作者简介:Jasvinder Singh,英特尔网络软件工程师,主要负责DPDK数据面功能和库的开发,主要贡献包括报文处理框架和ip_pipeline示例应用程序。
文章转载自DPDK与SPDK开源社区
DPDK报文处理框架(以下简称”处理框架”)能够帮助开发者在英特尔®的多核处理器上快速部署基于实际数据报文的处理工作负载,其灵活性高,性能优越。 该框架基于三个DPDK库:librte_port,librte_table和librte_pipeline。
处理框架最初是在DPDK v2.1中被引入的,同时被引入的还有示例程序ip_pipeline。在之后的版本中,更多的功能被加入到ip_pipeline这个示例程序中,使其转变成为一个可以用于开发复杂报文处理的工具包,如边缘路由器。 这里的信息适用于DPDK 16.04及更高版本。
DPDK报文处理框架库
处理框架使用一组DPDK库(librte_port,librte_table和librte_pipeline)来定义一个标准方法,用于处理复杂环境下的数据报文。该标准方法提供了一个可重用的、易扩展的模板,开发者可以将各种简单的功能基于该模板开发,作为流水线的一个标准模块,然后根据自身业务的需要,将各个模块以流水线的方式灵活的搭建起来,构建复杂的数据报文处理程序。
每一个流水线模块都由三个原语实体构成:输入端、输出端和流表。图1为一个示例。
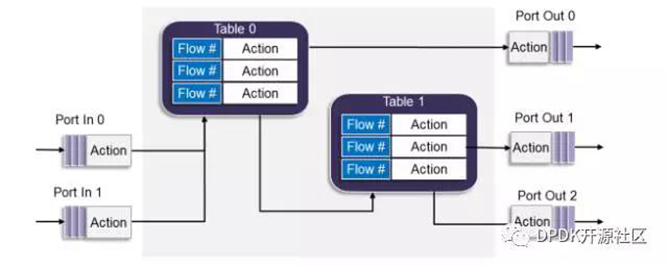
一个输入端只能连接到一个流表,但是,单个流表可以连接到其他流表或输出端。
在数据包经过流水线模块进行处理时,可以执行各种操作(actions), 例如在输入端进行数据包头部完整性检查和验证。 另外,根据流表查找的结果,可以执行相应的操作(actions),例如将数据包转发到另一个流表,或将数据包发送到输出端口,或者直接丢弃。
IP_pipeline示例程序
IP_pipeline示例程序旨在展示处理框架的使用方法。DPDK代码库中的这一示例程序使用上述流水线模型,实现了以下数据平面功能:
直通流水线(Pass-through):
此流水线仅仅在其输入端口和输出端口之间建立了连接,通常用于将不同类型的端口联接起来。 该流水线可以实现多种功能,如流量均衡、计算后续阶段需要的元数据(metadata)等等。
流分类流水线(Flow classification):
此流水线将所有输入端口都连接到一个流表,并在该流表中进行哈希查找,从而对数据包进行流分类,并将不同流发送到匹配的端口。这种流水线可以对不同类型的数据包(如QinQ,IPv4和IPv6)进行分类。
路由流水线(Routing):
此流水线使用实现最长匹配算法的(LPM)表来为传入的包规划路由。 如果在流水线中启用快速路径地址解析协议(ARP)(使用哈希表实现),那么输出端口将会由LPM和ARP表查询来决定。 根据下一跳协议,也可以在此结点用QinQ或多协议标签交换(MPLS)标签对报文进行封装。
防火墙流水线(Firewall):
此流水线使用访问控制列表(ACL)来对传入的数据报文执行防火墙策略。
流操作(Flow action):
流量计数和标记(traffic metering/marking),为不同的数据包标记不同颜色,作为统计用户/流使用其预分配带宽的方法。
流量监管(traffic policing),基于标记的颜色对输入数据包执行预定义的操作。
这些流水线模型可以被看成是预制模板,开发者可以通过配置文件的方式,对模型进行实例化和互通互联,创建完整的应用程序。
示例程序配置文件定义了应用的结构,包括流水线实例、设备队列和软件队列。不同的应用程序的创建要使用不同的配置文件;因此,ip_pipeline示例程序可以被看作是一个应用程序生成器。每个流水线的配置可以在运行时通过应用程序的命令行接口(CLI)进行更新。
运行IP_pipeline示例程序
运行ip_pipeline示例程序要遵循以下步骤:
(1)前往ip_pipeline示例程序目录:
|
1 |
$ cd /home/dpdk/examples/ip_pipeline/ |
(2) 导出下列环境变量,设定编译目标,下面的例子使用GCC为编译器,编译目标为Linux下的64位应用程序:
|
1 2 |
$ export RTE_SDK = /home/dpdk $ export RTE_TARGET = x86_64-native-linuxapp-gcc |
(3)建立ip_pileline示例程序
|
1 |
$ make |
•要运行ip_pipeline示例程序,请使用以下命令行:
|
1 |
ip_pipeline [-f CONFIG_FILE] [-s SCRIPT_FILE] -p PORT_MASK [-l LOG_LEVEL] |
示例程序的命令行参数是:
•-f CONFIG_FILE: (optional, default: ./config/ip_pipeline.cfg).
