

编者按:本文系SDN实战团技术分享系列,我们希望通过SDNLAB提供的平台传播知识,传递价值,欢迎加入我们的行列。
--------------------------------------------------------------------------------------------------
嘉宾简介:卢誉声,Autodesk软件研发工程师,从事平台架构方面的研发工作。
在此之前,他曾在思科系统(中国)研发中心云产品研发部工作,并参与了大规模分布式系统的服务器后端、前端以及SDK的设计与研发工作,在分布式系统设计与实现、性能调优、高可用性和自动化等方面积累了丰富的敏捷实践与开发经验。他主要从事C/C++开发工作,致力于高性能平台架构的研究与开发。此外,对JavaScript、Lua以及移动开发平台等也有一定研究。著有《分布式实时处理系统:原理、架构和实现》,并译有《Storm实时数据处理》《高级C/C++编译技术》《JavaScript编程精解(原书第2版)》。
最近关注的重点包括:性能优化、机器学习、深度学习和框架设计
--------------------------------------------------------------------------------------------------
随着互联网与计算机的普及,我们可以通过传统途径或者互联网收集到大量的数据,而我们在日常工作中对这么大量数据的处理需求也与日俱增。日常遇到的数据种类非常多,从结构化的表格数据、到半结构化非结构化的文本图像,我们需要掌握更多的技能与工具来学会如何处理这些数据。尤其在机器学习越来越热的今天,我们更加有必要学会如何处理这些数据,比如近两年最火的恐怕就是深度学习,而深度学习又非常依赖数据量,很多时候网络再怎么精心设计,再怎么使用技巧,也不如数据量来得实在。比如在我们这里经常需要为此处理大量的文本和图像数据。但是在这个过程中,我们发现总是在做很多重复的工作。总结一下,日常的工作模式抽象出来基本就是这么几件事:
1.将需要处理的数据输出到一个列表文件(或者存到数据库里),每一项就是一个任务
2.处理程序中开启多个Worker线程,并为每个线程分配任务,线程执行自己的任务,并将结果输出出来
3.处理程序还需要记录处理了哪些数据,哪些成功,哪些是异常的。
4.需要将这么多个处理程序连接在一起完成数据处理任务。

可以发现,这个需求其实就是一个简单的生产者-消费者模式,我们其实是在建立一个任务队列,然后让Worker来取任务并执行任务。为了简化这项工作,自己写了一个简单的消息队列以及生产者消费者的抽象,让程序专注于数据处理的逻辑。用户只需要建立一个MessageQueue(消息队列),一个Feeder(消息源),一个Consumer(消息处理单元),并且实现Feeder和Consumer的具体逻辑(可以使用函数对象或者lambda表达式)。这样就可以简化日常的任务,但是,经过长时间的工作发现这样还是远远不够的,我们还需要经常处理这些事情:

我们来分别看一看:
1.如何分配任务?一开始我们采取的是按序号分配任务,每个任务执行连续一批任务。后来发现这样会遇到很多问题,不如使用生产者消费者模式让Worker自己领取任务。但是由于缺乏统一的调度者,因此无法确保整体具有最高的计算效率。
2.如何处理任务失败?我们一开始的方法是将成功任务和失败任务分别放到两个独立列表里,每次一个任务结束后都要重新处理失败的任务,有非常多手动工作。
3.程序常常会因为各种原因在一半中断(未完全测试的程序可能有内存泄漏,内存越界,即时程序没有问题也可能会发生进程误杀甚至是断电等狗血的事情),因此我们需要保存任务状态,下次启动程序的时候可以自动跳过已经成功处理过的任务。
4.当数据过多的时候需要手动分割数据放在几个机器上执行,部署和手动管理成本很高。
后来我们发现Apache Storm的数据处理方式很适合解决这些问题。但是非常可惜,一方面出于性能考虑,另一方面为了更加容易地调用本地C++程序,这种基于Java的方式并不是那么方便,每次还需要编写JNI来接入我们的C++代码。
于是,我发现我们需要自己建立一套系统来解决这个问题。这套系统中包含这些东西:
- 使用NodeJS编写的网络爬虫,因为NodeJS单线程异步非阻塞,简化了高性能爬虫的编写工作。
- 使用MongoDB存储数据,因为MongoDB是文档型数据库,而且可以无模式,处理图像和网页数据的时候非常方便。
- 使用Caffe来进行训练和数据处理,由于我们的机器并不是特别多,这种情况下Caffe可以提供比Tensorflow更好的性能。
- Hurricane实时处理系统(http://github.com/samblg/hurricane 或 http://hurricane-project.net),是Storm的计算模型在C++11中的实现,不过做了部分简化和调整,以适应我们自己的工作。
这里面的关键就是Hurricane这个系统:

这张图就是Hurricane的计算模型,Hurricane实时处理系统是一个基于流的分布式实时处理平台,其计算模型是Topology。每个Topology都是一个网络,该网络由计算任务和任务之间的数据流组成。
该模型中Spout负责产生新的元组,Bolt负责处理前一级任务传递的元组,并将处理过的元组发送给下一级。Spout是元组的生成器,而Bolt则是元组的处理单元。每个任务都会将数据封装为元组传递给其他的任务。在系统中任务被定义为Task。Task是对计算任务的统一抽象,规定了计算任务的统一接口。Spout和Bolt都是Task的特殊实现。为了处理这种分布式的计算模型,我们设计了自己的分布式系统架构,如下图所示:
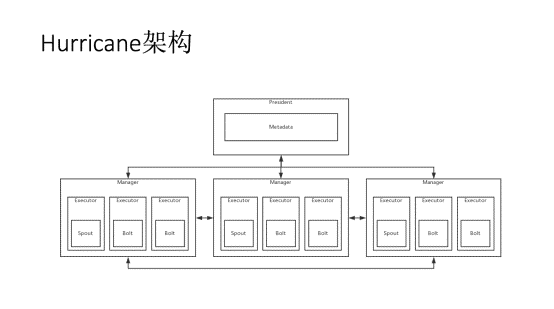
最上方的是President,这是整个集群的管理者,负责存储集群的所有元数据,所有Manager都需要与之通信并受其控制。下方的是多个Manager,每个Manager中会包含多个Executor,每个Executor会执行一个任务,可能为Spout和Bolt。
从任务的抽象角度来讲,每个Executor之间会相互传递数据,只不过都需要通过Manager完成数据的传递,Manager会帮助Executor将数据以元组的形式传递给其他的Executor。
Manager之间可以自己传递数据(如果分组策略是确定的),有些情况下还需要通过President来得知自己应该将数据发送到哪个节点中。
在这个基础架构与计算模型之上,我们还设计了一套上层接口Squared:

左侧是Hurricane基本的计算模型,在该计算模型中,系统是一个计算任务组成的网络。我们需要考虑每个节点的琐屑实现。
但如果在日常任务中,使用这种模型相对来说会显得比较复杂,尤其当网络非常复杂的时候。
为了解决这个问题,看一下右边这个计算模型,这是对我们完成计算任务的再次抽象。
- 第一步是产生语句的数据源
- 然后每条语句需要使用名为SplitSentence的函数处理将句子划分为单词
- 接下来根据单词分组,使用CountWord这个统计操作完成单词的计数。
- 所以这个接口的本质是将网络映射成了简单的数据操作流程。
解决问题和讨论问题都会变得更为简单直观,现在我们来看看Hurricane在SDN领域的应用。
现有网络中,对流量的控制和转发都依赖于网络设备实现,且设备中集成了与业务特性紧耦合的操作系统和专用硬件,这些操作系统和专用硬件都是各个厂家自己开发和设计的。
SDN是一种新型的网络架构,它的设计理念是将网络的控制平面与数据转发平面进行分离,从而通过集中的控制器中的软件平台去实现可编程化控制底层硬件,实现对网络资源灵活的按需调配。在SDN网络中,网络设备只负责单纯的数据转发,可以采用通用的硬件;而原来负责控制的操作系统将提炼为独立的网络操作系统,负责对不同业务特性进行适配,而且网络操作系统和业务特性以及硬件设备之间的通信都可以通过编程实现。
SDN 基本架构:
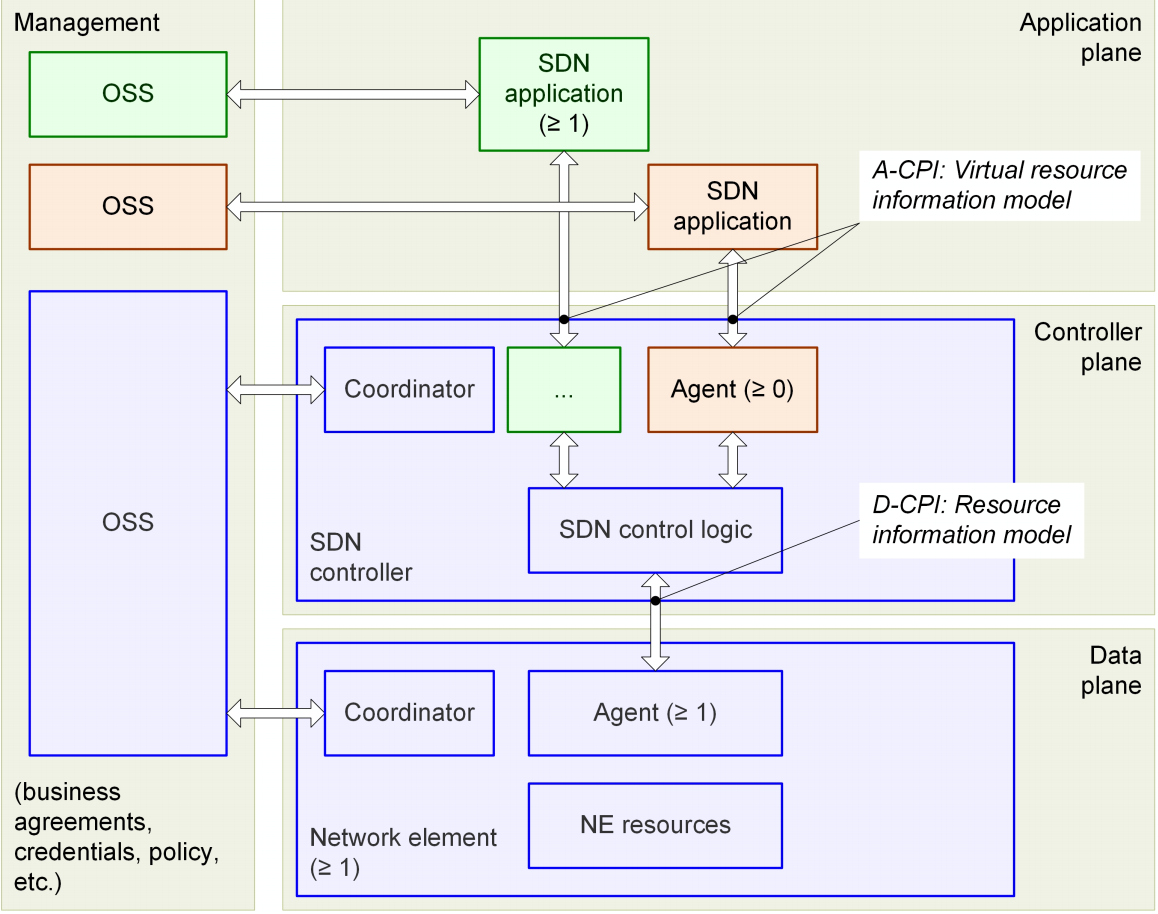
通常来说,我们可以把SDN架构拆分成以下几个部分组成:(相信大家都非常熟悉了)
1、Data Plane:由网络基本设备组成,通过D-CPI(data-controller plane interface)为Controller Plane提供服务。
2、Controller Plane:SDN控制器转发应用程序的请求,并在网络设备之间转发,而具体信息则通过SDN上层应用管理和控制。应用程序通过A-CPI(或NBI)访问服务。对于SDN控制器来说,它负责在有限硬件或网络资源的前提下更合理为应用程序分配资源。
3、SDN application:该层通过A-CPI访问和控制网络请求。
那么,Hurricane实时处理系统在这一整套SDN架构中可以承担什么样的角色呢?没错,消息控制和转发,hurricane提供了高性能的网络I/O和消息队列特性,并在分布式系统结构上抽象了多种消息分发和处理的能力。因此,我们可以利用hurricane 来完成消息转发和控制。不仅如此,Hurricane还通过President提供了exactly-once支持,因此它能够确保在整个分布式系统当中消息被处理一次,而且一定被处理,这样一来,就为可靠性方面提供了框架层面的保证。
Hurricane可以利用其高实时和可靠的特性,作为整个SDN的中央控制单元,一边接收消息,一边根据流量和其他情况自动计算消息与资源分配的解决方案,快速根据实际需求调整网络配置。用户只需要简单修改策略,Hurricane会自动更新整个网络中的策略并完成网络资源的实时调整,完成消息和配置的快速分发。
现在,我们来一起看看Hurricane是如何实现exactly-once语义的。
Hurricane中的每个元组有一个“确认编号(ackid)”,Bolt处理完一个元组后需要调用ack成员函数或者fail成员函数,调用ack表示Bolt成功处理了该Bolt,调用fail表示处理失败。Bolt处理信息会被传递给元组的来源任务(Spout或者Bolt),如果出现处理失败的元组,Storm会取消整个流(从Spout发出的元组以及根据其计算得到的整个元组树),并重新计算所有任务。每个元组还会有一个超时事件,如果一个任务发出元组后一定时间内没有收到ack或者fail信息,会主动认为该任务失败,并按照收到fail消息的情况处理该元组。
最后,Hurricane还有一些其他分布式实时处理系统不太关注的功能,这些功能十分关键,特别是对一些特定领域,比如SDN。
一个功能是数据的保序处理。比如在处理金融和交易业务这类数据的时候,数据处理结果和数据处理顺序密切相关。在SDN中,我们也要考虑到那些和顺序密切相关的消息和任务,如果将分布式系统中的保序控制完全交给开发者来做是非常复杂且不易控制的,而在系统内部日志处理这种任务中也需要用到保序,因此我们需要确保部分数据处理的顺序问题。如果所有的消息处理都进行保序会使整个系统变成顺序执行,那就和单机执行没有太大区别了,也是不适用于SDN的。因此Hurricane采用了不同的保序模式,将数据处理分成两个部分,一个是“处理”阶段,一个是“提交”阶段。处理阶段是数据处理和顺序无关的部分,大部分数据处理任务都在此时发生。提交阶段是需要将数据处理结果提交到数据库或真正触发业务的时候,这个时候如果不确保处理顺序才会发生问题。因此支持保序的Bolt必须要定义是否是用于提交任务的Bolt,Hurricane会在此类Bolt上支持保序。
另一个特性是多语言支持。因为在实际项目中我们会根据实际情况选择开发语言,C++并不永远是最合适的语言,因此支持其他语言调用Hurricane并与Hurricane集成是必要的。Hurricane目前都是用最高效的接口实现与其他语言的互操作,以减少互操作带来的性能消耗。目前Hurricane支持C语言、Java语言、Python语言和JavaScript接口。
感兴趣的同学,可以访问http://github.com/samblg/hurricane、http://hurricane-project.net和https://item.jd.com/11965338.html了解更多内部细节。
最后的最后,特别感谢@明明是我 (明明)在我准备这次分享过程中给予的大力帮助!今天的分享就到这,感谢大家的耐心。
Q&A
Q:Hurricane应该是可以应用到控制器集群方面的吧?我觉得Squared高级抽象元语好厉害!
A:嗯,目前主要就是应用在控制器集群上,Squared元语主要是简化编程模型,它将底层复杂的通信和控制细节隐藏了,因此使用Squared 能够大大简化集群控制编写代码的复杂度和工作量。
Q:请问Hurricane可以保证消息不丢没,可以的话是怎么做到的?
A:Hurricane从架构层面保证了消息不丢失,每个节点收到消息的ack之前会暂时缓存消息,知道该消息被ack为止,如果后面的消息全部处理失败,Spout消息源也会重新从数据源获取原始数据并重新向集群推送数据,确保消息被最终处理。所以不会发生消息丢失。
Q:我想问一下,对于一些特殊的场景,而sdn对业务层本身没有感知能力,应该怎么解决:例如计算结果x,>0分派给节点a计算,<0分派给节点b计算,这种任务sdn又应该怎么样在转发阶段正确地转发呢?
A:这种情况可以使用字段分组解决,比如预先为目的节点定义标签,然后字段分组会根据字段的值将元组分发到具体的目的节点上。依赖于hurricane中心节点President实现具体的功能。
Q:比较过这个和RabbitMQ么?有什么优缺点?
A: RabbitMQ和hurricane 有本质上的区别,hurricane由hurricane framework 和 libmeshy 两个部分组成,其中libmeshy 提供了分布式消息队列的基础工具,而上层的hurricane framework 则实现了简单的消息队列,并在此基础上提供了强大的接口供开发人员使用,开发具体的计算功能和任务。
Q:我感觉这个还可以跟sfc结合,sfc组织的是vNetwork Function,而你这里组织的则是vFunction,更加广义化了,但是像sfc实现,在进入业务链的一刻就已经决定了流向,对于一些需要计算分支控制的流,显得就不是那么灵活了吧?
A:是的,这个结构中的Bolt可以用来做vFunction,作为广义化的vNetwork Function,实现Service Function。这里经过的业务节点都是在某个节点上计算得到的(通过分组条件),所以可以更为灵活。
Q:理解上那么消息到hurricane 后应该只是在内存里,消息是多个副本存储在不同节点吗,不然单个节点异常应该会丢消息的
A:是的,消息源缓存了最初的数据,而这些数据通过中央President节点缓存,President外接NoSQL做备份,所以会尽可能将数据保存下来,确保不丢失。另外,Hurricane原生支持Redis 和 Cassandra 编程接口,因此使用起来十分简单。
Q:怎么屏蔽底层设备的差异性怎么屏蔽,另外使用分布式实时处理系统hurricane做底层分发组件么?
A:嗯,考虑使用hurricane做底层分发组件。Hurricane 无法忽视底层硬件设备的差异,我们尽可能的将可以抽象的实体封装成了接口供上层使用,当然还有不足,也需要借助社区的力量逐渐增强。如果有兴趣的同学可以访问 https://github.com/samblg/hurricane 来加入我们的队伍。由于hurricane framework 及其底层通信组件不依赖于任何第三方组件,因此在开发过程中尽可能隐藏硬件调用的细节,又因为是纯C++开发,从理论上讲在特定平台编译后都能够正常工作。(ARM 和 MIPS 等也在考量范围内)
Q:请问Hurricane+SDN有在做controller prototype实验,还是在理论概念阶段?
A:更多的是理论概念阶段。
Q:集群的管理者是一个节点还是集群,怎么做的高可用?
A:目前集群的管理者是一个节点,只不过可以使用热备模式在管理者出现问题的时候再选择一个新的管理者,因此通过这个机制,系统会较为快速的failover到另一台机器上,并让另一个节点作为管理器继续工作。
--------------------------------------------------------------------------
SDN实战团微信群由Brocade中国区CTO张宇峰领衔组织创立,携手SDN Lab以及海内外SDN/NFV/云计算产学研生态系统相关领域实战技术牛,每周都会组织定向的技术及业界动态分享,欢迎感兴趣的同学加微信:eigenswing,进群参与,您有想听的话题可以给我们留言。








