作者简介:张渐修,任职于上海同悦信息科技有限公司从事SDN/P4交换机的市场推广工作。
Barefoot公司的愿景很简单:就是让数据中心交换机和服务器一样享有开放性和可编程性。因此Barefoot公司推出了P4网络编程语言并与Google公司一起创建了开源社区,更为重要的是Barefoot芯片工程师辛勤努力的成果证明可编程芯片可以在速率、带宽、成本、功耗以及组网等诸多方面与固定功能交换机ASIC芯片保持同等水准。随着Tofino2以太网交换芯片的推出,Barefoot公司终于有机会将逐渐升温的可编程交换最终变现。

其实可编程交换在数据中心无可避免的主要动因和当年计算在数据中心面临的变革是一样的,只是时光流转,变革终于发生在交换领域。Barefoot公司创始人兼首席科学家Nick Mckeown有张数见不鲜的老图如下:
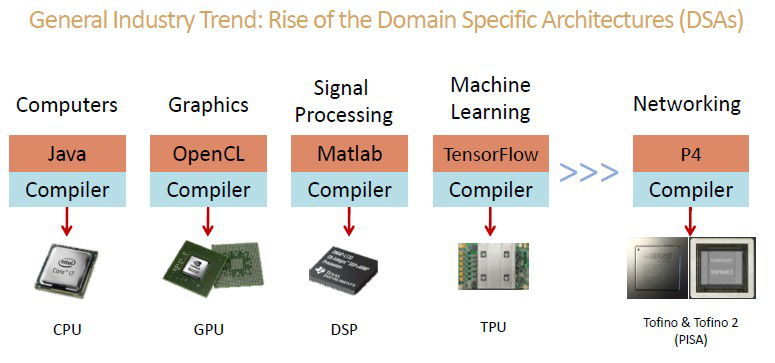
云服务提供商尤其是巨无霸们的一个趋势是自产出很多芯片,尤其是近几年来芯片不再是传统芯片厂商的专利,云服务商们借势推动芯片向特定领域发展。比如GPU不仅仅应用于图形领域,机器学习也有它的身影,还有TPU和其它AI和机器学习芯片,他们的共同特点都是基于可编程的芯片和针对特定领域的指令集,然后将高级语言编译后实现特定功能。
固定功能交换芯片和全可编程芯片在报文处理上有很大不同,下图很好的解释了两者的差异:
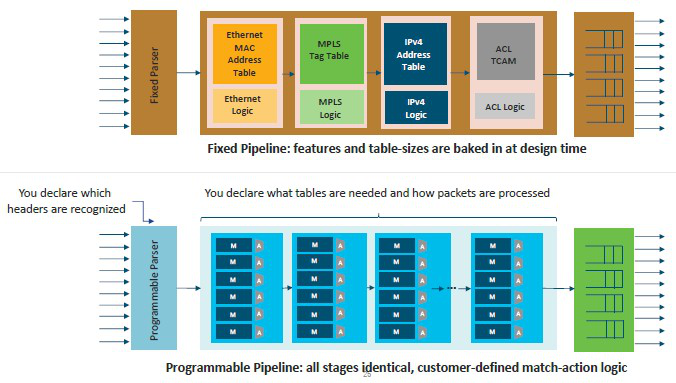
正常人都会想到的问题就是代价,其实可编程性并不会对功耗、性能或者成本带来很大的影响,否则高大上数据中心也不会考虑这种方案。和每一项新技术都一样,通常只有高大上的数据中心才会有足够的技能和强烈的需求来率先部署可编程网络,其它IT环境只会等到新技术成熟后直接享受果实。
Barefoot最终呈现出来的可编程芯片到底是骡子是马?下图第一代Tofino与某固定功能交换芯片的对比很好的说明了问题。高度谨慎猜测这款芯片是StrataXGS系列的Tomahawk 2。
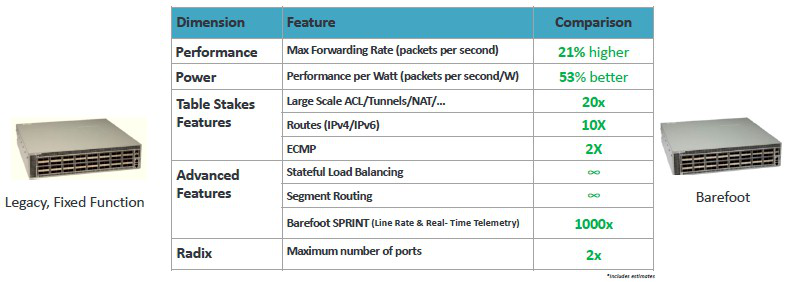
随着超大规模数据中心和云建设商设计生产自用芯片,以及Nvidia,Xilinx和Intel收购的Altera等公司谋划将自家的GPU或者FPGA应用于更广阔的计算领域,有理由相信他们的产品将具备更加灵活的可编程能力。
不过Barefoot公司创始人McKeown不惧挑战。“这些公司不可能比我们做的更好,因为我们的团队长久耕耘网络领域。他们中的某些人在尝试可编程的智能网卡,这里面涉及的交换技术很难。因为将可编程网络功能卸载到智能网卡没有先例,一切都要靠自己动手实现,所以无论从经济角度还是从维持团队规模角度这都不是最佳选择。这些方案的最大区别就是他们有不同的软件,而我们已经提供了可编程芯片,他们继续下去的意义并不是很大。看看我们客户对Tofino的使用,各家都有不同。在过去只有固定功能芯片的时代,很多差异化功能没法实现,所以每家产品看上去都大同小异。但是通过我们的可编程芯片,无论是Cisco还是Arista对Tofino芯片都有不同用法,这就是我们的设计初衷。对于采用Tofino的云服务商来讲,无论他们是在中国还是美国,他们的网络设计各不相同,这仅仅需要对网络做不同的编程实现。”
