

编者按:本文系SDN实战团技术分享系列,我们希望通过SDNLAB提供的平台传播知识,传递价值,欢迎加入我们的行列。
分享嘉宾
--------------------------------------------------------------------------------------------------
分享介绍:张晨:目前就读于北京邮电大学FNL实验室,网络与交换国家重点实验室。目前主要研究方向:软件定义网络,网络虚拟化,云数据中心网络。
--------------------------------------------------------------------------------------------------
企业在上云的时候,一般不会抛弃现有的物理服务器与物理网络设备,而选择完全的虚拟化环境。其原因有如下几点:1. 保护存量投资,进行增量部署;2. 一些特殊类型的工作负载(如大型数据库)不允许、技术上也很难迁移到虚拟化环境中;3. 虚拟化环境安全性、性能都不如物理环境。另外,虚拟机产生的Internet流量也不可避免地要送出虚拟化环境的边界,交由核心的路由器来处理。因此,虚拟化环境和非虚拟化环境的对接就成为了一个非常重要的问题,这一部分就来探讨一下对接的问题。
在开始介绍具体内容之前,要先来做一些前提的约束:1. 只考虑IP数据网络,不涉及存储网络和HPC;2. IP物理网络拓扑考虑最为常见的3-Stage CLOS;3. 虚拟网络只考虑采用Overlay设计的,对于采用FLAT这种设计的虚拟网络,其本质与物理网络没有区别,对接上不会存在大的问题。
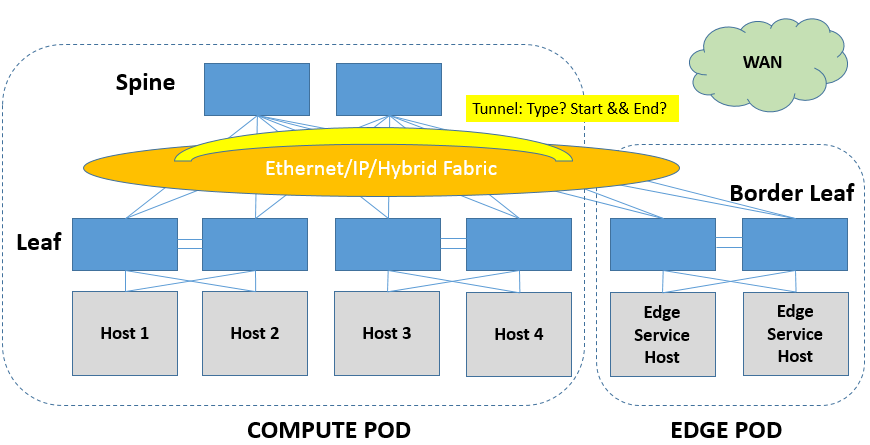
考虑到存量物理网络的复杂性,以及业务需求的多样性,虚拟化环境与非虚拟化物理环境的对接需要考虑的方面非常之多。为了能帮助读者梳理出一个较为清晰的思路,笔者将从以下两个维度来分析虚拟化、非虚拟化环境对接的关键点,当然这两点本身也并不是独立的,是互有交叉的。
- Overlay与物理网络对接的流量类型,是要打通二层还是要打通三层?
- Underlay的建设,是L2 Fabric还是L3 Fabric还是L2和L3混合组网?
