

编者按:本文系SDN实战团技术分享系列,我们希望通过SDNLAB提供的平台传播知识,传递价值,欢迎加入我们的行列。
--------------------------------------------------------------------------------------------------
分享嘉宾:曹鹿怡,16年IT从业经验,目前就职于Nutanix,负责中国区合作伙伴技术支持;加入Nutanix之前是VMware中国区政府行业技术支持团队负责人,也曾服务于Sun Micro等公司
--------------------------------------------------------------------------------------------------
超融合平台
针对于超融合的概念有着不同的理解,因为组件不同(虚拟化、网络等)而理解不同。然而,核心的概念如下:天然地将两个或多个组件组合到一个独立的单元 中。在这里,“天然”是一个关键词。为了更加有效率,组件一定是天然地整合在一起, 而不是简单地捆绑在一起。对于 Nutanix,我们天然地将计算和存储融合到设备的单一节点中 。这就真正意味着天然地将两个或多个组件整合在一个独立的、 可容易扩展的单元中。
其优势在于:
1.独立单元的扩展
2.本地I/O处理
3.消除传统计算/存储的竖井式结构,融合它们在一起
目前Nutanix超融合产品有两种形态: 1、捆绑式的硬件 + 软件设备(Nutanix NX系列、Dell XC系列及联想HX系列),2、纯软件模式(Nutanix on UCS等)
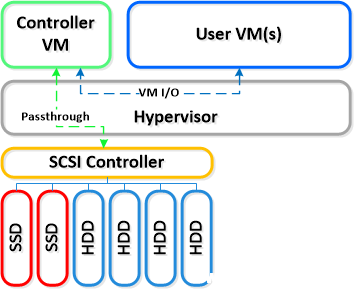
一般来说,从硬件形态看,是在 2U 的占用空间中放置 2 个节点或 4 个节点。每个节点都运行一个符合行业标准的虚拟机监控程序(当前是 ESXi、KVM、Hyper-V, XenServer在目前版本是Tech-Preview)和 Nutanix 控制器 VM (CVM)。
Nutanix CVM 将运行 Nutanix 软件,并为虚拟机监控程序的所有 I/O 操作和该主机上运行的所有 VM 提供服务。凭借虚拟机监控程序的功能,利用 Intel VT-d 将管理 SSD 和 HDD 设备的 SCSI 控制器直接传递到 CVM。
