

“如果没有软件定义网络,那Google就不会是今天的Google。”——Google研究员Amin Vahdat
SDN对Google网络的意义

2005年,在大多数公司还没有考虑开发自己的数据交换机的时候,Google出现了这方面的业务带宽需求。当时,市面上销售的设备昂贵且操作复杂,Google意识到支持自己服务的网络不存在且无法购买,所以,Google决定尝试使用自定制的方法。
Google的举动引发了新一轮的创新狂潮——软件定义网络,SDN最初诞生的目的就是在于替代传统的网络硬件,使得硬件可以通用化,从而降低成本,实现集中控制,降低网络维护难度。Google从2010年开始将机房与机房之间的网路连线(G-scale),转换成SDN架构,并自行设计交换器,而Google的全力投入和成功,也让其他人相信,SDN可能就是网络的未来。
Google的SDN支柱
Google在过去十年中一直在发展软件定义网络(SDN),以支持其服务。他们在2013年推出了B4,这是一个面向数据中心的广域网互连。2014年,推出的Andromeda是一个网络虚拟化堆栈,构成了Google Cloud的基础。2015年,Google拥有用于处理单个数据中心内的流量的Jupiter。2017,他们推出了Espresso,这是用于公共互联网的SDN,主要负责与互联网服务提供商的对等连接。他们建立了世界上最大的网络,以支持Google服务,如网络搜索,Gmail和YouTube。
GoogleSDN战略的四大支柱:
- B4 WAN互连:Google构建B4网络实现了数据中心的连接,以便在各个园区网之间实时复制数据。Vahdat表示:“B4是基于白盒交换机建立的,受Google开发的软件控制。”
- Andromeda:Google的Andromeda是一个网络功能虚拟化(NFV)堆栈,可以将其本机应用程序的功能提供给在Google云平台上运行的容器和虚拟机。
- Jupiter:Google通过SDN来构建Jupiter,Jupiter是一个能够支持超过10万台服务器规模的数据中心互联架构,支持超过1 Pb/s的总带宽来承载其服务。
- Espresso将SDN扩展到Google网络的对等边缘,连接到全球其他网络。Espresso使得Google能够根据网络连接实时性的测量动态智能化地为个人用户提供服务。
无论是B4 WAN,还是Espresso,Google的基本设计理念是,网络应被视为一个大规模的分布式系统,并在这个分布式系统上充分利用Google开发的计算和存储系统的基础设施。
B4
简介
Google 的广域网实际上分为B4(DCI)数据中心互联和B2骨干网。其中WAN网又可以分成两种,一种是数据中心之间互联的网络,又称为G-scale Network,它是一个内部网络,用来连接Google世界各地的数据中心。另一个是面向Internet用户访问的网络,即I-Scale Network。
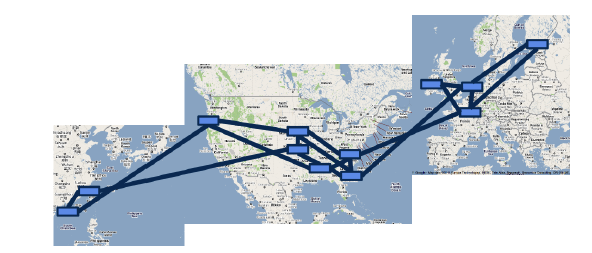
促使Google使用SDN改造WAN网的原因有很多,这里只谈两点。第一,当前连接WAN网的链路带宽利用率很低。Google WAN网的出口设备对外有上百条链路,这些链路被分成很多ECMP负载均衡组,这些均衡组内用的是基于静态Hash的负载均衡方式。在这种均衡下,很多流量可能会被分到同一个链路上从而导致丢包,为了避免这种状况发生,Google不得不准备冗余的链路和更高的带宽。然而这又带来了一个新的问题,实际链路的利用率只有30%-40%。而且在同一时刻,有的链路闲置,有的链路拥塞(设备还要支持大包缓存),此时的WAN网并不“聪明”。第二,数据中心之间互联的WAN网结构相对简单,设备类型以及功能比较单一,而且WAN网链路成本高昂(比如很多海底光缆),所以对WAN网的改造无论建设成本、运营成本收益都非常显著。他们把这个网络称为B4。
