

编者按:本文系SDN实战团技术分享系列,我们希望通过SDNLAB提供的平台传播知识,传递价值,欢迎加入我们的行列。
--------------------------------------------------------------------------------------------------
分享嘉宾:张晨,北京邮电大学网络与交换国家重点实验室,工程硕士。研究方向:软件定义网络,网络虚拟化,云数据中心网络。
--------------------------------------------------------------------------------------------------
SDN的出现给了网络界一针强有力的“兴奋剂”,释放了网络界压抑已久的创新的能量。这一波技术思潮催生了大量的SDN创业公司,对各大厂商发起了巨大的冲击,网络领域的生态链可能面临着彻底的重构。2012-2015年,SDN创业的主战场是数据中心虚拟化,2015年已经开始转向广域网专线。数据中心SDN第一阶段的拼杀基本已经结束了,经过市场的整合,大部分startup都投入了大厂商的怀抱,只剩下少数的几家仍然在市场上独立打拼着,随着Plumgrid在2016年底被Vmware收购,控制器这块主要就剩下了BigSwitch和Midolkura,还有一些和厂商完全不对路数的白盒选手,我们这节先来看看BigSwitch。
BigSwitch可以说是根正苗红的SDN玩家,公司从2010年成立,公司的主要创始人有很多都是从Clean State项目组出身的,包括Guido Appenzeller和Rob Sherwood,和Martin Cassado属于同一拨选手。几人都是OpenFlow的骨灰级玩家,不过BigSwitch和Nicira走的路线却有着很大的差异,BigSwitch用OpenFlow做的是Underlay,数据平面上搞得是白盒的OS,而Nicira用OpenFlow做的是Overlay,数据平面上搞的是Hypervisor上的vswitch。两者相比较而言,Bigswitch的理念是纯OpenFlow来做数据中心,偏向于狭义范畴的SDN,而Nicira走的理念则更接地气一点,Overlay一提出来对了很多人的胃口。随着Vmware的天价收购,Nicira成为了SDN界最知名的大明星,而BigSwitch至今仍然独立地存在着。
BigSwitch为OpenFlow贡献了非常多的知名的开源项目,控制器有FloodLight,协议编译工具Loxigen,虚拟化中间件FlowVisor,交换机代理Indigo,以及测试工具OFLOPS等等,这些开源项目(尤其是Floodlight)奠定了BigSwitch在开源SDN生态圈中的重要地位。OpenDaylight在成立之初,BigSwitch作为白金会员希望把自己的控制器代码作为OpenDaylight控制器的核心,不过社区最后采纳了将BigSwitch和Cisco One控制器进行融合的方案,以提供对OpenFlow在内的多种南向协议的支持。“提供多种南向协议的支持”听起来很美好,背后实际上是Cisco对当时火热的OpenFlow的围剿,眼看着社区ODL社区与OpenFlow背道而驰,BigSwitch在社区仅成立两个月后就立即选择了退出。不过,在Cisco的强大号召下,OpenDaylight还是建立起了广泛的生态,一定程度上可以说是成功地给OpenFlow降了温。
