作者简介:昌昊,英特尔软件工程师,负责Hyperscan算法开发和性能调优相关工作。主要研究领域包括自动机与正则表达式匹配等。
文章转载自DPDK与SPDK开源社区
Suricata简介
如前所述,Hyperscan作为一款高性能的正则表达式匹配库,极适用于部署在IDS/IPS等网络解决方案中。
Suricata(https://suricata-ids.org) 是一款免费、开源、成熟、快速、健壮的网络威胁检测引擎,该引擎能够进行实时入侵检测(IDS),嵌入式入侵防御(IPS),网络安全监控(NSM)和离线pcap处理。Suricata与其竞争对手Snort类似,有着相似的设计和规则样式,同样涉及到大量纯字符串及正则表达式匹配。本文重点介绍Hyperscan在Suricata中的应用,主要是单字符串匹配和多字符串匹配的基本原理。
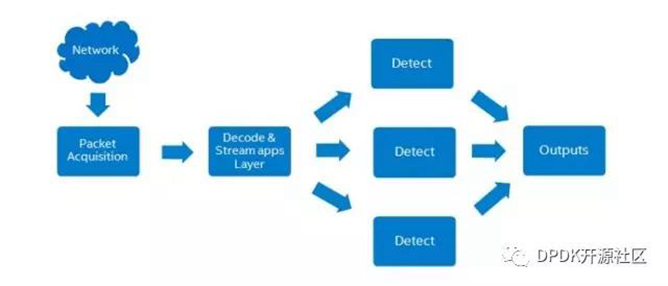
Hyperscan的应用
自Suricata(3.1 release)开始,Hyperscan在支持的平台作为其单字符串匹配和多字符串匹配的默认选项。另外也有单正则表达式匹配的试验工作。
单字符串匹配
Suricata原先使用BM算法做单字符串匹配,使用Hyperscan后,由Hyperscan中的Noodle引擎替换相关工作。Noodle充分发挥SIMD指令优势,通过对输入数据进行快速的预过滤来实现快速的单字符串匹配,在AVX2、AVX512上能达到更快的效果。预过滤的基本原理其实是使用朴素的shift-and算法。
例如,对单条字符串规则/Hyperscan/的单模式匹配,取字符串前2字节做预过滤,构建2个16字节的掩码:

运行时每次读取16字节输入数据,用2次PCMPEQB指令与上述掩码做逐字节比较。假设运行时读到输入数据为“MATCHmyHyperscan”,则2次PCMPEQB的结果为(表中的1实际应为0xFF,为表达简便标记为1):

对上述结果做“shift-and”,即LSHIFT+AND指令,得到用2个字节做预过滤的结果:

预过滤结果中出现“1”的位置才是可能产生真实匹配的位置(我们称之为Positive),我们对这些位置进行确认,最终生成一个真实匹配(True Positive),或者发现不是真实匹配(False Positive)。本例中是一个真实匹配。
对AVX2/AVX512环境,能够得到更好的表现,因为对AVX2可以构建32字节掩码且每次读取32字节输入数据,对AVX512可以构建64字节掩码且每次读取64字节输入数据,完成同样的预过滤目标所需的指令数减少了很多。
多字符串匹配
Suricata原先使用AC算法做多字符串匹配,使用Hyperscan后,由Hyperscan中的Teddy/FDR引擎替换相关工作。Teddy通常在轻量级多字符串匹配场景下(2-72条字符串)优先使用,FDR则用来应对极大量字符串的场景。同样,Teddy和FDR使用SIMD指令对输入数据进行快速预过滤,在多字符串匹配场景下,比单字符串匹配有更好的效果。类似的,其预过滤的基本原理是使用朴素的shift-or算法。
以Teddy为例,Teddy通常情况下使用字符串中的后3字节做预过滤,对多字符串规则,根据每个字符串的后3字节进行分组,分组上限为8或16组,为表达输入数据中每个位置的预过滤结果,前者用1字节(每位各对应一组),后者用2字节。
例如,对3条字符串规则:
/Teddy/
/daddy/
/Hyperscan/
根据后3字节分为2组:组0 – “ddy”(0x64, 0x64, 0x79),组1 – “can”(0x63, 0x61, 0x6e)。
再根据3字节中的6个4位构建出6个16字节掩码,初值全1,每个4位有16种可能取值,对应16字节掩码中的1字节,并在该对应字节的对应位(组)上贡献一个0。6个掩码依次对应最末字节低4位、高4位(绿色),倒数第二字节低4位、高4位(橙色),倒数第三字节低4位、高4位(蓝色)。为简化表达每字节只记录本例中两组对应的两位:

运行时每次读取16字节输入数据,并以上述掩码用PSHUFB指令逐字节做映射。假设运行时读到输入数据为“TeddyinHyperscan”(54 65 64 64 79 69 6e 48 79 70 65 72 73 63 61 6e),则6次PSHUFB的结果为:
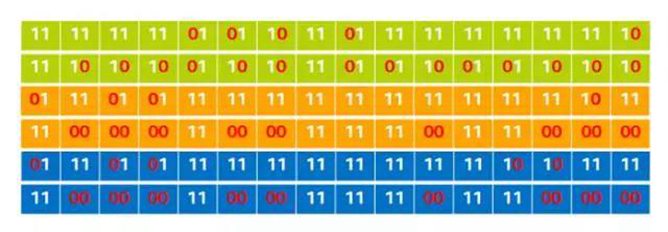
结果中的”0”表示输入数据中每个位置(列)对规则集后3字节是否产生匹配。相同位置只有高4位和低4位均得到相同组的匹配,才是一个完整字节的匹配。对相同颜色的掩码做OR得到:

对上述结果做“shift-or”,第一行不变,第二行做LSHIFT左移1字节,第三行做LSHIFT左移2字节,然后做OR得到:

此为预过滤的结果,其中的”0”表示在该位置出现与某组连续后3字节的匹配,是可能产生真实匹配的位置(Positive)。我们对这些位置进行确认,最终找出与候选组中哪个字符串产生了真实匹配(True Positive),或者发现不是真实匹配(False Positive)。本例中在位置4对组0的“Teddy”、位置15对组1的“Hyperscan”产生真实匹配。
同样的,对AVX2环境,我们只需把6个掩码均复制扩大一倍至32字节,且每次读取32字节输入数据;对AVX512环境,把掩码复制扩大至64字节,每次读取64字节输入数据。完成相同过滤目标的指令数也减少了很多。
性能数据
测试环境:Intel® Core i7 6700K CPU @ 4.0 GHz
软件版本:Hyperscan 4.3.1,Suricata 3.1
规则集:Emerging Threats public set (“emerging-all-20161102.rules”)
ET Pro set (“etpro-all-20161102.rules”)
输入PCAP文件:Alexa Top 100 browsing PCAP file
测试中我们衡量的是全部处理时间,包括编译和运行。原生的Suricata使用AC算法做多字符串匹配(MPM)和BM算法做单字符串匹配(SPM),使用Hyperscan全部替换后,在Emerging Threats规则集上获得1.95x性能提升,在ET Pro规则集上获得2.15x性能提升。
我们同样比较了单独替换多字符串AC算法及单独替换单字符串BM算法的性能,可见替换AC的性能要好于替换BM的性能,而二者性能又都介于原生和全部替换之间。各性能数据如下图所示。
这是可以预见的结果,因为对多模式匹配的良好支持正是Hyperscan的一大优势。