

作者简介:史梦晨,南京邮电大学通达学院 本科,柏林工大/巴黎六大 硕士 现就职于 欧洲高级网络测试中心 研究方向:网络设计,测试: 大规模数据中心,SD-WAN,EVPN,Segment Routing, NFV
前文说到,根据需求1-5,RFC7938提出了只使用eBGP作为数据中心内唯一的路由协议,那么是怎么考虑和实施的呢。

为何选择eBGP作为路由协议
首先为何eBGP一般不被考虑用做数据中心内的纯路由协议呢?主要是由于以下认识或者是原因:
1、eBGP一般是用于广域网域间互联,
2、BGP一般被认为收敛速度比IGP要“慢很多”
3、用环回口建立邻居时还需要借助IGP;iBGP邻居非直连
4、配置BGP的工作量会比较大,而且不能自动发现邻居
那么我们先来看看BGP的好处:
1、BGP协议的设计复杂度要小于IGP: 相比于链路状态路由协议如OSPF,BGP用TCP作为可靠的承载协议,保证了承载数据的可靠性和重传,从而在自身协议中不需要考虑过多的因素,增强自身的可靠性,满足了需求2(选择一个“狭窄”的协议组)和需求3(选择一个“简单”的路由协议)。
2、BGP信息泛洪的overload要少于链路状态协议:BGP本地只传播计算好的最佳路径,当网络中有故障的时候,这些故障被“隐藏”起来,直到新路径被计算出来,尤其是在高度对称的网络比如CLOS。相比于链路状态路由协议对所有的failure都需要在域内通知,这点在需求3和需求4(减小故障域)上要较OSPF等协议优化了很多。同时,链路状态协议因为邻居会超时,需要定期刷新路由协议,而BGP不需要因为邻居不会失效(虽然这些流量相比于如今的设备和流量不值一提)。
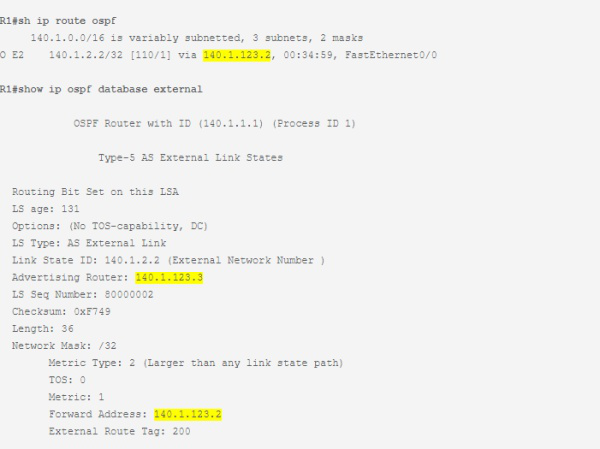