市场策略上,BigSwitch把基于Indigo的交换机操作系统Switch Light也贡献了出来,并和Accton等ODM厂商共同推广OpenFlow交换机。这种交换机出厂时没有操作系统,启动会自动到BigSwitch控制器上去下载Switch Light,BigSwitch将自己的这种模式定义为“BriteBox”。“Brite”是“Brand-White”的缩写,BigSwitch的商业逻辑是通过自己的开源交换机OS来捆绑白盒,从而销售自己的OpenFlow控制器。
(一)体系架构
BigSwitch产品的体系架构就是典型的控制器+OpenFlow交换机。限于OpenFlow的应用场景,BigSwitch的产品是专门为数据中心所设计的,其方案分为两套:Big Cloud Fabric(BCF)和Big Monitoring Fabric(BMF)。BCF用于网络自动化,BMF用于DMZ与网络可视化。
要理解BigSwitch产品的体系架构,更好的办法就是直接从公司的名字入手,即将基于白盒设备的Fabric抽象成一台“大的交换机”,通过OpenFlow对其进行集中式的单点控制。从反向的角度还可以理解为,将网络中昂贵的机箱式的大盒子换成多个便宜的白盒设备,以获得较低的拥有成本以及更好的可扩展性。如下图所示,无论是BCF还是BMF,都贯彻着这一思想。
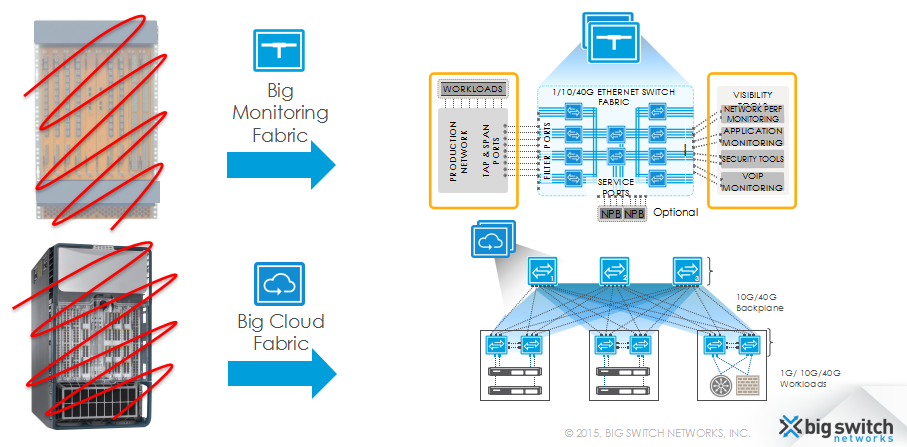
(二)控制平面
这一节我们将对BCF和BMF分开进行介绍。BCF和BMF都分为两个版本,BCF的P版本用于Vmware环境,P+V版本用于OpenStack环境,BMF的Out-of-Band版本用于带外流量分析,Inline版本用于DMZ。
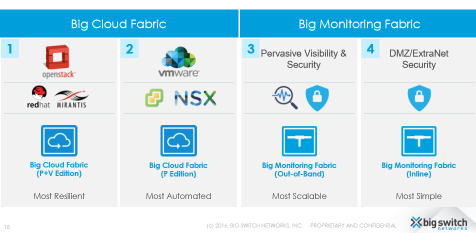
1.BCF
BCF的设计是要将传统的Chassis Switch结构和功能“移植”到Leaf-Spine架构中,其中Leaf相当于线卡,Spine相当于背板,而Controller则相当于控制引擎。那么BCF要实现的主要有以下几点:Chassis Switch的线卡是即插即用的,因此Leaf和Spine需要支持零配置(ZTP,Zero Touch Fabric);Chassis线卡上的能够支持L2、L3的转发,因此Leaf上需要实现分布式路由;Chassis内背板上的转发不需要复杂的L2、L3协议,因此Controller需要通过OpenFlow直接控制Underlay Fabric上的转发而非通过隧道Overlay在IGP/BGP上;Chassis Switch的控制引擎通常都是冗余的,并且是单点管理的,因此Controller需要实现集群形成一个物理上分布、逻辑上统一的控制器;Chassis Switch即使双引擎全部失效了,也有GR、NSF等机制来保证数据平面的正常转发,因此Controller集群都挂后数据平面也不能够失效;Chassis Switch背板也是冗余的,因此Fabric中的交换机、链路、路由都应该是互为备份的。
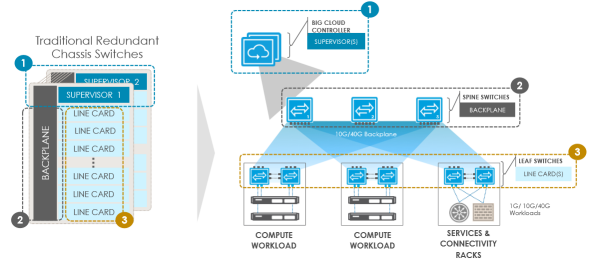
