

一、前言
为深入研究P4语言相关规范及运行操作使用,本系列文章根据P4.org网站给出的《The P4 Language Specification v1.0.2》[1]内容,并通过我们的运行使用的具体实例和分析汇总,希望能为大家研究P4提供一点参考。 作为大二和大三的本科生,水平和经验有限,感谢SDNLAB提供平台,希望能和大家相互学习交流。
本系列文章分为三个部分,系列一 翻译和阐述 P4.org网站给出的《The P4 Language Specification v1.0.2》的第二部分首部及字段;系列二是翻译和阐述《The P4 Language Specification v1.0.2》的第三部分解析器;系列三是基于Github开源项目p4factory中的P4项目源码分析。
二、首部类型声明
首部类型(Header types)描述了字段(fields)的结构(layout),同时也提供了用于索引的名称信息(相当于引用字段的指针),即References。
首部类型 用于声明两种首部实例:包头实例(header instances) 和 元数据实例(Metadata instances),将在下节进行讨论。

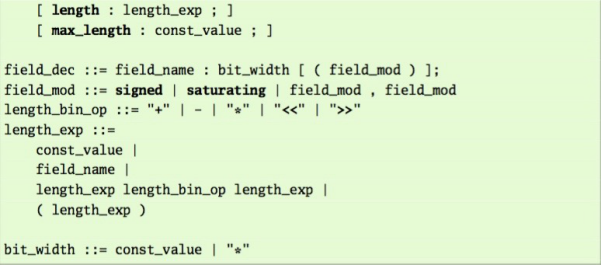
首部类型的BNF(巴科斯范式)如下:
首部类型的定义遵循如下规则:
(1)首部类型必须有一个字段域属性(fields attribute):
1.要求有一个个体字段的列表。
2.字段默认是无符号的,以及具有非饱和性(non-saturating)。(原文注:对该属性列表的添加或者删除操作导致的上溢或者下溢情况,会调用wrap函数来解决。)
3.首部的初始部分,字段域的偏移字节取决于字段域的所有字段宽度之和。
4.字节里的比特是根据重要意义排序的,因此,如果首部定义的字段域中,第一个字段的宽度为1比特,那么它就是该首部定义的第一个字节中的具有特殊意义的比特。
5.首部中的所有比特都会被分配给其对应的字段。
6.在首部类型定义中,一个字段域最多只能有一个字段的宽度是用“ * ”标识的,即该字段的宽度可变。
(2)固定长度(定长)首部 以及 可变长度(不定长)首部
如果所有字段的宽度都定义为固定的值(或者说,没有一个字段的宽度被声明为“ * ”),那么则称这个首部是定长的(fixed length);否则称这个首部是不定长的(variable length)。
(3)长度属性
长度属性明确说明了一种表达形式,这种表达形式的赋值使得按字节计数的首部长度为不定长形式。
1.如果首部有不定长的字段,那么首部定义必须给出长度属性。
2.如果定长首部声明了长度属性,那么编译器必须给出警告。
3.不定长的字段必须声明于字段域的最后。
(4)长度上限属性
对于不定长的首部而言,长度上限属性指明了按字节计数的首部长度上限。
1.运行时,如果计算的首部总长超过了该属性值,那么作为解析异常(parser exception)处理。
2.对于不定长首部而言,允许声明长度上限属性。
3.但是对于定长首部而言,如果给出该属性,那么编译器必须给出警告。
(5)操作符优先级和可结合性
操作符优先级和可结合性语义与C语言语法一致。
不定长字段计算方法:
P4通过对值为“*”的字段的使用,来支持从数据报中解析出不定长的首部实例。该值为“*”的字段的宽度,可以通过由长度属性说明的,按字节计数的首部总长推出。
公式如下:
该字段宽度 = (8 * 总长 - 其它定长字段宽度的总和) (单位:bit)
注意:
字段域中的字段宽度单位是 bit,而首部总长(长度属性)的单位是 bytes。计算特定字段的宽度值的时候,需要进行单位的换算,即 1 byte = 8 bits。
一个VLAN协议的首部类型定义如下:
|
1 2 3 4 5 6 7 8 |
header_type vlan_t { fileds { pcp : 3; cfi : 1; vid : 12; ethertype : 16; } } |
元数据类型是用相同的语义来定义的:
|
1 2 3 4 5 6 7 8 9 10 |
header_type local_metadata_t { fields { cpu_code : 16; port_type : 4; ingress_error : 1; was_mtagged : 1; copy_to_cpu : 1; bad_packet : 1; } } |
首部类型的定义,可以类比C语言中定义一个结构体,header_type 关键字类比 struct 关键字,local_metadata_t 类比结构体的名字,fields 字段域中的字段类比结构体的成员。
在底层的实际处理过程中,P4程序中首部类型的定义在解析的过程中,给解析状态函数(parse state function)提供参考,使其从真实的数据报中解析出对应的首部实例。
三、 包头实例和元数据实例
当P4程序中定义了一种首部的类型,那么映射到底层解析过程,解析状态函数根据首部类型的定义,有可能在数据报中发现大量的首部实例(header instances)。
P4要求每一个首部实例在被引用之前,都应该被明确的定义,即实例化。
有两种首部实例:包头实例和元数据实例。通常而言,数据包在抵达匹配-动作流水线的Ingress过程时,数据包包头信息会被确认;与此同时,元数据 Metadata 携带一些特别的数据包信息,这种信息并不经常在数据包数据字段出现,比如 Ingress端口 和 时间标志。
关于元数据:在处理数据包的时候,大多数元数据只是简单的数据包状态(per-packet state)信息,比如寄存器。但是,有一些元数据会影响交换过程中的操作,比如队列系统(the queuing system)会根据元数据实例中的字段值,为数据包选择合适的队列。P4承认这些具有特定目的和含义的元数据,但是并没有尝试去表示它。
由关键词header定义的包头实例,和由关键词metadata定义的元数据实例,它们之间的区别,仅在于合法性(validity)。(注:后面的章节有提到,区别在于合法性和逆解析过程,应该是两个方面;这里的说法,应该指的是在进入Ingress过程之前)
包头实例会带有特定的独立标记,用于测试其是否合法;而metadata,一般都认为它合法。
元数据实例的字段值,如果没有定义的话,默认初始化为0。
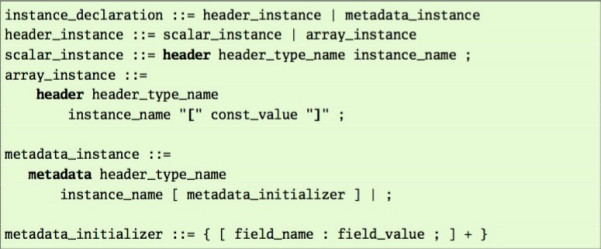
包头实例 和 元数据实例 的BNF如下:
注意:
- 只有包头实例(由关键词header定义)才可能形成数组(arrays)。元数据实例不行。
- 元数据实例一般不会被声明为不定长类型实例。
- 初始化的时候所用到的字段名称,必须能在首部类型定义中的字段域找的到。
- 如果指定了一个初始化容器(initializer),那么在这个容器中,被指定字段就被初始化为指定的值,没有被指定的字段值初始化为0。
- 对于一个包头实例来说,如果它所有的字段总长不是整数倍的单位字节,编译器必须报错。
代码实例:
关于包头实例的定义:
|
1 |
header vlan_t inner_vlan_tag; |
对以上代码的理解,一个是从语言语义的角度来看:关键字 header 就像C语言中定义结构体实例的 struct 关键字,但是在这里是不允许省略的;vlan_t 类比过来就是结构体的名字,那么 inner_vlan_tag 就是结构体实例的名字,如下:
|
1 |
struct stu_name s1; |
这样看,是不是比较亲切一些了呢?
但是,如果仅从语言语义的角度来琢磨代码,不能很好的理解P4程序定义底层数据报处理过程的作用;因此作者认为,理解P4程序,不仅仅要从代码语义的角度出发,更要与底层的真实处理流程联系起来,结合去理解。
这条P4语句,在P4程序中的作用是声明一个 vlan_t 首部类型的实例 inner_vlan_tag ;在底层实际处理这条语句的过程中,指明了要给从数据报中解析出来的,首部类型 vlan_t 的实例 inner_vlan_tag 分配资源,同时 inner_vlan_tag 实例成为解析表示(Parsed Representation,是一系列首部实例的集合,在之后的解析器章节中会提到)的一部分。
该包头实例,有可能在后面的匹配-动作流水线过程中被引用,可能是引用其中的某一个字段,也有可能是直接引用该实例,方法是使用其名字 inner_vlan_tag ,这种做法相当于引用指向这个包头实例的指针,那么如果要引用这个包头实例中的字段,可以通过“.”的方法引用:
|
1 |
inner_vlan_tag.vid |
关于元数据实例的定义:
|
1 |
metadata local_metadata_t local_metadata; |
从语言的角度理解,本质上和包头实例定义没有太大的区别,除了关键字换为metadata,在匹配-动作流水线中被引用的方法等和包头实例对等,元数据实例和包头实例的区别,一般在于接下来介绍的合法性(valid)。
3.1 检验包头实例和元数据实例是否合法
数据包中的首部实例以及其字段域中的成员字段们可能会被检查是否是合法的(valid)(是否有一个确切定义的值),合法性和逆解析过程是仅有的两个区分包头实例和元数据实例的方法。
由关键词header声明的包头实例有以下情况是合法的:
1.在解析过程中被extract函数调用。
2.在match+action过程中被操作(这个操作是 add 或者是 copy)。
如果首部实例合法,在首部实例中的字段也合法。
元数据实例中的字段总是被认作是合法的,因为一般来说它的字段的值是明确定义的。如果要检查元数据实例的合法性,编译器需要生成警告,并且评测的结果应该评价为True。
原因可以通过一个例子来具体说明:假设一个一比特的元数据flag是用来指明一个数据包拥有某些属性的(这是说,比如该数据包是IP包,那么这个元数据flag指明了是版本4还是版本6,也就是说它指明了IP版本号),那么这个值非0的元数据所携带的信息很关键,就得视作合法;倘若这个flag的值为0,那么等同于该flag不合法。
虽然流水线中一个匹配操作可能会检查首部实例(或者字段)是否合法,但是只有合法的首部字段才被允许进行匹配(当字段的值是为精确匹配或者三元匹配而指明的时候)。
相同的,只有合法的首部实例才被允许执行逆解析操作。
3.2 首部实例栈
P4支持首部实例栈的概念,它是一种邻近的,相同类型的首部实例的序列。首部实例栈的声明和C语言中的数组类似,声明的关键字是array_instance。
解析器需要保持某些信息来管理首部实例栈。
四、首部实例 及其字段的引用方法
对于匹配,动作以及流控制标准而言,需要与首部实例还有它们的字段建立索引的关系。首部实例可以通过它们的名字来被引用;对于首部实例栈来说,它在双括号中说明的索引值(index)可以是一个常量,如下BNF:
![]()
为了索引到一个特定的首部字段,使用了下标点符号“.”。关键词 last 相当于首部实例栈中的最大索引值(largest-index),能够利用它来索引得到首部实例栈中的最后一个合法实例。
![]()
比如上文提到的:
|
1 |
inner_vlan_tag.vid |
就是说引用实例 inner_vlan_tag 中的 vid 字段,这种做法和C++中引用类的成员做法一致。
注意:
- 在首部定义的字段域中必须有当前引用的字段;就是说,用于定义 inner_vlan_tag实例的 首部类型vlan_t 的字段域中,必须有一个叫做 vid 的成员字段。
- 对一个字段的引用 和 该字段所属的首部实例(以及 定义的首部类型) 有着密切的关系。允许在不同的首部类型定义中,声明同名的字段。
- 在某个时刻的首部实例,它可能是合法的,也可能是非法的;首部实例可能在匹配-动作过程中进行合法性测试。
- 运行时(run time),对于一个非法首部实例(或者是它的一个非法字段)的引用,编译将会返回一个特殊的未知的值,这个值的含义取决于程序的内容。
五、字段列表
在某些情况下,用P4语言描述出一个字段列表会使处理过程变得更加方便:比如一个哈希函数,它把这个字段列表作为函数的输入;根据这个字段列表来计算检验和(checksum)。
P4语言允许对字段列表的定义,在这个列表中的每一个表项,可以是一个首部实例中的某一字段的索引,可以是一个首部实例(与 按字段域中的字段顺序 列出该实例的所有字段 的效果一致),也可以是一个固定的值。

数据包的包头实例和元数据实例可能会在一个字段列表中被引用。
一个字段列表可能会引用到其他的字段列表。因此,字段列表的名字和首部实例的名字都应处于同一个命名空间下。
P4不支持字段列表的递归调用。
payload 标识符,指明在字段列表中声明的字段 所属位于数据包中的首部实例部分 之后的数据包内容,也包括在数据包中。这样做的目的是为了支持特定的情况,比如计算以太网CRC冗余码,或者是TCP的检验和。
参考文献
[1]《The P4 Language Specification v1.0.2》 http://p4.org
作者简介:
陈翔,福州大学数计学院2015级计算机科学与技术(实验班)本科生 ,对软件定义网络SDN,特别是对P4语言感兴趣。
黄志文,福州大学数计学院2014级计算机科学与技术(实验班)本科生,研究侧重于数据平面可编程化。
汪培侨,福州大学数计学院2014级计算机科学与技术(实验班)本科生,目前针对软件定义网络SDN的P4语言进行研究。








