

作者简介:杨文斌 大地云网产品技术总监,曾在 IBM、Cisco等公司任职。
转眼就进入2019,回想过去一年的忙忙碌碌,曾经答应朋友写点数据中心网络的文章,但是总以工作繁忙为借口,拖到现在。作为一名老网工历经了数据中心和网络技术的几度变迁,就写点数据中心网络发展过程的风风雨雨并总结分享一下,也算对过去的回顾和对未来的展望吧。
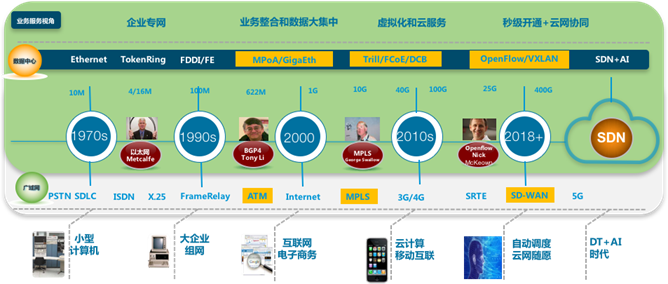
在记忆中2000年以前网络技术的争论是最多的,各种技术宗教信仰和流派,当时厂商(现在大部分都已经消失)经常会为技术争论的面红耳赤,直到2000年千兆路由交换机出现其他技术流派开始销声匿迹; 第二次是2009年随着云计算和虚拟化的开始出现,数据中心以太网络DCB技术和大二层TRILL技术将网络推向一个新的高潮;近些年随着公有云以及开源技术Openstack/Docker/SDN等大量使用,早期过于依赖底层设备的数据中心以太网络无法满足新生代云商和OTT等客户对网络弹性需求,尤其是企业上云对云网协同编排的新挑战,Network Overlay与Host Overlay如何选择?多厂商异构SDN混合组网和云网协同编排?本文将深入浅出谈谈对数据中心网络技术的发展和演进。
第一次转折或演进:以太网的生死之战
背景:时间追溯到1997-2000年,网络技术还是一个刚刚开始并处于混沌的状态,网络世界就像是个春秋战国一样:以太网、TokenRing、FDDI 、ATM/MPoA、SNA/IPX/IP等等百家争鸣,尤其是ATM/MPoA技术出现几乎市场和业界全都倒向ATM技术。记得当时一个焦点是:语音、视频和数据是跑在TDM还是VoIP?另一个焦点具有先进流控的ATM和基于CSMA/CD机制的以太网-争论的如火如荼,当时是个百花齐放的年代,更是个网工最红火的年代。

典型需求:企业联网和数据集中,数据中心网络技术如何选择?
焦点技术: MPoA和 千兆以太网; 大背景IT和CT之争(ATM最早来自CT公司)
战役的主角:IT网工 和 CT网工
当时的焦点技术分析:
- ATM技术:来源于通讯行业的一项技术, 建立在电路交换和分组交换的基础上的一种新的交换技术,ATM技术亮点是可以同时承载语音、视频和数据,通讯行业希望一种技术解决通讯网络和计算机网络(广域网和局域网)完美融合,ATM Cell交换芯片的高速率和低延时,一出来就支持25M/155M/622M, 远超100M以太网,QOS服务质量上: ABR/VBR/CBR 说起来头头是道, 而且当时就提出控制和转发分离基于MPOA 协议统一控制SVC连接,有点类似今天的SDN理念,以当时的技术而言ATM具有绝对的技术优势
- 千兆以太网GE技术: 以太网基于70年代的以太网CSMA/CD机制和技术,当时以太网速率只有 100M,半双工而且共享带宽,QOS最弱或技术基本上谈不上桌面, 初期通讯厂商提出利用ATM技术实现语音数据和视频的融合,技术上全面领先,传统的IBM等公司为保护自己的原有SNA/APPN市场,支持TokenRing/FDDI甚至偏向ATM阵营,以太网节节败退; 战役的后期:以太网速率提高到千兆速率和交换全双工,SNA和IP以太网达成战略同盟:以基于IP+Tunnel的DLSW+兼容和支持SNA/APPN,同时廉价的以太网卡延伸到桌面,基于IP的语音和视频H.323+RSVP帮助IP以太网的SLA服务质量问题,以太网终于开始扭转了生死战局。