可以看到,相比于其它数据中心SDN方案,BCF最大的特点就在于它使用OpenFlow来代替IGP/BGP来运行Underlay,支持在不使用VxLAN封装的情况下实现虚拟化。其优点在于节约了IGP/BGP的运维成本,不需要分别购买Overlay的Underlay的控制逻辑。不过,BCF需要将Leaf-Spine都替换成OpenFlow白盒,这样一来难以复用现有的设备,而且目前来看使用OpenFlow做Underlay的思路还没有被业界所普遍接受。不过作为OpenFlow的发源地,北美的市场上还是有一些客户愿意对此进行尝试的,包括Verizon这样的Tier-1运营商。
想用OpenFlow来搞Underlay,不可避免地要回答两个问题:1. TCAM不够用怎么办?2. 触发式的逻辑对控制器的冲击怎么解决?BCF给出的答案是:1. OpenFlow虽然对Flow-based Forwarding有很好的的支持,但是不是只能基于流进行转发,OpenFlow本质上只是一个更灵活的FIB RPC而已。对于普通的L2、L3流量,交换机本地把OpenFlow流表转化成CAM和LPM就行了,现有的芯片里面CAM表项轻松上100K,LPM可能少一些不过也要比ACL多多了。需要用Flow-based的时候再用,比如一些安全、服务链策略,不过这种策略通常是不会很多的。2. 同理,OpenFlow只是提供了对PacketIn的支持而已,Flowmod的逻辑是没必要非得和PacketIn绑定在一起的。如果把触发式转为预置式,那么和传统网络中控制引擎提前学好路由表,再同步到线卡里面去是没有区别的。如果一上线就打流量,传统设备达到线速转发也是要有一个收敛时间的,这是无法避免的。另外,BigSwitch对OpenFlow的理解也不是完全狭义的“数据平面没有任何控制逻辑”,一些需要触发的行为可以通过卸载到交换机上去完成,这可以进一步减少PacketIn对控制器的冲击。后面讲数据平面时会有一个图,上图给出了一些需要卸载的典型功能,如DHCP、ARP等等。
思路谈完了,开始讲具体的设计。下图是BCF的业务网络模型,租户表示为Tenant,一个Tenant可以有多个Segment,每个Segment通常对应于一个VLAN,同一个Tenant下的不同VLAN之间通过Logical Router进行通信,不同的Tenant间通过System Logical Router进行通信,System Logical Router逻辑上与出口路由器进行双上联,以对接非虚拟化环境。
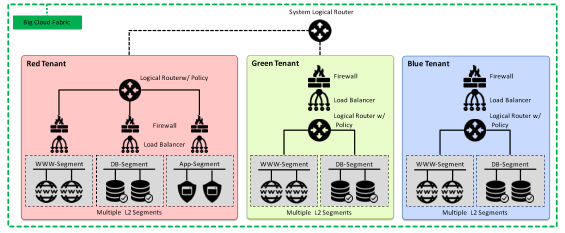
BCF分为P+V版本和P版本。其中,P+V版本是为了OpenStack设计的,除了白盒以外,BigSwitch还提供了自己的虚拟交换机IVS(也是基于开源的Indigo的),由于不使用VxLAN,因此BCF能够方便地提供Overlay+Underlay的一体化控制,包括虚拟机定位、路径追踪等等。
下图是P+V版本中的转发逻辑示意图。可以看到其转发表并不复杂,本地转发的就直接走目的所在的Port,远端的就通过Group选一个下一跳发出去。这些转发表都是BCF控制器通过OpenFlow流表预置的,DHCP、ARP、ICMP以及NAT/PAT都是卸载到交换机本地完成的,不需要通过PacketIn上送控制器,以避免流量对控制器的冲击。