这是示例程序要加载的配置文件的路径。
•-s SCRIPT_FILE: (optional).
这是在示例程序启动时由主管道运行的CLI脚本文件的路径。 如果此参数不存在,则不会在启动时运行CLI脚本文件。
•-p PORT_MASK: (required).
示例程序要使用的NIC端口ID的十六进制掩码。
•-l LOG_LEVEL: (optional).
日志级别决定了哪些应用消息可以打印到标准输出中来。可用的日志级别有:0(无),1(高优先级),2(低优先级)
示例: L3转发
Ip_pipline应用通过提供几个示例应用和配置文件,展示了流水线模块的使用方法。
图2展示了三层(L3)转发应用的配置文件。
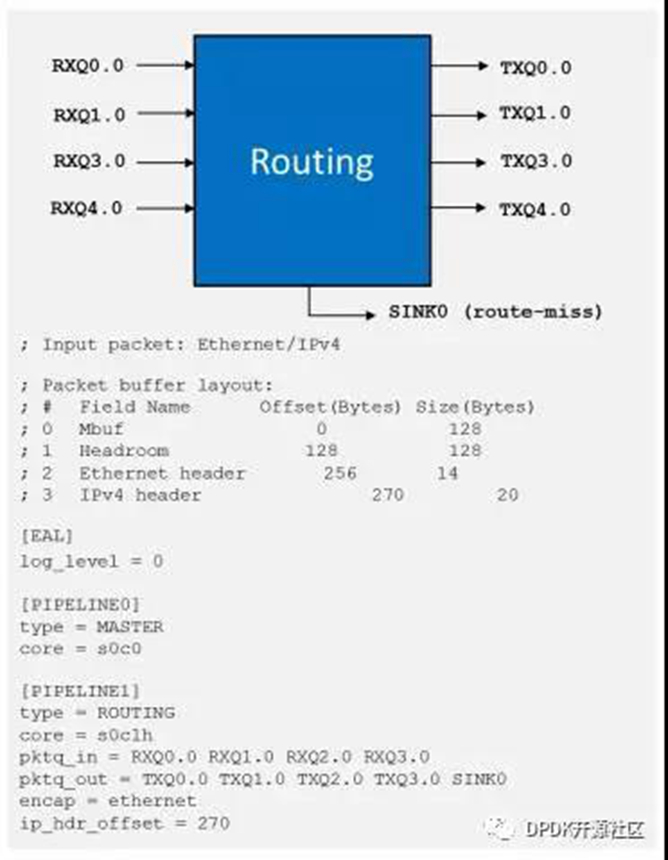
在文件中,[PIPELINE]部分定义了流水线中的各种参数。在这一示例中,它设置了简单的路由。
“core” 条目线程ID(socket ID,物理CPU ID和超线程ID)确定了用来运行流水线的CPU核。
“pktq_in” 和 “pktq_out”参数定义了数据包传输的接口,这里指接受和传送数据包。
可以将“encap”参数设置为“ethernet”, “qinq”或“mpls”,用来为所有出站包封装合适的包头。
最后一个参数”ip_hdr_offset”可用于设置DPDK数据包结构(mbuf)中ip-header的起始位置所需偏移字节。
图三展示了ip_pipeline的脚本文件,该文件中的内容将作为路由表项加入到路由流水线的最长匹配表中。此文件中的条目 “encap”字段设置为“ethernet”并禁用快速路径ARP。
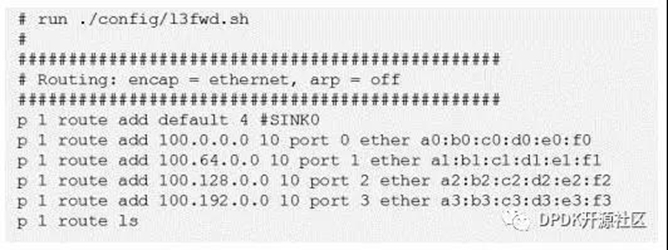
