

作者简介:储子叡,互联港湾软件架构师,资深网络爱好者 曾供职于Juniper/Brocade/VMware,对网络安全/操作系统内核/包转发/ASIC均有涉猎
“在革命的每个阶段都有人退出,这一点也不奇怪,正如大多数创业公司都会死掉,因此任何时间退出从概率上来看往往都是正确的。”
我们的问题在于,OpenFlow还行不行,如果不行了,是不是该选择退出?是彻底退出,还是给OpenFlow找个接班人?这个问题相信已经在SDN界(如果真的有SDN界的话)持续了一段时间了。

让人不禁有些气馁的是,我们不得不进行如下的思考,OpenFlow从当红炸子鸡变成今天的过气网红,这期间到底发生了什么?先天不足还是后天发育不良?是时机未到还是参与者各自心怀鬼胎?
这些问题里最幽默的是,很多振振有词的质疑者,他们其实根本连OpenFlow/OpenFlow-Controller 架构是什么也搞不清楚,更别说读懂一条流表,抑或是看懂一行OVS的代码。我虽然不是OpenFlow的铁粉,也觉得有必要来个正本清源,谈谈OpenFlow是什么,谈谈如何走到这一步,再谈谈将来的事情不迟。
首先,要谈论OpenFlow,先要说控转分离即控制平面(Control-plane)和转发平面的(Forwarding-plane)的分离。转发平面有时候也被叫做数据平面(Data-plane),其原因就是交换机/路由器/防火墙这些所谓的数通设备,其本质特征就是转发,数据包从一个接口进来,从另一个接口(可能是同一个接口)或者多个接口出去,如此而已。关键在于,进来的数据包从哪个(或者哪些)端口出去,由谁来决定?毫无疑问是由控制平面决定。控制平面根据从管理平面(Management-plane)来的命令/配置,加上通过路由/广播等方法学来的网络拓扑,应用到特定的数据包身上,从而得出相应的转发动作,通常而言,是把数据包复制一份,修改相应的报文字段,再从另外一个接口送出去。
传统设备上控制平面和转发平面从来都是分离的。所谓控转分离,是指把原先存在于每个设备的控制平面抽出来,集中放在一台或者几台核心设备上,由这些设备计算出网络拓扑和每个具体流量需要经过的转发路径,计算的依据,依然是来自控制平面的命令/配置,以及可以学习的拓扑。计算结果流表通过OpenFlow协议下发到每台设备上,设备仅需要匹配这些下发的流表完成转发动作即可。因此,要理解OpenFlow,必须理解流表。