下面是典型节点的逻辑表现形式的一个示例:
从软件定义的角度来看,一般来说,软件定义的智能化是在通用的、商品化的硬件之上通过运行软件来实现核心的逻辑,而这些逻辑之前用专有的硬件编程方式实现(例如 ASIC/FPGA 等)。对于 Nutanix 而言,是将传统的存储逻辑(例如 RAID,去重,压缩,纠删码等)采用软件方式去 实现,这些软件运行在标准的 x86 硬件上的 Nutanix 控制虚拟机(Controller Virtual Machine,即 CVM)内。那就真正意味着把关键处理逻辑从专有硬件中剥离放入到 运行在商用的硬件设备的软件之中。
一组 Nutanix 节点共同构成一个分布式平台,称为 Nutanix 分布式系统框架(DSF)。对于虚拟机监控程序,DSF 看起来就像任何集中式存储阵列一样,不过所有 I/O 都在本地进行处理,以提供最高性能。下面可找到有关这些节点如何形成分布式系统的更多详细信息。
以下是有关这些 Nutanix 节点如何形成 DSF系统的示例:

DSF可以看作是一个分布式自治系统,涉及从传统的单一集中模式处理业务转向跨集群内的所有节点分布式处理业务。传统角度考虑问题是假设硬件是可靠的,在某种程度上是对的。然而分布式系统的核心思想是硬件终究会出问题,在一个简单的、业务不间断的方式中处理故障是关键点。这些分布式系统的设计是为了调整和修复故障,达到自恢复和自治的目地。在组件发生故障时,系统 将透明地处理和修复故障,并持续按照预期运行。将会醒用户知晓故障的存在, 但不会作为一个紧急事件被提出来,任何一种修复(如:替代一个失效的节点)都可 以按照管理员事先设定好的计划表去自动化的处理。另外一种方式是重建而不需要替换,一个主数据节点被随机选举出来,当其故障后新的主数据节点会被选举出来, 利用 MapReduce 的概念来分配任务的处理。
因此DSF可实现:
- 分配的角色和任务到系统内的所有节点
- 利用MapReduce等机制执行分布式任务处理
- 当需要一个新的主数据节点时,采用选举机制
优势在于:
- 解决了单点故障(SPOF)
- 分布式业务负载,消除任何瓶颈
Nutanix超融合群集组件
Nutanix 平台由以下高级组件组成:
Medusa
- 关键角色:分布式元数据存储
- 描述:Medusa 基于经过重大修改的 Apache Cassandra,以一种环式分布方式存储和管理所有群集元数据。利用 Paxos 算法来保证严格一致性。该服务在群集中的每个节点上运行。
