

作者简介:郑敏先,任职于诺云信息系统(上海)有限公司,担任售前工程师。从事SDN、白盒交换机等开放网络关产品的推广工作。
王国维在《人间词话》中说:古今之成大事业、大学问者,必经过三种之境界:“昨夜西风凋碧树,独上高楼,望尽天涯路。”此第一境也。“衣带渐宽终不悔,为伊消得人憔悴。”此第二境也。“ 众里寻他千百度,蓦然回首,那人却在,灯火阑珊处。”此第三境也。

白盒交换机的应用上也有三个境界,一、白盒交换机+商业交换机OS ; 二、白盒交换机+自研交换机OS; 三、自研交换机+自研交换机OS 。 今天本人翻译一篇达到第三境界的Facebook于2018年Sigcomm 会议上发表的论文。作为OCP/开放网络的武林盟主,Facebook 分享的这篇武功秘籍有很多干货,总结了Facebook在过去五年间为大规模生产环境数据中心构建的开发、部署、运营和开源的交换机软件的历程。
FBOSS:大规模构建交换机软件
英文原作者:
Sean Choi,Stanford University,Boris Burkov,Facebook, Inc.,Alex Eckert,Facebook, Inc.,Tian Fang,Facebook, Inc.,Saman Kazemkhani,Facebook, Inc.,Rob Sherwood,Facebook, Inc.,Ying Zhang,Facebook, Inc.,Hongyi Zeng,Facebook, Inc.
摘要
在网络设备上运行的传统软件,例如交换机和路由器,通常是设备商提供的,专有且闭源。因此,它往往包含单个运营商永远不可能被充分使用的无关紧要功能。此外,超大规模云数据中心网络通常都会有交换机供应商可能无法很好解决的软件和操作要求。
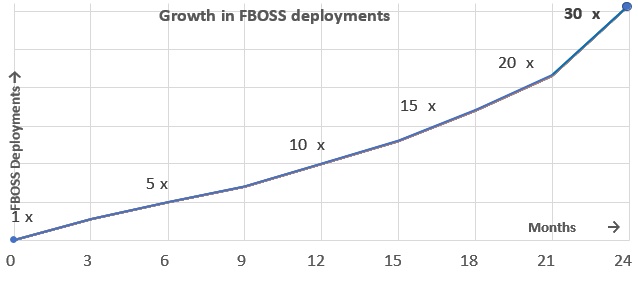
在本文中,我们会介绍Facebook在设计、开发、部署和运行内部软件时所面临的复杂性和扩展问题的持续经验,这些软件旨在管理和支持ICP(互联网内容提供商)大规模数据中心交换机所需的一组功能。文中介绍了我们自己的数据中心交换机软件FBOSS,它是基于我们的Switch-as-a-Server(交换机即服务器)和早期部署和迭代原则而设计的。我们将在数据中心交换机上运行的软件视为在商用服务器上运行的软件服务。我们还构建和部署最少数量的功能并对其进行迭代。这些原则使我们能够快速迭代,测试,部署和管理FBOSS。在过去的五年中,我们的经验表明,FBOSS的设计原则使我们能够快速构建稳定且可扩展的网络。作为证据,我们在两年的时间内成功地将数据中心运行的FBOSS实例数量增加了30多倍。
关键字
FBOSS, Facebook, Switch Software Design, Data Center Networks, Network Management, Network Monitoring
1 介绍
当今时代对在线内容的制作、消费和分发的渴望正以前所未有的速度增长。与这种增长相适应,在扩展物理网络方面同样是前所未有的技术挑战。大型互联网内容提供商被迫在其技术堆栈的各个方面进行创新,包括硬件、内核、编译器和各种分布式系统构建块(Building Block)。一个驱动因素是,在超大规模网络中,即使相对适中的效率改进也会产生很大的影响。对我们而言,我们的数据中心网络为拥有数十亿用户的大规模云互联网内容提供商提供支持,互连数十万台服务器。因此,对在交换机上运行的软件进行创新是很自然和必要的。
传统的交换机通常带有供应商编写的软件。这些软件包括用于管理专用分组转发硬件(例如 ASIC、FPGA或NPU)、路由协议(例如 BGP,OSPF,STP,MLAG)、监视和调试功能(例如 LLDP,BFD,OAM)、配置接口(例如:传统的CLI,SNMP,NetConf,OpenConfig),以及运行现代交换机所需的其他的一些功能。设备商模型中隐含的假设是不同客户的网络需求是相同的。换句话说,设备供应商是成功的,因为他们可以开发少量型号的产品并在许多客户中重复销售它们。但是,我们的网络规模和网络增长率(图1)与其他大多数数据中心网络不同。这意味着我们的要求与大多数客户完全不同。
运行大型网络的主要技术挑战之一是管理多余的网络功能的复杂性。供应商提供适用于其整个客户群的通用软件,因此他们的软件包括所有客户在产品生命周期内请求的所有功能的联合。但是,更多功能会导致更多代码和更多代码交互,最终导致错误、安全漏洞、操作复杂性和停机时间增加。为了缓解这些问题,许多数据中心网络都是采用简化设计,只使用精心挑选的网络功能子集。例如,微软的SONiC专注于在交换机中构建“精益堆栈”[33]。
我们的另一个网络扩展挑战是保持网络稳定性的同时实现高速创新。能够及时且大规模地测试和部署新想法非常重要。但是,供应商提供的软件模型中固有的特征是,更改和功能的优先级取决于它们与所有客户的关联程度。我们经常拿出来讲的一个案例是IPv6转发,由于大量客户的需求,它很快就被我们的某个供应商实现。但是,我们的运营工作流程的一个重要特征是对IPv6的细粒度监控,我们会根据自己的运营需求快速实施。如果我们将此功能留给大众市场并由供应商实现,我们就不会提前拥有这个功能。实际上直到四年之后,这个IPv6功能才在市面上出现。
近年来,构建网络交换机组件的实践变得更加开放。首先,出现了不自研ASIC芯片的网络供应商。相反,它们依赖于第三方芯片供应商,这些芯片即常说的“商业芯片”。然后,商业芯片供应商以及盒式/框式交换机制造商的出现,创建了一个新的解耦生态系统,用户可以购买不带任何软件的硬件交换机。因此,终端客户现在可以从头开始构建完整的自定义交换机软件堆栈。
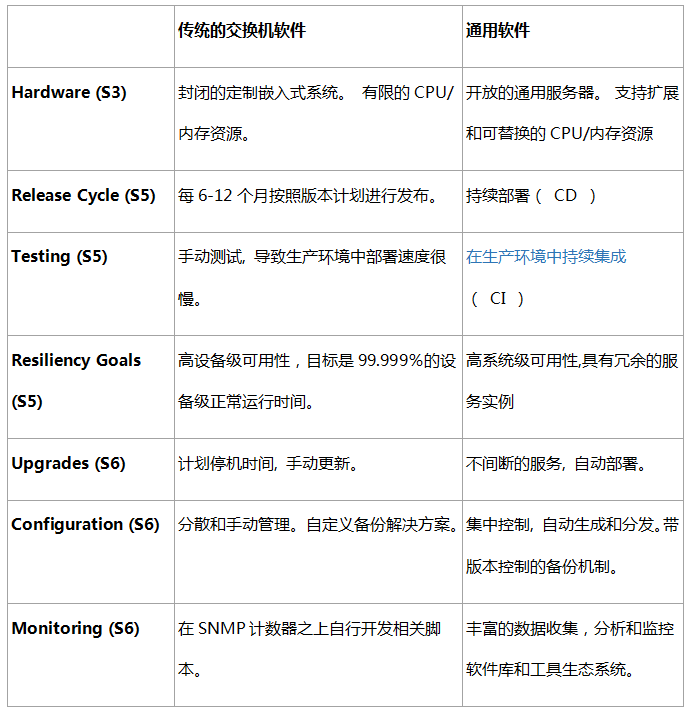
由于这种趋势,我们在五年前开始了一项构建我们内部设计的交换机软件的实验。我们的服务器集群已经运行了数千种不同的软件服务。我们想看看我们是否可以像运行服务器软件服务一样运行交换机软件。该模型与传统网络软件的管理方式截然不同。表1总结了二者之间的差异[17]。
最终我们开发出了Facebook开放交换系统(FBOSS),它现在是我们数据中心基础设施中很重要的一环。在本文中,我们对过去五年间有关构建、部署和管理FBOSS的经验做报告。本文的主要目标是:
(1)提供有关交换机上运行的软件内部工作的一些背景信息,包括挑战、设计权衡和改进机会,包括所有网络交换机软件的摘要和我们特定的实用设计决策。
(2)描述FBOSS的设计、部署监控自动化工具和补救方法。