3、BGP支持第三方下一跳(Third-party Next Hop)。作者在一篇博文里面详细解释了原理和用途(原文)。第三方下一跳允许某个路由的下一跳指向一个特定的下一跳IP地址,而不是由源宣告出来的IP地址。这样做的好处就是我们操控和调整基于非ECMP或者是基于需求转发的multipath。这个特性其实RIP,EIGRP,OSPF和ISIS都以不同的形式支持。eBGP的next-hop-self的行为就是第三方下一跳,满足了需求5(流量工程TE)(下一跳和宣告出口在同一网段不改变下一跳的行为这里不展开讨论了)。OSPF通过Forwarding Address功能也可以做到但是实施比较复杂并且难以控制传播范围(图1)。下一次,我们将再次谈论。
4、用良好设计的ASN和as_path的环路检测能控制BGP path hunting(由于消息传播时间,间隔和withdraw消息造成的路由检测振荡),并且忽略不想要的路径。
5、EBGP更容易进行网络可达性的troubleshooting。在大多数实施中,我们可以通过BGP loc-RIB,路由器的RIB,BGP的邻居Adj-RIB-In和Adj-RIB-Out,NLRI来进行排错,同时满足了需求3(选择一个“简单”的路由协议)。
在CLOS架构中,上次我们也提到了3阶CLOS和5阶CLOS(从服务器到服务器经过的交换机为3个或者5个),之后以5阶CLOS为例,我们可以参考以下eBGP设计原则:
1、所有的eBGP session都使用直连接口,不使用多跳或者loopback建立session
2、使用私有的ASN(64512-65534)
3、所有的Tier 1使用一个ASN
4、每一组Tier 2设备使用一个不重复的ASN
5、每一个Tier 3(比如TOR)使用一个ASN
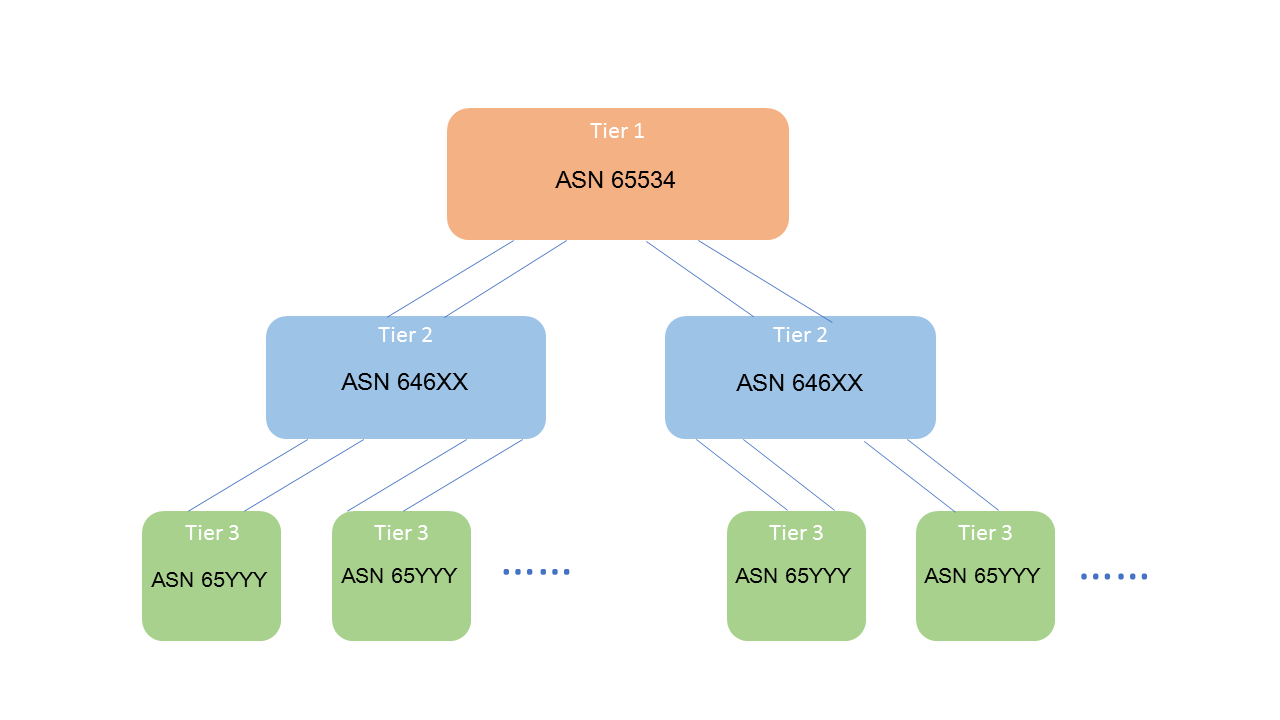
- 在Tier 3重用ASN
我们可以选择比如65001到65032作为固定的Tier 3的ASN并在不同的Cluster里。但是传统的AS_Path属性防环(当收到的BGP路由信息中AS-PATH列表中包含自己的AS号,则丢弃该路由)会阻止不同的Cluster互相学习路由。这里一种被广泛支持但没有标准化的功能”Allows-in“可以解决这个问题(override也可以)并且由于设计。这里有Cisco allows-in配置样例。 - 4-Octet ASNs