Zeus
- 关键角色:群集配置管理器
- 描述:Zeus 将存储所有群集配置(包括主机、IP、状态等)并且基于 Apache Zookeeper。该服务在群集中的三个节点上运行,其中一个被选举为领导节点。领导节点会接收所有请求并将其转发给对等节点。如果领导节点没有响应,则会自动选举一个新的领导节点。
Stargate
- 关键角色:数据 I/O 管理器
- 描述:Stargate 负责所有数据管理和 I/O 操作,并且是虚拟机监控程序的主要界面(经由 NFS、iSCSI 或 SMB)。该服务在群集中的每个节点上运行,以便为已本地化的 I/O 提供服务。
Curator
- 关键角色:映射化简群集的管理和清理
- 描述:管理者将负责整个群集中任务的管理和分配,包括磁盘平衡、主动清理和许多其他项目。管理者在每个节点上运行,而且受选定的主管理者的控制,主管理者会负责任务和作业的委派。
Prism
- 关键角色:UI 和 API
- 描述:Prism 是组件的管理网关,也是管理员配置和监控 Nutanix 群集所使用的管理网关。这包括 Ncli、HTML5 UI 和 REST API。Prism 在群集中的每个节点上运行,而且与群集中所有组件一样使用选定的领导者。
此外,Nutanix集群的节点间通讯(包括存储,服务)采用Google的Protocol Buffers以提升分布式系统的通讯效率和性能。
数据结构
Nutanix DSF的分布式存储系统由以下高级结构组成:
存储池
- 关键角色:物理设备组
- 描述:存储池是一组物理存储设备,包括群集的 PCIe SSD、SSD 和 HDD 设备。存储池可以跨越多个 Nutanix 节点,并且会随群集的扩展而扩展。大多数配置中只使用一个存储池。
容器
- 关键角色:VM/文件组
- 描述:容器是存储池的一个逻辑分段,包含一组 VM 或文件(虚拟磁盘)。有些配置选项(比如 RF)是在容器级别配置的,但是会应用于单独的 VM/文件级别。容器通常与数据存储存在 1 对 1 的映射(就 NFS/SMB 而言)。
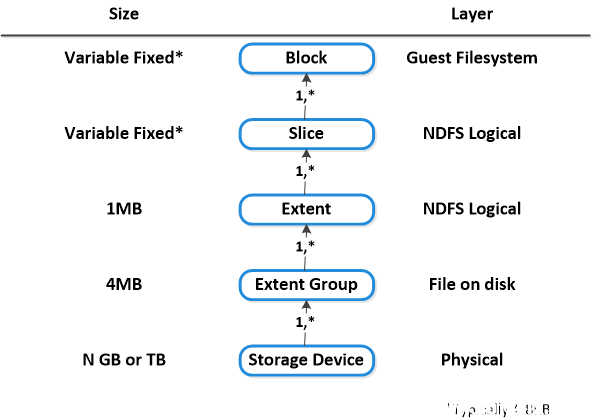
vDisk
- 关键角色:虚拟磁盘
