

在3月30号召开的SD-WAN应用研讨会上,Intel网络软件工程师杨智勇跟大家分享了基于FD.io/VPP和Denverton的SD-WAN方案优化技术。

演讲主要围绕了五部分展开,分别是Denverton硬件架构, FD.io/VPP软件架构, uCPE/SD-WAN开放架构和参考方案, Denverton平台上的VPP优化技术和Denverton平台上VPP性能数据。
Denverton硬件架构
那什么是Denverton呢?Denverton是Intel ATOM™ 处理器C3000系列的一个别称,有以下四个特点:
1.Denverton平台主要面对的是网络及边缘计算市场,拥有低功耗的特性,对于Denverton最低的功耗可以达到8.5W。
2. Denverton不同的产品core数量可以从2到16。
3.拥有加密和解密功能,在SOC里面集成了Intel特有的QAT技术,在加速方面可以达到20GBPS的性能。
4.可以支持Intel虚拟化技术,支持VT-x,VT-d。

Denverton用的是14nm的制程技术,保证了它低功耗的特性,Denverton平台与XEON 指令集是兼容的,可以最大限度让投资者在软件投资中得到兼容性的保护,其最高可以支持到SSE4.2指令集,有128bit矢量寄存器,可以支持单指令多数据SIMD的操作。另外Denverton平台一个时钟周期可以执行三条指令,保障了并行处理的能力。
图3是Denverton平台的架构,集成了Pcie和以太网的若干个接口,以及有QAT来保证加解密的高性能表现。

FD.io/VPP软件架构
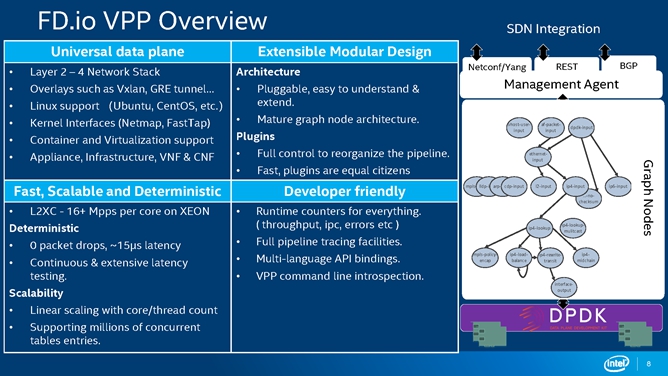
FD.io社区于2016年2月创建并同时加入Linux基金会, VPP项目是FD.io/VPP的核心组件,该项目在通用硬件平台上提供了具有灵活性、可扩展、组件化等特点的高性能IO服务框架,目前这个VPP支持多种平台,包括Intel的x86、ARM、PowerPC。
图4是FD.io/VPP的一个概述,FD.io/VPP支持2层到4层的网络协议栈,常见的协议在FD.io/VPP都能得到很好的支持。另外FD.io/VPP是以插件方式进行拓展的,这样的设计使架构具有了开放性,不需要去修改其核心代码,就可以把用户想要加的新特性用插件的方式加入到FD.io/VPP里面去。
图4 右边的示意图是FD.io/VPP,它每一个模块都可以去独立地实现某些功能,如果需要加入一些新特性的话,可以用新Graph Node的形式加入到需要的服务链路中去。
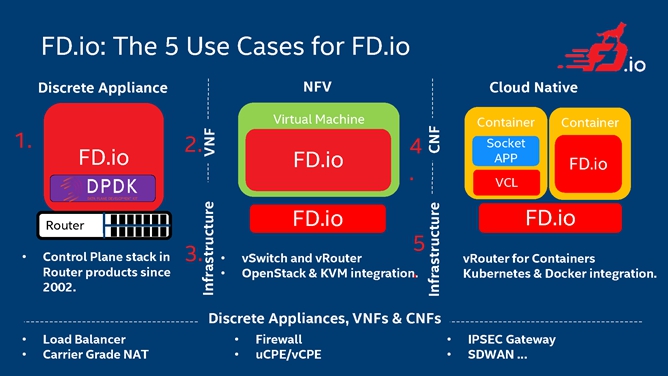
那么FD.io/VPP在实际的应用当中到底支持哪些应用场景呢?常见的应用场景都可以得到广泛的支持。第一种就是在一个机器的主机上面直接运行FD.io/VPP,让这个机器变成一个路由器。第二种是对NFV的支持,可以看到,在上面可以运行FD.io/VPP去做vSwitch和vRouter的工作,并且可以跟OpenStack和KVM有非常好的结合。另外现在随着云的发展,FD.io/VPP一个显著的特点是可以支持云原生,可以在容器中运行VPP。各种场景的应用,比如防火墙、IPSEC网关、SD-WAN等都可以得到FD.io/VPP的广泛支持。
uCPE/SD-WAN开放架构参考方案
图6是uCPE/SD-WAN开放架构参考方案,这是Intel推出的基于SD-WAN方面的一个架构设计。第一部分实现了硬件的白盒设计,第二部分设计了一个SDK,底层的操作系统用的是CentOS 7.5 和KVM,上面一层使用的是DPDK和VPP(19.01),对外的管理引擎用的是SweetComb。管理、操作和编程都是通过ODL去控制。客户可以在SDK的基础上,在虚拟机或container中去运行想要的业务,这样整体就构成了一个SD-WAN的应用,那么它是怎么接入云上面去的呢?这样一个SD-WAN的方案可以通过MPLS把它汇集到Cloud Gateway,通过Gateway上传到云上面,
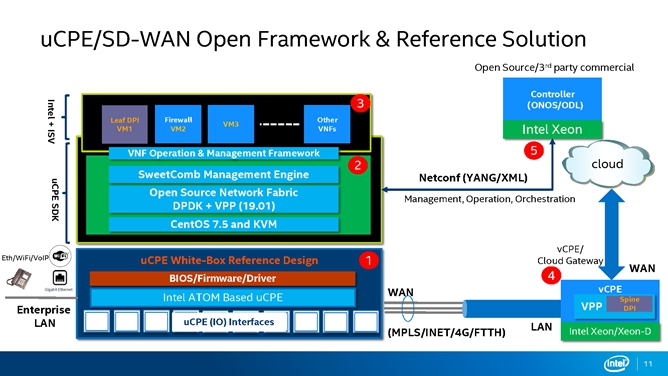
uCPE SDK主要的目标是希望通过搭建这样的基础架构,可以实现路由器、VPN、VoIP、SD-WAN等等的应用。