体会和点评:再完美的技术如果没有群众基础难以成功,ATM/MPoA技术上的优势难以弥补其在通用性的缺点,一方面25M/155M网卡和芯片在价格上企业难以承受, 另一方面是转发层面过分依赖控制层面导致性能和可靠性下降。最后以Bay网络被北电收购以及美国Fore 公司被收购结束了这场网络界最具争议和旷日持久的战役,”先进的技术”也会被传统技术打败。战役的结果以太网统治了网络界20多年直到今天也无法动摇,确立霸主地位,厂商思科无疑是这场战役的大赢家。当然IT网工收获颇丰,记得2000年考个CCNP/CCIE在美国可以拿到一年10+万美元的年薪,IT网工也是那个年代最耀眼的IT群体。
第二次属于和平演进:网络大二层技术的兄弟之战
背景:这场战役的时间追溯到2009-2012年,记得2009年左右云计算刚刚开始,以太网的霸主地位繁荣了将近10+年,这10年传统的IT公司都在分享以太网的胜利果实相安无事,直到有一天Google 和Amazon(包括Vmware)为代表的新一代互联网巨头的出现,希望打破这个传统的IT格局,提出了云计算新的IT模式。虽然云计算不是针对网络,但是传统的IT公司和网络公司开始坐不住了,开始了自我革命。这10年以太网发展到10G,40G速率已经不是问题,但是过时的STP环路常常导致以太网灾难性宕机,另外网络的基于POD的二层设计,无法实现云计算大规模二层的扩展,而云计算和虚拟化如Vmotion要求L2越大越好,另外数据中心内部还有一个独立于以太网之外存储SAN网络,逍遥法外,于是网络公司开始提出面向云计算的网络新技术新课题。
典型需求:虚拟化大二层STP无环路网络设计,IP数据网和存储SAN网的整合
焦点技术:TRILL、DCB、OTV和 FCoE
战役的主角:传统的网工和懂存储或懂主机的 ”网工”, IT内部信息部门之间
架构上达成一致:由于虚拟化和云计算的出现,现在大家又要重新洗牌,IT信息内部兄弟间出现了裂痕,原来井水不犯河水,这次的战役有点像是兄弟内讧,不过这次的战役”网工”战略经验更加丰富,由于都来自IT自家兄弟,怎么好撕破脸皮,那大家坐下来先谈架构,既然云计算和和虚拟化要求大二层,网工主动提出将传统的三层架构改造为基于CLOS架构的Spine/Leaf的二层架构,原来L3网关在Agg下移到Leaf节点,但核心Spine节点之间是否互联又是一个争论话题,懂网络又懂SAN的 网工主张参考SAN架构,Spine节点之间独立最好不需要互联,于是架构就这样愉快的决定了。
争论的焦点:由于这场争论是基于以太网这个核心不动摇的前提,大家的斗争要温和很多,更多集中在技术改良问题,如以太网技术发展30多年了,出现了太多STP环路问题,而基于ISIS/OSPF的路由技术由于有全网拓扑状态信息被验证是远远优于STP技术,于是大家一致同意用新的技术实现大二层设计而没有环路,于是很快诞生了基于L2MP的TRILL技术,以及基于数据中心DCI之间如何实现大二层设计和多活中心的OTV/LiSP技术。 如果激烈一点算是以太网和SAN网络之间的较量,由于以太网的实力过于强大,基本上这场战役主角还是围绕以太网的技术自身的如何发展争论而已。存储数据网络整合是基于FcoE、FCIP和 FC 如何整合。

焦点技术1:大二层技术TRILL/L2MP
在Spine/Leaf的二层架构中,核心层与接入层设备有两个问题是必须要解决的,一是拓扑无环路,二是多路径转发。但在传统Ethernet转发中只有使用STP才能确保无环,但STP导致了多路径冗余中部分路径被阻塞浪费带宽,给整网转发能力带来了瓶颈。因此云计算中需要新的技术在避免环路的基础上提升多路径带宽利用率,这是推动L2MP TRILL(厂商私有如 思科FabricPath/Juniper QFabric)这些新技术产生的根本原因。