RFC6793引入了4-Octet ASNs,如果使用此功能,那么目前来看是足够用了(大约9千万个私有ASN),但是如果采用这种技术,需要考虑到需求3和需求4,我们又引入了一种feature,那么硬件采购收到限制,同时我们还需要考虑在出口移除私有ASN号(在外部连接中会介绍)。
路由通告
由于此设计中会有大量的点到点的直连链路被使用,宣告这些链路也许会造成FIB的overload,并且会对路由计算带来很大压力。关于此点作者提出了2个解决方案:
1、不宣告链路地址到BGP。由于eBGP的设计会在每台设备上更改下一跳地址,终端地址可以被访问而不需要这里链路地址在每台设备里都可达。这个方案带来的问题就是运维和监控会更复杂些,比如我们使用traceroute的时候会显示这些链路地址不可达。
2、宣告链路地址,并且在每台设备上进行路由汇总。这个方案就需要我们对地址进行规划,使用连续的可汇总的地址段作为链路地址。
服务器的网段当然是必须被宣告的,并且在tier 1和tier 2上都不汇总。因为在BGP中汇总路由会在单链路failure的时候造成路由黑洞。
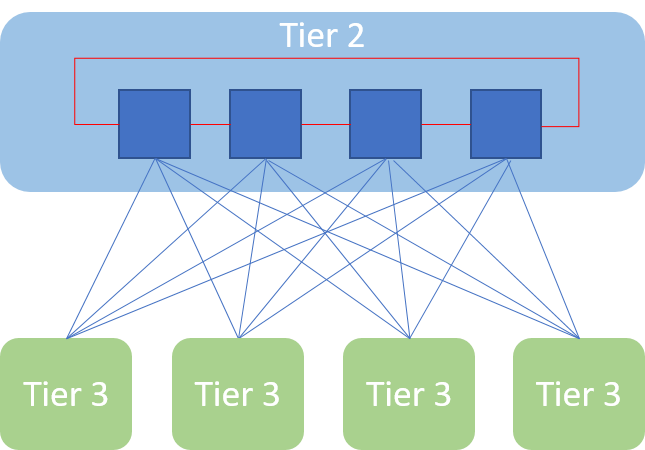
我们都知道,iBGP可以通过全互连,RR或者团体属性来解决由路由汇总造成的黑洞。但是原本的CLOS架构中,在同一个Tier之间的设备是没有互联peer link的,那么我们要解决这个问题就必须引入peer-mesh links来防止路由黑洞,但是由于浪费端口和复杂度,作者不推荐此做法。有一种折中的解决方案就是简化连接,比如4台tier 2设备成环形连接,但是这样的拓扑无疑增加的额外的跳数和被限制的带宽,并且有可能要调整BGP的设计。
外部连接
在这个设计中,一个或者多个cluster会被用来与WAN相连,在这个cluster里,tier 3的设备一般是WAN路由器。如果是通过互联网连接到广域网,一般来说tier 3设备会被划分到对应的广域网ASN里。Tier 2的设备一般被称为边界路由器(Boarder Routers),提供以下功能:
- 隐藏内部网络拓扑信息:在BR上移除私有ASN。这样可以防止ASN冲突,并且提供同样长度的AS_PATH用于广域网的ECMP和Anycast prefix。这里需要的feature是remove private as,一般也是被广泛支持的。
- 生成默认路由。这也是整个设计中唯一生成默认路由的地方。因为之前也说过,汇总路由会造成路由黑洞。在此设计中,推荐所有的BR都需要和WAN Router全互连,同时推荐使用重分布BR学到的默认路由进入数据中心。
边界路由汇总
路由汇总无疑是有好处的,尤其是大规模数据中心,如果有2000台tier 3设备就意味着2000个subnets加上设备上和之间的prefixs。但是如同之前所讨论的,汇总路由造成的路由黑洞也是我们所要避免的。在BR生成默认路由之前也说了,这里给出了2种方案:
1、BR之间起peer link, 可以使用全互联或者是上面图示的ring或者是hub-spoke的连接并使用iBGP mesh交换路由信息
2、在tier 1和BR之间增加保护链路,也就是每个tier 1和至少2个BR相连。按照我的理解,由于BR Cluster的特殊性和唯一性,并且是router,并不是每个tier 1设备都需要和BR连接的。这里因为需要提供保护链路,也就提高的端口的需求,同时意味着tier 1和其他普通的tier 2设备连接就减少了。
只要使用了以上任意一种方案,就可以在边界进行汇总路由而不造成路由黑洞。最后,我们来用一张图汇总一下这里的设计方案。
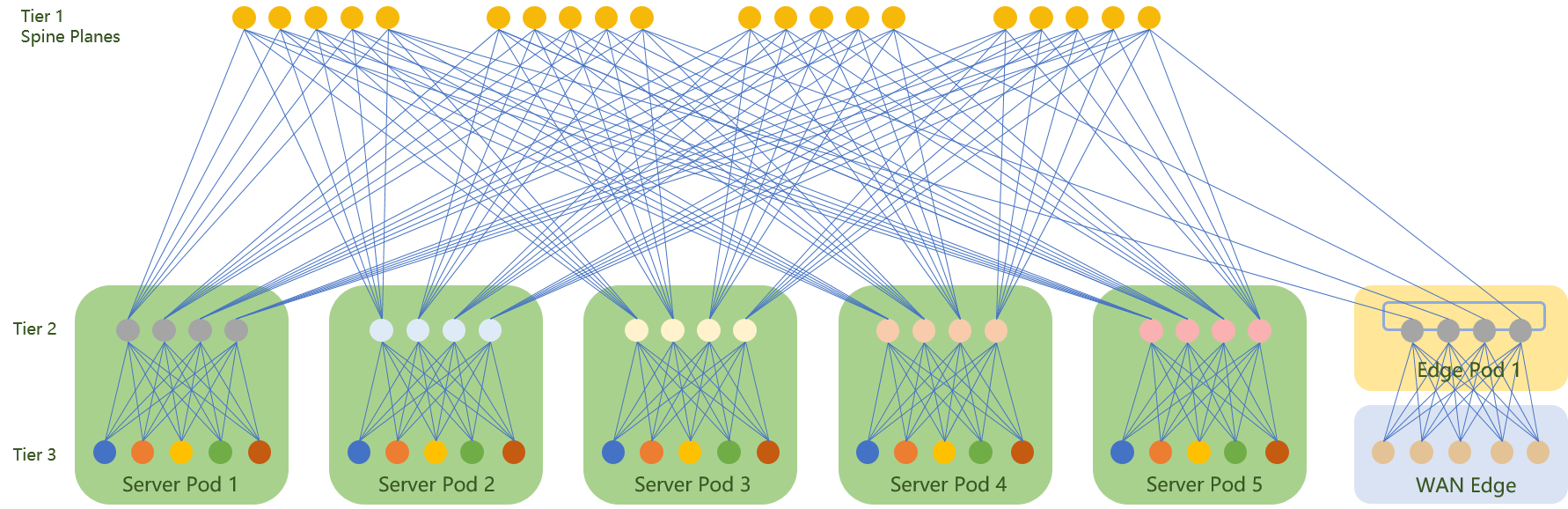
在上面的部分中,我们已经研究过:
- 为什么选择bgp
- 如何设计ASN
- 如何通告路由条目以及在何处进行边界汇总
下一次,我们将讨论:
- ECMP
- 路由收敛属性
- 对于设计的额外选项