Denverton平台和VPP优化技术
最能体现CPU之美的是软件,同样一个处理平台可以使用不同的软件让它去变成自己想要的样子,提供不同的功能。软件优化有几个层次。第一个层次是系统设计,一个良好的系统设计可以让软件高效的运行,成败与否至关重要。第二部分是算法以及结构方面的设计,算法决定了计算的复杂度,数据结构及指令结构的编排可以让代码可读性更好,更清晰明了。当然第三层面上就是编程,这个也有很大优化的空间可以挖掘。
VPP是怎样工作的,为什么它叫VPP呢?实际上可以把它理解为是一个批处理的过程, VPP最多支持256个包同时被抓进来。VPP的显著特点就是graph node要同时把这些包处理完毕,才会释放到下一个graph node里。
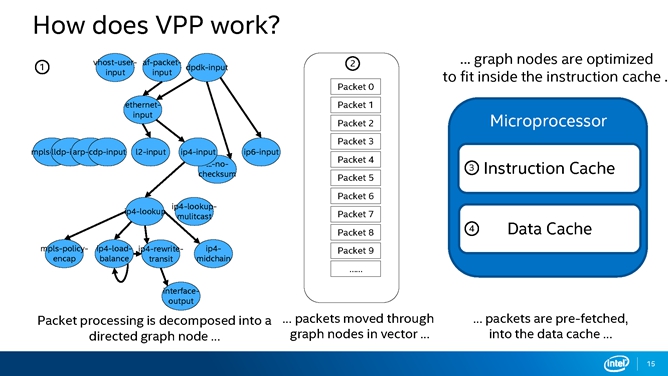
图9展示了VPP最常用的一个ethernet-input工作流程,是接入二层处理以太网包的一个graph node。
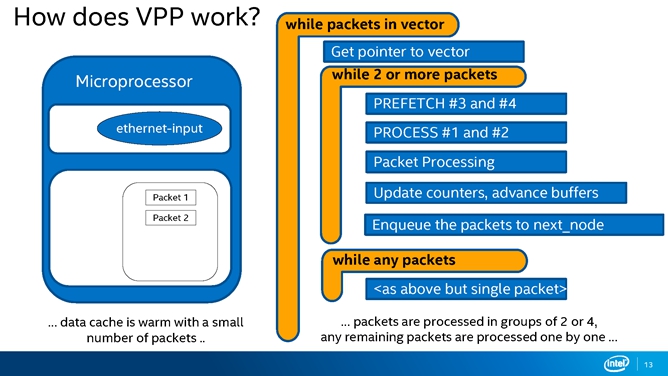
下面是关于一些优化方面的技巧,杨智勇在研讨会上给了大家四个建议。


良好的数据结构设计保证了VPP在现代的微处理器上有良好的表现。在处理过程开始之前,将vxlan报文头需要存储的pre_data区域提前预取到data cache,可以大幅提升性能,vxlan-encap graph node节省了接近一半的开销,92 clocks/pkt.
Denverton平台上VPP性能数据
FD.io/VPP社区现在已经是非常成熟的社区了,在创立之初就有了一个CSIT的项目,这个子项目是为了帮助测试VPP以及FD.io下面的其他子项目,提供功能和性能测试。
下图是Denverton的测试的系统数据,做了一个NIC到FD.io/VPP,再转出到NIC这样一个测试。测试严格按照FD.io社区CSIT的测试流程,遵循的是RFC2544标准。下面这个数据已经公开发布在CSIT性能测试报告里面,有兴趣的朋友可以去详细看看这个数据。

只有单核性能测试是不够的,还应该看看FD.io/VPP在Denverton上面是多核的可扩展性。通过下图可以看出在Denverton平台上,FD.io/VPP表现的十分不错,性能随核数增加做到了线性扩展。









