

作者简介:喻津,Intel软件工程师, 主要从事SPDK软件开发工作。
本文转载自DPDK与SPDK开源社区
导读
随着SPDK集成应用的日益广泛,我们希望可以通过解读spdk/example/nvme/perf这个应用,让大家进一步熟悉SPDK用户态驱动的主要工作流程和方式,以及SPDK是如何实现高性能的服务。
什么是SPDK
Storage Performance Development Kit (SPDK)提供了一组用于编写高性能、可伸缩、用户态存储应用程序的工具和库。SPDK的基础是用户态、轮询、异步、无锁 NVMe 驱动。这提供了从用户空间应用程序直接访问SSD的零拷贝、高度并行的访问。
Perf Case的解析
Perf是SPDK用来测试NVMe SSD 性能的工具,它的代码在spdk/example/nvme/perf路径下。Perf主要用来测试NVMe SSD的IOPS, Bandwidth和Latency,它既可以测本地的target,也可以测远端的target,本文解析主要以本地target为主。
perf代码实现的框架如图1所示。
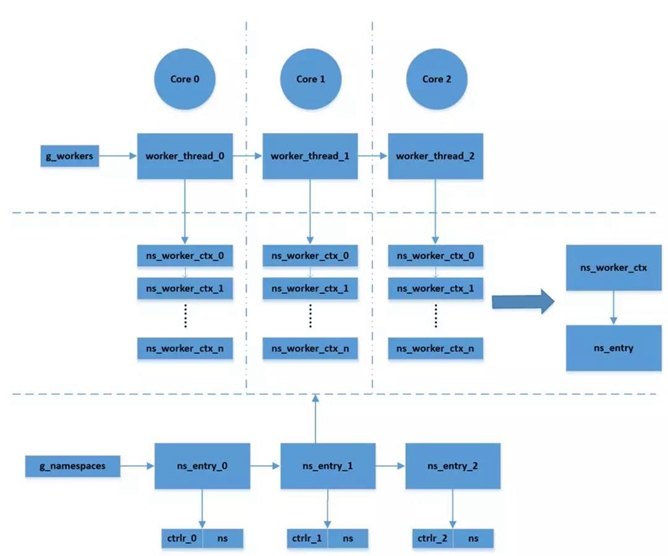
Worker_thread和core是一一对应的,根据core 的数量创建对应的worker_thread。Ns_entry和controller(ctrlr)一一对应,根据NVMe SSD的数量创建对应的ctrlr和ns_entry。Work_thread和ns_entry通过ns_worker_ctx联系起来,联系的规则如下:
- ns_worker_ctx_nums = work_thread_nums > ns_entry_nums ? work_thread_nums : ns_entry_nums;
- 根据ns_worker_ctx_nums,创建ns_worker_ctx并同步循环遍历g_workers和g_namespaces,每个ns_worker_ctx指向一个ns_entry,然后ns_worker_ctx挂到worker_thread指向ns_worker_ctx的链表中;
所以:
- 如果core_nums == ctrlr_nums,则一个core对应一个ctrlr;
- 如果core_nums > ctrlr_nums,则存在多个core对应同一个ctrlr。例如core_nums 2, ctrlr_nums 1,则两个core对应同一个ctrlr;
- 如果 core_nums < ctrlr_nums,则存在一个core对应多个不同的ctrlr;
等到ns_work_ctx建立完毕后,就给每个core绑定一个work_fn,在每个work_fn中做同样的事情,流程如图2所示:
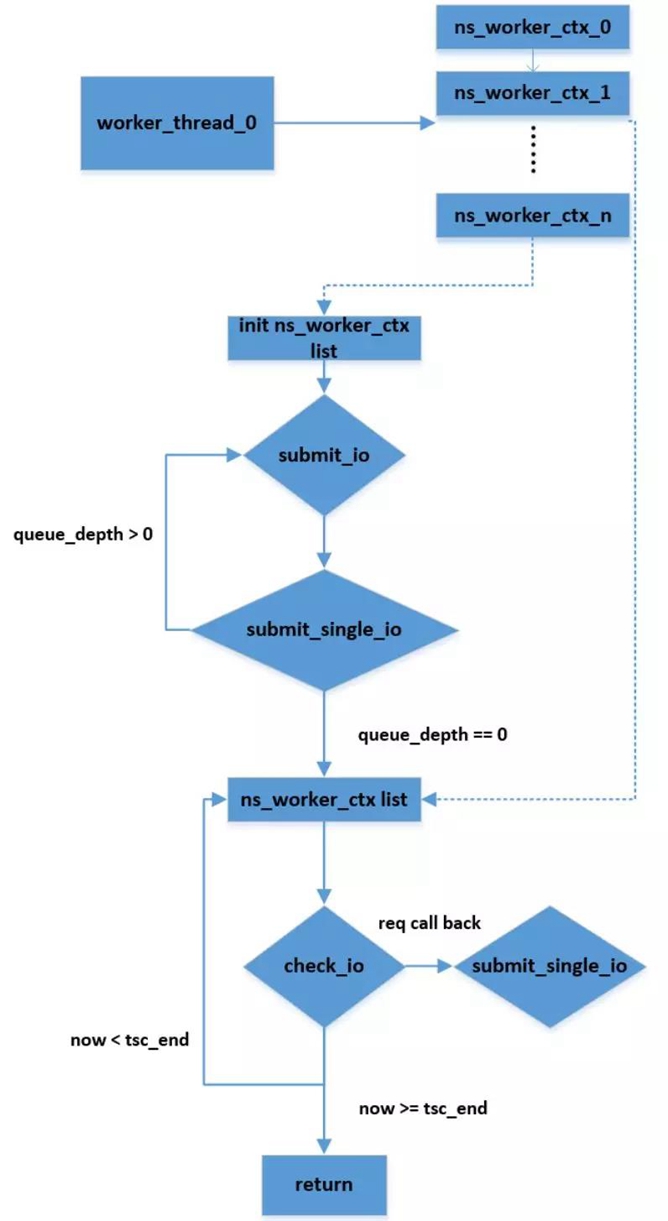