TRILL目标是在大型Ethernet网络中解决多路径而无STP环路的方案。控制平面上TRILL引入了ISIS做为L2寻址协议, TRILL封装是MACinMAC方式,当时学习这个技术时觉得真的很先进,因为当时能讲明白而且动手实操的网工大仙实在太少,另一方面由于TRILL对交换机的芯片和设计提出了苛刻要求,这也许是技术太先进太复杂导致很难大规模部署的原因。- 就像ATM技术。

焦点技术2:OTV和LiSP组合
OTV是一项”MAC in IP”技术,最早提出控制面和转发面分离, 基于 ISIS做为控制协议实现MAC地址路由表交换和管理,OTV可提供一种叠加(overlay)网络,能够在分散的二层域之间实现二层连接。数据平面OTV以MAC in IP方式封装原始Ethernet报文,报文结构非常类似今天VXLAN技术。

在当时利用OTV技术可以为跨任意传输网络的二层连接扩展,OTV结合虚拟化环境的精确定位技术LISP, 来承载跨数据中心的多种应用、信息和IT资源虚拟化, 并通过优化的智能服务。这两个技术的出现在当时的确眼前一亮,非常看好这两个技术, 是当时云计算和多中心多活或灾备时最爱讲的技术话题, 尤其是OTV/LISP都引入了控制平面协议来处理拓扑管理和转发路径判定的工作,利用ISIS之类协议解决STP原来二层的环路和MAC广播问题,虽然最终都没有成为今天主流,但是今天的Overlay VXLAN网络技术的确离不开这几个技术的铺垫,如图可见VXLAN数据报文格式基本上照搬OTV的报文格式。
虚拟化精确定位技术LISP(Locator/ID Separation Protocol ):LISP名址分离网络协议,在LISP中,原有的网络IP地址被分成EID(end-identifier)和RLOC(routing locator)。其中,EID用于标志主机,不具备全局路由功能;RLOC用于全网路由。名址分离网络自然会引入名与址的映射,即LISP中EID-to-RLOC的映射。利用OTV和LISP结合可以很好的用于支持虚机扩展、集群以及在线VMotion的场景,当扩展子网时,LISP目的是解决服务器或虚机的位置信息并提供的最佳径路;在当时通过LISP和OTV的组合可以解决虚拟化资源的迁移和业务连续等技术难题。
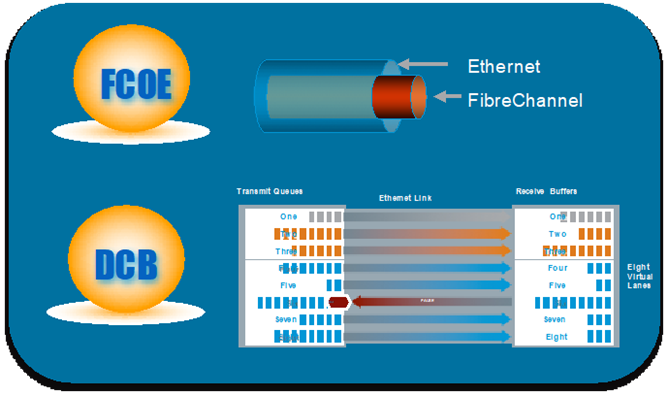
焦点技术3:FCoE和 DCB
FCoE是在2007年INCITS(国际信息技术标准委员会)的T11委员会制定的标准,2009年6月标准完成(FC-BB-5)。通过FiberChannel Over Ethernet(FCoE)技术,可将传统的FC存储网络功能融合到以太网中。和标准的光纤通道 FC 一样,FCoE协议也要求底层的物理传输是无损失的。但是标准以太网暂停选择(IEEE 802.3 Annex 31B)一旦拥塞,但它会阻止一条链路上的所有流量,包括FC流量。为了使以太网能够满足应用的无丢包要求,需要制定一种方法来通过以太网提供无损服务。基于优先级的流量控制PFC和DCB正是在这种背景下出现,PFC允许在一条以太网链路上创建 8 个虚拟通道,并为每条虚拟通道指定一个 IEEE 802.1P 优先等级,这一方法使网络能够为单个虚拟链路创建无丢包类别的服务,使其能够与同一接口上的其它流量类型共存。协议标准化后称为数据中心以太网DCB或“融合型增强以太网(DCE)”。FCoE技术运行在一个无损的数据中心以太网络DCB上,再加上万兆以太网接入提供了更大的I/O接入带宽,满足当时FC的速率需求,整个故事就讲的非常圆满。
当时为了解决虚拟机与外部虚拟化网络对接、关联和感知的问题,还出现了若干虚拟化技术: 802.1Qbg,802.1Qbh,802.1BR和 VN-Tag等,实现交换机端口上对每个虚拟网卡的识别,并可在网卡上灵活划分每个虚拟网卡的资源,实现精细粒度的QoS管理,这里就不做一一介绍。
体会和点评:这次演进以云计算和虚拟化开始,数据中心的网络技术开始出现TRILL/FabricPath、OTV/LiSP、DCB/FCoE等一系列眼花缭乱的新东西,由于这是数据中心网络技术的和平演变和网络自身的改革,虽然打着云计算的”幌子”,但是当时厂商也不见得真正知道云计算需要什么,刀片服务器+TRILL+FCoE顶多算是为虚拟化资源池做了最佳实践,或者成果可以算是为虚拟化和多中心服务器应用多活进行的网络实践,因此这次的战役三个网络巨人(思科、华为和H3C)空前达成一致,先后推出的技术惊人的相似,由于没有颠覆性的技术改变格局,大家相安无事,甚至最后存储网络厂商也没有受到任何影响。网工经过这次洗礼,对存储技术,刀片技术,虚拟化技术开始掌握或精通,开始出现跨界网工,那个时代的网络工程师开始要懂一些存储SAN,服务器、灾备、PUE和云计算Vmware,开始研究ITIL流程,开始学习TOGAF架构方法论……
第三次转折或争论:基于SDN的Openflow与VXLAN孰优孰劣
背景:随着公有云的真正崛起,以Google,Facebook ,Amazon为首的领先企业,依赖内部有网络研发经验的顶级技术架构师,设计出来了后来被称之为SDN的全新网络架构。SDN作为云网协同必备技术,SDN技术渐渐真正进入人们的视野,尤其是进入2016前后,从运营商、云商到OTT再到大的企业都已经开始大谈SDN网络规划和部署,甚至WannaCry蠕虫爆发时有人谈到利用SDN的方法抵御。但是由于SDN的特殊性和网络具体环境的复杂性,不同客户SDN的部署实际上千差万别,从刚开始基于Openflow的SDN流派、到网络厂商的私有SDN流派、再到后来基于开放VXLAN/EVPN的广义SDN流派,很多人经历了Openflow美好愿景到现实骨干的艰难探索。

典型需求:云服务商到OTT蔓延到大企业: 数据中心网络云网协同部署,秒级开通
焦点技术:OpenFlow和VXLAN EVPN,如何利用SDN技术实现云网协同
战役的主角:Underlay(传统网工)和Overlay 团队(云时代的新网工)
焦点技术1:基于Openflow的SDN技术
记得2015年左右SDN+Openflow技术架构成了最热的话题,OpenFlow技术最早由斯坦福大学提出,它的核心思想很简单,就是将原本完全由交换机/路由器控制的数据包转发过程,转化为由OpenFlow交换机和OpenFlow控制器分别完成的独立过程,控制平面与转发平面分离,把控制功能集中到一个中央大脑(OpenFlow控制器)。由于Openflow对控制器的过度依赖,一开始本人就对Openflow持怀疑态度,我常常和同事拿它和MPOA(ATM LANE)比较,由于流表需要从控制器获得,导致两个大问题:1 控制器负责流表处理,全网控制器成为一个大的安全隐患;2 另外控制器的性能会大大影响全网的性能和扩展能力,后来这个问题在一个OTT项目得到验证,当一个POD区域的服务器出现异常(如部分服务器掉电重启),Arp大量广播导致全网性能下降几乎不可用。
OpenFlow由于它的局限性实际部署的不算太多,是不是数据中心网络的一种过渡形态的昙花一现,仁者见仁智者见智,不在此做过多评价。好在SDN和OpenFlow并不是等号关系,SDN技术越来越多元化,越来越多的项目更倾向于由最初的传统的狭义SDN(基于Openflow)走向广义SDN,多元化的广义SDN技术依然可以大放光彩。
焦点技术2:基于VXLAN/EVPN SDN技术
第一次听到VXLAN技术还是在2012-13年左右,记得当时还在到处宣讲TRILL/OTV的时候,有一次和思科研发的一位大神K.F.交流,他告诉我TRILL/OTV架构还是太重了,另一个轻量级的Tunnel技术(就是今天VXLAN)将取代TRILL/OTV架构,当时给我当头一击,好不容易刚学会点皮毛的东西就要被抛弃,难道我们给客户推荐的技术又将被推倒重来, 后来事实也证明验证了大神的预言。
VXLAN(Virtual Extensible LAN)作为一种网络虚拟化技术,采用“MAC in UDP”封装形式并且基于IP网络的实现大二层技术,是一种用于实现大型云计算和数据中心的网络二层互通技术。VXLAN作为一种数据封装技术,其本身没有控制平面,其在转发数据前的表项学习,如arp表、VNI、VTEP地址等都是通过数据包的泛洪来完成,因此VXLAN数据转发前表项学习的泛洪流量一开始就是一个重要难题,好在VXLAN出来后网工们就开始制定它的控制层面的标准- BGP EVPN (RFC7432)标准的出现可谓及时雨宋江,大大促进了VXLAN的快速发展和普及,并为VXLAN和其它Overlay技术竞争中奠定了优势,基于BGP EVPN控制层学习L2和L3的可达信息,通过EVPN完成在VXLAN转发数据报文前ARP表项学习,主机路由学习和VTEP自动发现,VXLAN+EVPN成为云数据中心环境下网络的首选技术,为实现数据中心虚拟化、集群和云部署大二层网络奠定夯实了网络基础。详细技术SDNLAB上很多不再累述。

体会和点评:SDN将传统网络设备中的控制平面和转发平面进行功能解耦的概念,将整个物理网络抽象并简化为“单一”逻辑网络资源池,形成易于控制和管理的逻辑网络,人们很快接受这个新的理念和技术。这场SDN争论是非常冷静和温和的,网工们已经变得成熟,技术上没有ATM/MPoA轰轰烈烈的争论,也不像TRILL/DCB/FCoE那样和谐一致,由于有云计算爆发性业务发展,也就几年时间轻量级标准化的Overlay/VXLAN大行其道,VXLAN技术结合SDN将Underlay 和overlay 完美实现。有趣的是,对于Openflow两个最早的提出者 Nick McKeown和Martin Casado也都开始抛弃了Openflow; 基于Openflow的SDN虽然不被看好,但Openflow在有些方面可能依然有效,包括在HostOvelay环境一些ARP流表的主动下发,以及早期流量工程和服务链等方面, Google曾经成功基于Openflow实施的数据中心互联B4就是一个极佳的案例。两年前我们也曾想在Openflow做些流控安全或应用分担 L4-L7功能等,对国内外Openflow交换机进行了调研考察,但结果发现大多数厂商/白牌机都不生产那种带有足够容量的通用转发表,甚至以K为单位,不能满足在数据中心里使用的交换机或者L4-L7功能,一两家有大流表的交换机价格超出了想象。
另一方面,这一波浪潮明显感觉OTT和云服务商成为云网时代的领路者,前两次浪潮可以说是金融和大企业领跑行业数据中心和网络新技术。传统网工在这场战役明显失去了优势,云时代感觉就像进入了开源和码农时代,不少云网络技术团队分成Underlay 和Overlay 团队,传统网工只负责Underlay –基础网络的搭建,Overlay(VXLAN)由上层云管平台负责, 由于业务都是基于Overlay开通,传统网工如果只做Underlay就会和时代脱节,尤其是 OpenStack 和Docker 环境下。这个年代的网络江湖很难找到一统江湖的大师,因为既熟知基础网络(MPLS、 SR,、VXLAN、 EVPN、SD-WAN、SAN..),又懂得开源OpenStack、ODL/ONS、NFV、RestAPI和Netconf/Yang、Python、同时还要能侃侃Devops、微服务和IT架构的网工实属不易。
第四次风雨或焦点:基于SDN的Network Overlay与Host Overlay混合组网
背景:转眼2018年已过,虽然基于VXLAN和OPENFLOW 的SDN技术主会场已见分晓,但是云网技术的发展和演进还远远没有结束,还有很多技术分会场战斗还在继续探索,基于VXLAN 的Overlay由于其简单、易扩展等优势已经成为数据中心网络最炙手可热的技术首先。然而,基于软件的Host Overlay与基于硬件的Network Overlay如何选择?孰优孰劣?还是软硬结合协调工作 又给网工带来了新的挑战和争论,异构厂家的VTEP硬件设备的如何实现统一SDN管理而不是被厂商绑定?如客户希望思科、华为、H3C以及白牌机硬件多品牌设备按需选择,另外数据中心和骨干网以及接入SD-WAN如何实现统一管理?……
典型需求:Network Overlay与Host Overlay如何混搭? 多厂商异构组网?
战役的主角: 软件厂商(如OVS解决方案)和硬件网络厂商(硬件VTEP方案)
由于时间篇幅,下面简单聊一聊:典型的云环境包括基于主机的Network Overlay和 虚机VM 的Host Overlay的管理, 或公有云和BM托管云的管理,虚机有可能是 Openstack 也可能是 Vmware等;即使都选择VXLAN作为底层技术,但是由于Network Overlay和Host Overlay控制层面技术有机制不同(如 EVPN 、Openflow或其它),如何实现自动打通,VTEP终结在哪里,目前没有标准答案,不同场景有不同的探索;另一个热点是多厂商硬件VXLAN/EVPN的协同管理:目前厂商的SDN解决方案都是围绕厂商的设备做的SDN控制,一旦选择了一家厂商SDN方案,SPINE/LEAF 设备通常只能选这家厂商设备,SDN与设备的紧耦合违背SDN初衷也不利于客户的灵活选择。那么Network Overlay与Host Overlay孰优孰劣如何混搭? 多厂商异构组网?下面以大地云网(一家专注SDN的软件公司)经验分享一下,仅供参考:
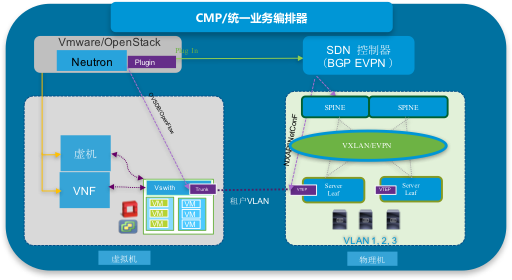
- 混搭模式一 极简中继模式:云宿主机处通过vlan Trunk与VTEP交换机互联, 利用PortVLAN等实现租户VXLAN关联。物理主机资源池为主,兼顾云主机资源池,支持虚拟环境有Openstack (或Vmware 环境)与物理服务器(BM)网络SDN统一管理,实现SDN控制器与Neutron的集成和对接。这种模式自动化部署、部署简单,方便实现云主机和物理主机统一管理;适合:物理主机为主,兼顾虚拟化和云环境的场景推荐使用。
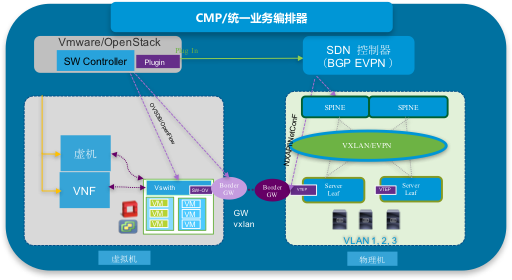
- 混搭模式二 GW模式:混合Overlay组网分别纳管自动部署,以Host Overlay为主,兼顾HW VTEP逻辑资源池, Neutron负责Host Overlay的管理,SDN控制器负责Network Overlay的管理,各自的Border GW实现打通双方租户信息,这种方式software的GW和hardware的GWHW通常只做L3租户打通,如果做L2打通还需要考虑很多因素包括Anycast GW 以及两边的Mac学习模式一致性等问题? 有人建议合并两个GW,但是由于管理界限不清,也会产生很多问题。这种架构看起来不够完美,如果做L3 租户打通部署相对起来简单, 做L2打通需要设计和考虑复杂一些。适合:云环境主机为主,兼顾物理机的场景推荐使用。
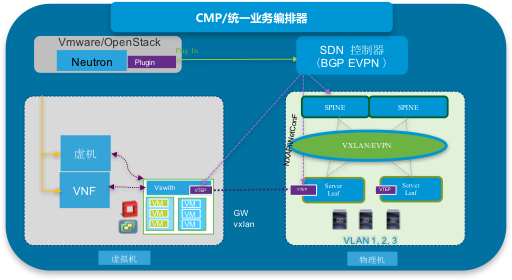
- 混搭模式三 统一纳管模式:混合Overlay组网由SDN控制器统一纳管,实现租户的VM与BM物理机实现基于VXLAN大二层互通,将VTEP延展到虚机层面。每台宿主机装一套VTEPAgent , 通过Evpn 与其他硬件或软件VTEP建立连接并交换 L2 和L3 entries,租户的VM与BM物理机通过VXLAN实现灵活大二层互通。这种架构理论很好,但是有的厂商VTEP的Peer数量有一定限制,如果VTEP Agent设计不好会造成很大的问题和隐患,当然这种模式也存在被厂商锁定的风险。

- 异构环境VXLAN的协同编排和管理:目前厂商的SDN解决方案都是围绕厂商的设备做的SDN控制,一旦选择了一家厂商SDN方案,SPINE/LEAF 设备通常只能在这家选择,不利于客户的灵活选择。 对于大型企业和服务商、云商,希望能够基于标准的南向支持NetConF/Yang/CLI等协议控制和管理多厂商物理设备, 好在在开源和开放的大趋势下,各个厂商物理交换设备支持VXLAN/EVPN 和NetConF以及开放北向API等,而且在运营商、云商已经开始探索和成功部署多厂商SDN协同编排器,利用统一的SDN协同编排器实现多厂商设备的解耦,整合异构多厂商设备。这方面大地云网作为独立的第三方SDN软件控制器厂商,提出了一套松耦合SDN技术架构,如右图所示,大地云网TerraFabric Controller可以实现思科、华为和H3C多厂商设备的统一纳管控制器,实现SDN网络与设备层面的解耦,以及可以实现Openstack,Docker和多家云管平台对接或定制开发。
结束语和展望:20年来在IT同仁和网工的共同努力下,数据中心网络技术经历了一个百家争鸣、架构混乱逐步走向融合、统一和通用的新时代,数据中心和SDN网络经过这几次起起伏伏和演变,硝烟基本落定;但是SDN网络技术作为开放软件架构在开放性、通用标准和互操作还有很多路要走:从SD-WAN到数据中心SDN网络的未来会不会采用统一技术(如VXLAN,SRTE)以及如何实现统一编排管理?在异构环境下混合Overlay组网以及L4-L7 &Docker的协同管理?如何将AI技术引入流量感知、调度和风险管理(提供精准的智能调度能力以及流量与业务关联分析)还有很多事情要做;未来的在运营商、OTT和云商的云网建设经验在大型企业能否复制也值得探讨。但不论如何,SDN和云计算作为未来IT发展的两大最基本的创新引擎势不可挡,作为一名网工只有在这一次次浪潮中不断的学习不断地接受洗礼并调整自己才能适应时代的发展,路漫漫而修远兮,让我们不忘初心,拥抱2019。
由于本文涉及到众多技术,有些内容是个人的观点,仅供参考,在这里也要感谢一下大地云网Shawn同学给予的很多建议。