(3)提供管理大规模云数据中心交换机软件时遇到的经验和代表性问题。
(4)鼓励交换机软件更易访问/开放领域的新研究,并提供一种工具—— 一种开源版本的FBOSS [4],用于在真实硬件上评估的现有网络研究。
本文的其余部分行文结构严格遵循表1的结构,如下:我们首先提供了一些指导FBOSS开发和部署的设计原则(第2节)。然后,我们简要介绍大多数数据中心交换机软件需要管理的主要硬件组件(第3节),并总结在我们的系统中做出的具体设计(第4节)。然后,我们描述相应的部署和管理目标和经验(第5节,第6节)。我们描述了三个操作挑战(第7节),然后讨论我们如何成功克服它们。我们进一步讨论影响我们最终设计的各种主题(第8节),并为未来的工作提供路线图(第9节)。
2 设计原则
我们设计的FBOSS有两个高级设计原则:
(1)在我们的交换机上部署和演进软件,正如我们在服务器一样(Switch-as-a-Server)。
(2)使用早期部署和快速迭代(Deploy-Early-and-Iterate)来强迫我们拥有一个只使用严格需要的功能的最低复杂度网络。这些原则在业界得到了响应 - 其他一些定制的交换机软件工作,如Microsoft ACS [8]/SONiC [33]基于类似的动机。然而,基于通俗的推理有一点需要注意的是服务[17]。
我们的设计原则是和我们Facebook的基础设施相关。 Facebook的数据中心网络有多个内部组件,如Robotron [48],FbNet [46],Scuba [15]和Gorilla [42],这些组件经过精心打造,可以相互协作,而且FBOSS也不例外。因此,我们的设计的特定目标是简化FBOSS与现有基础架构的集成,这最终意味着它可能不会适合其它数据中心。鉴于此,我们特别关注这些设计原则在软件架构、部署、监控和管理方面的影响。
2.1交换机即服务器(Switch-as-a-Server)
这一原则背后的动机源于我们构建大规模软件服务的经验。尽管许多相同的技术和扩展挑战同样适用于交换机软件和普通分布式软件系统,但从历史上看,它们的处理方式却截然不同。对我们而言,通用软件模型在可靠性、灵活性和操作简单性方面更为成功。我们部署了数千种并非完美的软件服务。但是,我们会仔细监控我们的服务,一旦发现任何异常,我们会快速修复bug并部署补丁。我们发现这种做法在构建和扩展我们的服务方面非常成功。
例如,数据库软件是我们业务的重要组成部分。我们启动了一个开源的分布式数据库项目,并对其进行了大量修改以供公司内部使用,而不是使用包含不必要功能的封闭式专有解决方案。鉴于我们可以完全访问代码,我们可以针对所需的功能集精确定制软件,从而降低复杂性。此外,我们每天对代码进行修改,并使用持续集成和分阶段部署的行业惯例,能够快速测试和评估生产环境中的变化。此外,我们在商用服务器上运行数据库,而不是在自定义硬件上运行它们,因此可以轻松地控制和调试软件和硬件。最后,由于代码是开源的,我们将更改提供给全世界,并从外部贡献者生成的讨论和错误修复中获益。
我们在通用软件服务方面的经验表明,这一原则在可扩展性,代码重用和部署方面取得了巨大成功。因此,我们基于相同的原理设计了FBOSS。但是,由于数据中心网络与通用软件服务存在不同的操作要求,因此只有一部分注意事项可以直接采用第8节中提到的这一原则。
2.2 早期部署-和迭代
我们最初在生产环境的部署是故意缺少很多功能的。摒弃传统的网络工程智慧,没有实现一长串“必须拥有”的功能,如控制平面策略、ARP/NDP过期、IP分片/重组、生成树协议(STP)等,我们就将其部署到生产环境。我们没有先实现这些功能,而是优先构建基础架构和工具,以便高效且频繁地更新交换机软件,例如热启动功能(第7.1节)。
为了快速演进网络和降低复杂性,我们设想可以通过将交换机软件迭代地部署到生产环境中来动态地推导出实际的最小网络需求,观察什么中断了,并快速推出修复程序。通过从小规模开始并依赖于应用程序级别的容错机制,开发人员团队能够从一无所有到生产环境中上线代码,需要的人/年数量比典型的交换机软件开发要少一个数量级。
也许更重要的是,利用这一原则,我们能够为我们的环境推导出最简单的网络,并尽快对生产网络产生积极影响。例如,当我们发现缺少控制平面策略导致BGP会话超时时,我们快速开发出补丁并部署来解决问题。通过尽早对生产网络产生积极影响,我们能够为其他工程师提供更有说服力的案例,并提供更多帮助。到目前为止,我们仍然没有实现IP分片/重组、STP等一长串曾被广泛认为“必须拥有”的功能。
3 硬件平台
为了提供FBOSS的设计背景,我们首先回顾一下典型的交换机硬件包含的内容,比如交换机专用集成电路(ASIC)、端口子系统、物理层子系统(PHY)、CPU、复杂可编程逻辑设备(CPLD)和事件处理器。典型数据中心交换机的内部结构如图2所示[24]。

3.1组件
交换机ASIC。交换机ASIC是交换机上重要的硬件组件。它是一种快速处理数据包的专用集成电路芯片,能够以每秒最高达12.8Tbps的速率交换数据包[49]。交换机可以通过其他处理单元(例如FPGA [53]或x86 CPU)来增强交换机ASIC,但性能只会增加一点点[52]。交换机ASIC内部有多个组件:存储器,通常是CAM、TCAM或SRAM [19] ,用于存储需要由ASIC快速访问的信息 ; 一个解析流水线,由一个解析器和一个deparser组成,它从数据包中定位、提取、保存感兴趣的数据,并在数据包发送出去之前重建数据包[19] ; 匹配-动作(Match-Action )单元,它们指定ASIC应如何根据数据包内的数据、配置的数据包处理逻辑和ASIC存储器内的数据来处理数据包。
PHY。PHY(物理层子系统)负责将链路层设备(例如ASIC)连接到物理介质(例如光纤),并将链路上的模拟信号转换为数字化的以太网帧。在某些交换机设计中,PHY可以在ASIC内构建。在高速传输数据时,电信号干扰非常严重,会导致交换机内部数据包损坏。因此,需要复杂的降噪技术,如PHY tuning [43]。 PHY tuning控制各种参数,例如预加重(pre-emphasis)、可变功率设置或用到的前向纠错算法(FEC)的类型。
端口子系统。端口子系统负责读取端口配置,检测已安装端口的类型,初始化端口以及为端口提供与PHY交互的接口。数据中心交换机包含多个Quad Small Form-Factor Pluggable(QSFP)端口。 QSFP端口是一种紧凑的热插拔收发器,用于将交换机硬件与线缆连接,数据速率最高可达100Gb/s。 QSFP端口的类型和数量由交换机规范和ASIC决定。