- 首先初始化worker_thread指向的ns_worker_ctx链表,主要就是给每个ns_worker_ctx指向的ctrlr申请一个io_qpair;
- 遍历ns_worker_ctx链表,向每个ns_worker_ctx指向的ctrlr发送queue_depth个io request到io_qpair。
- 循环遍历ns_work_ctx链表,检查每个ns_work_ctx指向的ctrlr的io request的完成情况。如果io request已经完成就在io complete callback中重新发送io request。遍历完一次链表之后就检查一下时间,如果超过指定的时间就退出,否则继续。
在到达预期的运行时间后,所有的core退出work_fn。最后遍历g_workers以ns_work_ctx为单位计算性能数据。
那么perf是如何计算性能数据的呢?
Perf计算性能数据的公式简单,直接。在submit_single_io()中提交io request时记录每个io request提交的时间,然后在io complete callback 也就是io_complete()中记录io request的完成时间,计算io request的用时并加到ns_work_ctx->total_tsc,同时增加io request的完成量ns_work_ctx-> io_completed++,最后用io request的完成时间和ns_work_ctx中已存的max_latency和min_latency比较,更新。
Ns_work_ctx的各个性能参数IOPS,Bandwidth,Average Latency,Min Latency和Max Latency的计算公式如下:
|
1 2 3 4 5 6 7 8 9 |
IOPS = ns_work_ctx->io_completed / expected_time; Bandwidth = IOPS * io_size; Average Latency = ns_work_ctx ->total_tsc / ns_work_ctx->io_completed; Min Latency = ns_work_ctx->min_tsc; Max Latency = ns_work_ctx->max_tsc; |
总的性能数据就是把所有的ns_work_ctx的数据相加。
展示完性能数据后,释放申请的资源。至此,一次perf测试结束。
SPDK的高性能实现
通过解析perf我们可以一窥SPDK的高性能是如何实现的。
用户态的驱动
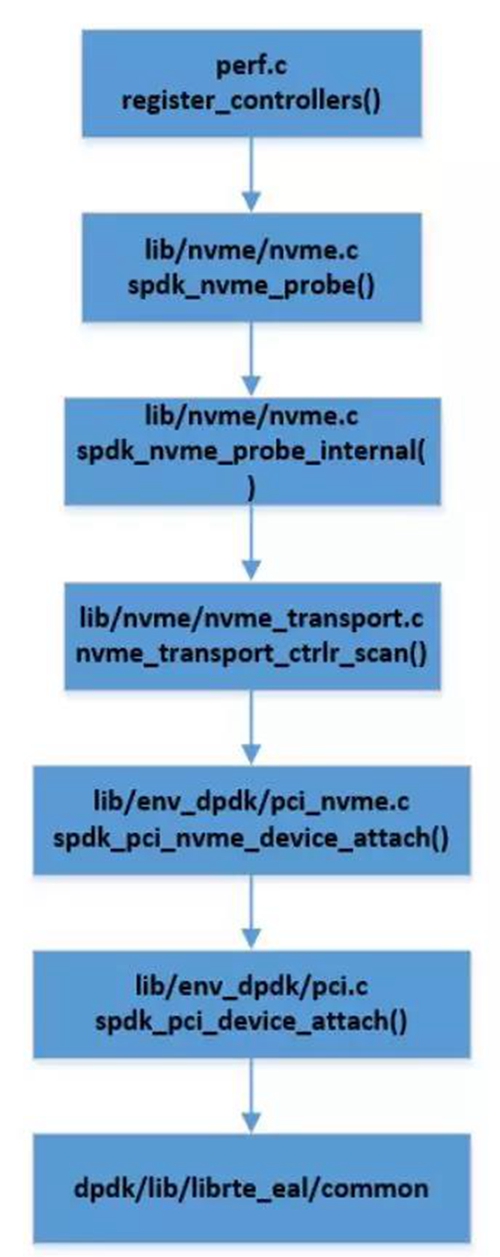
perf.c的代码中用register_contollers注册ctrlr,追踪它的实现如图3所示,到最后是依赖DPDK EAL 层的实现。
事实上SPDK的用户态环境是建立在DPDK EAL层的基础之上的,所以SPDK的程序在开始都需要进行DPDK EAL层的初始化。例如perf.c中,在程序开始的位置就调用了spdk_env_init()。
如果想要详细了解perf.c中userspace driver的实现,需要把register_contrllers()和rte_eal_init()->rte_bus_probe()结合起来看,这一部分的代码的逻辑不是太简单。
简单来说它主要是利用UIO/VFIO驱动把PCIe设备的相关信息,如配置空间和bar空间,通过/sys接口暴露出来,SPDK利用这些信息构建用户态的ctrlr来驱动这些设备,从而实现了用户态的驱动和zero copy。这些实现的前提需要用UIO/VFIO驱动替换device默认的驱动,这也是为什么在跑SPDK的case之前需运行spdk/scripte/setup.h,它的主要作用之一就是把driver替换成UIO/VFIO。
在multi-processes的情况下,用户态的驱动实现有稍许不同。上面讲的是master process的处理过程,由于slave process和master process共享memory,所以对于已经在user space实现了的ctrlrs,slave process可以直接拿过来用的,而不用再额外建立。带来的明显的好处是节约了内存,其次ctrlr的状态变化,可以直接反馈到多个进程。perf.c的代码中用register_contollers注册ctrlr,追踪它的实现如图3所示,到最后是依赖DPDK EAL 层的实现。
事实上SPDK的用户态环境是建立在DPDK EAL层的基础之上的,所以SPDK的程序在开始都需要进行DPDK EAL层的初始化。例如perf.c中,在程序开始的位置就调用了spdk_env_init()。
如果想要详细了解perf.c中userspace driver的实现,需要把register_contrllers()和rte_eal_init()->rte_bus_probe()结合起来看,这一部分的代码的逻辑不是太简单。
简单来说它主要是利用UIO/VFIO驱动把PCIe设备的相关信息,如配置空间和bar空间,通过/sys接口暴露出来,SPDK利用这些信息构建用户态的ctrlr来驱动这些设备,从而实现了用户态的驱动和zero copy。这些实现的前提需要用UIO/VFIO驱动替换device默认的驱动,这也是为什么在跑SPDK的case之前需运行spdk/scripte/setup.h,它的主要作用之一就是把driver替换成UIO/VFIO。
在multi-processes的情况下,用户态的驱动实现有稍许不同。上面讲的是master process的处理过程,由于slave process和master process共享memory,所以对于已经在user space实现了的ctrlrs,slave process可以直接拿过来用的,而不用再额外建立。带来的明显的好处是节约了内存,其次ctrlr的状态变化,可以直接反馈到多个进程。