首先要搞懂流表,流表就是一张表!和一张普通的数据库表并没有什么不一样,都是由一些字段(Field)定义的,可以把它们称为列。而流表的具体内容,可以称为行。列是需要预先定义(Pre-defined)的,而行则是可以随时(Run-time)被增删改查(CRUD)的。
我们先忽略OpenFlow复杂的版本关系,看看这张表抽象以后是个什么样子。

首先,Header Fields是数据包的包头。我们知道几乎所有的数据包都是由包头(header)和负载(payload)组成的。一个数据包可能有很多个包头组成的,这实际上就是网络分层(layer)的本质,每一层都有自己的能够提供的服务(service),而服务其实就是定义在包头里的。下个层次的包头对于上一个层次来说,是负载的一部分。打个比方来说TCP的包头就是紧接在IP包头的后面的,对于IP这个层次来说,TCP的包头就是负载。所以,从数据流的视角来看,数据包是由一系列的包头依次组成的,不同的转发层面的动作,例如我们常说的二层交换,三层路由,四层防火墙,其实就是对于数据包这个连续的数据流,你看多远(多少个包头)而已。其实并没有本质区别。
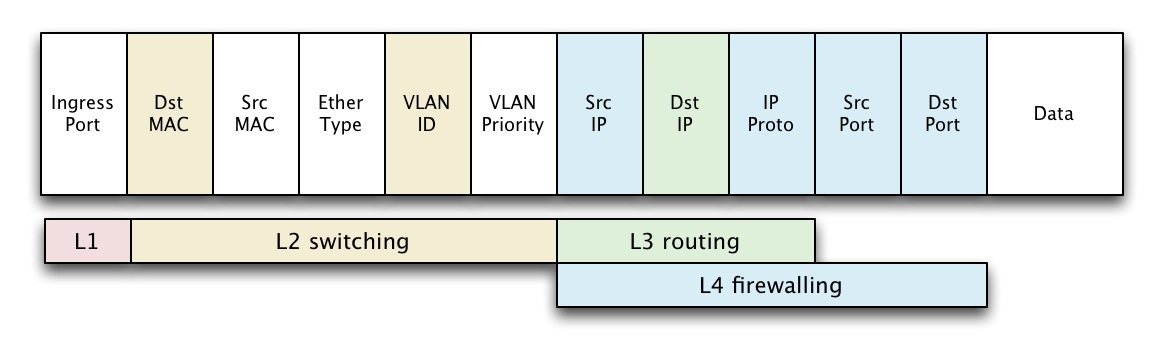
因此,OpenFlow 的Header Fields是一系列需要匹配的包头的组合。
OpenFlow的转发动作就是从以上连续的包头的域(Field)里,找出需要匹配的那些,用来标志出一个数据流(Flow),对于所有匹配这个流的数据包,均做相同的动作(Action),并且更新计数器(Counter)。对于所有Flow都不能匹配的数据包,则需要用Packet-in的消息把这个数据包送到控制器去,由控制器来决定怎么办,或者丢弃,或者为这个包创建一个新的数据流。
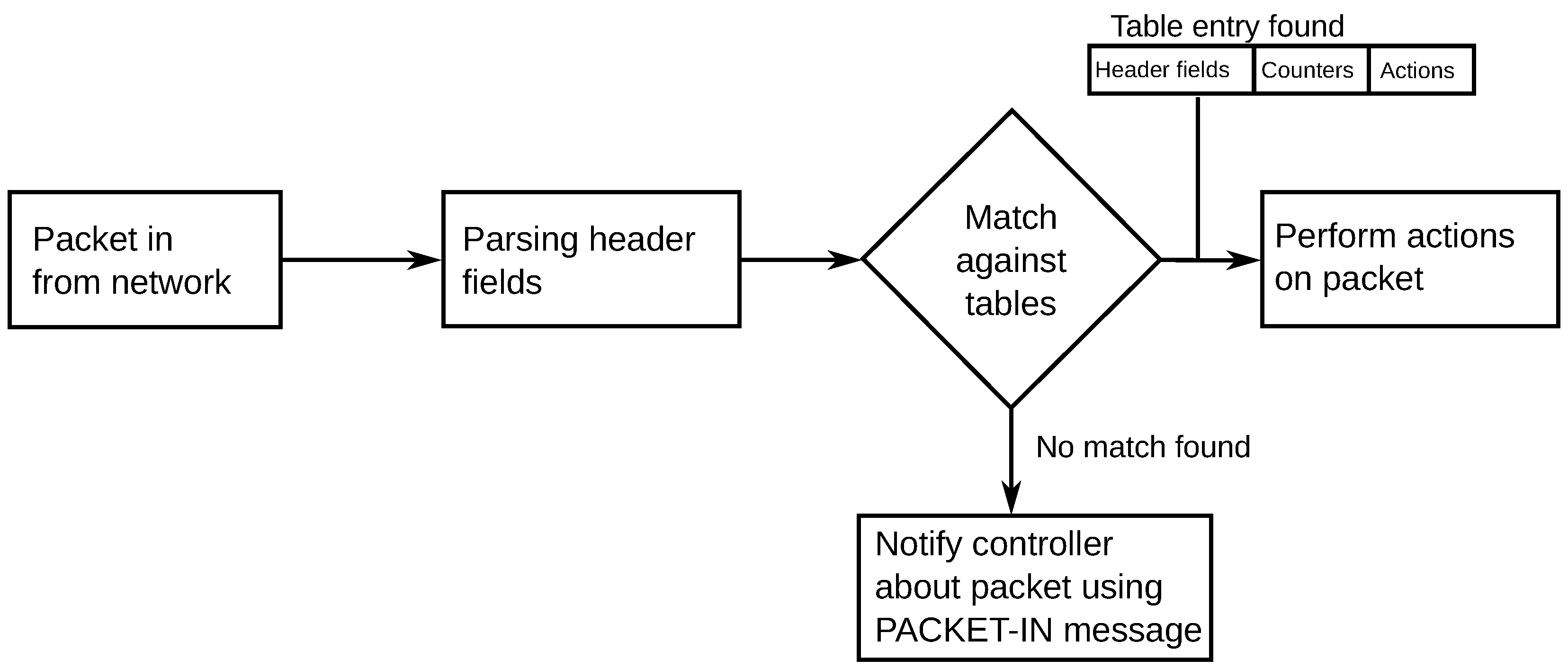
通过OpenFlow完成的转发动作,和原先传统设备的转发流程并没有区别,换句话说,如果传统设备厂商愿意,完全可以在自己单台设备的控转平面之间跑OpenFlow,因此,控转分离的架构不会给转发设备带来任何挑战,那么OpenFlow带来的真正挑战是什么?