Google对B4网络的改造方法,充分考虑了其网络的一些特性以及想要达到的主要目标。首先,Google希望通过控制应用数据的优先级和网络边缘的突发流量(Burst)来优化路径,缓解带宽压力,而不是靠无限制地增大出口带宽。其次,改造网络也要考虑成本,虽然Google富可敌国,但面对每天数据流量的增加,Google也没法承受设备成本的增加。
架构
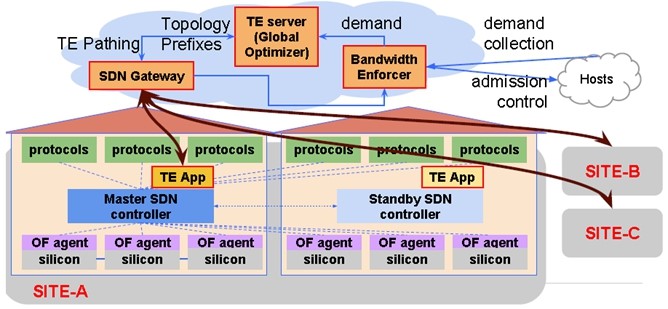
为了对这个方案进行充分的测试,Google用强大的软件能力模拟了整个B4的网络拓扑和流量。B4网络主要3层分别是物理设备层(Switch Hardware)、局部网络控制层(Site Controllers)和全局控制层(Global)。一个site就是一个数据中心,每个数据中心都部署物理交换机和Site Controllers,而第三层的SDN网关和TE服务器则是在一个全局统一的控制地。
第一层:物理设备层
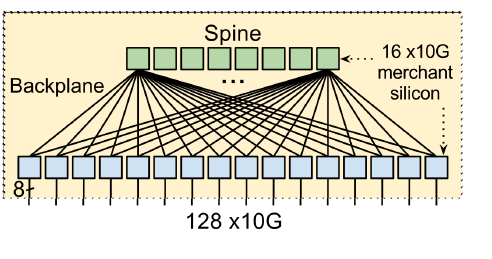
第一层的物理交换机是Google自己设计并请ODM厂商代工的,用了24颗16×10Gb的芯片,搭建了一个128个10Gb端口的交换机。交换机里面运行了OpenFlow协议,该协议采用了TTP的方式,包括ACL表、路由表和 Tunnel表等。这些交换机会把BGP/IS-IS协议报文送到Controller去供 Controller处理。
第二层:局部网络控制层
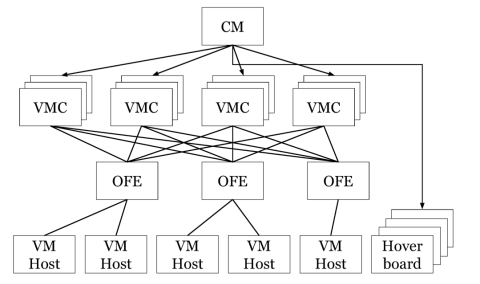
B4网络中每个数据中心都有一个服务器群,而且每个服务器上都运行了一个Controller。一台交换机可以连接多个Controller,但处于工作状态的只能有一个。每个Controller也可以控制多个交换机。一个叫Paxos的程序负责所有控制功能的领导人(leader)选举。每个站点上的Paxos实例对给定控制功能的可用副本集执行应用程序级故障检测。当大多数的Paxos服务器检测到故障时,他们从剩余的可用服务器集中选出一个新的负责人。然后,Paxos将递增的ID号回调给当选的leader。leader使用这个ID来明确地向客户表明自己的身份。
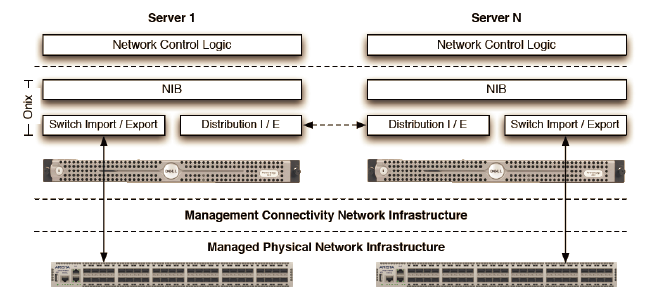
Google用的Controller是基于分布式的Onix Controller改造来的,有很好的扩展性,因此可以用来控制大型网络。每个Controller只控制物理层设备,并且只把汇聚过后的信息发送给逻辑控制服务器,这样服务器就可以掌握整个链路上的拓扑信息。在Controller之上跑了两个应用,一个叫RAP(Routing Application Proxy),作为SDN应用跟Quagga通信。另外一个应用程序叫TE Agent,跟全局的Gateway通信。每个OpenFlow交换机的链路状态(包括带宽信息)会通过TE Agent送给全局的Gateway,Gateway汇总后,送给TE Server进行路径计算。
第三层全局控制层(Global)