我们先来看对接的流量类型。在设计对接之前,必须要搞清楚的是,对接的地方要跑的是什么流量。
(一)二层流量的对接
虚拟化和非虚拟化环境的二层对接,最重要的其实就是一件事情,即对同一个二层在虚拟化环境和非虚拟化环境中的标识做映射。非虚拟化环境中的二层标识基本上就是VLAN ID了,虚拟化环境中的二层标识就是一些L2 overlay tunnel中的标识了。
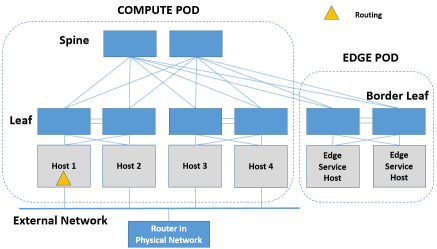
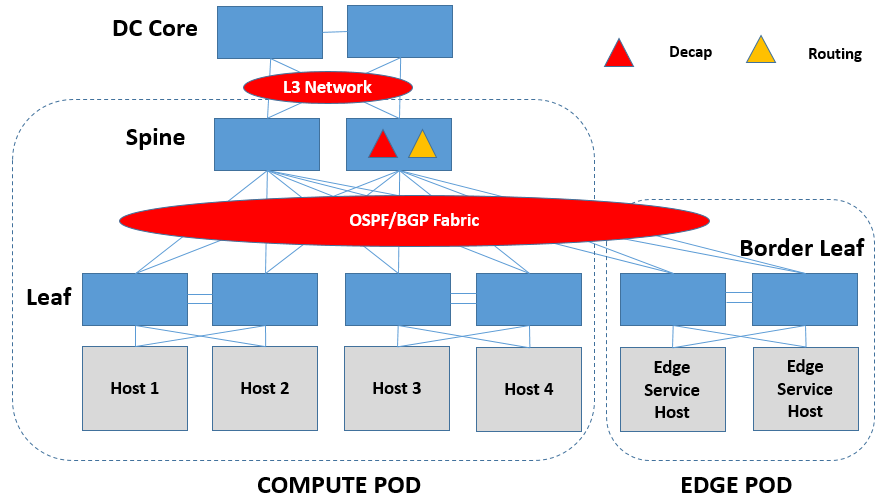
二层标识映射需要一个专门的设备(为了方便称为Translation设备)来完成,根据这个Translation设备的形态来分,它可能是软件交换机实现的,也可能是硬件交换机实现的。软件交换机的话可以放在Border Leaf下面Edge Service Host中专门做边缘连接功能的设备中实现,硬件交换机的话可以放在Border Leaf上、也可以放在Spine上。
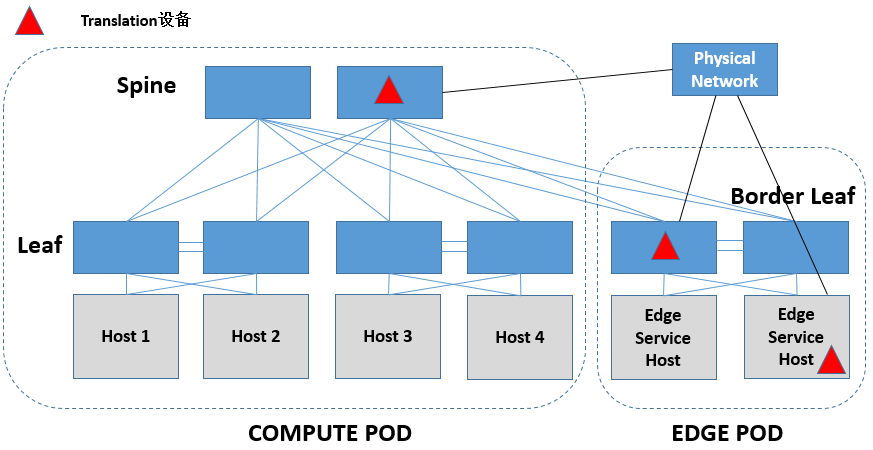
Translation设备除了完成转换以外,更重要的是要使得两侧的控制平面能够做到同步。非虚拟化环境就是xSTP + Per VLAN自学习了,要注意非虚拟化侧产生的xSTP等控制信令要隔离在虚拟化环境之外。虚拟化环境可能是SDN的,也可能是非SDN的。对于采用SDN构建的虚拟化环境,Translation设备也要支持开放的接口,主要和SDN控制器/云管理平台交互以下信息:
a)同一二层在两侧的标识的映射
b)各个二层的MAC地址在两侧的分布
c)虚拟化环境中的ARP信息(可选)
二层的流量,根据源、目的的位置,可以分为同一DC内的二层互通以及跨DC间的二层互通。同一DC内的二层互通没什么好说的,跨DC间的二层通信需要经过特定的DCI设备来完成。同样,这个DCI设备可能是软件实现的,也可能是硬件实现的,而一般来说都是硬件实现的。软件DCI的话可以放到Border Leaf下面Edge Service Host中专门做边缘连接功能的设备中实现,硬件交换机的话可以在Spine上做,也可以放到Translation设备后面物理环境中的专用DCI设备来做。
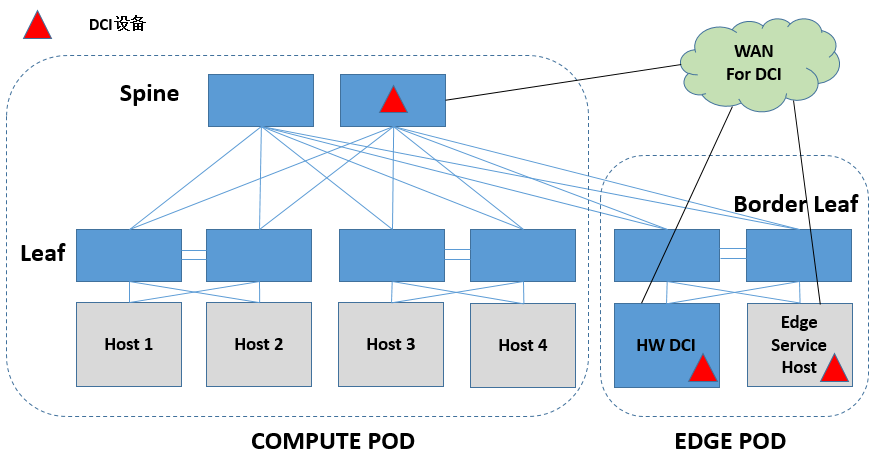
DCI实现的方法很多,可以单独成一个专题了,这里不会做深入讨论。简单地说,DCI设备间也要想办法做MAC地址同步,DCI设备也可是是SDN的或者非SDN的。对于采用SDN构建的DCI网络,DCI设备也要支持开放的接口,主要和DCI SDN控制器/云管理平台交互以下几类信息:
a)同一二层在不同DC的标识的映射
b)各个二层的MAC地址在各DC的分布
c)虚拟化环境中的ARP信息(可选)
(二)三层流量的对接
三层流量的对接,除了处理tunnel的封装以外,相比于二层的对接还要多干一件事,那就是IP的路由。这两件事可以在同一个设备上干,也可以分开在不同的设备上干。另外,三层流量在流量模型上要比二层流量复杂一些,从第一跳路由的实现方式上来看,三层路由可分为集中式路由和分布式路由。
1)集中式路由
集中式路由好理解,它的好处是流量容易做Trouble Shooting,而且容易集成防火墙等Middle-Box。缺点是集中点容易成为瓶颈,而且很多时候流量路径的hop会比较多。
去Tunnel封装可以和IP路由放在一个设备中(为了方便称为Overlay-IP GW)实现。Overlay-IP GW可以是软件实现的,放到Border Leaf下面Edge Service Host中专门做边缘连接功能的设备中实现,也可以由Spine或者Border Leaf抑或Border Leaf下面的HW Router做硬件的实现,用硬件实现要求芯片既能做Decap,又能做Routing。
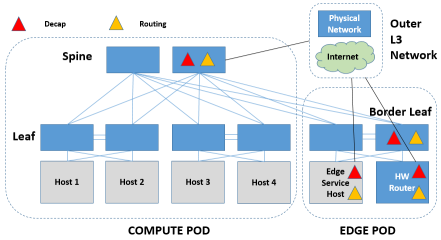
当然,去tunnel封装和IP路由也可以放在不同的设备中实现:先去封装做映射,进入非虚拟化环境,然后在路由器上做IP路由。不过这样的话,其实就可以看做是做二层的对接了。

集中式路由其实和传统数据中心网络中的路由模式很像:在Spine做路由就相当于在Access-Core网络的Core上做路由,在Physical Router或者Border Leaf/Edge Service Host/HW Router中做路由就相当于在Access-Agg-Core网络的Core上做路由。只不过是拓扑变化为leaf-spine后,看起来的样子可能会有所区别。
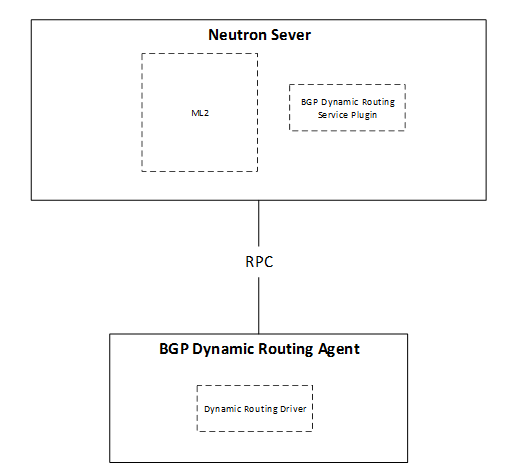
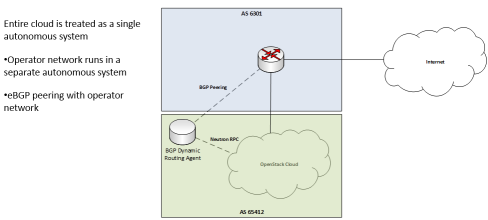