行走在网络可编程的路上
Barefoot公司2016年6月推出第一代Tofino交换芯片,目标直指数据中心的最后一个封闭堡垒,他们坚信其它ASIC厂商会响应这一呼声并合力打开盒子。他们实现了目标,尤其是超大规模数据中心和云建设商开始接纳真正的开放网络,不仅仅是用商用芯片加上一个开放的网络操作系统,而是第一次将最底层用于控制层面和数据平面的芯片实现了可编程。Tofino芯片还被用于在机器学习集群中卸载部分功能达到提速增效的目的。Arista作为网络交换芯片领域的用户代表已经推出基于Tofino的交换机产品,同样Cisco在自家产粮的情况下也很快推出了基于Tofino的Nexus 3400交换机。
预计在2019年以及2020年,通过这些早期的积累可编程交换机会加速进入市场。因为有些OEM/ODM已经在Tofino1芯片上具备经验,所以设计Tofino2芯片的速度会更快,这一次设备厂商也不需要再花费2年的时间才能将产品推向市场。
Tofino2芯片采用50Gb/sec信号和PAM-4编码, SERDES带宽相比前一代增加一倍,因此芯片的总带宽达到12.8Tb/sec。Barefoot和大部分推动制程发展的芯片设计公司一样选择台积电(TSMC)为代工厂,Tofino1当时采用的是16nm技术,Tofino2依然选择TSMC合作。不过Tofino2严格意义上讲不是一颗芯片,它是多颗采用不同制程芯片的组合体。
这种多制程Chiplet策略同样被AMD公司应用于代号为Rome(罗马)的Epyc服务器芯片以及被Xilinx公司应用于代号为Evest(珠穆朗玛峰)的Cersal系列FPGA。这项技术是未来芯片的发展方向,虽然它会稍微增加生产的复杂度,但是小尺寸芯片比大尺寸芯片有更高的产率,并且老制程比新制程也有更高的产率。某些电路,比如内存控制器,I/O控制器和通信控制器,过于追求新制程时反而会使得实际表现更糟糕,与CPU或者FPGA上用于数据处理的核心计算单元或者交换芯片上的报文处理单元相比,他们更适合大尺寸的晶体管,对芯片的整体设计而言这种方案利大于弊。在Rome Epycs芯片中,核心I/O和内存控制器位于芯片的中央采用14nm制程,而CPU核采用7nm制程通过Chiplet的方式散布在中央周围,从而保证性能达到最佳。
Barefoot并未透漏Tofino2的详细生产工艺,只是确认芯片封装的核心位置采用7nm制程,包围核心用于实现50Gb/s信号的I/O组采用的是TMSC前一代的工艺,我们猜测是过渡性的12nm制程,Nvidia曾用来生产代号Volta的GPU芯片。