负责全局控制的TE Server通过SDN Gateway从各个数据中心的控制器收集链路信息,从而掌握路径状况。这些路径被以IP-In-IP Tunnel的方式创建通过Gateway到Onix Controller,最终下发到交换机中。当需要传输一个新的业务数据时,应用程序会预估它传输时所需要的带宽,为它选择一条最优的路径。从而整体上使链路带宽 利用率达到最优。
Andromeda
简介
云计算的兴起为网络带来了新的机遇和挑战。云提供商必须支持具有高性能和丰富功能的虚拟网络,例如负载平衡、防火墙、VPN、QoS、DoS保护、隔离和NAT。在云计算的网络支持方面已经有了大量的研究,特别是高速数据平面、虚拟路由基础设施和NFV中间盒。但是,将工作系统地、端到端地结合起来的研究还不够,因此Google开发了Google Cloud Platform(GCP)的网络虚拟化环境 - Andromeda,展示如何跨全局、分层控制平面、高速主机虚拟交换机、包处理器和可扩展网关划分功能。
Google将Andromeda描述为基于软件定义网络(SDN)的基板,用作配置和管理虚拟网络以及网内数据包处理的编排点。目标是暴露底层网络的原始性能,同时暴露网络功能虚拟化(NFV),包括分布式拒绝服务(DDoS)保护、透明服务负载平衡、访问控制列表和防火墙。
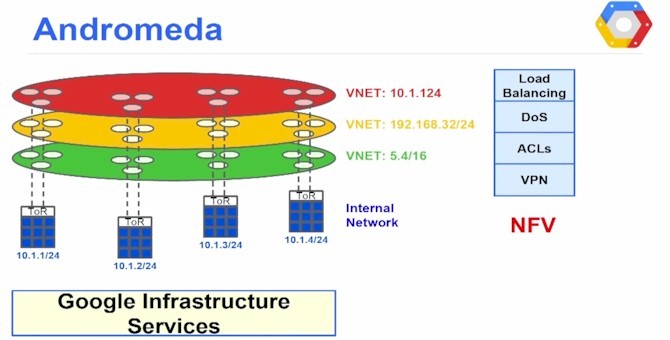
架构
Andromeda的控制平面和数据平面都使用分层结构。控制平面维护有关网络中每个VM的信息,以及所有更高级别的产品和基础架构状态,例如防火墙,负载平衡器和路由策略。它是围绕全局层次结构与整个云集群管理层一起设计的。数据平面提供一组灵活的用户空间数据包处理路径,整体数据平面设计理念是灵活、高性能的软件和硬件卸载。
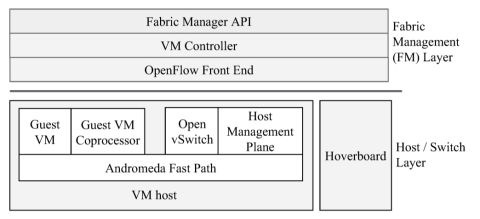
控制平面
控制平面由三层组成:
- 集群管理(CM)层:CM层代表用户提供网络、存储和计算资源。它的功能不是特定于网络的,当集群管理层需要配置虚拟网络时,它使用结构管理层服务来执行此操作。
- 结构管理(FM)层:FM层为CM层提供一个高级API来配置虚拟网络。API表达用户意图并抽象实现细节,例如编程交换机的机制、封装格式和负责特定功能的网络元素。
- 交换层:在这一层中,有两种类型的软件交换机支持封装、转发、防火墙和负载平衡等。每个VM主机都有一个基于Open vSwitch的虚拟交换机,可以处理主机上VM的所有流量。悬浮板是独立的交换机,充当某些流的默认路由器。
数据平面

数据平面是一个用户空间进程,它执行所有主机上的VM数据包处理,同时结合了虚拟网卡和虚拟交换机功能。有两个主要的数据平面包处理路径:快速路径和协处理器路径。快速路径执行高性能数据包处理工作,如通过流表进行封装和路由。协处理器路径执行的数据包工作要么是cpu密集型的,要么不具有严格的延迟要求,例如WAN数据包加密。
每个VM都由一个用户空间虚拟机管理器(VMM)管理。每个VM有一个VMM。VMM将RPC发送到Andromeda数据平面,用于映射客户VM内存、配置虚拟网卡中断和卸载以及附加虚拟网卡队列等操作。
快速路径维护转发状态和相关数据包处理操作的缓存。当数据包在快速路径缓存中丢失时,它将被发送到主机上的vswitchd, vswitchd保持VMC编程的全转发状态。Vswitchd发送流缓存更新指令并将数据包重新注入快速路径。
