

作者简介:杨子夜,Intel 存储软件开发工程师,主要从事SPDK软件开发工作。
简 介
NVMe/TCP transport是NVM express这个标准组织为NVMe over Fabrics(NVMe-oF) 制定的一个基于TCP的新的传输层。这个Technical proposal (TP 8000)自去年11月份发布以来,相应的代码在内核态(Linux kernel)和用户态(SPDK库)中均有了支持。在这篇文章中,我们将主要介绍SPDK中NVMe/TCP transport的一些实现细节,对于NVMe/TCP transport的一些简要介绍可以参考前文《SPDK宣布在NVMe-oF Fabrics中支持TCP transport》。

SPDK NVMe/TCP 代码解析
总的来讲,SPDK NVMe/TCP transport 的整个设计遵循了SPDK无锁,轮询,异步I/O的理念,如Table1 所示。根据TP8000 specification中的定义,每个TCP连接(TCP connection)对应于一个NVMe的qpair。在SPDK的实现中,我们依然采用group polling的方法来管理所有的TCP连接。每一个SPDK thread上运行一个TCP相关的polling group,每一个TCP连接只会被加入一个TCP polling group中,由这个polling group处理后续的所有事件,那么这个TCP连接将会被唯一的CPU core处理,这样就不会存在CPU的竞争情况:不同CPU竞争处理同一个TCP connection。 这样的设计在很大的层面上避免了CPU资源的竞争。另外目前存在很多用户态的TCP协议栈,为此SPDK 封装了一些socket API相关的操作。目前,NVMe/TCP的实现代码直接使用SPDK封装的API 进行socket的操作,如此一来,我们可以接入不同种类的Socket API实现,诸如VPP,mTCP,fstack,seastar等。只要能够实现SPDK socket API所定义的抽象函数,就可以整合到SPDK的sock库中。
NVMe-oF transport(传输层)的抽象
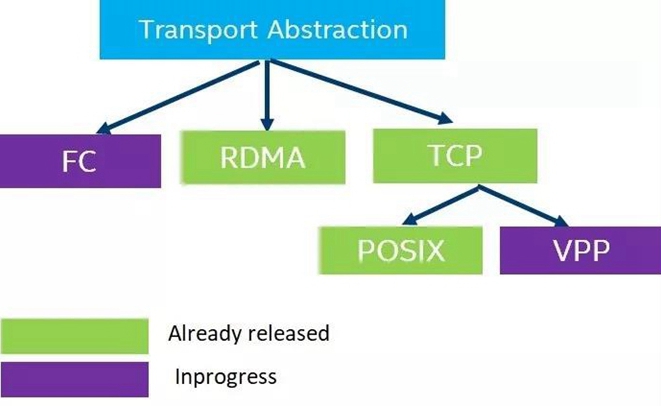
SPDK定义的NVMe-oF的框架剥离出了NVMe或者NVMe-oF处理逻辑的共同代码,然后针对所有的transport提供了一个统一的抽象接口。那么每个transport只需要实现这个接口里面的函数或者数据结构即可。对于TCP transport也是一样,target端和host端完全遵循这个设计。Figure1给出了目前SPDK软件库实现的或者将要实现的transport。其中Fibre Channel的支持的patch还在review 过程中,TCP transport和VPP的stack可以整合,但是由于VPP stack的一些稳定性原因,所以也标记为“在整合过程中”。
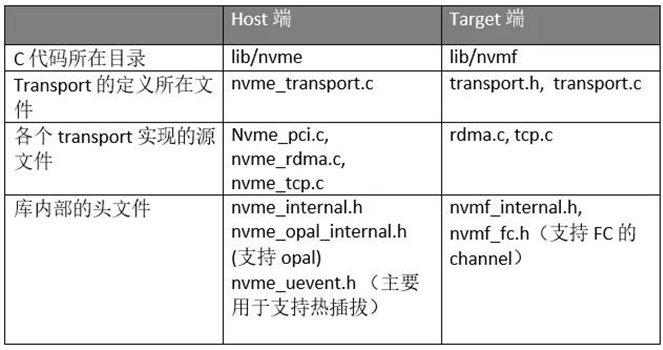
另外Table2 给出了SPDK在target 和host端对transport支持的源文件的一些路径。
NVMe/TCP transport的信息管理
在target端的TCP传输层主要对以下信息进行了管理:
Portals:
可以定义为
共享数据池(Data buffer Pool):
NVMe/TCP transport的读/写命令,都需要分配相应的buffer,然后进行后续的读写。当每个NVMe读/写命令(包含在NVMe/TCP transport的Command Capsule PDU中)被正确解析后,我们就会在共享数据池中分配所需要的data buffer。使用共享数据缓冲池的目的是为了控制内存使用的footprint。如果所需要的内存根据每个qpair的深度(Queue depth),那么所需要的内存大小将随着qpair的增加而线性增加, 这样对于支持大量TCP 连接而言是巨大的内存消耗。
在SPDK的设计中,数据缓冲池由每一个CPU core上的TCP polling group共享,那么这些polling group之间必然会存在对这个共享池的数据竞争。为了很好的缓解这个数据竞争的问题,我们采用以下策略,即每个polling group在这个共享池中预先保留了一些data buffer,这些data buffer组成了一个buffer cache。那么这将保证每个TCP polling group 都有内存可以分配,杜绝了starvation(饥饿)的产生。因为在buffer cache中分配的数据buffer在使用完毕以后,依然会被回收到相应的polling group对应的buffer cache中。
TCP polling group 中的socket管理:
首先SPDK对Socket套接字的API 进行了封装,这样我们既可以使用内核态的TCP / IP栈的所对应的Posix API,也可以利用用户态的API(诸如VPP,用户也可以根据SPDK 对于socket API的抽象定义,整合其他用户态协议栈)。所以我们使用的函数都是以spdksock为前缀的函数。
例如,我们正常使用“listen”函数来监听端口,在SPDK 里面使用spdk_sock_listen,SPDK的TCP polling group (数据结构是struct spdk_nvmf_tcp_poll_group)中有一个sock_group的指针。这个sock_group会在TCP polling group在创建的时候被同时创建,这个sock_group用于管理所有映射到这个TCP polling group的所有TCP 连接的socket。当一个TCP scoket连接被建立的时候,一定会被加入某个TCP polling group(目前使用的是Round Robin的算法),那么这个TCP的socket同时会被加入到这个TCP polling group的sock_group 中。一个socket在socket polling group的周期,可以分为以下三类:
-
加入某个socket polling group。我们可以在Linux 系统中可以使用epoll相关的操作(例如,epoll create创建一个event相关的fd),然后通过epoll_ctl将socket信息(实际是fd,file descriptor)绑定到一个这个由epoll 创建的event fd中。
-
在polling group 被轮询。然后我们就可以利用epoll来检查每个其中的socket是否有EPOLLIN的事件(来自远程的数据);如果有相应的数据监测到,将会读取数据进行后续处理(实际上是调用spdk_nvmf_tcp_sock_cb这个回调函数)。
-
在socket polling group被删除。另外在轮询过程中,监测到TCP 断开时,我们会将这个socket从这个polling group中删除(比如在Linux系统中是调用epoll_ctl在event fd中解绑那个socket的fd信息),那么这个socket将不会被处理。
NVMe/TCP PDU的生命周期管理
无论在target还是host 端,SPDK 都采用了同样的状态机对一个PDU的生命周期进行管理(如图2所示),其中SPDK定义了5个状态:
▪Ready:
等待处理新的PDU。
▪Handle CH:
TCP 连接收到数据,收到8个bytes后,判断PDU的类型,进行一系列的检查。如果错误,则进入到错误状态(Error State); 否则进入到下一个状态(Handle PSH)
▪Handle PSH:
这个状态用于处理PDU的specific header。如果处理出错,则进入错误状态(Error State),否则要么要么进入ready状态等待处理新的PDU,要么进入处理payload的状态(Handle payload)
▪Handle payload:
是主要用于处理PDU中包含的数据。而这些PDU只可能是CapsuleCmd,C2HDATA,H2CDATA,H2CTermReq,C2HTermReq。处理结束以后,要么进入ready状态要么进入错误状态(Error State)。
▪Error State:
如果这个TCP 连接在接收 PDU的时候处于错误状态(Error State),那么这个TCP 连接会给对端发送TermREQ命令,意味着这个TCP 连接在不久将要被关闭。