这种模块化架构的意义不仅仅是简单用不同制程生产芯片的不同的部分,它实际上通过模块化使得设计者可以混合匹配、增加删减芯片封装中的不同组件,从而实现具有不同价格的差异化芯片。比如,每通道56Gb/sec的Serdes在经过前向纠错和编码后可实现50Gb/sec的速率,当有一天每通道更高速度的112Gb/sec的Serdes可实现100Gb/sec的速率时,设计者不需要改变核心的报文交换部分,只需要更换Serdes就可以快速推出新一代芯片。目前看112Gb/sec的serdes还需要2年的时间。芯片的封装也可以调整为驱动铜缆或者光模块,甚至在将来更换为硅光模块。通过减少交换核心并相应减少芯片封装的SerDes模块数目还可以生产出更少管脚的芯片,因此Tofino2相对于一代芯片可以变化出更多的产品线,这也是Barefoot公司正在做的事情。
Tofino2芯片的高端12.8Tb/sec版本将支持3种不同的规格:32路400Gb/sec端口,128路100Gb/sec端口和256路50Gb/sec端口,同时50Gb/sec端口可以降速到25Gb/sec或者10 Gb/sec。在顶配的12.8Tb/sec之外还会有带宽为8Tb/sec和6.4Tb/sec两个系列,其中6.4Tb/sec版本与Tofino一代具有相同带宽,50Gb/sec、100Gb/sec和400Gb/sec端口均是最高版本的一半。Tofino一代芯片支持的不同规格为1.9 Tb/sec、2.5 Gb/sec、3.3 Tb/sec和6.5 Tb/sec。
Tofino2产品线不仅仅根据带宽来划分芯片系列,还会根据构成报文转发核心的报文处理引擎(PPE)的数目来划分。Tofino一代有48个PPE,Tofino2根据不同系列会有24、48或者80个PPE,同时系列芯片包含的网络功能加速器也有不同,如下图所示。
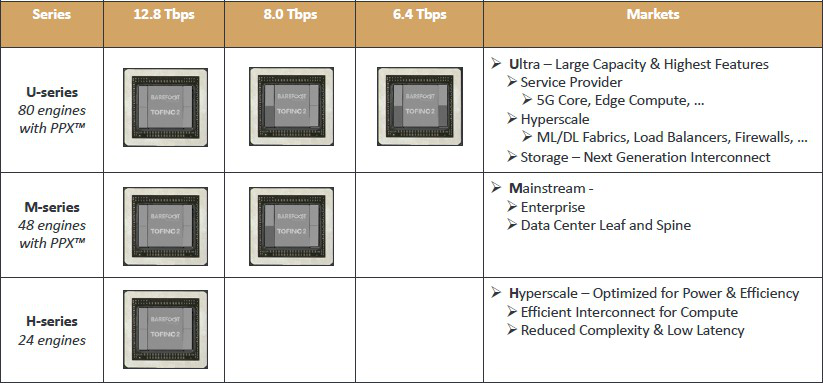
所以通过组合不同带宽和引擎数目,Tofino2芯片可以有不同的价格区间。H系列定位于超大规模,只有24个引擎但是交换带宽可达12.8Tb/sec,具有最低的延时和最优惠的价格;M系列定位于主流的企业级市场的ToR交换机和大型数据中心的Leaf/Spine网络,具有8Tb/sec或者12.8Tb/sec的带宽以及和Tofino一代相同的48个引擎;U系列是高端产品,具有数目最多的80个引擎,但是三种带宽模式均可选。它定位于运营商市场服务于5G,边缘计算以及那些超大型数据中心客户想要把诸如负载均衡和防火墙等软件功能都包含在交换机当中。它还考虑运用于存储集群市场,在高带宽需求的同时需要把一些计算工作卸载到交换机当中。Barefoot通过去除SerDes模组来调整带宽,上图中没有展示出的Tofino2 Advanced系列芯片运行在6.4Tb/sec(意味着芯片只有2条SerDes模组),目标市场包括NFV卸载,计算卸载以及网络应用层实现。