快速路径的一个关键目标是提供高吞吐量、低延迟的VM网络。为了提高性能,快速路径忙于轮询专用逻辑CPU。物理内核上的另一个逻辑CPU运行低CPU控制平面工作,如RPC处理,留下大部分物理内核用于快速路径使用。快速路径可以在单个CPU上每秒处理超过300万个小数据包,相当于每个数据包的CPU预算为300ns。可以使用多队列NIC将快速路径扩展到多个CPU。
Jupiter
Google的数据中心网络带领它走到了今天的领先地位。Google一直站在开发新丰富服务支持网络设计的最前沿,主要是因为他们将数据中心视为计算机的指导愿景。随着云应用不断增加,数据中心的流量也呈现爆炸式增长,这对Google的数据中心带来了巨大的挑战。为了应对如此之大的数据流量压力,Jupiter就此诞生。
Jupiter是Google最新一代的数据中心网络,它引入了SDN技术并且使用了OpenFlow,是一个能够支持超过10万台服务器规模的数据中心互联架构,支持超过1 Pb/s的总带宽来承载其服务,达到这一量级的Google数据中心网络则可以同时支持100000台计算节点以10Gbps的网络速度通信,这个规模是非常惊人的。
Google主要围绕一个三管齐下的计划:使用Clos拓扑,使用SDN,并以他们自己的Googlish方式构建自己的自定义设备。Jupiter的主要构建模块和最终的设备形态如下图所示,体现了Google在其数据中心网络中引入的采用Clos拓扑、商用晶片等核心设计理念。

Espresso
简介
Google在ONS Summit 2017上推出了他的第四个SDN控制器Espresso(浓缩咖啡),在Metro网络中新引入SDN控制器来调整出方向(Egress)流量。
Espresso首要需求是:动态调整每用户/每应用流量,在PR出口避免拥塞。现有的互联Peering网络是依赖于BGP设计的。BGP设计之初是为了提供稳定的联通性,完全没有考虑网络的动态变化。虽然BGP有很多问题,但是大多数的传统的SP/ISP还在采用BGP互联,Google/Facebook还不能抛弃BGP,所以Google/Facebook引入SDN控制器来自动调节BGP出口流量。
系统架构
为了更好的规划Metro里的流量调度,Espresso引入了全球TE控制器(B4中也采用)和本地控制器(Location Controller)来指导主机发出流量选择更好的外部Peering 路由器/链路,进行per flow Host到Peer的控制。并且解耦了传统Peering路由器,演进为Peering Fabric和服务器集群(提供反向Web代理)。
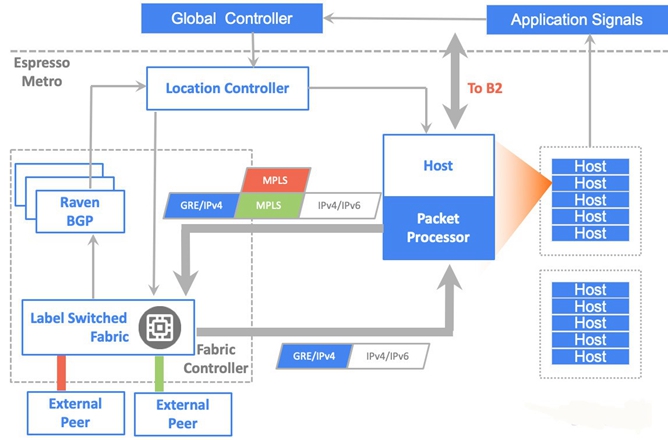
首先,BGP speaker学习邻路由信息并将其传送到本地控制器(LC),然后本地控制器将这些路由信息传送到全局控制器(GC)。之后,GC建立最佳转发路由表,它将这些路由表再分发给各个LC,LC将它们安装在所有TCP反向代理主机中。具体步骤如下:
- 外部系统请求进入Google Metro,在Peering Fabric上被封装成GRE,送到Meglev负载均衡和反向web代理主机处理。如果可以返回高速缓存上的内容以供用户访问,则该数据包将直接从此处发回。如果CDN没有缓存,就发送报文通过B2去访问远端数据中心。
- 主机把实时带宽需求发送给全局控制器(GC)
- GC根据搜集到的全球Internet Prefix情况,Service Class和带宽需求来计算调整不同应用采用不同的Peering路由器和端口进行转发,实现全局出向负载均衡。
- GC通知本地控制器(LC)来对host进行转发表更改。同时在PF交换机上也配置相应的MPLSoGRE 解封装。