Target端NVMe/TCP request的生命周期管理
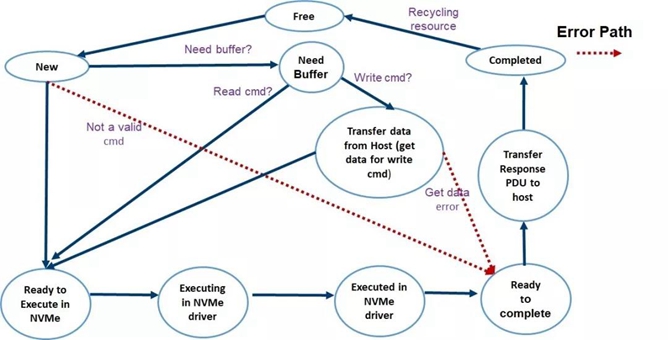
在target端我们对nvme tcp request(struct spdk_nvmf_tcp_request) 定义了10个状态(如Figure3 所示),Figure4 给出了相应的状态转化图,清晰的描述了一个NVMe/TCP request的生命周期。这和目前SPDK 主分支里面的代码是完全一致的。

总 结
本文详细介绍了SPDK NVMe/TCP transport的一些内部实现细节,希望对想基于SPDK NVMe/TCP transport进行后续研究或者二次开发的研发人员会有所帮助。
文章转载自DPDK与SPDK开源社区