这种卸载应用至关重要。McKeown提到一个中国的数据中心客户通过运行于Tofino芯片的P4程序,取代了之前运行于200台x86服务器之上的负载均衡工作,而且是线速处理。(当时是指UCloud喽,点赞!)这仅仅是刚刚开始。
Mckeown解释说:“我是这样认为的,网络是由服务器上的软件,经过网卡、柜顶交换机以及多层交换机最后到达链路对端的服务器上的软件组成,整条流水线的行为如果都采用相同的P4语言来定义是最理想的状态,此时用户可以完全自主选择网络功能和特性的分割,可以根据最佳匹配,最高效率,最佳方案,甚至是根据你拥有的硬件资源来决定在何处实现何等功能。
你说在这样一个世界服务器和交换机的边界到底在哪里?
Tofino系列可编程芯片还有一个很大的场景就是Barefoot公司称之为计算网络的应用,它类似于Mellanox公司为HPC和AI提供的InfiniBand交换机,Barefoot公司基于可编程的方式提供同样的功能,不过是通过在机器学习集群内部的P4可编程交换机上运行参数服务器来实现。
McKeown认为计算网络应用刚刚开始。我们碰到很多考虑可编程交换机的客户,当他们意识到可以通过Tofino网络来实现大量的计算任务时都大为震惊,这件事情是他们长久以来就想做但又无法在固定功能芯片中实现的。不仅仅是上面提到的机器学习,只要是连接交换机的服务器涉及到Key/value存储,你就可以利用交换机来缓存热数据。Memcached很适合做分布式存储,它虽然很小但是因为热数据被频繁访问,所以利用交换机上相对很小的存储区就可以大幅提升访问性能,同时降低由于热数据访问而形成的尾延时。很多人刚开始觉得难以置信,会问我们缓存在什么位置,但是经过一段使用后他们就会明白因为所有处理都是线速所以并不需要特殊缓存。任何程序经过编译后运行在Tofino芯片上都会是线性处理,它就是单向流架构,所以一点也不需要考虑性能调优的问题,运行起来就是全速。因此对于计算网络应用,Tofino方案非常简单,它天然就是实时处理,用户不需要再担心中断等类似问题。
在某个时间节点,Broadcom或者Cisco或者Mellanox或许会收购Barefoot,听上去很有道理。或许是AMD或者Intel,服务器会逐步被交换机取代(编辑您是认真的吗?难道上面的案例就能说明服务器要被交换机取代?),当交换芯片中加入更多的存储模块和FPGA加速器,会有更多的服务器会被取代(欢迎微信Cloudefinetworking交流关于Barefoot的怪论)。或许Intel应该收购Barefoot而不是收购Qlogic和Cray的互联业务,当然AMD迅速搞定Barefoot也不晚!
无论如何,Tofino2芯片预计在2019年的上半年提供样片,OEM/ODM会在9个月内提供设备,在超大型数据中心和云服务商场景可能会最早得到应用。