- 描述:虚拟磁盘是 DSF 上任何超过 512KB 的文件(包括 .vmdks 和 VM 硬盘)。虚拟磁盘由盘区构成,这些盘区在磁盘上作为盘区组进行分组并存储。
下图展示了这些节点如何在 DSF 和虚拟机监控程序之间进行映射:

Extent
- 关键角色:逻辑上连续的数据
- 描述:盘区是一段逻辑上连续的 1MB 的数据,由 n 个连续块组成(因来宾操作系统块的大小不同而不同)。以子盘区(又称切片)为基础来写入/读取/修改盘区,以保证粒度和效率。根据读取/缓存的数据量,将盘区的切片移动到缓存中时可能会对其进行剪裁。
盘区组
- 关键角色:物理上连续的存储数据
- 描述:盘区组是一段物理上连续的 4MB 的存储数据。该数据作为一个文件保存在 CVM 所拥有的存储设备上。盘区动态分布在盘区组之间,以便跨节点/磁盘提供数据分块,从而提高性能。
下图展示了这些结构在各种文件系统之间是如何关联的:
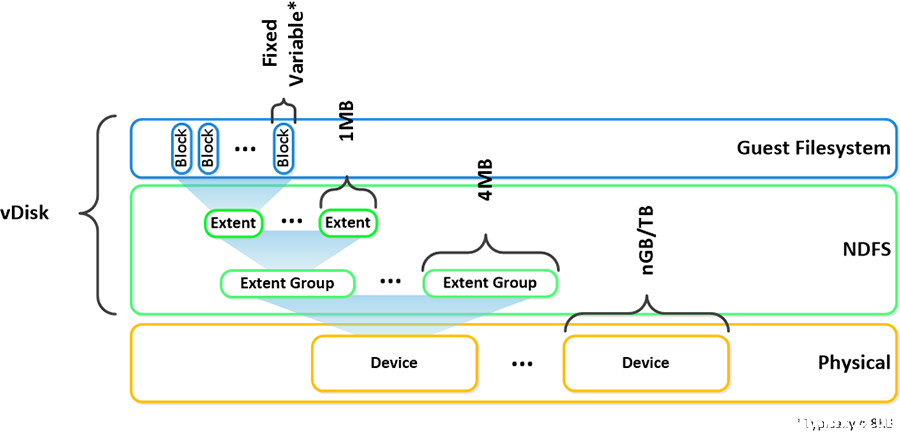
下面是有关这些单元如何逻辑相关的另一个图形表示:
I/O 路径概述
Nutanix DSF系统的 I/O 路径由以下高级组件组成:

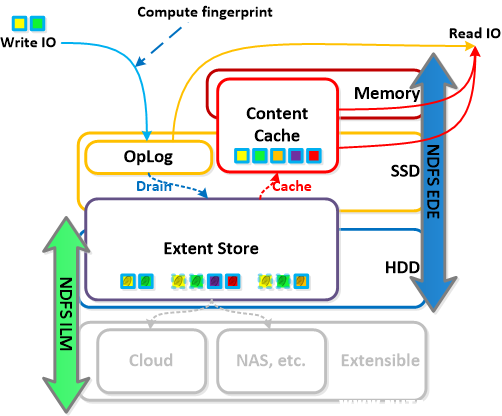
OpLog
- 关键角色:永久性写入缓冲区
- 描述:Oplog 类似于文件系统日志,它的构建是为了处理突发性写入,它会将写入合并,然后将数据按顺序排入盘区存储。为了确定数据可用性而要确认写入之前,OpLog 会将写入同步复制到另一个 CVM 的 OpLog。所有 CVM 的 OpLog 都会参与复制,并且会根据负载进行动态选择。OpLog 存储在 CVM 的 SSD 层上,以便提供极快速的写入 I/O 性能,特别是对于随机 I/O 工作负载。对于连续工作负载,OpLog 将被绕过,写入直接进入盘区存储。如果当前数据处于 OpLog 中且尚未排出,所有读取请求将从 OpLog 直接完成,直到将它们排出,然后将由盘区存储/内容缓存为它们提供服务。对于启用指纹识别(又称重复数据删除)的容器,将会使用哈希方案对所有写入 I/O 进行指纹识别,以便根据内容缓存中的指纹来识别它们。
Extent Store
- 关键角色:永久性数据存储
- 描述:盘区存储是 DSF 的永久性大容量存储,跨 SSD 和 HDD,而且可以扩展,为其他设备/层提供便利。进入盘区存储的数据要么是 A) 从 OpLog 排出的,要么是 B) 本质上是连续的,直接绕过 OpLog。Nutanix ILM 将根据 I/O 模式动态确定层的放置并将数据在各层之间移动。