FBOSS通过分配动态通道映射和适应端口更改事件来与端口子系统交互。动态通道映射是指将每个QSFP中的多个通道映射到适当的端口虚拟ID。这允许更改端口配置,而无需重新启动交换机。FBOSS监视端口的健康状况,一旦检测到任何异常,FBOSS就会执行修复步骤,例如恢复端口或将流量重新路由到活动端口。
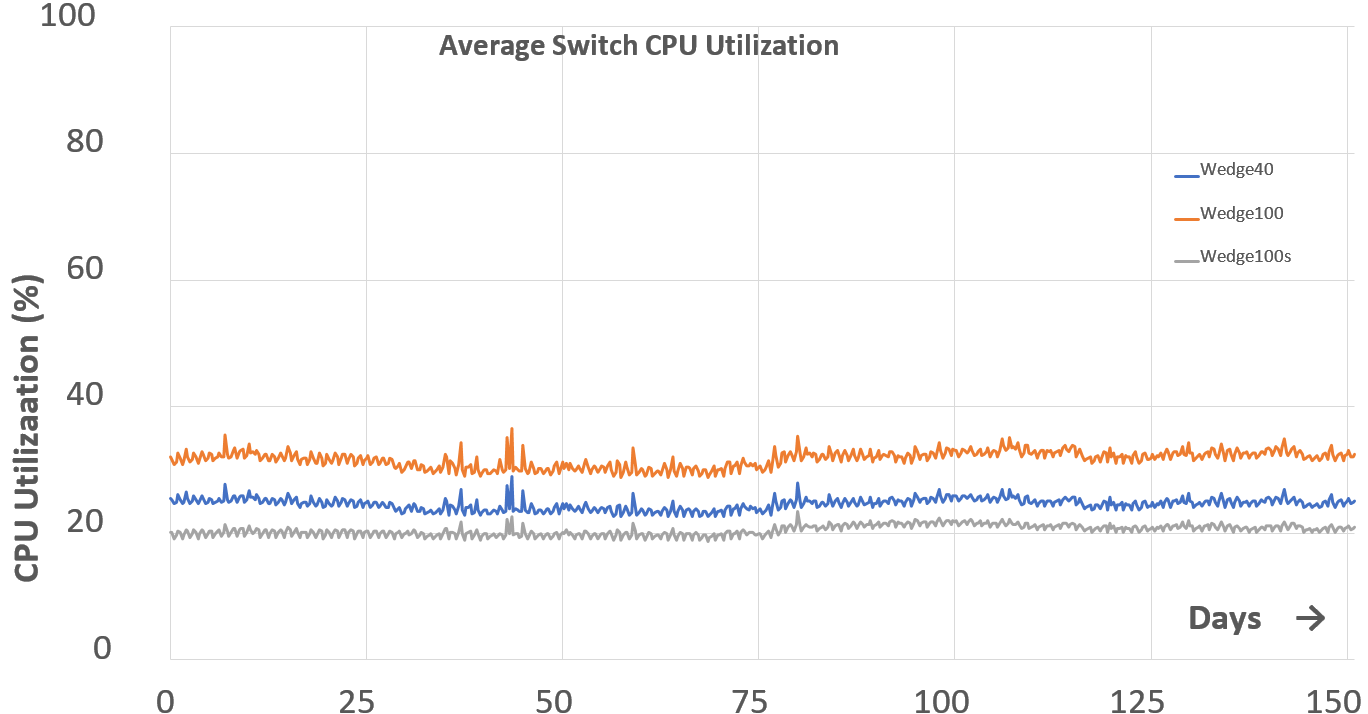
CPU板。在交换机中存在一个运行微服务器的CPU板[39]。 CPU板非常类似于商业服务器,包含商业x86 CPU、RAM和存储介质。除了这些标准部件外,CPU板还通过专门的PCI-E总线与交换机ASIC互连,可实现对ASIC的快速调用。X86 CPU的存在使得能够为交换机安装商用Linux进而提供常见的操作系统功能。与服务器级CPU相比,交换机内的CPU通常性能要低一些。但是,FBOSS设计之初就假设交换机中的CPU与服务器级CPU一样强大,因此交换机可以运行尽可能多的所需服务。幸运的是,我们在公司内部设计和构建数据中心交换机,使我们能够灵活地选择符合设计要求的CPU。例如,Facebook的Wedge 100交换机配备一颗四核Intel Atom E3800 CPU。我们超配CPU,以便交换机CPU在40%的利用率下运行,处理关闭交换机时发生的一切突发事件。这种设计选择可以在我们部署的各种类型的交换机中看到,如图3所示。 此外,分配给CPU板的大小限制了我们选择一个功能更加强大的CPU [24]。
其它板管理器。交换机将各种繁杂功能从CPU和ASIC卸载到其它各种组件,以提高整体系统性能。这些组件中的两个例子是复杂可编程逻辑器件(CPLD)和基板管理控制器(BMC)。CPLD负责状态监控、LED控制、风扇控制和前面板端口管理。BMC是一种专用的片上系统,具有自己的CPU、存储器、存储器和连接传感器/CPLD的接口。 BMC管理着电源和风扇。它还提供系统管理功能,例如远程电源控制、LAN上串口、带外监控和错误日志,以及用户将操作系统安装到设备之前的一个迷你操作系统环境。 BMC由OpenBMC等定制软件控制[25]。
其它板管理器为FBOSS带来了额外的复杂性。例如,FBOSS从CPLD检索QSFP控制信号,这一过程需要与CPLD驱动程序进行复杂的交互。
3.2事件处理程序
事件处理程序使交换机能够将内部状态更改通知到任何外部实体。交换机事件处理程序的机制与任何其他基于硬件的事件处理程序非常相似,因此处理程序可以同步或异步方式处理。我们讨论两个特定于交换机的事件处理程序:链路事件处理程序和慢速路径数据包处理程序。
链路事件处理程序(Link Event Handler)。链路事件处理程序通知ASIC和FBOSS发生在QSFP端口或端口子系统中的任何事件。此类事件包括链路开启和关闭事件以及链路配置的更改。链路状态处理程序通常使用繁忙轮询方法实现,其中交换机软件具有活动线程,该线程持续监视PHY以获取链路状态,然后在检测到更改时调用用户提供的回调。FBOSS提供对链路事件处理程序的回调,并在激活回调时同步其链路状态的本地视图。
慢路径数据包处理程序(Slow Path Packet Handler)。大多数交换机允许数据包从指定的CPU端口发出去,即慢速路径。与链路状态处理程序类似,慢速数据包处理程序不断轮询CPU端口。一旦在CPU端口接收到数据包,慢速路径数据包处理程序就会通知交换机软件捕获的数据包并激活提供的回调。回调提供有各种信息,其中可能包括捕获的实际数据包。这允许慢速路径数据包处理程序极大地扩展交换机的功能集,因为它可以实现自定义数据包处理,而无需更改数据平面的功能。例如,可以对分组的子集进行采样以进行带内监视,或者修改分组以包括自定义信息。但是,如其名称所示,慢速路径数据包处理程序太慢,无法以线速执行自定义数据包处理。因此,它仅适用于涉及使用交换机接收的少量数据包的场景。
4 FBOSS
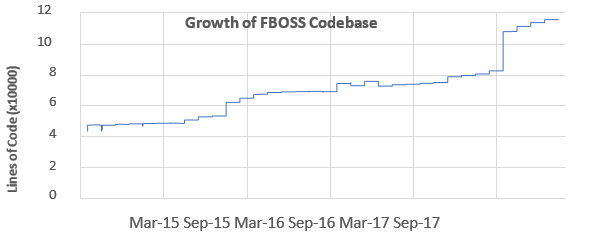
为了管理第3节中描述的交换机,我们开发了可以在标准Linux发行版上运行的与设备商无关的交换机软件FBOSS。 FBOSS目前已部署到我们的生产数据中心的ToR和汇聚交换机。 FBOSS的代码库作为开源项目公开发布,并得到了不断发展的社区的支持。截至2018年1月,共有91位开发者参与了该项目,现在代码库涵盖了609个文件和115,898行代码。下面给一个功能用了多少代码行举个例子,在FBOSS中实现链路聚合需要5,932行新添加的代码。图4显示项目自成立以来的开源代码的增长情况。2017年9月发生的代码库大幅增加是为FBOSS添加大量硬编码参数以支持特定供应商NIC的结果。
FBOSS负责管理交换机ASIC并提供更高级别的远程API,转换为特定的ASIC SDK方法。外部处理的包括管理、控制,路由、配置和监控流程。图5说明了交换机中的FBOSS、其他软件进程和硬件组件。请注意,在我们的生产环境部署中,FBOSS与我们的服务器共享相同的Linux环境(例如,操作系统版本、打包系统),因此我们可以在服务器和交换机上使用相同的系统工具和库。
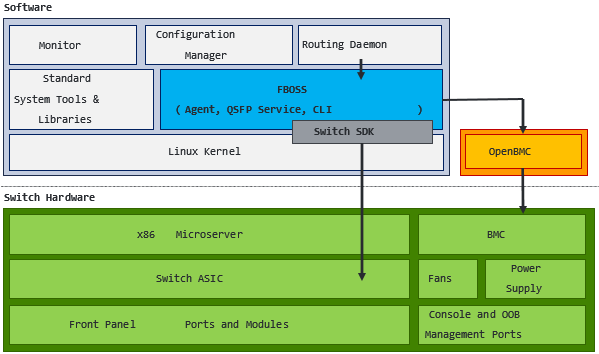
4.1架构
FBOSS由多个互连组件组成,有这几大类:交换机软件开发工具包(SDK),HwSwitch,硬件抽象层,SwSwitch,状态观察器,本地配置生成器,Thrift [2]管理接口和QSFP服务。 FBOSS代理是主进程,运行着FBOSS大部分功能 。交换机SDK与FBOSS代理打包在一起并进行编译。SDK由外部的交换机ASIC供应商提供。除QSFP服务之外的所有其他组件(作为其独立进程运行)驻留在FBOSS代理内。我们将详细讨论除了本地配置生成器之外的每个组件。本地配置生成器将在第6节进行中讨论。
交换机SDK。交换机SDK是ASIC供应商提供的软件,它暴露出用于与底层ASIC功能交互的API。这些API包括ASIC初始化、安装转发表规则和监听事件处理程序。
HwSwitch。 HwSwitch代表交换机硬件的抽象。 HwSwitch的接口提供了用于配置交换机端口、向这些端口发送和接收数据包、以及为端口上的状态更改和这些端口上发生的数据包输入/输出事件注册回调的通用抽象。除了通用抽象之外,ASIC特定实现也被推送到硬件抽象层,允许与交换机硬件进行交换机无关的交互。虽然不是一个完美的抽象,但FBOSS已被移植到两个ASIC系列,并且正在进行更多移植。可以在此处找到HwSwitch实现的示例[14]。
