的企业并不多,但每个企业依旧希望拥有一个低成本、大规模的网络。Facebook再一次展示了它是如何完成这一目标的,并且已经形成了一个开放的生态系统,公司可以利用其设计并将硬件商业化,让世界其他地区都能从中受益。
原文链接:https://www.nextplatform.com/2019/03/20/how-to-benefit-from-facebooks-new-network-fabric/