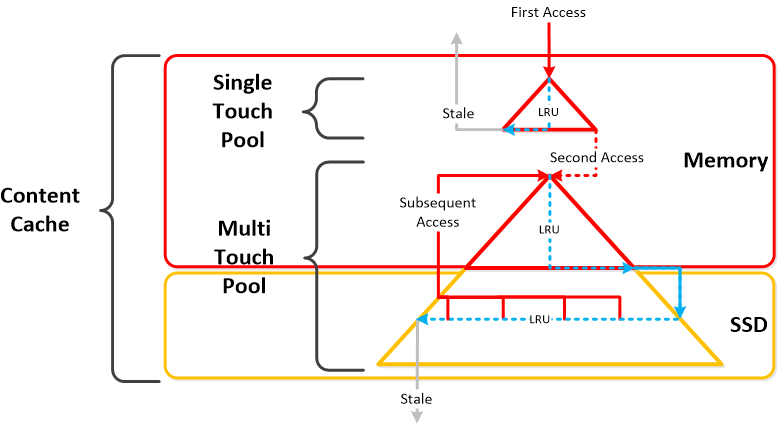
内容缓存
- 关键角色:动态读取缓存
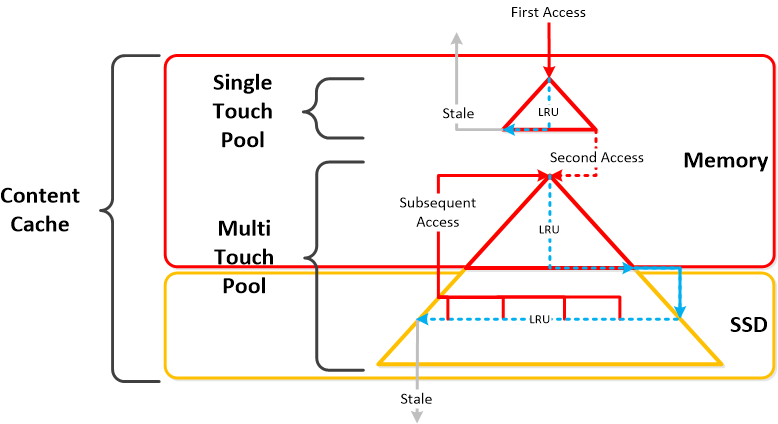
- 描述:内容缓存(又称“弹性重复数据删除引擎”),是通过指纹识别的读取缓存,可以跨越 CVM 的内存和 SSD。当缓存中(或根据特定指纹)不存在数据的读取请求时,数据将被放入单一触控的内容缓存池中,内容缓存池完全处于内存中,在这里它会使用 LRU,直到将其从缓存中选定。任何后续读取请求会将数据“移动”(事实上并不移动任何数据,只是缓存元数据)到由内存和 SSD 组成的多点触控池的内存部分。这里将有两次 LRU 循环,其中一次是针对内存中的数据,逐出会根据它将数据移动到多点触控池的 SSD 部分,在多点触控池中将分配新的 LRU 计数器。多点触控池中任何数据读取请求都将导致数据达到多点触控池的顶峰,在这里会为其给定一个新的 LRU 计数器。指纹识别是在容器级别配置的,并可通过 UI 配置。默认情况下禁用指纹识别。
下图展示了内容缓存的高级概述:
Extent Cache
- 关键角色:内存中的读取缓存
- 描述:盘区缓存是一种内存中的读取缓存,在 CVM 的内存中完成。这将为禁用指纹识别和重复数据删除的容器存储非指纹盘区。在 3.5 版及之前版本中,该缓存与内容缓存独立,不过在后续版本中这些缓存将会合并。
数据保护
目前,Nutanix 平台使用复制因子 (RF) 来确保节点或磁盘发生故障时数据的冗余和可用性。如“架构设计”部分所述,OpLog 充当一个临时区域,将传入的写入吸收到低延迟的 SSD 层。将数据写入本地 OpLog 时,在被主机确认 (Ack) 为成功写入之前,数据将会同步复制到另外的一个或两个 Nutanix CVM 的 OpLog 中(取决于 RF)。这将确保数据存在于至少两个独立的位置,且具有容错能力。所有节点均参与 OpLog 复制以避免出现任何“热节点”并确保扩展时的线性性能。
然后,将数据异步排出到隐式维持 RF 的盘区存储中。之后在节点或磁盘出现故障的情况下,会将数据在群集中的所有节点之间重新复制以维持 RF。
下面我们将展示此过程的逻辑表现形式的一个示例:
数据位置
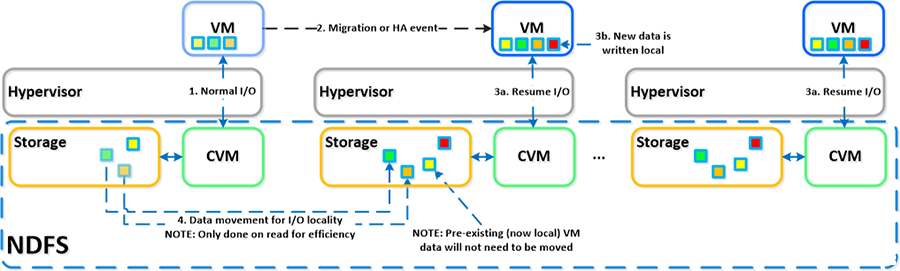
作为一个融合的(计算+存储)平台,I/O 和数据位置对与 Nutanix 有关的群集和 VM 性能至关重要。如前面 I/O 路径中所述,所有读取/写入 IO 均由本地控制器 VM (CVM) 提供服务,本地控制器 VM 位于邻近常规 VM 的每个虚拟机监控程序中。在 CVM 的控制下,VM 的数据将在本地由 CVM 提供服务并且位于本地磁盘中。当 VM 从一个虚拟机监控程序节点移动到另一个时(或发生 HA 事件时),最新迁移的 VM 的数据将由现在的本地 CVM 提供服务。在读取旧数据(存储在现在的远程节点/CVM 上)时,I/O 将由本地 CVM 转发到远程 CVM。所有写入 I/O 将立即在本地出现。DSF 会检测到 I/O 从另一节点出现,并在后台将数据迁移到本地,现在将允许在本地为所有读取 I/O 提供服务。为了不泛洪网络,只在读取时迁移数据。
下面我们将展示数据在虚拟机监控程序的节点之间移动时如何“跟随”VM 的一个示例:
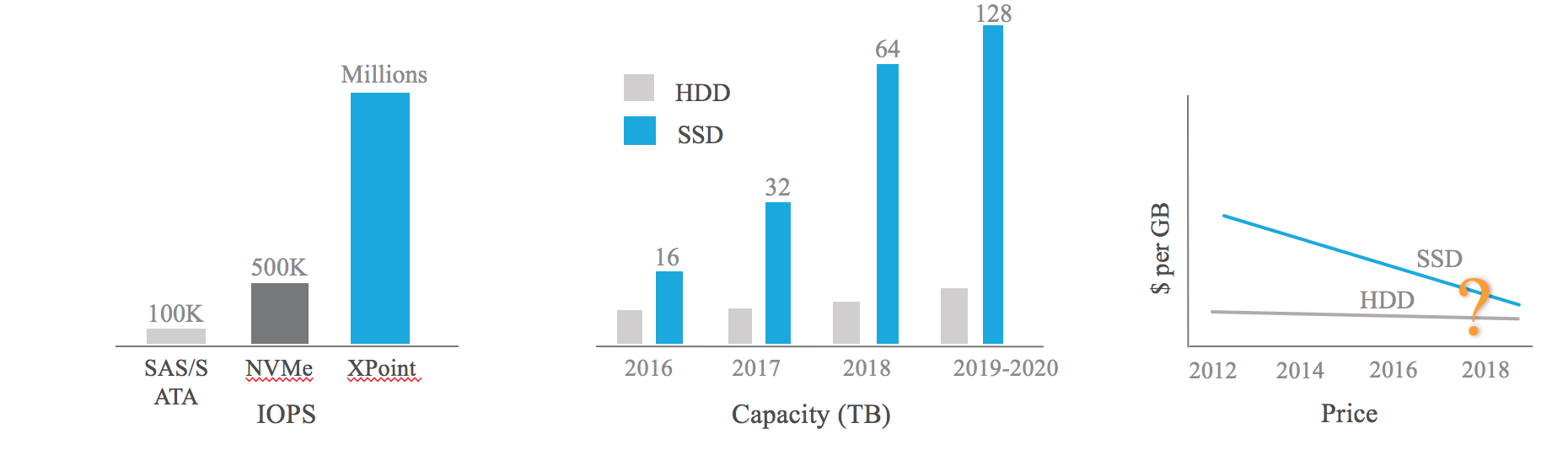
尤对于闪存相关技术当前的发展(其快速增加的容量和密度)及网络带宽与延时的相对滞后,,使得数据位置/数据本地化的作用会更加明显。
闪存单元设计增强:
- SLC: Single Level Cell (1 bit per cell)
- MLC: Multi Level Cell (2 bits per cell, 2x density)
- TLC: Tri Level Cell (3-bits per cell)
3D NAND
- 闪存单元按层排列以增加密度(垂直堆叠)
NVMe
- 使用PCIe-based标准替代SATA 和 SAS接口
- Fabric topologies 替代networks
- 预计2017/18年有能够成为主流
3D XPoint (Optane)
- Intel and Micron推出的新的非易失性存储记忆体
- 相较于闪存更强大性能 (1000倍)
- 预计2018/2019年有望进入企业应用市场
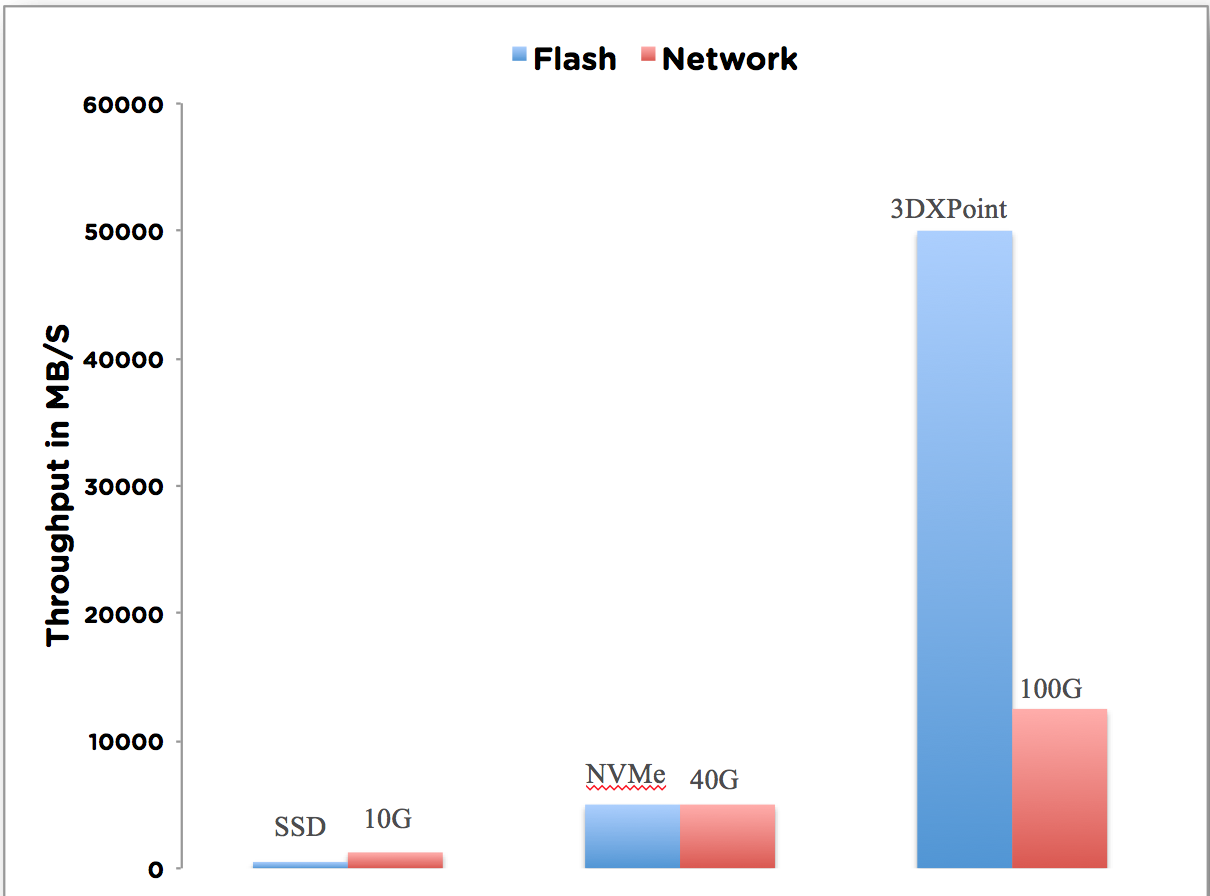
以一款经典的企业级SSD (Intel S3700)为例计算
随机 I/O 性能:
- