

【编者的话】本文系SDN实战团微信群(团长张宇峰@brocade)组织的线上技术分享整理而成,本次由Calient 中国技术总监 曲宏亮给大家分享美国超大型互联网公司不停在买的Next-Gen光交换技术,同时也结合ODL的SDN controller 构建不一样的Cloud Data Center。
嘉宾介绍
--------------------------------------------------------------------------

曲宏亮:Calient中国技术总监
分享正文
-------------------------------------------------------------
大家晚上好,首先声明一下,今天在这里分享的内容为个人技术关点,不代表公司立场。SDN和Optical这块知识我不是专家给大家起个穿针引线,哪块说的不对还请各位多多指正。
今天给大家分享四部分内容:
1.第一部分光的部分:3D MEMS,
2.基于odl的LightConnect Manager软件架构,这部分跟sdn相关
3.基于3D MEMS的光交换机在数据中心内部的应用场景
4.光包混合型数据中心openflow东西向流量调度测试报告
在分享第一部分前,我们来思考几个问题,没有定性的答案。
- 网络本质是什么,解决什么问题?
- 光在数据中心内部应用是不是真的能解决成本?提升效率?
- 25G/50G/100G数据中心内部选择多模还是单模?
- 100G PSM4/CLR4/CWDM4/LR4/SR4/SWDM/应该如何选择?
由于时间关系,这些问题在这里就不展开讨论,我们先看第一部分。
3D-MEMS 全称3D Micro-ElectroMechanicalSystem,3D微型电子机械系统。我们平常见到最多是MEMS-CMOS, 也就是MEMS传感器,今天说的这个3D-MEMS是另外一个分支。技术很简单用初中物理的知识就可以解释清楚。看一张图
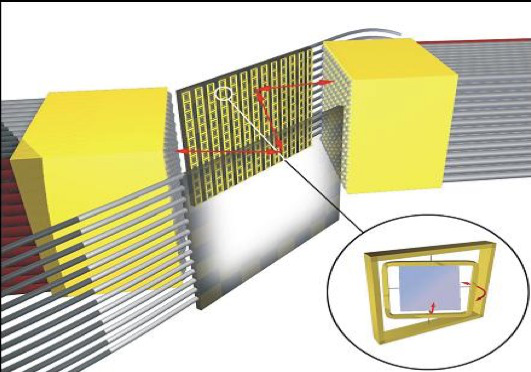
这张图上有两片1cm x 1cm硅片,正常的半导体工艺是在硅片上做晶体管,3D-MEMS技术是在硅片上雕刻镜子,镜子的形状如上图的右下角所示,单个镜子大小0.5mm x 0.5 mm。
什么是3D呢?每个镜子可以水平转动也可以垂直转动(两个方向,正负20度)。除去镜子之间的间隙,一张1cm x 1cm的片子可以刻384个镜子,通过调整镜子的角度利用光学反射原理可以实现光路切换。为什么需要2块片子呢?入光和出光各对应一个mirror,只要调整入和出的mirror角度就可以完成一次光路切换。
在工厂QA阶段,从384中挑出320个mirrors,剩下64个做为backup. 原理很简单,镜子怎么转动呢?每个mirror X/Y轴各有两个引脚共4个引角,一张片子384x4=1536针脚,针脚连接到电路驱动板上。用静电压值控制每个镜子的角度实现光路交换。整个MEMS可以实现384x384的光路交换,实际使用320x320,也就是入光片子上的每个镜子与出光片子上的所镜子都可进行光路切换。入光和出光片子上的每个镜子对应一根光纤,也就是320进320出。我们知道在OTN ROADM中的WSS是N x1的光开关,不是MEMS技术。关于ROADM这里就不展开了。
总结一下3DMEMS特点:完全无源的光子层面上的交换技术、3D微机电系统结构、规模型微机电系统、静电驱动、比特率无关、低功耗
什么是无源的光子层面上的交换?我们先看一个概念:哪位知道什么是O-E-O?什么是O-O-O?大家都知道O2O,OEO称光电光,我们通常看到的2-7层设备基本上都是,光纤连到设备上通过光模块转成电信号,在设备内部芯片之间靠PCB板走线连在一起,出设备又通过光模块再做一次电转光。当然光背板的Router也有了,感兴趣的可以看一下Compass或Search一下COBO。
384x384整体功耗45W,那么MEMS有没有短板呢?有。是什么?不支持多模光,也就是不支持850nm波段。1310~1625nm O、S、C、L全波段都支持。那么支不支持多模光纤呢?支持。单模光跑多模光纤也不是什么新鲜的事,这里就不展开了。
MEMS为什么不支持多模光?拿两根光纤多模和单模对比,发现多模光纤直径要比单模粗。也就是说多模光的光点直径要比单模大,多模光打到MEMS mirror上很容易发生色散失真,MEMS能不能做到支持多模,理论上是可以,把mirror做大,入和出片子间距缩短减少插损。稳定性、可靠性、灵活性、成本、端口密度上就会大打折扣。从商业应用的角度上看是不成立。
这就是第一部分内容,接下来我们看第二部分跟软件相关的内容。
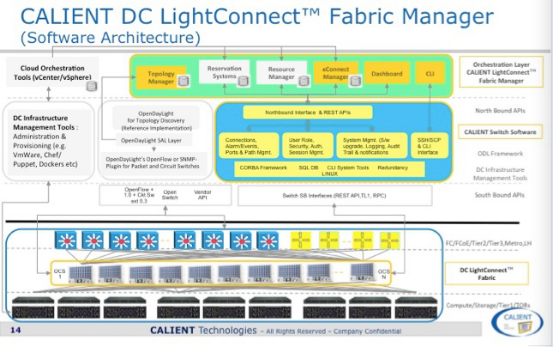
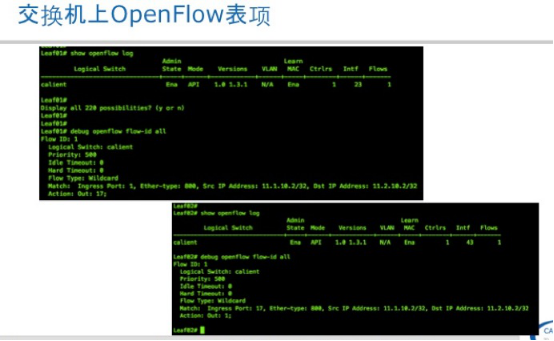
上面这张图黄色和桔黄色部分是Calient自己做的工作,灰色部分是ODL原生态的部分,我们看南向接口左侧部分是通过ODL的Openflow1.0/1.3与以太网交换机对接,右侧部分光交换机的南向接口是通过Calient自己的接口与光交换机对接,主要是用于跟系统管理相关的功能,在Openflow extension中没有定义的那些功能,但光交换机已经支持Openflow1.0 extension版本,通过基于ODL的SDN Controller主要实现物理层的动态拓扑及光层拓扑的自动化、可视化,可管理性及物理资源灵活调度功能。具体应用场景下一部分我们再展开。
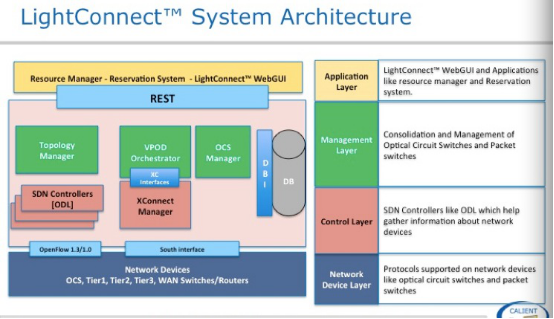
这张图是对上一张图右侧部分功能的解释,主要有三部分:拓扑管理、VPOD 、光交换机系统管理,拓扑管理是物理层拓扑,怎么能自动形成拓扑,在下一张图说明,VPOD会在应用场景部分做说明,光交换机系统管理是对光交换机日志、软件批理升级、用户权限等跟系统相关部分。
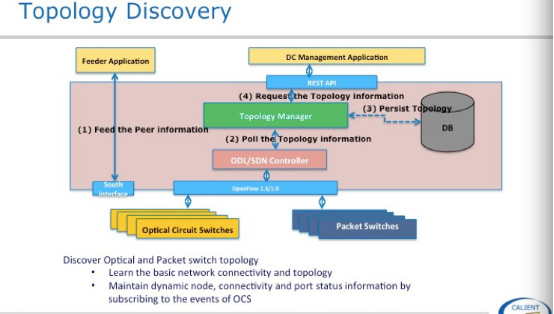
光与以太网交换机怎么能自动发现及形成拓扑呢?我们知道以太网交换机有链路发现协议如lldp/cdp,但光交换机不能发送和接收任何报文。它怎么知道自己的端口对应那台以太网交换机那个端口呢?很显然需要我们告诉它,在拓扑发现之前需要将以太网交换机的mac地址在光交换机上做个导入工作,用Script或Excel方式都可以,很简单。第二步topology manager会主动通过of poll光交换机和以太网交换机端口信息,并同步到db中。这就形成一个整体的拓扑。
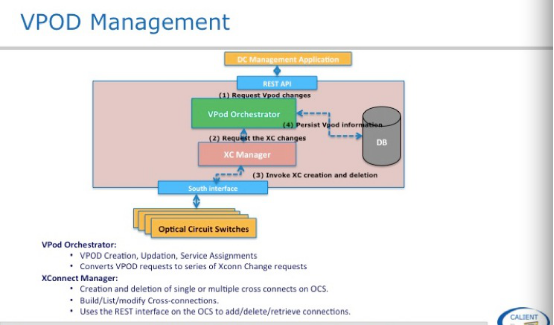
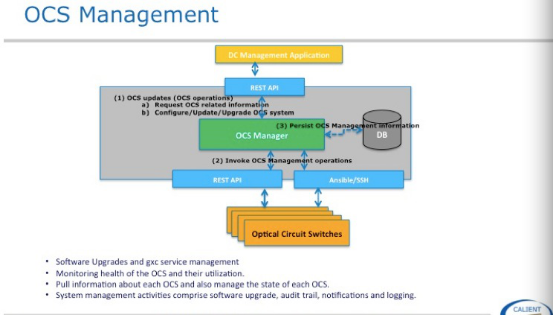
这是 VPOD和OCS Management大家看一下,就不展开了。
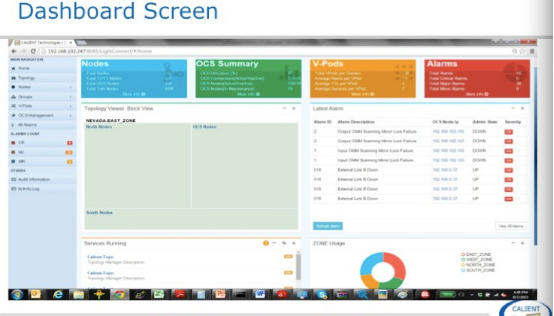
这是LightConnect Fabric Manager的Dashboard,在alrams中可以看到光层面的日志信息,有什么用呢?我们在生产网里偶尔也会碰到crc error帧,怎么造成的呢?一个帧的比特位顺序错误或丢失几个比特位都会产生crc。什么会造成这种现象呢?
大家注意看光模块的参数会发现有一个Tx端有个tx power 和Rx端有个接收敏感度两个值,Tx端有个最大值和最小值范围,用接收端敏感度的值减去Tx的最小值就是最小的Margin,如果光模块Tx光功率衰减,Tx power降低加上光纤的插损小于Rx端的接收敏感度,这时候就会出现误码。所以对光功率的监控是很好的工具对识别网络中的误码。
接下来我们来看第三部分,也就是应用场景。有三个应用场景,一个是WAN的和二个数据中心内部的。由于时间关系在这里介绍两个数据中心内部的应用场景。
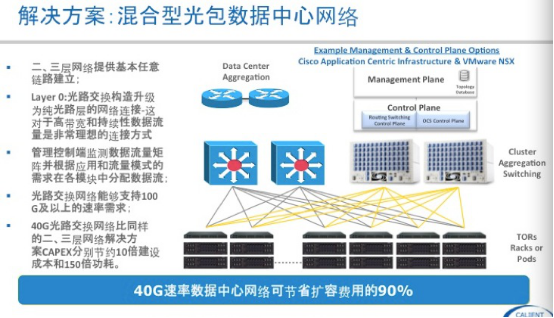
第一个应用场景hybrid datacenter,主要是解决数据中心内部东西向持续性大流量问题,把大流量offloading到光交换机上,可用于POD内部,也可以用于POD之间。这个应用场景对原有的架构改动不是很大,只需要在TOR或汇聚交换机加些Uplink到光交换机,调整以太网侧的收敛比来降低成本。
通过ODL实现光层拓扑自动建立,自动下发Openflow表项到以太网交换机,实现流量自动地offloading. 用上面的图举例,东西向流量相当于TOR to TOR的调度,只需要一跳,关于hadoop中的burst问题不是这个方案所能解决的,在网络侧只有深buffer也就是片内buffer所能解决,在应用侧也有其它的解决方法,在这里不展开了。
接下来我们看第二个方案VPOD
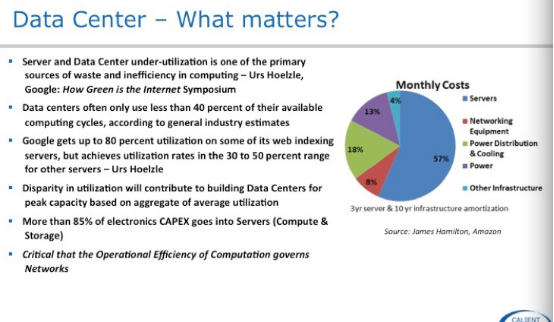

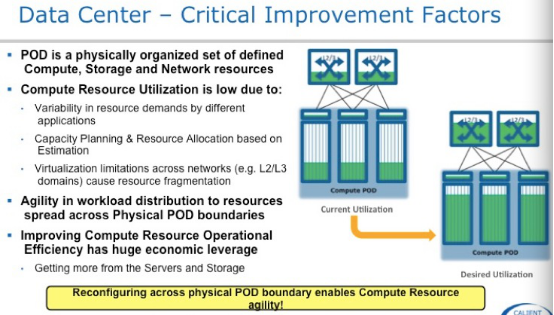
这三张图是讲述数据中心的Workload问题,大家看一下。既然有Workload的问题,物理层的问题用物理的方法解决。
我们来看一下vpod架构。

首先我们看到POD到Spine的黑色线部分是传统的IP-CLOS架构,右侧黄色线部分是连接到光交换机上形成一个Optical Fabric,也就是一POD内部有一半的资源是固定的,别一半资源是可以通过光层面灵活做物理资源调配。那么什么是VPOD呢?
看下面这张图:

看一下VPOD定义,是由一排一排机架组成的一个虚拟POD,这些机架源于原有的POD可能是在不同的物理位置,也可能是在不同的Building。
我们看右上角的框里面,大家都认识。资源管理应用,首先要知道数据中心中那些资源是空闲可以被再利用。左上角的框里面,大家也都认识,自动化配置管理工具。有了这两个框再加上Fabric Manager,我们就可以在光层把数据中心物理资源进行“池化”,进行物理资源的灵活调度,让基础架构随应用需求动起来,提升物理资源灵活性与利用率。当然这个应用场景需要用户有很强coding能力,对基础架构改动也蛮大的。
最后给大家分享一下Hybrid DataCenter 用openflow做东西向流量调度测试报告,这里面软件层面基本上都是开源的,Inmon + ODL, 光交换机这侧做个简单 Coding接口对接,整个架构就跑起来,非常简单。
接下来发几张图:
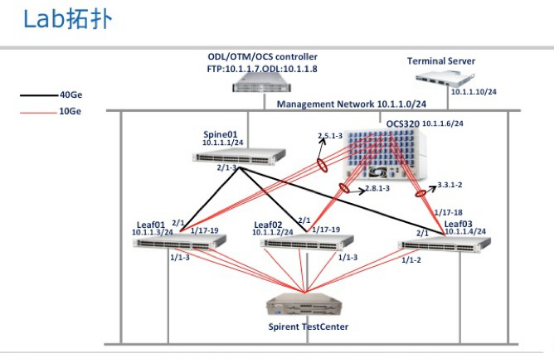

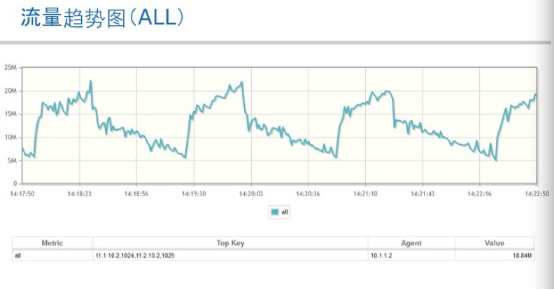
下面这张图很关键
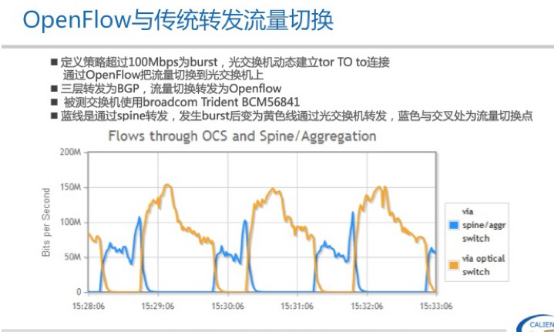
解释一下,曲线图中黄色部分表示流量通过Openflow切换到光交换机上,蓝色部分表示流量切换到以太网汇聚交换机上走路由转发。在这里定义的TE策略是超过100Mb为burst切换到光交换机侧,低于80Mb切回到以太网汇聚交换机上。

上图左侧看到的Openflow表项是由inmon+TE db自动生成的。
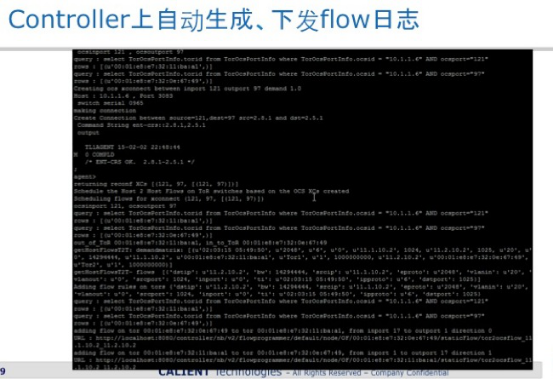
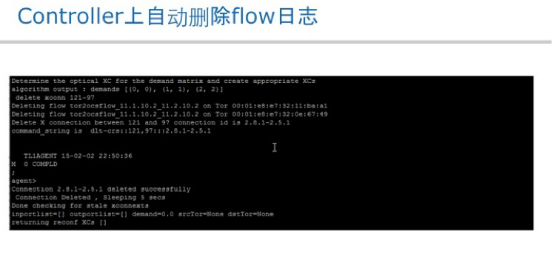
光交换机这侧在这个测试里面是用tl1自动化建立与删除光路,Openflow有点慢。
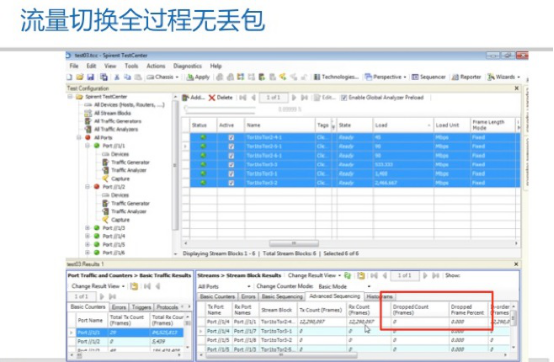
这是TestCenter的UI,注意看红色框中的drop count是0

trident商用芯片,至少可以说明Openflow Hybrid Mode在商用芯片上是没有问题的。当然这个场景也相对简单。
对这个测试例做一下总结,个人关点。Openflow在做流量调度具有灵活性,所有需要跑Openflow的交换机之间互联接口不需要配置互联IP,如果是二层接口首先要把stp disable掉,如果是三层接口不会有这个问题。所以建义用三层接口方式。Openflow短板是在实时下发flow table的场景下需要考虑一条路径上所有节点表项同步的问题,这是和传统方式的最大区别,传统二三层表项是靠节点间二三层协议收敛自动完成。宽外管理网的可靠性,以及Controller到每个节点Latency值得考虑。
下面是些光在数据中心应用的一些paper,感兴趣的可以去读一下。Baidu一下都可以找的到。


对于sdn看法,个人观点:不能说好,也不能说不好。但有一点是肯定,能给我们很多可以想象的空间。我的分享完了,谢谢大家的时间
Q&A
Q1:比起传统网络设备 这个对客户的benefits是什么?
A1:这方面我不是专家,群里边有很多高手可以解答你的问题
Q2:请问在这里BGP是运行在控制器上吗?是用eBGP负责和外网通信还是负责和內网多个控制器之间用iBGP通信?
A2:bgp没有运行在controller上。ebgp在数据中心内容做multipath. ibgp不行。
Q3:那就是BGP运行在传统switch上?
A3:对,bgp是在以太网交换机上。
Q4:针对第一个场景和测试里的场景,我理解还是光通信里的“bypass”的方案,通过光层连接直接承载流量旁路电层转发以达到更高效的目的。但这里有个问题原理上讲这种机制只对持续时间较长且数据量很大的流有效,如何在数据中心内部及时判断这种流就是一个很关键的问题;更进一步,如果正好碰上一个抽风的流,当超过阈值触发了你的光层旁路机制后流量又急速下降造成倒回电上,如此反复又如何处理?这种方法一个前提是tor上一个或几个端口预留给光开关使用,其实也是一种资源浪费,如果都连接到汇聚层是否会更好?
A4:首先是用到sflow,其次在TE策略中可以定义时间。对像hadoop这种burst不起作用。
Q5:那传统网络交换机现在也开放接口由Odl controller管理吗?就是说所有的网络设备,光的,OpenFlow的,传统的都由Sdn控制器管理?还是BGP路由器还是分布式的做网关呢?就是说请问这些设备是如何融合的?
A5:看你要解决什么问题了?把所有功能都放到controller上从目前看是一件不现实的事。
--------------------------------------------------------------------------
SDN实战团微信群由Brocade中国区CTO张宇峰领衔组织创立,携手SDN Lab以及海内外SDN/NFV/云计算产学研生态系统相关领域实战技术牛,每周都会组织定向的技术及业界动态分享,欢迎感兴趣的同学加微信:eigenswing,进群参与,您有想听的话题可以给我们留言。