- 数据报文从主机出发,根据GC指定的策略,首先找到GRE的目的地址(PF),PF收到报文之后,解除GRE报文头。根据预先分配给不同外部Peering的MPLS标签进行转发(注意,采用集中控制器,不需要引入BGP-LU来分配MPLS标签)。如上图所示,如果采用红色MPLS标签,就会转发给红色链路。
Espresso 的设计与Google的整体 SDN 策略目标一致,将网络视为一个大规模的分布式系统,用与Google计算和存储系统同样的方法管理和控制。
Espresso内容参考了Google Espresso 解耦重构 BGP SDN一文
未来十年的挑战
在ONS Summit 2017上,Google研究员Amin Vahdat谈到了谷歌未来十年的挑战,在过去的十年里,Google一直致力于软件定义网络的研究。从2013年推出的B4网络到2017年公布SDN控制器Espresso。Google似乎在全世界范围内建立了一个网络帝国,但随着企业应用程序迁移到云,他们现在正在为其他人托管服务,从而推动他们进入新的领域——云。云文化的诞生似乎催生了下一代网络的变革。
Google的云架构是围绕整个数据中心的存储和计算分解而构建的。哪个服务器保存什么数据并不重要,因为这些数据都可以在整个数据中心内复制。Vahdat指出,这种方法的挑战是,任何地方的访问延迟都会大幅增加,从而也推动了他们对数据中心内部网络的需求。
“现在他们正在转向Cloud 3.0,侧重点是计算,而不是服务器,“Vahdat说。这样可以使人们更关注于他们的业务,而不是担心数据的位置,不同组件之间的负载平衡,或虚拟机上操作系统的配置管理。由于网络在云3.0中发挥关键作用,Google需要考虑几个关键要素:存储分解,无缝遥测,透明地实时迁移,服务水平目标等。
未来十年,Google会变成啥样?有分析家称,由于它拥有充足的现金储备、活跃的风险资本支持以及网络世界无以伦比的缓存能力,未来10年中,Google不仅能够维持其“网络之王”的地位,而且还会继续扩大。不管怎样,Google还是要保持警惕,毕竟前方还有亚马逊、微软、Facebook一直虎视眈眈。
参考
1.http://www.chinairn.com/news/20150820/165042257.shtml
2.https://www.linux.com/blog/event/open-networking-summit/2017/5/networking-challenges-next-decade
3.https://www.cnblogs.com/yasmi/articles/5459324.html
4.https://www.sdnlab.com/sdn-guide/14862.html
5.https://sdn-lab.com/2017/08/16/espresso-more-insights-into-googles-sdn/
6.https://www.sdxcentral.com/articles/news/google-brings-sdn-public-internet/2017/04/
7.https://www.sdnlab.com/sdn-guide/14868.html
8.https://www.sdnlab.com/22498.html
9.https://www.usenix.org/system/files/conference/nsdi18/nsdi18-dalton.pdf