脚本文件中的规则采用以下格式:
|
1 |
p <pipeline_id> route add <ip_addr> <depth> port <port_id> ether <next hop mac_addr> |
可使用以下命令来运行L3转发应用:
|
1 |
$./build/ip_pipeline -f l3fwd.cfg -p 0xf -s l3fwd.sh |
拓扑可视图
有时,应用程序在不同的功能模块之间进行互联时具有复杂的拓扑结构。在这种情况下,仅仅查看它的配置文件很难理解应用程序包处理流程。为了解决这一问题,我们使用了一个名为diagram-generator 的Phython程序,从配置文件中创建应用程序的拓扑可视图。
一旦应用程序配置文件准备就绪,请运行以下命令生成拓扑图。
|
1 |
$./diagram-generator.py -f <configuration file> |
图4展示了复杂的ip_pipeline示例程序生成拓扑的一部分。
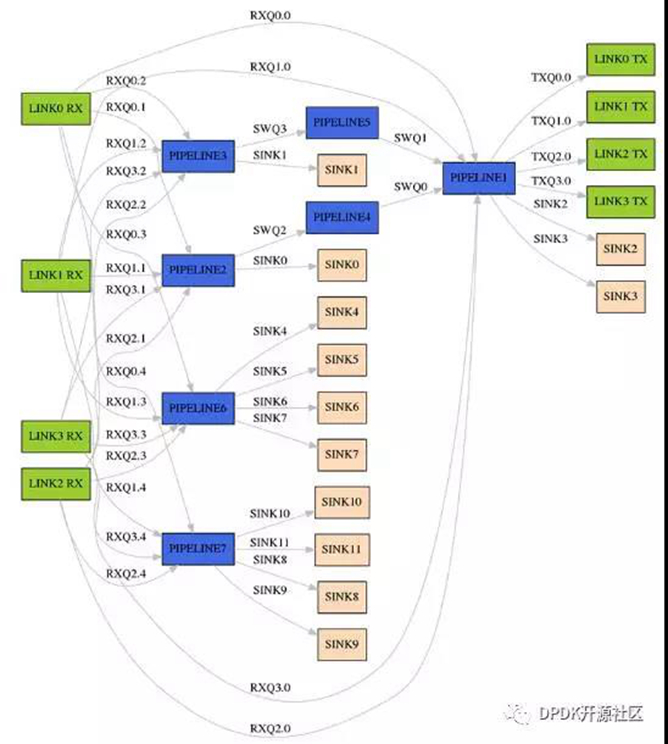
结 论
本文介绍了DPDK报文处理框架库,它可以使开发者在多核CPU系统上,迅速开发基于实际数据报文(real-world packet)的处理应用程序,并提供使用该库构建的标准流水线模型的架构。
各种使用此标准流水线模型构建的网络功能(流水线)都可作为DPDK ip_pipeline示例应用程序的一部分。 尽管其中一些示例比较简单,但是在实际运用中,开发者可以创建配置文件,搭建出符合实际需要的程序。此外,本文还介绍了如何运行示例程序,以及如何使用命令生成流处理的拓扑可视图。
本文翻译自Intel Developer Zone,点击以下链接可浏览原文。