轮询
Perf.c中轮询操作体现的很明显。在worker_fn中,我们提交完io request之后,就一直通过轮询的方式来判断io request是否完成。SPDK架构中也是通过这样的方式,而不是依靠中断,这样带来的好处是降低总延迟和延迟抖动。
无锁
无锁在perf.c中体现的比较简单,实际上SPDK架构的无锁设计和它类似,但是比它要复杂的多。SPDK会把任务和core绑定,通过消息传递的机制把任务送到对应的core上执行。Perf.c中每个core独立运行,不会和其他的core产生竞争,当多个core操作一个controller,通过初始化ns_worker_ctx时创建不同的io_qpair实现操作隔离,这样多个core可以并行读写。不过需要注意的是过多的io_qpair会提高设备调度复杂度和延时。
如何实现一个简单test case
通过perf.c的实现,我们整理一下SPDK中NVMe的实现层次和逻辑,然后看看如果要实现一个简单的case,我们需要哪些步骤。
SPDK中一个简单的NVMe 的模型如图4所示,用户看到的最小单位的是namespace,一个ctrlr可以有多个namespace, ctrlr的底层实现依赖于transport type,用户看到的就是一个ctrlr,不用关心底层的实现。
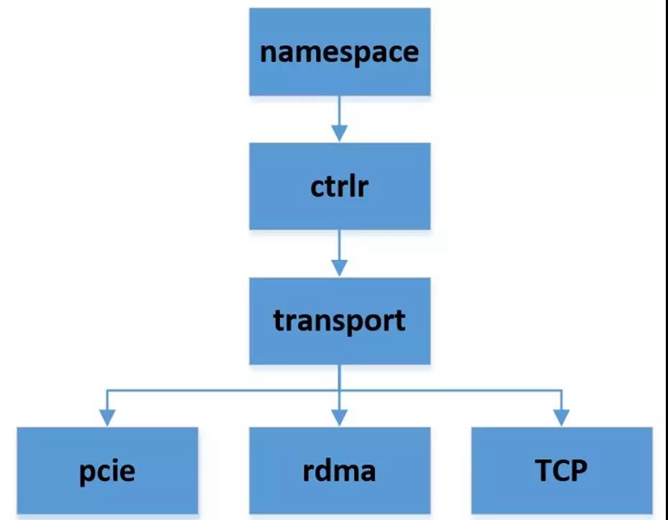
我们对设备的所有操作,最终都是围绕着ctrlr进行的,无论是读或者写。
从perf.c中提取出来一个简单case的实现步骤如下:
- 指定想要操作的物理设备,本地或者远端目标。例如,本地就是PCIe + BDF,远端就是rdma+ip addr + port 等。
- 初始化DPDK EAL 层。可以用spdk_env_init();
- 注册ctrlr。可以用spdk_nvme_probe();
- 创建io_qpair。可以用spdk_nvme_ctrlr_alloc_io_qpair();
- 发送io request到device。这个时候可以通过namespace,或者直接通过ctrlr,不过推荐使用namespace,前者实现起来更简单。可以用nvme_ns_cmd.c中的接口。
- 检查IO request的完成情况。可以用spdk_nvme_qpair_process_completions()。
这样一次简单的io操作就完成了。
小结
Perf是SPDK下用来测试NVMe SSD盘性能的工具,通过解读perf的代码,可以弄清楚它的性能数据是如何测试,计算。另一方面,也可以窥视SPDK是如何实现高性能的服务。









