

作者简介:马子俊,2014/08 - 至今,清华大学软件学院大四本科生
前言
2014年, 网络领域顶级会议SIGCOMM的一篇论文“P4: Programming Protocol-independent Packet Processors”,提出了数据平面领域特定语言P4,为SDN数据平面带来了独立于协议的高度可编程性。
2017年,由清华大学网络科学与网络空间研究院所著的一篇SIGCOMM Poster“CacheP4: A Behavior-level Caching Mechanism for P4”,从缓存机制的角度出发,加快P4数据平面的数据包转发处理操作,为方兴未艾的P4注入新的活力。
一、CacheP4切入点
CacheP4的设想来源于在数据平面转发处理报文流时存在的一个事实:转发设备会对同一个无状态报文流中的数据包进行重复的表项匹配。如图1所示,当无状态的报文流F的第一个数据包经过三个Match Action Table(以下简称MAT)T1、T2、T3后,我们实际上可以确定该报文流中的所有数据包都会执行A1、A3、A5三个转发处理操作。因此对于此报文流的后继数据包来说,T1、T2、T3对数据包的匹配是多余的。
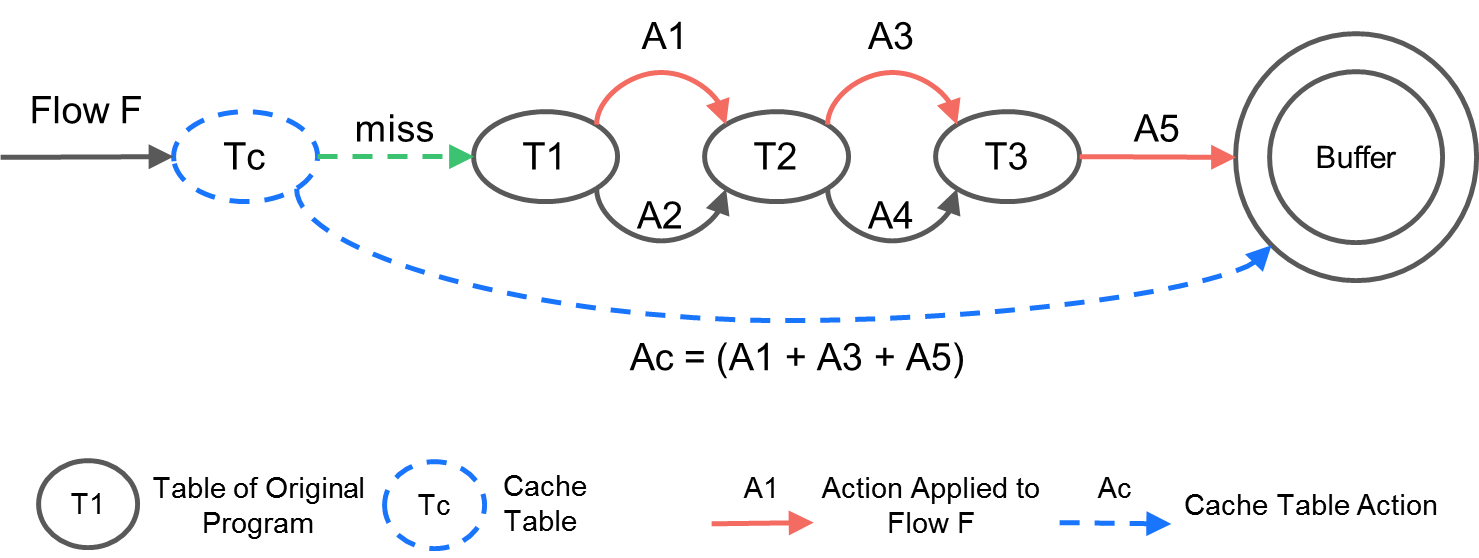
图1 CacheP4示例
CacheP4即通过避免这样的重复匹配来加快数据包转发处理操作。具体来说,CacheP4通过在P4 Ingress Pipeline或者Egress Pipeline中的起始位置插入一个新的MAT作为cache MAT。该cache MAT每一个表项的匹配域的参数用于识别特定的报文流,表项的动作域则负责将此Pipeline内对报文的操作一次性执行完毕。对应在图1中,我们插入了Tc作为cache MAT,并利用Tc表项的匹配域参数识别出报文流F,利用Tc表项的动作域将A1、A3、A5一次性执行完毕。
需要说明的是,CacheP4不是将缓存技术用于报文转发设备的第一例。在数据平面领域,NPU(Network Processing Unit)与CPU类似,同样具有物理缓存区。因为网络应用编译成汇编语言或者机器语言的代码后再难维持“匹配-转发”的逻辑形态,NPU缓存区只能够缓存程序运行过程中的机器指令和数值,所以NPU的缓存是一种“低级缓存”,无法消除报文转发过程中出现的重复匹配。
相较之下,当下在数据中心极为流行的OVS(OpenvSwitch)通过引入快速路径,实现了与CacheP4类似的行为水平的缓存。但CacheP4与OVS的快速路径相比,有着以下不同:
- OVS对报文的转发操作是协议相关的。这决定了它的缓存机制也是协议相关的;CacheP4作为针对P4数据平面设计的缓存机制,具有协议无关性。
- OVS的缓存机制是以软件的形式内建的;CacheP4则是通过修改P4程序引入缓存机制的,对P4转发设备无特殊要求。这意味着CacheP4有望成为多平台通用缓存机制。
二、CacheP4设计简述
1. CacheP4整体架构
CacheP4整体架构如图2所示,总体上分为P4程序的编译阶段和P4设备运行阶段。
P4程序的编译阶段:
1.cache MAT被构建并加入到P4 Pipeline中
2.修改后的P4程序被编译安装到P4转发设备中
P4设备运行阶段:
3.网络管理员可以利用网络监测手段决定需要被缓存加速的报文流,并将报文流的特征告知位于控制层的应用程序
4.应用程序根据报文流的特征构建出cache MAT表项的匹配域参数和动作域参数(即应当执行何种转发处理操作)
5.应用程序将构建出的cache MAT表项下放到cache MAT中作为缓存的一部分,指定的报文流便可以被缓存所加速
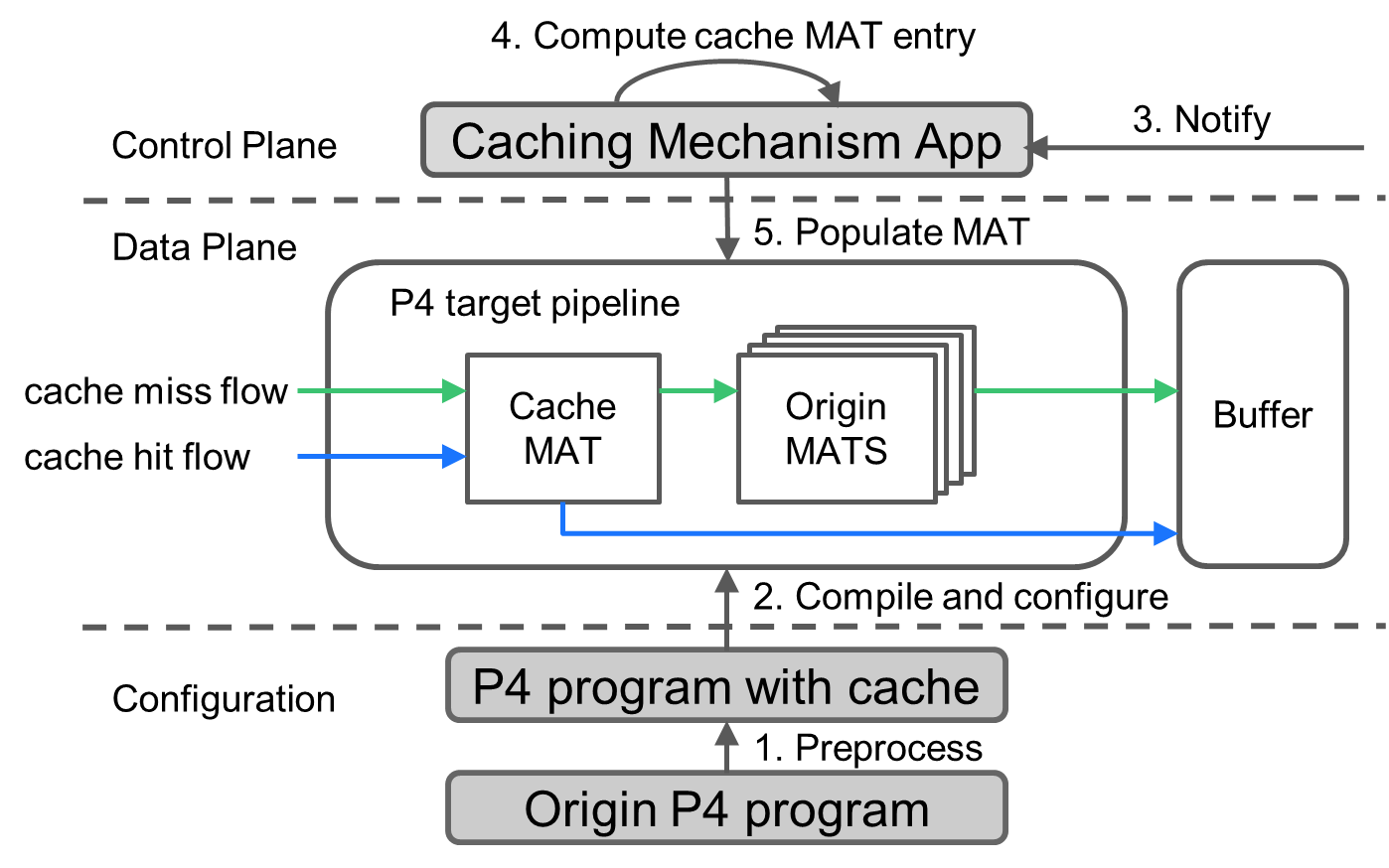
图2 CacheP4整体架构
2. cache MAT的生成
在P4程序编译阶段,生成cache MAT是CacheP4设计的一个难点。回想一下,在OVS的快速路径中的cache MAT的结构是确定的,因为OVS的转发处理操作是协议相关的。相反,因为P4是协议无关的,程序中的MAT的匹配域字段是编程者自行确定的,所以cache MAT的结构基于P4 Pipeline内原有的MAT的结构而定。一方面,匹配域的字段的个数和动作域的转发操作的个数不能过少,以防止cache MAT不能对报文流进行有效地区分和正确地转发;另一方面,需要匹配的字段的个数不能过多,以防止cache MAT的匹配为数据平面的报文转发操作的性能带来明显的额外负担。
为了使cache MAT的结构尽可能简洁,同时维持P4设备转发操作的正确性,cacheP4利用现有的程序切片技术分析P4 Pipeline内的代码片段,得到对P4 Pipeline执行流产生影响的若干初始变量——数据包的字段和标准元数据。这些初始变量作为cache MAT的匹配域。cache MAT动作域中的每一种转发处理操作,则对应P4 Pipeline中每一种可能的执行顺序下原有MAT的转发操作的串行叠加。
三、CacheP4验证及结果探讨
我们基于Bmv2对CacheP4做了初步验证,实验结果如下:

表1 CacheP4验证案例
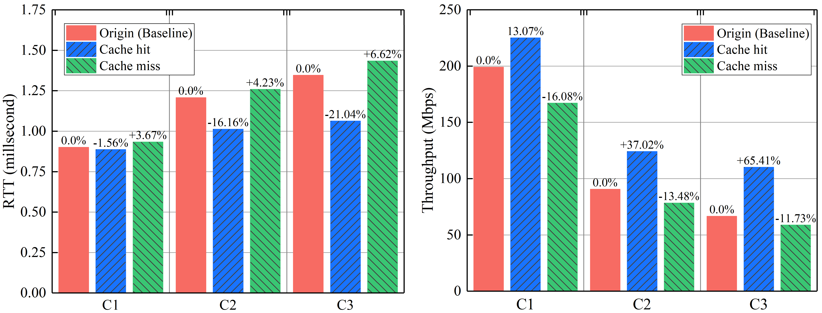
图3 CacheP4性能提升
实验初步表明了CacheP4在提升P4设备的转发速率和吞吐量方面的优秀潜力。实验环境下的测试报文流均为单条报文流;而在生产环境下,同一时刻流经P4设备的报文流可能存在多条。因此,如何选择被缓存加速的报文流以使得缓存机制对转发性能的提升更加显著,是一个需要仔细考虑的问题。我们对此问题虽无定论,但提出了若干可能影响流选取的因素:(1)报文流中数据包的总数估计值;(2)报文流中数据包的大小估计值;(3)报文流经过的MAT个数;(4)cache MAT表项的个数上限;(5)管理员意图。
四、CacheP4未来工作
我们计划在未来工作中对CacheP4进行完整的设计和充分的实现,并在此基础上探索不同报文流选取策略的优劣。
结语
以上就是关于CacheP4的介绍,希望能给诸位P4爱好者以启发。笔者接触P4时间不长,资历尚浅。在此感谢张程,周禹两位博士生在撰文过程中提供的宝贵意见,以及毕军教授的指导。
参考文献
Zijun Ma, Jun Bi, Cheng Zhang, Yu Zhou, and Abdul Basit Dogar. 2017. CacheP4: A Behavior-level Caching Mechanism for P4. In Proceedings of the SIGCOMM Posters and Demos (SIGCOMM Posters and Demos '17).