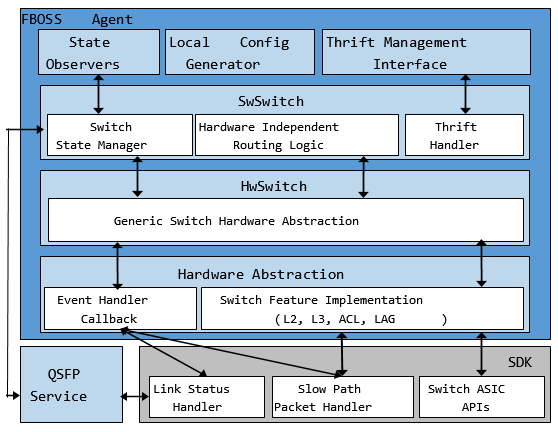
硬件抽象层。 FBOSS允许用户通过扩展HwSwitch接口轻松添加支持特定ASIC的实现。这也使得轻松支持多个ASIC而无需更改FBOSS主代码库。自定义实现必须支持HwSwitch接口中指定的最小功能集。但是,鉴于HwSwitch仅指定少量功能,FBOSS允许自定义实现包含其他功能。例如,FBOSS的开源版本实现了自定义功能,例如指定链路聚合、添加ASIC状态监视器和配置ECMP。
SwSwitch。 SwSwitch为数据包的交换和路由提供硬件无关的逻辑,并与HwSwitch交互来将命令传输到交换机ASIC。 SwSwitch提供的一些功能包括:L2和L3表的接口、ACL条目、状态管理。
状态观察器(State Observers)。通过保持协议状态变化,SwSwitch可以实现ARP,NDP,LACP和LLDP等底层控制协议。通过称为状态观察(State Observation)的机制向协议通知状态变化。具体而言,任何对象在初始化时都可以将自身注册为状态观察者。通过这样做,每个未来的状态更改都会调用对象提供的回调。回调提供了对有问题的状态更改、允许对象做出相应的反应。例如,NDP将自身注册为状态观察器,以便它可以对端口更改事件做出反应。通过这种方式,状态观察机制允许协议实现与关于状态管理的问题分离。
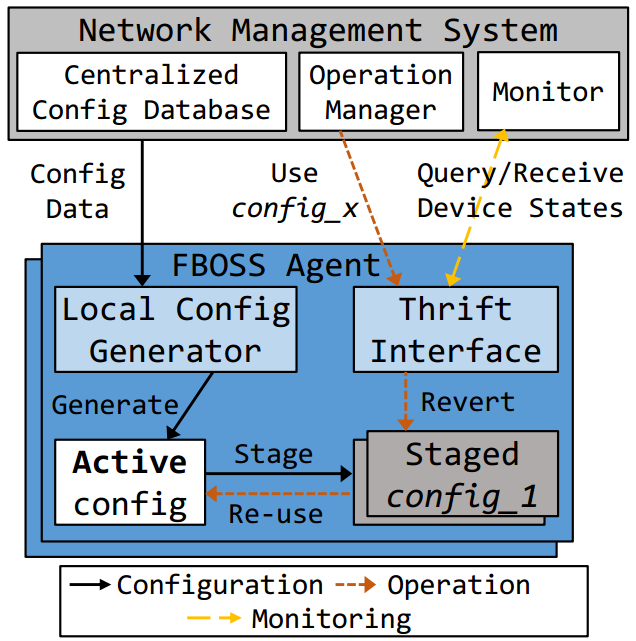
Thrift管理接口。网络的配置管理平面是与网络分离的。每个FBOSS实例都包含一个本地控制平面,运行如BGP或OpenR [13]等协议,在微服务器上通过Thrift管理接口与集中式网络管理系统进行通信。它们之间发送的消息类型如图7所示. FBOSS Thrift接口的完整开源规范可以可公开获取的[5]。鉴于可以修改接口以满足我们的需求,Thrift为我们提供了一种简单而灵活的方式来管理和操作网络,从而提高稳定性和高可用性。我们将在第6节讨论Thrift管理接口和集中式网络管理系统之间的交互细节。

QSFP服务。 QSFP服务管理一组QSFP端口。 该服务检测QSFP模块的插入或移除、读取QSFP产品信息(例如制造商)、控制QSFP硬件功能(即改变功率配置)、监视QSFP模块。FBOSS最初在FBOSS代理内部拥有QSFP服务。 但是随着该服务的不断发展,我们必须重新启动FBOSS代理和交换机来应用更改。 因此,我们将QSFP服务分离为一个单独的流程,以提高FBOSS的模块性和可靠性。因此,FBOSS代理更可靠,因为QSFP服务中的任何重新启动或错误都不会直接影响代理。但是由于QSFP服务是一个单独的进程,因此需要单独的工具进行打包、部署和监控。 此外,现在需要在QSFP服务和FBOSS代理之间进行精细的进程同步。
4.2 状态管理
FBOSS的软件状态管理机制专为高并发、快速读取和简单安全的更新而设计。状态被建模为版本化的copy-on-write (写时复制)树[37]。树的根是主交换机状态类,根的每个子节点代表交换机状态的不同类别,例如端口或VLAN条目。当树的一个分支发生更新时,如果有必要,将会复制并更新分支中一直到根的每个节点。图8说明了由VLAN ARP表条目更新调用的交换机状态更新过程。我们可以看到只重建了从修改后的ARP表到根目录的节点和链接。在创建新树时,FBOSS代理仍然与先前的状态交互,而不需要捕获任何状态上的锁。一旦完成整个树的copy-on-write过程,FBOSS将从新的交换机状态进行读取。
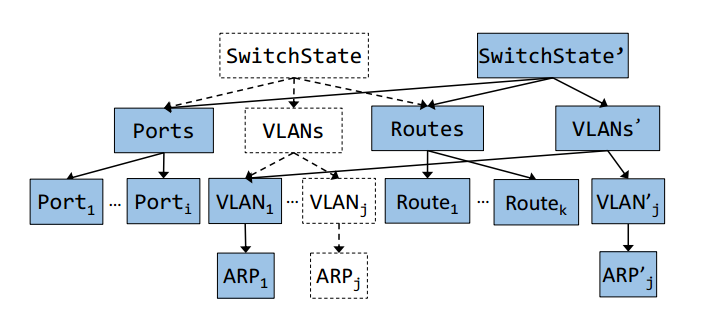
这个模型有很多好处。首先,它允许简单的并发,因为没有读锁。在创建新状态时,读取仍然可以继续进行,并且状态只会被创建或销毁并且从不修改状态。其次,版本化状态要简单得多。这样可以更轻松地调试、记录日志和验证每个状态及其转换。最后,由于我们记录了所有状态转换日志,因此可以执行重新启动,然后将状态恢复到其重新启动前的形式。这个模型也有一些缺点。由于每个状态更改都会产生新的交换机状态对象,因此更新过程需要更多的处理。其次,切换状态的实现比简单地获取锁和更新单个对象更复杂。
硬件特定状态。硬件状态是保留在ASIC内部的状态。每当需要在软件中更新硬件状态时,软件必须调用交换机SDK以检索新状态。 FBOSS HwSwitch在硬件状态的相应部分上获得读锁和写锁,直到更新完成。基于锁定的状态更新的选择可能因SDK实现而异。
5 测试和部署
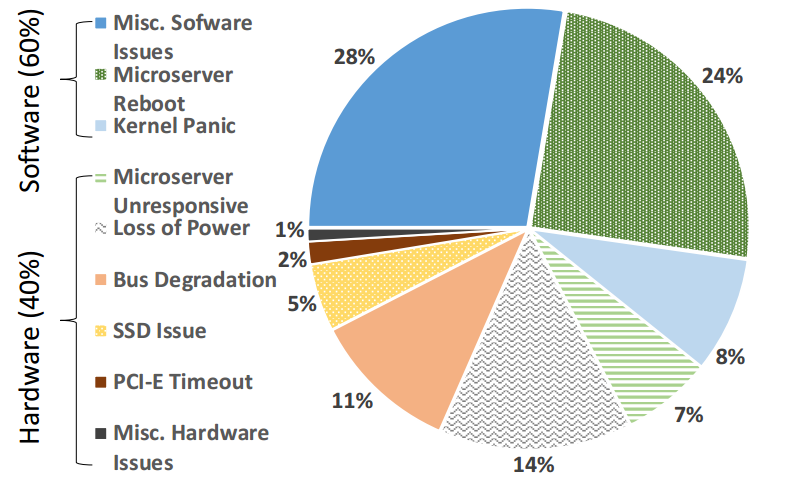
交换机软件通常由交换机供应商开发和发布,并且是封闭的和专有的。因此,在冗长的开发和手动QA测试周期中,发布一个交换机软件的新版本可能需要数月时间。此外,鉴于软件更新周期很长,更新通常包含大量更改,这些更改可能会引入先前不存在的新错误。相比之下,典型的大规模软件部署过程是自动化的、快速的,并且每次更新包含一组较小的更改。此外,功能部署还配有自动和增量测试机制,可快速检查和修复错误。我们的中断记录(图9)显示,大约60%的交换机中断是由软件故障引起的。这接近业界数据中心设备中已知的软件故障率——约为51%[27]。为了最大限度地减少这些中断的发生和影响,FBOSS采用灵活、可靠和可扩展的大规模软件开发和测试方案。
FBOSS不使用像Chef [3]或Jenkins [6]这样的现有自动化软件部署框架,而是使用自研的名为fbossdeploy的部署软件。开发我们自己的部署软件的主要原因之一是允许与现有外部监视器进行更紧密的反馈循环。我们有几个现有的外部监视器,可以持续检查网络的健康状况。这些监视器检查链路故障、BGP收敛时间、网络可达性等属性。虽然为部署通用软件而构建的现有部署框架可以很好地防止软件相关错误的传播,例如死锁或内存泄漏,但它们不是为了检测和防止整个网络范围的故障而构建的,因为这些故障可能很难从单个节点检测出来。因此,构建fbossdeploy可以快速响应部署期间可能发生的整个网络范围的故障,例如可达性故障。
FBOSS部署过程与其他持续部署过程非常相似[22],并分为三个不同的部分:连续金丝雀(Continuous canary),每日金丝雀(Daily canary)和分阶段部署。这三个部分中的每一个都是为了可靠部署这个目的。我们目前是大体按月的部署周期,按月的部署周期包含金丝雀和分阶段部署,以确保高度的运营稳定性。