对于L3流量,采用的是任播+分布式路由的做法,各个Segment中的.1地址即为对应的Logical Router接口,这些Logical Router Interface都使用相同的MAC地址,Logical Router分布在流量接入的vSwitch/Leaf上,识别出L3流量就在直接完成MAC地址的改写并对TTL减1,然后在目的的Segment中进行转发。如果是跨租户的Inter-Tenant L3或者Internet流量,还需要额外在System Router上进行一次路由,为了方便一些安全策略的实现,System Router的转发逻辑被分布在了Spine中。

当然,控制器能够完成上述逻辑的前提是能够得知物理网络的拓扑以及虚拟机、裸机的位置。物理网络拓扑,需要在控制器上事先通过交换机的MAC地址来定义其拓扑角色(vSwitch、Leaf或者Spine),LLDP和LACP被卸载到交换机本地以探测交换机间的连接,以及裸机/虚拟机与交换机间的Bond连接。虚拟机的位置,vSwitch可以通过监听vNIC的plug动作来上报,裸机的位置就只能通过事先定义或者通过与OpenStack的接口来获取了。
P版本主要是用于与Vmware NSX的对接。在最开始的几个版本,BCF不提供对于VxLAN的支持,因此只能作为单纯的Underlay SDN方案,无法作为HWVTEP将裸机接入NSX环境。DHCP、ARP是由NSX来负责的,拓扑和Bond的发现是通过LLDP/CDP来完成的,BCF为VTEP间的通信提供Transport VLAN的自动化配置,VxLAN的封装与解封装都是由VDS来完成的。不过,虽然BCF不参加VxLAN的控制过程,但是可以通过vCenter间接地从NSX处得到虚拟机与VTEP的对应关系,做一些整合后即将虚拟机和Underlay的位置关系显示出来。对于路径的追踪,由于Underlay不具备VxLAN的能力,就只能提供好目标流量所对应的外层包头信息,包括源VTEP IP、目的VTEP IP和源端口号(由内层包头的五元组哈希得到,可以标识内层流量)与目的端口号,因此这是一种这种比较初级的路径追踪方案。
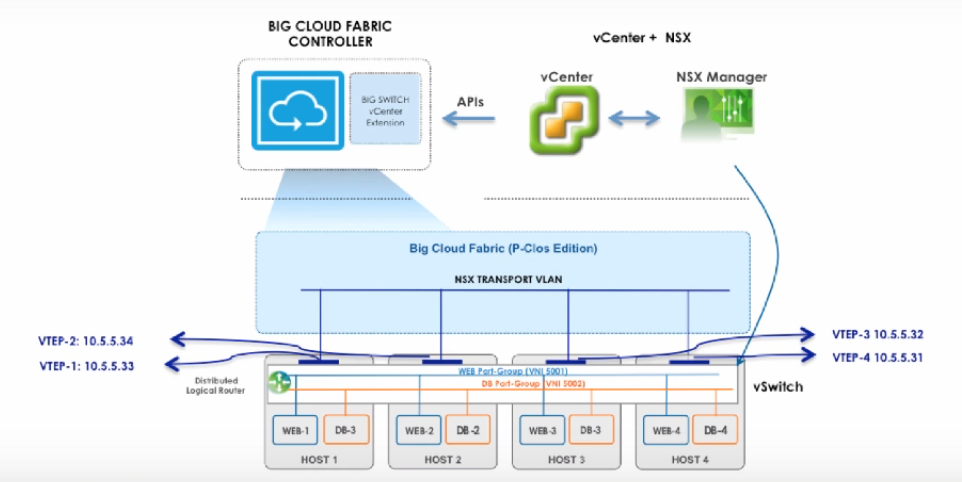
2016年后,BCF开始在P版本中添加对VxLAN的支持,以提供对裸机接入NSX环境。其原理也很简单,就是在BCF Controller上使能VxLAN,然后配置好HWVTEP上Segment VNI到Port、VLAN的映射关系,然后BCF Controller和NSX直接通过OVSDB进行通信交互MAC与VTEP的映射关系,然后再向HWVTEP同步转发表,裸机发送的ARP也由HWVTEP来代理完成。实际上对于NSX来说,BCF Controller就是HWVTEP,BCF Controller可以看做是NSX和HWVTEP间的中继。BCF有了对VxLAN进行处理的能力以后,路径的追踪就可以直接通过内层流量特征来完成了,而不用再提供外层包头。

回头再来说说VLAN和VxLAN的事情。Broadcom Trident 2早在2012年就支持了VxLAN,为什么BCF最开始没有选择对VxLAN进行支持呢?笔者猜测的原因有两点:一是VxLAN封装后把内层报文隐藏了起来,Leaf和Spine上的一些转发逻辑写起来比较困难;二是Trident 2不支持VxLAN Routing,BigSwitch并不具备改芯片的能力,使用了Trident 2的话是没有办法在硬件上打通L3流量的。随着Trident 2+(支持VxLAN Routing)在2015年的上市,BCF也开始提供了对VxLAN的支持,不过VxLAN对于BCF来说主要还是用在P版本中,来作为NSX HWVTEP接入裸机的。不过前面说过,VxLAN这种Overlay思路是和BCF的思路有冲突的,因此在对接OpenStack的P+V版本中,BCF可控的环节多了,就仍然使用VLAN来做Fabric了。