如下是一个具体的OpenFlow的表,看看其中有何奥妙。
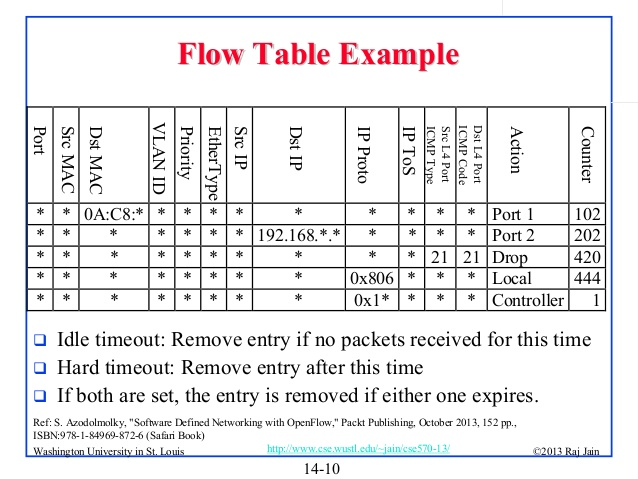
我们知道数据库的设计,查起来快不快,关键在于键(Key)和索引(Index),以上这个表的问题是键在哪里?可能被用来做为匹配的字段高达十二个,而每一行都可能只有这十几个字段中的几个,没有键和索引,没办法迅速查表!
为什么要查表?刚才只讲了转发动作中控制平面和转发平面的互动,由控制平面来决定如何进行转发,但是显然一个数据流可能包括成千上万个数据包,决定了第一个包怎么转发,其实基本就确定了后面所有的包如何转发,完全没有必要请控制平面来参与所有包的处理,转发平面需要做的仅仅是查表而已,这个包属于曾经被转发过的流,简单的复制一下转发动作即可,这就是所谓的快速转发(Fast-path)。一个数据包从入接口(Ingress)进来,OpenFlow交换机需要确定他匹配哪个流,从而找到相应的转发动作,迅速的把这个数据包从出接口(Egress)送出去,然后赶紧去处理下一个数据包,必须迅速查流表,而不是线性查流表。换句话说,不能从第一行(Line)开始一行一行匹配,看这个数据包的Header Field是不是跟这一行匹配。如果这个表有成千上万的行,逐行的查找是不可接受的,因为需要的时间,根本不能匹配10Gbps或者更高的速率!
首先看传统网络设备是怎么干的,传统设备里也有转发表,例如一个传统的防火墙,他的转发表可能支持一百万个会话(session),标志一个会话的特征是五元组(源目的地址/源目的端口/协议号),所以一个数据包进来以后,防火墙需要做的就是把这个五元组提取出来,然后根据这个五元组算一个哈希值(Hash),根据这个哈希值,常数时间O(1)直接可以找到会话,然后或者匹配这个会话以后,就知道应该把包送到哪个出接口,是不是需要对包头进行修改,进行转发即可。如果匹配不到任何会话(把这个数据包送给控制平面的CPU,看能不能建立一个新的会话)。传统设备为什么可以这么干?因为他们的功能是限定的,他们需要处理的包头的域是确定无疑的,那么提取这些域,然后做哈希查找/快速转发,全部可以用硬件实现,从而达到非常高的转发速率。
问题是到了OpenFlow这个新世界里,有些假设不存在了,还是以上这张表,在看到具体的表内容之前,交换机/路由器是不可能预先知道需要提取哪些字段的,也很难提前做硬件电路设计,硬件虽说不是完全没有办法,但是局限很大,适应所有字段全灵活匹配的腾挪空间严重不足,那还怎么快速查表,怎么转发?
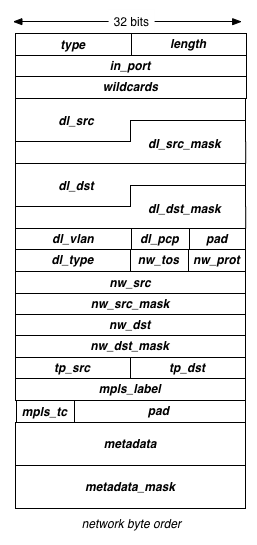
随着OpenFlow版本的不断升级,匹配(match)的字段由少变多,匹配本身也从定长变成了类似TLV的结构,如下图
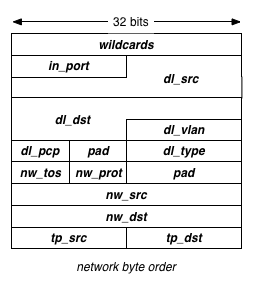
OpenFlow 1.0
OpenFlow 1.1
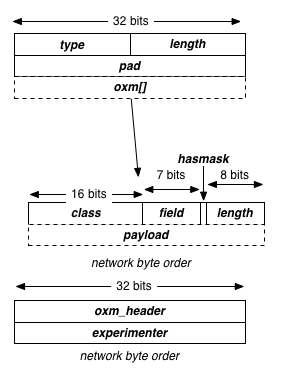
OpenFlow 1.3
虽然OpenFlow版本之间并不一致,但是“需要匹配的域是不固定的”这点并没有变化,对于大多数习惯了“二层交换,三层路由,四层防火墙”的厂商来说,二三四层灵活组合的匹配方式,的确是太复杂了。虽然各家都在努力支持更多流表的种类,支持更多流表的数目,但跟传统动辄七八十万条路由,百万级的策略/会话的大盒子(Device)来比,纯OpenFlow设备能达到的性能和指标的确是还差得很远。
因此,OpenFlow太过灵活,先天不足等等说法也就不足为奇了。
还好有些人并不这么想,硬件搞不定,就说软件太灵活,这个锅不能背!难道不能设计一个能搞定的硬件吗?答案是可以的,不仅可以,还不止一种!我们需要的是重新定义一下转发面的硬件,也就是所谓的PISA(Protocol Independent Switch Architecture),大家把这个事情统一一下认识,至于具体各家各户怎么实现,大可以自己回家闭门造车,各显其能。
PISA的核心是转发平面可以编程(Programmable),编程语言也就是比OpenFlow更红的P4了。那P4到底是不是OpenFlow的终结者/继承者/替换者呢?首先看这个图。
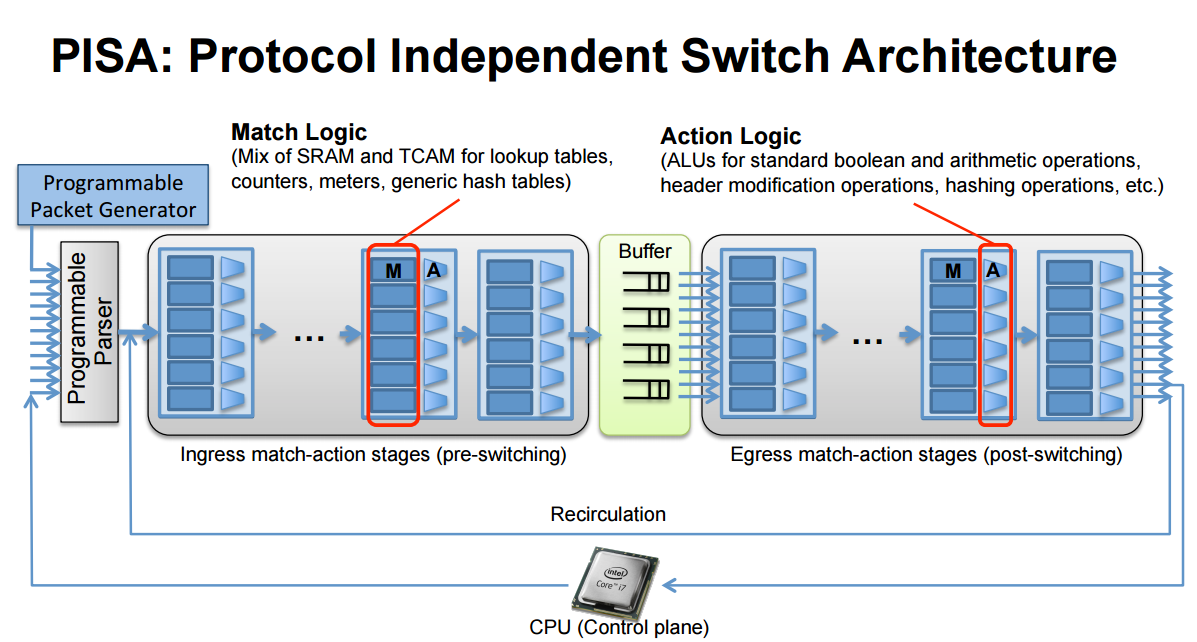
首先,Parser把数据包解析成一系列的Header,然后依次进入Ingress和Egress两类流水线。在流水线里可以经历一系列的匹配(M)/动作(A)的阶段(Stage)。每一个Stage的核心是:一张表!匹配这张表,然后根据匹配结果做动作,跟我们上面说的一摸一样对不对!那么这张表是OpenFlow的流表吗?答案是,不一定。
准确的说,某一类的流表可以转化成PISA里的一张表。看一下一张P4的表,跟OpenFlow的表比较一下。

可以发现
- P4的表是需要被P4程序明确定义的,依然是Match/Action这个思路。
- P4的表需要匹配的键(Key)是固定的,如上图的VRF/IP-Prefix
- P4支持多级的表,数据包匹配完第一个表后可以匹配下一个表,因此,对于 不同包头字段的匹配要求,可以用多个表来实现
- P4的匹配项目可以支持最长前缀匹配LPM(longest prefix match),以及带 掩码的三元匹配(Ternary Match),这是需要硬件TCAM支持的,考虑到TCAM 的成本,这样的匹配项目显然也不能太多(但是好歹比支持OpenFlow任意匹 配简单多了)。
最关键的一条,PISA 架构要求可编程性,因此用P4定义的表是可以重新编程的,重新编程P4表可以导致重新生成一个交换机的固件(Firmware),交换机下载以后,可以重新分配他的硬件(流水线,内存,TCAM等)资源,针对新的匹配表实现硬件加速。在此之前,基于ASIC的传统转发设备对此是不可想象的。ASIC被认为是固定(fixed)的,一旦硬件成型以后其匹配/转发能力就是确定而不可扩展的,软件只能通过修改寄存器来进行微调。而进行一次重要的ASIC版本升级,其消耗的时间和金钱都是巨大的。
所以简单的来说,P4的出现并不是为了替换掉OpenFlow,而是为交换机支持OpenFlow提供了可能性。OpenFlow的设计的确是灵活,但是并不是“太过灵活”,事实上,支持任何类型的OpenFlow流表并没有意义,实际情况下一台网络设备将要面对的流量和流量是可以预测的,是有限的,根据可能的OpenFlow流表写好P4的程序是可能的,通过可编程的交换芯片实现硬件加速是可能的,一旦发生未知的流量/应用重新编写P4程序并下发到P4交换机也是完全可以的。因此可以这么说,P4一开始的诞生也许是为了让交换芯片适应OpenFlow(OpenFlow Adapter),后来逐渐发展成了一种全新的可编程的交换机架构PISA,不仅表的匹配是可编程的,Parser也是可以编程的,匹配以后的动作Action也是可以编程的,PISA可以说是转发层面的一场革命。
OpenFlow的流表和P4的表本质上是一样的,都是从控制层面到转发层面的消息,而P4则定义了整个转发层面,和OpenFlow所处的位置不完全一致。P4和OpenFlow可以很好的协同工作,所以不存在有了P4就可以代替OpenFlow的说法,至于P4是OpenFlow 2.0的说法也是非常不严谨的(BTW,P4-runtime成为OpenFlow 2.0还倒是真的有点可能)。做为参考资料,可以看下https://github.com/p4lang/switch/blob/master/p4src/OpenFlow.p4,看OpenFlow和P4这对好基友是怎么一起工作的 :)
谈完了转发平面,再来讨论一下控制平面的事情,OpenFlow是控制器发给交换机的,交换机有了PISA,那Controller呢?从这个架构诞生的第一天起,如何解决Controller的单点故障问题就被一直被质疑。解决单点故障的唯一办法就是把单点变成多点,也就是用多个Controller来代替单一的Controller,那么多个Controller之间数据如何同步?这又是一个老生常谈的分布式系统的问题。
我们知道,分布式系统有CAP原理。

阐述了分布式系统中的一个事实:一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)不能同时保证。三个只能选择两个。很不幸,这是所有分布式系统都具备的特性,并不是OpenFlow-Controller架构独有的“缺陷”!即使是最红的分布式系统区块链技术,也得服从CAP原理。换句话说,没有万能的金丹。那种希望CAP兼得的想法,只能说是疯狂或者幻想(Pure Madness)。
首先来解释一下这个原理。假设有两台Controller A、B,两者之间互相同步保持数据的一致性。现在B由于网络原因不能与A通信(Network Partition),此时某个交换机向A发了Packet-in,A通过计算以后发现需要下发流表。他有两种选择:
- A拒绝下发流表,这样能保证与B的一致性,但是牺牲了可用性,交换机不能在有限的时间内得到确定的响应。
- A正常向Client下发流表,但是这样就不能保证与B的一致性了
由于众所周知的原因,我们面临的网络环境,Network Partition是必然的,网络非常可能出现问题(断线、超时),因此CAP理论一般只能AP或CP,也就是在可用性和一致性里二选一。
- CP: 要实现一致性,则需要一定的一致性算法。
- AP: 要实现可用性,则要有一定的策略决议到底用哪个数据。
在以上的例子里,显然应该首先满足可用性,A控制器应该先下发流表,保证交换机可以正常工作,等到AB之间的网络恢复以后,再设法将这个变化同步给B,使得AB之间达到最终一致性。(Eventually Consistency)。如果这个分布式系统不止AB这两个节点,而是足够复杂,最终一致性可能不是通过简单的同步(Sync)可以完成的,可能需要再多个节点之间通过投票来完成。也就是著名的共识算法(如Paxos和Raft)。区块链技术也高度依赖共识算法,一个基本的认识是,去中心化(Decentralization)需要参与投票的节点足够多,才可以避免有人可以控制51%以上的算力。同理,如果有人抱怨控制器不可靠或者不同步,原因可能仅仅是控制器不够多。如果仅仅有两台数据不一致的控制器,如何确定哪一台的数据是完备的?如果有三台或者更多,可能就会简单一点,让他们去投票就好了,毕竟多台控制器集体发疯的可能性比较小。
因此,为了避免单点故障引入了分布式系统,CAP原理是分布式系统固有的特征,这不是并不是OpenFlow-Controller架构的什么固有缺陷。通过共识算法,达到分布式系统的最终一致性,是完全可以实现的。事实上,主流的SDN-Controller早已实现。可以参考如下的论文https://www.telematica.polito.it/~giaccone/papers/icc16-onos.pdf
话又说回来了,控制器也不是越多越好的,传统的网络里,每台设备都有控制平面,其实就是个控制器无限多的分布式系统。这些控制器之间跑着各种各样五花八门的控制协议,想让他们达成某种共识,几乎是不可能的。传统网络基本上是一个既没有一致性C也没有可用性A的不可控的分布式系统,这个系统的形成有其历史原因,跟互联网一步步从一个个试图互联的孤岛变成无所不在的智能网络的历程有关,目前看,似乎工作的还可以,但是这不是我们固步自封拒绝变化的理由。我们需要更好的互联网,需要更好的一致性和可用性,在传统设备的世界里自娱自乐,不能带来这一切。
综合起来看,OpenFlow的红旗,说得更准确一些,SDN的红旗,恐怕还是要继续打下去了。