连续金丝雀。连续金丝雀是它自动将FBOSS存储库中所有新提交的代码部署到生产中运行的少量交换机的过程,每种类型的交换机大约1-2个交换机,并监控交换机和相邻交换机的运行状况和故障。一旦检测到故障,连续金丝雀将立即撤销最近一次部署并恢复至最后一个稳定版本的代码。连续金丝雀能够快速捕获与交换机初始化相关的错误,例如热启动、配置错误和不可预测的竞争条件等问题。
每日金丝雀。每日金丝雀是一个连续金丝雀之后的过程,用更多的交换机在更长的时间尺度上测试新的提交。每日金丝雀每天运行一次,并部署连续金丝雀验证过的最新提交。每日金丝雀部署为每种类型的交换机选择大约10到20个交换机。每日金丝雀全天运行以捕获随时间慢慢出现的错误,例如关键线程中的内存泄漏或性能回归。这是整个网络范围部署之前的最后阶段。
分阶段部署。每日金丝雀完成后,人工操作员进行干预,将最新代码推送到生产环境中的所有交换机。这是整个部署过程中唯一涉及操作人员的步骤,大约需要一天才能完全完成。操作员使用适当的参数运行部署脚本,以便一次将最新代码慢慢地推送到交换机的子集中。一旦故障交换机的数量超过预设阈值(通常约为整个交换机总数的0.5%),部署脚本将停止并要求操作员调查问题并采取适当的措施。最终步骤仍用手工执行的原因如下:首先,单台服务器足够快,可以将代码部署到数据中心的所有交换机,这意味着部署过程部署代码的这一台机器不会有性能瓶颈。其次,它对现有监视器可能无法捕获的不可预测的错误进行了细粒度的监视。例如,我们修复了不可预测和持续的可达性丢包,如无意中更改了接口IP或端口速度配置以及我们在分阶段部署期间发现的瞬时中断(如端口flap)。最后,我们仍在改进我们的测试、监控和部署系统。因此,一旦测试覆盖率和自动修复在一个可接受的范围内,我们也计划把这最后一步也实现自动化。
6 管理
在本节中,我们将介绍FBOSS如何与管理系统交互,并从网络管理的角度讨论FBOSS设计的优势。图10显示了交互的架构图。
6.1配置
FBOSS旨在用于具有中央网络管理器的高度受控的数据中心网络。这极大地简化了跨大量交换机生成和部署网络配置的过程。
配置设计。网络设备的配置在数据中心环境中高度标准化。给定一个特定拓扑,每个设备都使用模板和自动生成的配置数据进行自动配置。例如,交换机的IP地址配置由交换机的类型(例如,ToR或aggregation),还有集群中的交换机上游/下游邻居确定。
配置生成和部署。配置数据由我们的网络管理系统Robotron [48]生成,并分发给每个交换机。然后,FBOSS代理中的本地配置生成器使用配置数据并创建活动配置文件。如果对数据文件进行了任何修改,则会生成新的活动配置文件,并将旧配置存储为分阶段配置文件。这种配置过程有许多优点。首先,它不允许多个实体并发修改配置,这避免了配置出现不一致。其次,它使配置可重现且确定,因为配置是版本化的,并且FBOSS代理总是在重新启动时读取最新配置。最后,它避免了人为配置错误。另一方面,我们的全自动配置系统也存在缺点 - 它缺乏功能强大的人机交互式CLI,使得手动调试错误变得困难;此外,不支持增量配置更改,这又使得每次配置更改都需要重新启动FBOSS代理。
6.2 Draining(下线交换机)
Draining是指安全地从其服务中下线aggregation 交换机的过程。除非ToR交换机下的所有服务都移除了,否则ToR交换机通常不会全部被移除。同样,Undraining是恢复交换机先前配置并使其重新投入使用的过程。由于在交换机上频繁执行功能更新和部署,因此Draining和Undraining交换机是经常执行的主要操作任务之一。然而,由于严格的时序要求以及交换机上多个软件组件的同时配置变化,下线交换机通常是一项困难的操作任务[47]。相比之下,由于配置管理设计中的自动化和版本控制机制,FBOSS的上线/下线操作变得更加简单。我们下线交换机的方法如下:
(1)FBOSS代理从中央配置数据库中检索下线的BGP配置数据。
(2)中央管理系统通过Thrift管理界面触发下线过程。
(3)FBOSS代理激活下线完成的配置,并使用下线完成的配置重新启动BGP守护程序。至于上线的过程,我们采用上线交换机的配置重复上述步骤。
(4)作为最后添加的步骤,管理系统ping FBOSS代理并查询交换机统计信息以确保上线过程成功。
下线交换机是一个例子,很好地展示了FBOSS的Thrift管理界面 和集中管理的配置快照显著简化了操作任务的优点。
6.3 监控和故障处理
传统上,数据中心运营商使用标准化的网络管理协议(如SNMP [21])从供应商网络设备收集交换机统计信息,例如CPU/内存利用率、链路负载、数据包丢包情况和其他系统运行健康状态。相比之下,FBOSS允许外部系统通过两种不同的接口收集交换机统计信息:Thrift管理接口和Linux系统日志。 Thrift管理接口以Thrift模型中指定的形式提供查询。该接口主要用于监控交换机上层的使用情况和链路统计信息。鉴于FBOSS作为Linux进程运行,我们也可以直接访问交换机微服务器的系统日志。这些日志专门用于记录事件类别和失败事件。这允许管理系统监视底层系统运行状况和硬件故障。对于收集的统计数据,我们的监控系统FbFlow [46]根据数据类型将数据存储到Scuba [15]或Gorilla [42]数据库中。存储数据后,我们的工程师可以在很长一段时间内在高层次查询和分析数据。监控系统可以轻松获得监控数据如图3等图表。
为了配合监控系统,我们还实施了自动故障修复系统。修复系统的主要目的是自动检测软件或硬件故障并从中恢复。它还为操作人员提供了更深入的视角以简化调试过程。修复的过程如下:检测到故障后,修复系统会自动将每个故障归类为一组已知的根本原因,并在需要时应用修复,并将中断的详细信息记录到数据存储中。故障的自动分类和修复使我们能够将调试工作集中在未确诊的错误上,而不是反复调试相同的已知问题。此外,大规模的日志可以帮助我们提供诸如将罕见故障确定到特定硬件版本或内核版本之类的洞察力。
总之,我们Facebook的监控和故障处理方法具有以下优点:
- 灵活的数据模型。传统上,为了支持新类型的数据来收集或修改现有数据模型需要对网络管理协议进行修改和标准化,然后设备商实施标准还需要很长时间。相反,由于我们通过管理系统控制设备,通过FBOSS监控数据传播和数据收集机制,我们可以轻松定义和修改收集规范。我们明确定义了我们需要的细粒度计数器,并在设备上报这些计数器。
- 提高性能。与传统的监控方法相比,FBOSS具有更好的性能,因为可以定制数据传输协议以减少收集时间和网络负载。
- 具有详细错误日志的修复。我们的系统允许工程师专注于为看不见的错误构建补救机制,从而提高网络稳定性和调试效率。
7 经验
虽然使用自定义交换机软件和硬件运营数据中心网络的经验大多令人满意,但我们遇到了以前没遇到过的中断故障,这些中断对我们的开发和部署模型来说是独一无二的。
7.1基础设施复用(Reuse)的副作用
为了提高效率,我们的数据中心一个服务器接入机柜使用单个ToR交换机部署网络拓扑,这意味着ToR交换机是机柜中服务器的单点故障之处。因此,在ToR交换机上发出的频繁FBOSS版本必定不能产生网络中断,以确保在这些主机上运行的服务的可用性。为此,我们使用称为“热启动(warm boot)”的ASIC功能。热启动允许FBOSS重新启动而不会影响ASIC内的转发表,从而有效地让数据平面在重新启动控制平面的同时继续转发流量。尽管此功能非常具有吸引力,并且允许我们实现所需的版本发布速度,但它也极大地使FBOSS、路由守护进程、交换机SDK和ASIC之间的状态管理复杂化。因此,我们分享了一个热启动和我们的代码重用实践导致重大断网的案例。
尽管我们对新代码部署进行了一系列测试和监控过程,但是不可避免地会将漏洞泄漏到数据中心范围的部署中。最困难的错误类型是罕见的不一致性的错误。例如,我们的BGP守护程序具有正常重启功能,可防止热启动在FBOSS重启或故障导致BGP会话被拆除时影响邻居设备[38]。在声明BGP会话中断之前,正常重启具有超时时间,这能有效地对热启动操作花费的总时间施加时间限制。在我们的一个部署中,我们发现Kerberos [7]库(FBOSS和许多其他软件服务用于保护服务器之间的通信)导致数据中心中的一小部分交换机中断。我们意识到中断的原因是库通常需要很长时间才能加入FBOSS代理线程。由于其他软件服务的时间和可用性限制比FBOSS的热启动要求更宽松,因此现有的监视器未构建检测到这种罕见的性能回归。
心得:简单地复用为广泛使用的代码、库或为通用软件服务进行优化的基础设施可能无法有效地用在交换机软件中。
7.2 快速部署的副作用
在我们早期的FBOSS部署后的前面几个月,我们偶尔会遇到多个交换机的未知级联中断。中断会从某个设备开始,并扩散到附近的设备,导致群集内的数据包丢包非常多。有时网络会自行恢复,有时则不然。我们意识到如果部署出错会更容易发生中断,但是它们很难调试,因为我们已经同时部署了许多新的更改。这就是我们早期的FBOSS部署。
我们最终注意到丢包通常限于16个设备的倍数。这指向我们数据中心中叫作备份组的配置。在部署FBOSS之前,我们数据中心内最常见的故障类型是单个链路故障导致流量黑洞[36]。为了处理这种故障,如果到目的地的最佳直连路由变得不可用,则指定ToR交换机的组(在图11的左侧示意图)以提供备用路由。备份路由是预先计算和静态配置的,以便更快地进行故障转移。
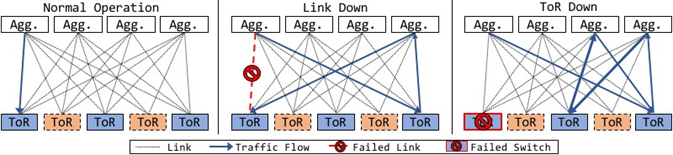
我们遇到的中断是,ToR故障导致备份ToR和汇聚交换机之间的数据包像乒乓球那样来回发送,错误地认为备份路由可用。这导致备份路由条目出现环路。图11的右侧部分说明了路径环路是如何的出现的。该环路最终导致所有备份交换机出现巨大的CPU峰值。 CPU峰值的主要原因是FBOSS没有正确地从转发表中删除失败的路由条目,并且还为所有来回ping 255次的数据包生成了TTL超期的ICMP数据包。鉴于我们之前没有遇到过这种行为,我们没有为控制平面开发将所有TTL为0的数据包发送给FBOSS代理的策略。FBOSS代理能处理这些数据包的速率远远低于我们接收帧的速率,因此我们会越来越落后并超出BGP keep-alive时长阈值并撤回网络收敛所需的消息。最终BGP对等体会到期,但由于我们已经处于环路状态,它往往使事情变得更糟,导致该问题无限期持续下去。最终,我们添加了一些控制平面补丁,从此,即使多个ToR故障,网络也能保持稳定。
心得:适用于传统网络的功能可能不适用于部署FBOSS的网络。这是快速部署的副作用,交换机中断比传统网络更频繁。因此,必须小心采用即使是在传统网络中稳定的功能。
7.3 解决互操作性问题
虽然我们开发和部署了自研的交换机,但由于种种原因,我们仍然需要交换机和FBOSS与不同类型的网络设备进行交互。我们分享FBOSS设计中能够快速解决互操作性问题的经验。
在FBOSS和特定供应商设备之间配置链路聚合时,我们发现在供应商设备上翻动(flap)逻辑聚合接口可能会禁用该接口上的所有IP操作。粗略检查发现,虽然设备期望对聚合接口的地址进行重复地址检测(DAD)[50],但它意外地检测到相应子网中的重复地址 。该行为被隔离到LACP和DAD探测器之间的竞争条件,其中硬件支持链路聚合的构件可能导致DAD的Neighbor Solicitation数据包被环回到供应商交换机。根据DAD规范,供应商设备已将环回的Neighbor Solicitation数据包解释为另一个参与用于相同的地址DAD的节点,DAD规范强制要求交换机在DAD已经触发DAD的接口上禁用IP地址相关操作。我们还发现,将同一供应商设备与不同供应商的交换机互连会出现相同的症状。
接口的翻动是我们的网络操作人员在日常网络维护期间执行的步骤。为了确保仍然可以以无中断的方式执行维护,我们修改了FBOSS代理以避免上述情况。相比之下,为了回应我们向设备厂商报告此错误,即该设备商的交换机应当表现出与我们自研交换机相同的行为,该设备商建议其他供应商对DAD进行扩展。通过完全控制我们的交换机软件,能够快速提供我们网络所需的内容。
心得:互操作性问题在具有各种网络设备的网络中很常见。 FBOSS允许我们直接快速诊断和修复问题,而不是等待设备商更新或采用半生不熟的解决方案。
8 讨论
现有交换机编程标准。随着时间的推移,交换机上开放软件的各个方面,已经提出了许多软件标准。在学术方面,针对开放交换机的各个方面有几十年种,包括主动网络[35]、FORCES [32]、PCE [26]和OpenFlow [40]。在工业界方面,新兴厂商试图用更加开放策略与现有企业竞争(例如,JunOS的SDK,Arista的SDK),并且传统大厂也推出自己的开放网络方案(例如,I2RS,思科的OnePK)作为回应。在学术和工业界方面,还有许多控制平面和管理平面协议,类似地试图使交换机软件可编程性/可配置性更好。这些尝试中的每一个都有自己的一组权衡和支持硬件的子集。因此,有人可能会争辩说,这些标准的某些综合体可能是“一个完美的API”,它为我们提供了我们想要的功能。那么,为什么我们不仅仅使用或改进这些现有标准之一呢?