当然,使用VLAN做Fabric就面临4K不够用的问题,解决这个问题的做法有两个。一个是VLAN Rewrite,将本地和Port绑定的Local VLAN和传输用的Segment VLAN进行一次映射,虽然转化后还是只有4K,不过这是可以解决一定的问题,因为一些租户可以只放在一个vSwitch/Leaf下,不用占用全局的Segment VLAN。不过这是治标不治本的。另一个就是QinQ,也就是VLAN Stack,一个VLAN不够用就再嵌套一个VLAN,QinQ结合VLAN Rewrite,理论上也是可以支持到16million的租户的。
不过不论是Vmware还是OpenStack,基本上都是用在私有云里面的,4K通常来看都是够用的。而且像BCF这种Overlay和Underlay都需要由控制器来控制的方案,规模也是不会做的太大的。因此BCF在销售策略上是以POD为规模在卖,客观上讲是算不得大二层了,当然了传统的Chassis也就是在POD内部用一用。目前来看,想要二层上规模,主流上还是得用VxLAN来搞。
2.BMF
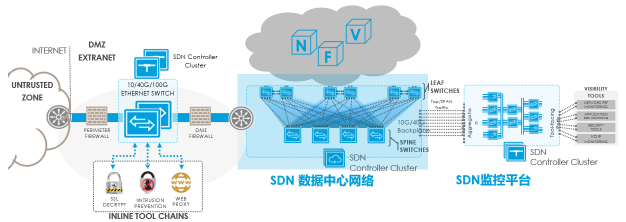
BMF(最初称为Big Tap)是BigSwitch最早开始推的产品,分为两个版本,Out-of-Band版本用于带外监测,Inline版本用于DMZ。下图中蓝色部分为BCF,BCF左侧的为Inline BMF,实现DC入口处的流量安全,BCF右侧为Out-of-Band BMF,实现BCF(或者其它生产网络)的流量可视化。
下图是 Out-of-Band BMF的示意图。一些OpenFlow白盒组成一个Monitoring Fabric,两侧分别连接生产网络和第三方的网络可视化软件,BMF Controller通过OpenFlow对生产网络产生的Tap/SPAN流量部署一些策略,如过滤、聚合、分流等等,然后再有针对性地转发给网络可视化软件,以提高网络可视化软件的处理效率。实际上,这些功能传统的NPB(Network Packet Broker)就可以实现,不过传统NPB都是一些专用的Chassis,这些Chassis虽然功能和性能强大,但是价格昂贵而且可扩展性较差。BMF Out-of-Band的思路就是通过OpenFlow Fabric来替换掉Chassis,通过Controller的灵活控制来实现类似的NPB功能,优点是可以降低成本、提高可扩展性、以及能够开放出来一些监控策略的API,这与BCF的设计思路是基本一致的。
不过,由于OpenFlow交换机的NPB功能相比于专用的Chassis还是有限的,比如一些去重、加时间戳、分片等,因此BigSwitch还为BMF提供了可选的的Service Node,以实现这些“OpenFlow Beyond”的NPB功能。另外,如果策略想匹配一些隧道包的内层特征的话,标准的OpenFlow也是无法提供支持的。BMF通过对OpenFlow进行扩展了解决了这一问题,思路就是匹配时不指定字段名称了,而是通过Anchor+OffSet的方式来自定义报文解析与匹配。该技术被称为DPM(Deep Packet Matching),和POF中的相关机制是类似的,不过DPM是收到长度的限制的。
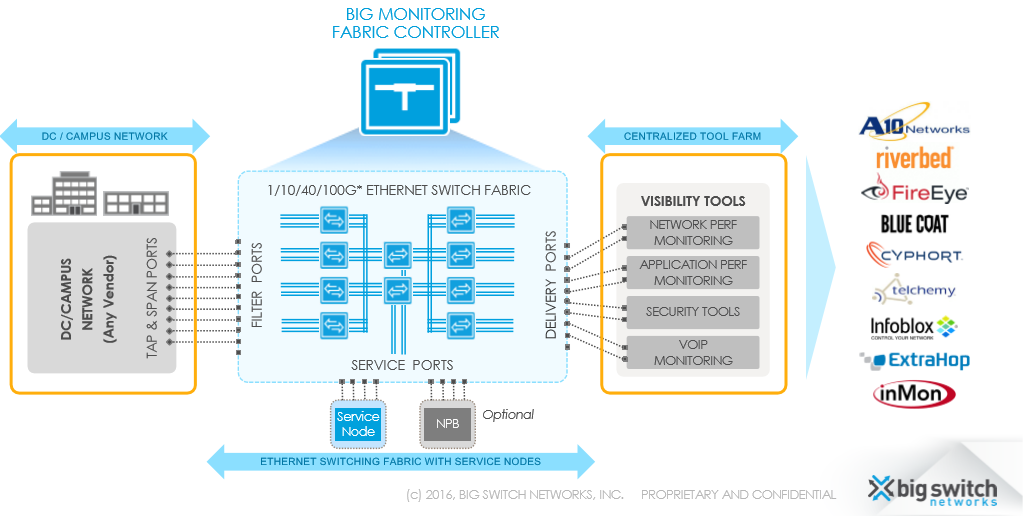
该方案中OpenFlow交换机的端口分为几种不同的角色。连接生产网络的TAP/SPAN流量的端口称为filter interface,连接网络可视化软件的端口称为delivery interface, Fabric内部互联的端口称为core interface。Service Node通常通过两个端口来接入Fabric,pre-service interface用于从Fabric接收流量,post-service interface用于处理完流量后重新注入Fabric。
Out-of-Band BMF实际上就是通过OpenFlow来Match特定的流量(如12元组),然后通过Drop、Output、Group等Action在不同的interface间执行过滤、引流、聚合等策略。当前,这个的前提是首先在BMF Controller上实现定义好交换机端口的角色,以及Fabric的拓扑。这个的控制逻辑也没有什么特定的模式,完全是根据监控的策略来实现的,这里就不再细谈了。
既然是用OpenFlow做策略的,那么又有两个问题了:1. 两个优先级相同的策略,发生冲突了怎么办?2. 策略要是细一点,只能用TCAM来做了,那如果策略多了TCAM不够用怎么办?这两个问题实际上非常偏学术,在工程上只能给一些简单的处理,BMF的做法是:1. BMF Controller对新下发的策略和老的策略进行比较,发现发生了冲突的话,就尽量把Match和Action合并进一条流表。2. 对流表做优化,主要是对含有inport和ip_prefix的流表进行适当的聚合。当然,无论如何处理,这都必将会以损失一定的策略精度为代价。
除了部署监控策略以外,BMF Controller本身也提供了一些数据的可视化,比如主机追踪,子网追踪,TAP分析,sFlow数据采集,SNMP监测等等。不过,更为精细的可视化就只能通过引流到第三方专业的网络可视化软件了完成了。
Inline BMF主要面向的场景是在DMZ区域部署服务链,以实现DC入口处的流量策略。与Out-of-Band需要额外TAP/SPAN把流量引到带外不同,Inline直接将OpenFlow交换机串在外网和DC入口设备之间,通过BMF Controller识别某些流量并执行服务链的引流,当然这台OpenFlow交换机也把流量SPAN到BMF Out-of-Band上去,进行更进一步的分析与审计。Inline BMF实际上和Out-of-Band BMF是一套软件,技术上还是那些东西,由于Inline BMF通常只涉及一两台交换机,其策略的实现还要比Out-of-Band BMF简单一些,这里就不再赘述了。

(四)数据平面
前面提到过,BigSwitch的商业逻辑是为ODM提供自己的开源交换机OS来捆绑白盒,从而到达销售自己OpenFlow控制器的目的。BigSwitch开源出来的交换机OS叫做Switch Light,简单地说可以把Switch Light理解成是“OpenSource Linux with OpenFlow Agent”。下图是对Switch Light结构的介绍,我们将分别来看看图中各个颜色的部分。

蓝色的是OpenSource Linux,当然这个Linux的Distribution并不是我们日常用的Ubuntu,而是基于开源网络操作系统ONL(Open Network Linux)。ONL是专门为bare-metal switch设计的操作系统,它提供了很多开源的、标准化的网络OS模块,如用于对设备的监控的SNMP,用于交换机自动化配置的ZTN Loader,用于记录日志的Syslog等等,还包括一些交换机外设(如风扇和LED)的驱动。ONL希望在硬件和交换机的网络程序间提供一个通用的平台,其代码是完全开源的,ONL在2015年被OCP(Open Compute Project)采纳为了标准的开源交换机网络操作系统。Baremetal switch只要是支持ONIE(Open Network Install Environment)就可以自动下载ONL Image。
当然ONL只是一个通用的OS,Switch OS厂商需要基于ONL来提供他们自己的OS,如Pic8、Cumulus、Pluribus等等。Switch Light是BigSwitch提供的基于ONL的OS,其定制化的内容就在于Indigo,即为本小节第一张图中橙红色的部分。Indigo是BigSwitch开源出来的一个OpenFlow Agent,下图是其Indigo_v2内部模块的简单示意。Indigo北向是OpenFlow控制器(图中为BigSwitch开源的FloodLight),LoxiGen(同为BigSwitch开源)为其提供OpenFlow 协议的编码。南向是转发通道的SDK。如果是转发是ASIC,那么Switch Light经过包装后就变成了白盒交换机,如果转发是Linux Kernel,那么Switch Light包装后就是虚拟交换机IVS(同为BigSwitch开源)。
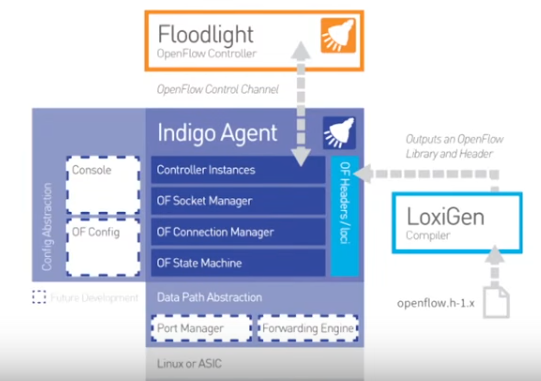
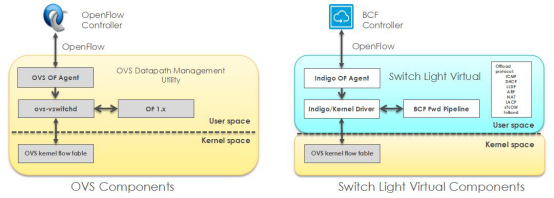
Switch Light不是OpenFlow传统意义上的“Thin Agent”,Switch Light在Indigo之外还增加了很多本地功能,如DHCP、ARP、LLDP、LACP、ICMP等等,能够有效地防止这些流量对Controller的冲击,以增强Controller的可靠性。下图示意了IVS相比于标准的OpenvSwitch增加的部分功能。
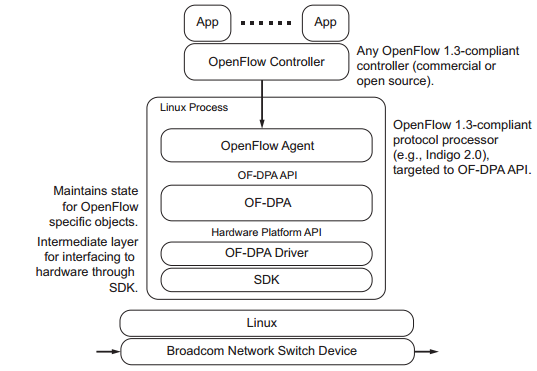
本小节的第一幅图中,紫色和深蓝色的部分是不开源的。深蓝色的是ASIC,目前能够支持OpenFlow的主流ASIC为Broadcom的Trident II和Tomahawk。Trident II和Tomahawk都是通过传统的转发表来模拟OpenFlow流表的行为的,Broadcom开放了OF-DPA作为Trident II和Tomahawk的SDK,以方便OpenFlow Agent对芯片进行操作。实际上把OF-DPA说成是ASIC SDK并不是十分准确,因为出于保密Broadcom在ASIC和OF-DPA中间还另外作了一层抽象,因此OF-DPA准确地说应该是“SDK of ASIC SDK”。Indigo的ASIC Driver(本小节第一幅图中的紫色部分)是没有开源出来的。