集中式路由的工作都在边缘或边缘以外来完成,如果需要向外界发布Overlay网络的路由,一般都要模拟OSPF/BGP/ISIS这类分布式路由协议。其实,SDN是不太适合抢这口饭吃的,非要软件定义的话应该是只能用API做做管理了,Neutron的BGP Dynamic Routing就准备干这样的一件事情,下面是他们在Austin Summit上的两张胶片。简单地说就是为了L3 Agent增加向外界发布Overlay网络路由的能力,不过这个能力不是在L3 Agent内部实现的,而是通过专门的BGP Dynamic Routing Agent来实现的,Neutron Server上相关的Plugin会通过RPC告诉Agent需要发布的路由信息,由Agent与外界的路由器建立BGP Peer并发布路由,使得:1. External Router能够将Overlay流量的下一跳指到相应的L3 Agent上。2. L3 Agent也可以在多个External Router中更加灵活地选择出口。Vmware NSX中的DLR Control VM也是类似的设计。
2)分布式路由
分布式路由在传统数据中心网络中很少出现。云计算的兴起改变了数据中心的流量模型,东西向流量取代南北向流量占据了主导地位,而集中式路由是为南北向流量设计的,对于东西向流量并不合适,主要原因就是它会导致同一rack下、甚至同一pod下的流量路径hop增多很多。因此分布式路由,解决的思路就是将虚拟机L3流量在第一跳就进行路由,路由后跨rack的再封装tunnel,同一rack或者同一host的就没必要封tunnel绕路送到集中式的router上了,直接送给目的虚拟机/物理主机。
分布式路由同样可由软件实现,也可由硬件实现。软件实现就是做在流量源所在的host上,硬件实现就是做在流量源所在host连接的Leaf上,硬件实现要求芯片既能做Encap,又能做Routing。
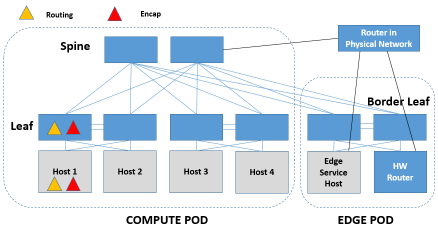
上面看起来似乎和非虚拟化环静没有任何关系,没错。不过分布式路由的第一跳结束后,第二跳就很可能要跳出虚拟化环境了。要注意的是,管理员要搞清楚第二跳究竟是物理路由器还是Edge Service Host上的逻辑路由器,因为在这第二跳上是有很大讲究的。
我们刚才讨论的,着眼点都是从虚拟化环境出去的流量,那么从外界进入虚拟化环境的流量呢?这就涉及了虚拟化环境中,处理南北向流量的最核心的问题——上下行流量的对称性。我们知道传统网络中,主机都是按IP地址前缀聚合到不同的物理位置的,和它有相同IP前缀的主机都位于该物理位置中,因此路由器按照IP前缀能够准确地送到主机所在的物理位置。但是虚拟化环境中,虚拟机是要能够任意漂移的,也就是说同一个租户的同一个IP前缀的不同虚拟机可以处在不同的物理位置,这就给路由带来了很大的困扰。
对于分布式路由的第二跳路由R来说,从外界来了一个要访问虚拟机A的数据包。假设A的前缀是192.168.1.0/24,那么这个R该怎么办呢?因为192.168.1.0/24的主机现在分散在不同的host上,R仅仅通过IP前缀是没办法知道虚拟机A的确切位置的,那么R的下一跳就没办法确定了。
因此,R必须要具备准确定位A的能力,那么怎么办呢?就是为R增加MAC寻址的能力,所有要访问Internet流量的网段,R必须要直接与它们有二层的连通能力,以便通过MAC为下行流量进行准确的寻址。这时,Routing,Encap必须集成于一个设备上,这个设备可以是Spine,也可以是Border Leaf/Edge Service Host/HW Router。
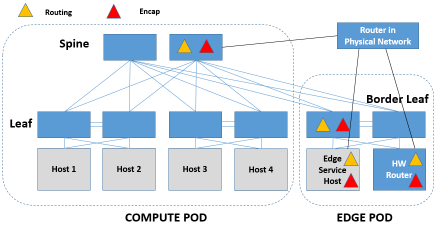
当然,也有思路是在第二条路由器上直接通告VM的32位路由信息,直接用路由指到VM所在的host/Leaf上,然后通过分布式路由器和第二跳路由器间的VNI送给该host/Leaf上的分布式路由器,再由改分布式路由器路由给VM。这种方式的优点是第二跳路由器上不用大量的VM subnet的L2学习和转发了,缺点是第二跳路由器上面的路由表项会很多。这个缺点对于vRouter倒是还好,多占点服务器内存罢了,不过对于物理路由器来说可能就吃不消了,当然如果只用于路由少量的FloatingIP还是可以的。其部署模型和上面的一张图没什么区别,就是在VM所在的host/LEAF上还会有一次路由。
另外,说起FloatingIP,基于SDN的分布式路由的实现经常会出现下面的设计(Neutron DVR、ODL Netvirt、ONOS ONOSFW)。各个host都与物理网络直接相连,分配了浮动IP的虚拟机,其与外界通信的流量,经过NAT后直接从本地经过External Network送给物理路由器处理,而不再经过CLOS网络。
分布式路由其实很适合SDN(尤其是OpenFlow)来做,虚拟机侧的接入设备用OpenFlow匹配分布式路由的VIP+租户标识+IP地址,然后改写MAC做转发就完事了,否则用VM或者namespace来做要麻烦的多。同理。第二跳路由上对虚拟化环境一侧的转发,也很适合用SDN来做,对非虚拟化环境一侧的转发,还是老老实实跑OSPF/BGP/ISIS吧。实际上,BGP Dynamic Routing也准备将他们的思路贯彻到DVR上,但是个人并不看好这个方向。
----------------------------------分割线--------------------------------------------------
Overlay对于Underlay网络实际上没有什么特别的要求,只要能保证封装后的包能够送到目的地即可,但是为了保证虚拟化环境的整体性能,Underlay网络要求是无阻塞+Multipath的Fabric结构。xSTP这类在CLOS网络中少说要block掉50%链路,转发要靠自学习的选手,肯定是指望不上了。目前,Underlay Fabric基本上就是在TRILL/SPB两种L2 Fabric或者OSPF/BGP两种L3 Fabric中进行选择了。当然,L2和L3混合着用也自然是可以的。
另外,也不排除有其它派系的选手。像Juniper Contrail,就希望用MPLS这种L 2.5的技术来搞DCN Underlay Fabric,这充分体现了J做大网的技术基因,不过MPLS的维护成本对于DC管理员来说实在是太高了,因此目前看来L 2.5的Fabric也没有能够流行起来。
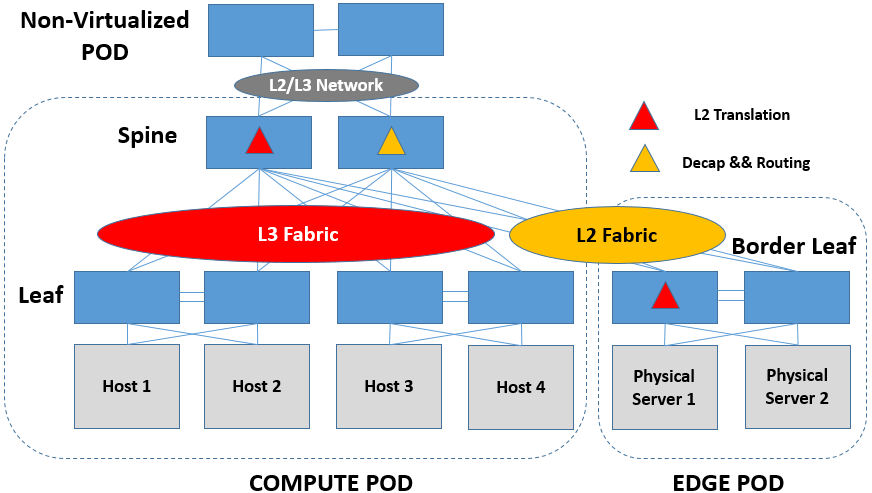
L2/L3 Fabric这部分内容,其实超出了本书对于SDDCN讨论的范围,他们都运行着非常健壮的分布式协议,控制平面是自成体系的,也没有什么必要通过SDN控制器对它们做什么定义或者优化。因此,下面的内容不会去讨论L2/L3 Fabric的逻辑,而是会将Fabric看做一个整体,说一说这个整体对于虚拟化、非虚拟化环境对接的影响。
(一)L2 Fabric
这几年SDN+VxLAN的风靡,使得L2 Fabric在市场上还未兴起,就已经露出了衰退的迹象,但是从内部比较而言,TRILL和SPB这两个L2 Fabric选手间的竞争,基本上是以TRILL胜出作为收场了。TRILL选择用ISIS作为L2的控制平面,数据平面上为Original L2 Frame增加header来做L2路由。TRILL可以实现16路的ECMP,并支持多种方式实现组播,作为VxLAN的Underlay Fabric在技术上是绰绰有余的。但是,选择用TRILL做Underlay Fabric的话,端到端的Path Track和Trouble Shooting仍不够成熟。
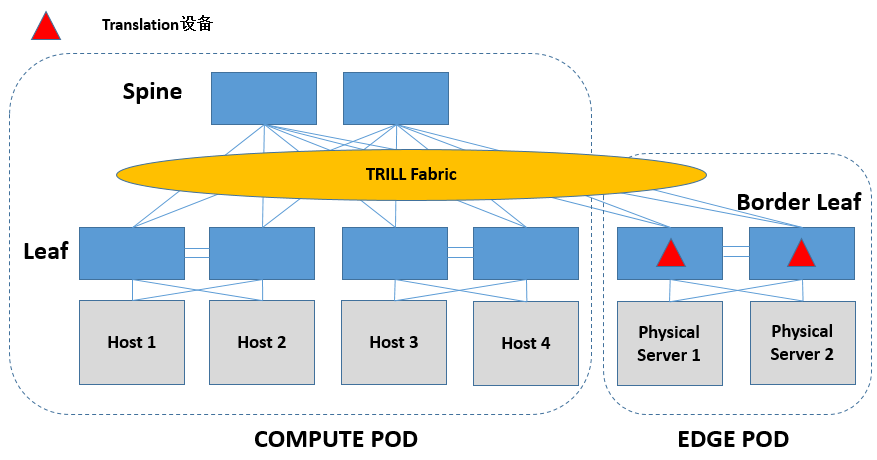
从上一节的讨论来看,Encap/Decap、L2 Translation和IP Routing在Underlay中的部署位置可以说是千变万化的。其实,IP Routing这种事情是TRILL设备不太擅长来做的,因为TRILL本身是要看Nickname而不是IP地址来做路由的。同理,tunnel的Encap/Decap做在TRILL硬件交换机上,代价也是比较高的,因为TRILL的芯片本来就要Encap/Decap TRILL自己的header,再来搞tunnel的header,芯片的压力会比较大。不过为了对接Overlay和物理网络,那是没有选择的,硬着头皮也得上。
IP Routing,如果在Underlay Fabric上做的话,Leaf/Spine上做都是可以的,看各家的设计了。

L2 Translation,在Underlay Fabric上做最一般地来说,就在Border Leaf上来做。
不过,从Spine上做L2 Translation也是可以的,直接用Spine上联L2物理网络(VLAN/TRILL)即可。另外,由于TRILL本身就是个二层的域,因此在Spine上做Translation,也不一定非要上联物理网络,这相当于说Spine的下方既包括TRILL + VLAN(for VxLAN)+ VxLAN + Original L2 Frame,也包括TRILL + VLAN + Original L2 Frame的环境,好用不好用不好说,但看上去是比较新鲜的。
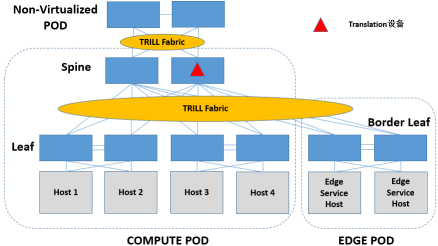
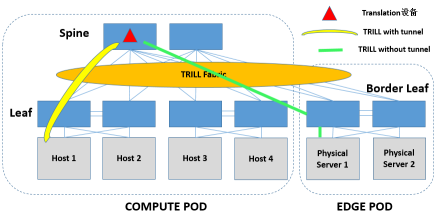
引入SDN,无非就是给L2 Translation设备加点智能,主要和SDN控制器/云管理平台交互的东西还是下面这么几类:
a)同一二层在不同DC的标识的映射
b)各个二层的MAC地址在各DC的分布
c)虚拟化环境中的ARP信息(可选)
其实,Overlay Tunnel + L2 Fabric在技术上并不是一个很好的选择,毕竟L2 Fabric中控制平面的设计是为了虚拟机间的通信来做的,虚拟机的流量在进入TRILL域之前,还要先包上一个tunnel header,那么TRILL控制平面的高深武功就已经被废了一大半。另外,TRILL再包一个新的TRILL Header,对效率和MTU也会有一定的影响。
(二)L3 Fabric
相比于L2 Fabric,L3 Fabric做Underlay是较为合适的。一来,L3的技术已经非常成熟了,控制平面健壮,即使出了错调试起来也都比TRILL容易多了,毕竟OSPF/BGP这些可都是运维人员的看家本领;二来,Scale-out的能力是要比L2 Fabric强的;三来,不需要像TRILL/SPB一样加新的包头,省去了很多麻烦。最后,做IP Routing是顺带手的,不需要新张罗芯片的功能。至于用OSPF还是BGP,这个就要看不同运维人员的个人习惯了,哪个玩的顺手就来哪个。
IP Routing,在L3 Fabric上做非常合适,两侧都是L3,还可以跑不同的L3协议。同样,到底是在Leaf还是Spine上做,就看厂家自己产品的考量了。
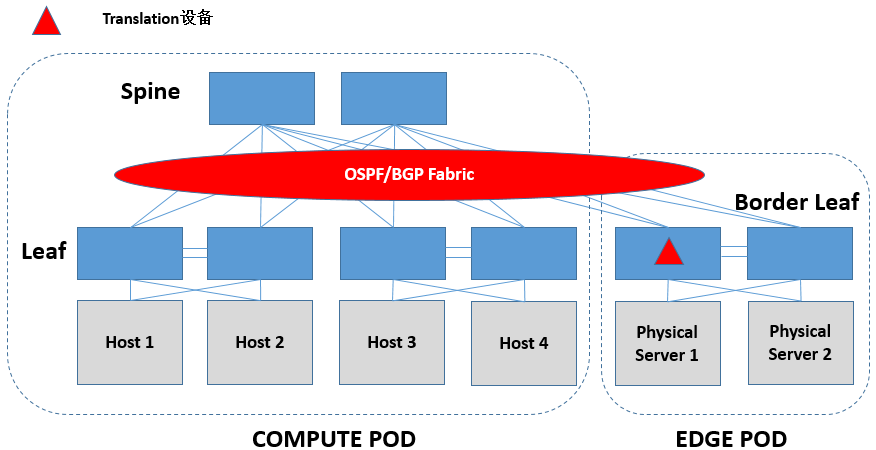
L2 Translation,一般在L3 Fabric的Border Leaf上做。当然,在Spine上做也是可以的。
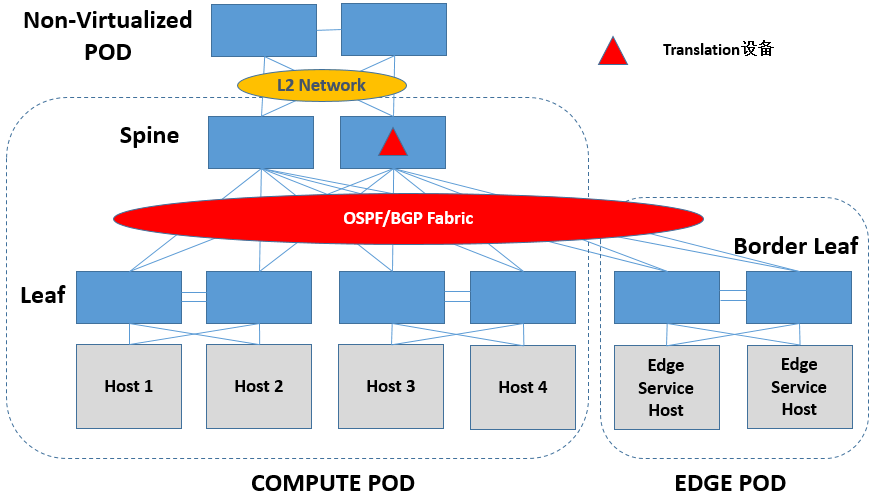
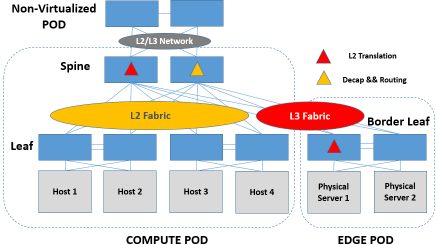
(三)Hybrid Fabric
L2和L3在leaf和spine间混合着用也是没问题的。不过如果混用一定要适度,不是说技术上存在什么不可能,而是这样会造成运维的难度大幅增加。
--------------------------------------------------------------------------
SDN实战团微信群由Brocade中国区CTO张宇峰领衔组织创立,携手SDN Lab以及海内外SDN/NFV/云计算产学研生态系统相关领域实战技术牛,每周都会组织定向的技术及业界动态分享,欢迎感兴趣的同学加微信:eigenswing,进群参与,您有想听的话题可以给我们留言。