问题是这些现有的标准都是“自上而下”的:它们都是在现有供应商软件之上的附加软件/协议,而不是完全取代它。这意味着如果我们想要改变底层的非开放软件,我们仍然会受到我们的供应商愿意支持的时间和时间表的限制。通过“自下而上”控制整个软件堆栈,我们可以控制交换机上所有可能的状态和代码,并且可以按我们自己的时间表随时公开我们想要的任何API。更重要的是,我们可以尝试使用我们公开的API,并随着时间的推移逐步发展以满足我们的特定需求,从而使我们能够快速满足我们的生产需求。
FBOSS作为更大交换机的构件模块(Building Block )。虽然最初是为ToR开发的单ASIC交换机,但我们已经将FBOSS作为构建模块,以运行更大的多ASIC框式交换机。我们设计并部署了自研的框式交换机,带有可移动线卡,支持128x100Gbps链路,具有完全的二分连接。该交换机内部由8个线卡组成,每个线卡都有自己的CPU和ASIC,以逻辑CLOS拓扑连接到四个Fabric卡,Fabric卡也有自己的CPU和ASIC。
我们在十二个(八个线卡加四个fabric卡)CPU中运行一个FBOSS实例,在交换机内部让它们成为BGP对等体,从逻辑上创建一个运行数据中心aggregation 层的大容量交换机。虽然看起来是一种新的硬件设计,但我们交换机的数据平面遵循传统的供应商来源的机箱架构。主要区别在于我们不会部署额外的服务器来充当Supervisor卡,而是利用我们更强大的数据中心自动化工具和监控系统。虽然这种设计不能和传统供应商交换机提供的相同的单一逻辑交换机抽象,但它使我们能拥有更大的交换机形式,而无需更改软件体系结构。
隐式和循环依赖。我们在尝试像服务器一样运行交换机时发现的一个微妙但重要的问题,即网络中隐藏的隐式循环依赖关系。具体来说,我们所有服务器集群都运行一组标准的二进制文件和库,用于日志记录、监控等。通过这种设计,我们希望在交换机上运行这些现有软件。不幸的是,在某些情况下为服务器构建的软件隐式地依赖于网络,当FBOSS代码依赖于它们时,我们创建了一个循环依赖,阻止了我们的网络初始化。更糟糕的是,这些情况只会在其他错误情况下出现(例如,当守护程序崩溃时)并且很难调试。在一个特定情况下,我们最初使用与服务器上其他软件服务相同的任务调度和监控软件将FBOSS部署到交换机上,但我们发现该软件在运行之前需要访问生产网络。因此,我们不得不将代码与其分离,并编写一个自定义任务调度软件来专门管理FBOSS部署。虽然这是一个更容易调试的案例,但随着每个软件包的发展和独立维护,一直存在着善意的威胁,但以服务器为重点的开发人员在网络上添加了微妙的隐式依赖。我们目前的解决方案是继续加强我们的测试和部署程序。
9 未来的工作
分区FBOSS代理。 FBOSS代理目前是由多个功能组成的一个二进制文件。与QSFP服务的分离以提高交换机可靠性类似,我们计划进一步将FBOSS代理分区为独立运行的较小二进制文件。例如,如果状态观察器(State Observers)作为与FBOSS代理进行通信的外部进程存在,那么任何使状态观察器超载的事件都不会使FBOSS代理失效。
新颖的实验。我们对FBOSS的主要目标之一是允许更多更快的实验。我们目前正在尝试自定义路由协议、更强的慢速路径隔离(例如,处理错误实验)、微突发检测、宏观流量监控、低级硬件统计数据的大数据分析以推断故障检测等众多其他设计元素。通过使FBOSS开源并使我们的研究更加公开,我们希望借助工具和思考帮助研究人员直接实现关于生产环境就绪软件和硬件的新颖研究思路。
可编程ASIC支持。 FBOSS旨在同时轻松支持多种类型的ASIC。事实上,FBOSS成功地迭代了不同版本的ASIC,这些ASIC没有任何大的设计变化。最近随着可编程ASIC的出现,我们认为FBOSS支持可编程ASIC [19]以及编程这些ASIC的语言(例如P4 [18])将是有意义的。
10 相关工作
现有的交换软件。有各种专有的交换机软件实现,通常称为“网络操作系统”(NOS),例如Cisco NX-OS [12]或Juniper JunOS [41],但FBOSS与它们截然不同。例如,FBOSS允许完全访问交换机Linux,使用户可以灵活地运行自定义进程进行管理或配置。相比之下,传统的交换机软件通常通过它们自己的专有接口访问。
还有各种在Linux上运行的开源交换机软件,如Open Network Linux(ONL)[30]、OpenSwitch [11] 、Cumulus Linux 和Microsoft SONiC [33]。 FBOSS可能与SONiC最具可比性:都可以大规模运行交换机软件以满足不断增长的数据中心网络需求、又具有类似的架构(硬件抽象层,状态管理模块等)。 SONiC和FBOSS之间的一个主要区别是FBOSS不是一个单独的Linux发行版,而是和我们的大型服务器集群中使用相同的Linux操作系统和库。这使我们能够真正复用许多监视、配置和部署服务器软件的最佳实践。总体来说,交换机软件相周边关的开源社区正在开始增长,这对FBOSS来说很有希望。
最后,最近提出了从交换机中彻底消除交换机软件[31,51]的建议。它们为交换机软件的作用和数据中心交换机设计的未来提供了新的见解。
集中式网络控制。在最近的软件定义网络(SDN)浪潮中,许多系统(例如,[28,34]),有时也被称为“网络操作系统”,以实现集中式网络控制。虽然我们依赖于集中配置管理和分布式BGP守护进程,但FBOSS在很大程度上与这些努力正交。根据功能,即使实现和性能特征完全不同,FBOSS也可以与Open vSwitch [44]等软件交换机相媲美。事实上,类似于Open vSwitch使用OpenFlow的方式,理论上,FBOSS的Thrift API可以与中央控制器连接,以提供更像SDN的功能。
大规模软件部署。 fbossdeploy受到支持连续金丝雀的其他云规模[16]持续集成框架的影响[45]。一些值得著名的例子是Chef [3],Jenkins [6],Travis CI [10]和Ansible [1]。与其他框架相反,fbossdeploy专门用于部署交换机软件。它能够监视网络,以在部署过程中执行特定于网络的修复。此外,fbossdeploy可以以考虑全局网络拓扑的方式部署交换机软件。
网络管理系统。有许多网络管理系统可与供应商特定设备进行交互。例如,HP OpenView [23]具有控制许多厂商交换机的接口。 IBM Tivoli Netcool [29]实时处理各种网络事件,以便进行有效的故障排除和诊断。 OpenConfig [9]最近提出了一个统一的厂商无关的配置界面。 FBOSS没有使用标准化管理接口,而是提供可编程API,可与厂商无关的其他网络管理系统集成。
11 结论
本文回顾了Facebook过去五年间为大规模生产环境数据中心构建的开发、部署、运营和开源的交换机软件。 在构建和部署交换机软件时,我们避开了传统方法,且采用了广泛用于确保构建和部署通用软件的可扩展性和弹性的技术。 我们构建了一组模块化抽象,允许软件不受特定功能或硬件限制。 我们构建了一个持续部署系统,允许软件以增量和快速方式进行更改、自动测试并逐步安全地部署。我们构建了一个自定义管理系统,允许更简单的配置管理、监控和操作。 我们的方法提供了显著的优势,使我们能够快速,渐进地扩展我们的网络规模和功能,同时降低软件复杂性。
参考资料:
1.[n. d.]. Ansible is Simple IT Automation. https://www.ansible.com/.
2.[n. d.]. Apache Thrift. https://thrift.apache.org/.
3.[n. d.]. Chef. https://www.chef.io/chef/.
4.[n. d.]. FBOSS Open Source. https://github.com/facebook/fboss.
5.[n. d.]. FBOSS Thrift Management Interface. https://github.com/ facebook/fboss/blob/master/fboss/agent/if/ctrl.thrift.
6.[n. d.]. Jenkins. https://jenkins-ci.org/.
7.[n. d.]. Kerberos: The Network Authentication Protocol. http://web.mit. edu/kerberos/.
8.[n. d.]. Microsoft showcases the Azure Cloud Switch. https://azure.microsoft.com/en-us/blog/ microsoft-showcases-the-azure-cloud-switch-acs/.
9.[n. d.]. OpenConfig. https://github.com/openconfig/public.
10.[n. d.]. Travis CI. https://travis-ci.org/.
11.2016. OpenSwitch. http://www.openswitch.net/.
12.2017. Cisco NX-OS Software. http://www.cisco.com/c/en/us/products/ ios-nx-os-software/nx-os-software/index.html.
13.2018. Facebook Open Routing Group. https://www.facebook.com/ groups/openr/about/.
14.2018. HwSwitch implementation for Mellanox Switch. https://github. com/facebook/fboss/pull/67.
15.Lior Abraham, John Allen, Oleksandr Barykin, Vinayak Borkar,
Bhuwan Chopra, Ciprian Gerea, Daniel Merl, Josh Metzler, David
Reiss, Subbu Subramanian, Janet L. Wiener, and Okay Zed. 2013. Scuba: Diving into Data at Facebook. Proc. VLDB Endow. 6, 11 (Aug. 2013), 1057–1067. https://doi.org/10.14778/2536222.2536231
16.Michael Armbrust, Armando Fox, Rean Griffith, Anthony D. Joseph,
Randy Katz, Andy Konwinski, Gunho Lee, David Patterson, Ariel Rabkin, Ion Stoica, and Matei Zaharia. 2010. A View of Cloud Computing. Commun. ACM 53, 4 (April 2010), 50–58. https://doi.org/10.1145/1721654.1721672
17.Randy Bias. 2016. The History of Pets vs Cattle and How to Use the Analogy Properly. http://cloudscaling.com/blog/cloud-computing/ the-history-of-pets-vs-cattle/.
18.Pat Bosshart, Dan Daly, Glen Gibb, Martin Izzard, Nick McKeown,
Jennifer Rexford, Cole Schlesinger, Dan Talayco, Amin Vahdat, George Varghese, and David Walker. 2014. P4: Programming Protocolindependent Packet Processors. SIGCOMM Comput. Commun. Rev. 44, 3 (July 2014), 87–95. https://doi.org/10.1145/2656877.2656890
19.Pat Bosshart, Glen Gibb, Hun-Seok Kim, George Varghese, Nick McKeown, Martin Izzard, Fernando Mujica, and Mark Horowitz. 2013. Forwarding Metamorphosis: Fast Programmable Match-Action Processing in Hardware for SDN. In SIGCOMM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication (SIGCOMM). 99–110. http://doi.acm.org/10.1145/2486001.2486011
20.Cumulus. [n. d.]. Cumulus Linux. https://cumulusnetworks.com/ products/cumulus-linux/.
21.Harrington D., R. Presuhn, and Wijnen B. 2002. An Architecture for Describing Simple Network Management Protocol (SNMP) Management
Frameworks. https://tools.ietf.org/html/rfc4862.
22.Sebastian Elbaum, Gregg Rothermel, and John Penix. 2014. Techniques for Improving Regression Testing in Continuous Integration Development Environments. In Proceedings of the 22Nd ACM SIG-
SOFT International Symposium on Foundations of Software Engineering (FSE 2014). ACM, New York, NY, USA, 235–245. https:
//doi.org/10.1145/2635868.2635910
23.HP Enterprise. [n. d.]. HP Openview. https://software.microfocus.com/ en-us/products/application-lifecycle-management/overview.
24.Facebook. 2017. Wedge 100S 32x100G Specification. http://www.
opencompute.org/products/facebook-wedge-100s-32x100g/.
25.Tian Fang. 2015. Introducing OpenBMC: an open software framework for next-generation system management. https://code.facebook.com/ posts/1601610310055392.
26.A. Farrel, J.-P. Vasseur, and J. Ash. 2006. A Path Computation Element (PCE)-Based Architecture. Technical Report. Internet Engineering Task Force.
27.Phillipa Gill, Navendu Jain, and Nachiappan Nagappan. 2011. Understanding Network Failures in Data Centers: Measurement, Analysis, and Implications. In Proceedings of the ACM SIGCOMM 2011 Conference (SIGCOMM ’11). ACM, New York, NY, USA, 350–361. https://doi.org/10.1145/2018436.2018477
28.Natasha Gude, Teemu Koponen, Justin Pettit, Ben Pfaff, Martín Casado,
Nick McKeown, and Scott Shenker. 2008. NOX: Towards an Operating
System for Networks. SIGCOMM Comput. Commun. Rev. 38, 3 (July 2008), 105–110. https://doi.org/10.1145/1384609.1384625
29.IBM. [n. d.]. Tivoli Netcool/OMNIbus. https://www-03.ibm.com/ software/products/en/ibmtivolinetcoolomnibus.
30.Big Switch Networks Inc. 2013. Open Network Linux. https:
//opennetlinux.org/.
31.Xin Jin, Nathan Farrington, and Jennifer Rexford. 2016. Your Data Center Switch is Trying Too Hard. In Proceedings of the Symposium on SDN Research (SOSR ’16). ACM, New York, NY, USA, Article 12,
6 pages. https://doi.org/10.1145/2890955.2890967
32.D Joachimpillai and JH Salim. 2004. Forwarding and Control Element
Separation (forces). https://datatracker.ietf.org/wg/forces/about/.
33.Yousef Khalidi. 2017. SONiC: The networking switch software that powers the Microsoft Global Cloud. https://azure.github.io/SONiC/.
34.Teemu Koponen, Martin Casado, Natasha Gude, Jeremy Stribling, Leon
Poutievski, Min Zhu, Rajiv Ramanathan, Yuichiro Iwata, Hiroaki Inoue,
Takayuki Hama, and Scott Shenker. 2010. Onix: A Distributed Control Platform for Large-scale Production Networks. In Proceedings of the 9th USENIX Conference on Operating Systems Design and Implementation (OSDI’10). USENIX Association, Berkeley, CA, USA, 351–364. http://dl.acm.org/citation.cfm?id=1924943.1924968
35.David L. Tennenhouse and David J. Wetherall. 2000. Towards an Active Network Architecture. 26 (07 2000), 14.
36.P. Lapukhov, A. Premji, and Mitchell J. 2016. Use of BGP for Routing in Large-Scale Data Centers. https://tools.ietf.org/html/rfc7938.
37.Ville Lauriokari. 2009. Copy-On-Write 101. https://hackerboss.com/ copy-on-write-101-part-1-what-is-it/.
38.K. Lougheed, Cisco Systems, and Y. Rkhter. 1989. A Border Gateway
Protocol (BGP). https://tools.ietf.org/html/rfc1105.
39.R. P. Luijten, A. Doering, and S. Paredes. 2014. Dual function heatspreading and performance of the IBM/ASTRON DOME 64-bit microserver demonstrator. In 2014 IEEE International Conference on IC Design Technology. 1–4. https://doi.org/10.1109/ICICDT.2014. 6838613
40.Nick McKeown, Tom Anderson, Hari Balakrishnan, Guru Parulkar, Larry Peterson, Jennifer Rexford, Scott Shenker, and Jonathan Turner.
2008. OpenFlow: Enabling Innovation in Campus Networks. SIGCOMM Comput. Commun. Rev. 38, 2 (March 2008), 69–74. https:
//doi.org/10.1145/1355734.1355746
41.Juniper Networks. 2017. Junos OS. https://www.juniper.net/us/en/ products-services/nos/junos/.
42.Tuomas Pelkonen, Scott Franklin, Justin Teller, Paul Cavallaro, Qi
Huang, Justin Meza, and Kaushik Veeraraghavan. 2015. Gorilla: A Fast,
Scalable, In-memory Time Series Database. Proc. VLDB Endow. 8, 12
(Aug. 2015), 1816–1827. https://doi.org/10.14778/2824032.2824078
43.A.D. Persson, C.A.C. Marcondes, and D.P. Johnson. 2013. Method and system for network stack tuning. https://www.google.ch/patents/ US8467390 US Patent 8,467,390.
44.Ben Pfaff, Justin Pettit, Teemu Koponen, Ethan Jackson, Andy Zhou, Jarno Rajahalme, Jesse Gross, Alex Wang, Joe Stringer, Pravin Shelar, Keith Amidon, and Martin Casado. 2015. The Design and Implementation of Open vSwitch. In 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI 15). USENIX Association, Oakland, CA, 117–130. https://www.usenix.org/conference/nsdi15/ technical-sessions/presentation/pfaff
45.Danilo Sato. 2014. Canary Release. https://martinfowler.com/bliki/ CanaryRelease.html.
46.Brandon Schlinker, Hyojeong Kim, Timothy Cui, Ethan Katz-Bassett,
Harsha V. Madhyastha, Italo Cunha, James Quinn, Saif Hasan, Petr Lapukhov, and Hongyi Zeng. 2017. Engineering Egress with Edge
Fabric: Steering Oceans of Content to the World. In Proceedings of the
ACM SIGCOMM 2017 Conference (SIGCOMM ’17). ACM, New York, NY, USA, 418–431. https://doi.org/10.1145/3098822.3098853
47.Arjun Singh, Joon Ong, Amit Agarwal, Glen Anderson, Ashby Armistead, Roy Bannon, Seb Boving, Gaurav Desai, Bob Felderman, Paulie
Germano, Anand Kanagala, Jeff Provost, Jason Simmons, Eiichi Tanda,
Jim Wanderer, Urs Hölzle, Stephen Stuart, and Amin Vahdat. 2015.
Jupiter Rising: A Decade of Clos Topologies and Centralized Control in
Google’s Datacenter Network. SIGCOMM Comput. Commun. Rev. 45,
4 (Aug. 2015), 183–197. https://doi.org/10.1145/2829988.2787508
48.Yu-Wei Eric Sung, Xiaozheng Tie, Starsky H.Y. Wong, and Hongyi Zeng. 2016. Robotron: Top-down Network Management at Facebook Scale. In Proceedings of the ACM SIGCOMM 2016 Conference (SIGCOMM ’16). ACM, New York, NY, USA, 426–439. https:
//doi.org/10.1145/2934872.2934874
49.David Szabados. 2017. Broadcom Ships Tomahawk 3, Industry’s Highest Bandwidth Ethernet Switch Chip at 12.8 Terabits per Second. http://investors.broadcom.com/phoenix.zhtml?c=203541&p= irol-newsArticle&ID=2323373.
50.S Thomson, Narten T., and Jinmei T. 2007. IPv6 Stateless Address
Autoconfiguration. https://tools.ietf.org/html/rfc4862.
51.F. Wang, L. Gao, S. Xiaozhe, H. Harai, and K. Fujikawa. 2017. Towards reliable and lightweight source switching for datacenter networks. In IEEE INFOCOM 2017 - IEEE Conference on Computer Communications. 1–9. https://doi.org/10.1109/INFOCOM.2017.8057152
52.Jun Xiao. 2017. New Approach to OVS Datapath Performance. http: //openvswitch.org/support/boston2017/1530-jun-xiao.pdf.
53.Xilinx. [n. d.]. Lightweight Ethernet Switch. https://www.xilinx. com/applications/wireless-communications/wireless-connectivity/ lightweight-ethernet-switch.html.