由于BigSwitch的重点放在了控制器上,因此BigSwitch没有选择自己做盒子,而是通过与ODM(如Accton、Quanta等)合作来建立控制器的生态。BigSwitch为ODM提供交换机的OS,ODM来做盒子的整体集成与包装。BigSwitch自己倒是基于x86为BMF作了Service Node,用于弥补OpenFlow实现NPB功能上的不足。
上述就是对BigSwitch的介绍了。作为SDN骨灰级的创业公司,BigSwitch一直在坚持OpenFlow+白盒的的路线,虽然BigSwitch在生态方面做出了巨大的努力,但是由于众多因素OpenFlow目前的进展并没有完全符合预期。不过BigSwitch在产品上也瞄的比较准,尤其对Monitoring Fabric和DMZ这块,可以算是OpenFlow在数据中心的杀手级应用了。目前来看,BigSwitch在北美还是争取到了一些大客户,融资情况也不错,C轮目前已经拿到了4850万美元。BigSwitch对OpenFlow最初所设想的SDN路线的长期坚持,且不谈未来究竟前景如何,这种对执着的技术追求,可以说在鱼龙混杂的SDN创业圈子里是一股清流。不过,元老级的CTO Rob Sherwood在2016年底出走Facebook,不知道未来BigSwitch的技术路线能否继续坚持下去。如果将来有一天BigSwitch也被收购了,那么OpenFlow颠覆传统网络的梦想可能也就该画上句号了。
Q&A
Q1:Big switch大量使用了offload的技术,将控制器的packet-in的功能下放的switch上,对吗?switch上是asic,还是cpu来做呢?
A1:多数是cpu,少部分有芯片级的
Q2:交换机卸载功能的细节
A2:据我目前找到的资料,bigswitch卸载的都是控制面的功能,nat这块现在支持PAT
Q3:路径追踪主要有什么用途?
A3:overlay+underlay一体化运维
Q4:PAT是有状态的还是无状态的?
A4:据说是有状态
Q5:还有刚才讲到bigswitch控制器搭配白盒子用,而且不同的版本对应不同的应用场景,想请教下启动后白盒子是怎么知道该去下哪种应用类型的哪个版本呢?
A5:dhcp option,不知道是不是这样的,42+66+67,这块应该是ONIE的东西,有专门的规范
Q6:二层链路检测用的什么机制?
A6:LLDP/CDP
Q7:这个检测时长有多长呢?
A7:这个确切的不知道了,不过没关系,都是卸载到数据平面的,不是从控制器出来的
Q8:流表还是Openflow的形式,控制面可以是其他协议?
A8:个人理解openflow本质上只是”有能力对流进行编程的协议”,bigswitch的说法是类似于"FIB RPC"。除了转控分离以外,openflow不一定是只针对流,不一定要reactive,不一定控制器挂了网络就瘫了,也不一定是集中式控制。如果提到流表了,控制面基本就是openflow
--------------------------------------------------------------------------
SDN实战团微信群由Brocade中国区CTO张宇峰领衔组织创立,携手SDN Lab以及海内外SDN/NFV/云计算产学研生态系统相关领域实战技术牛,每周都会组织定向的技术及业界动态分享,欢迎感兴趣的同学加微信:eigenswing,进群参与,您有想听的话题可以给我们留言。








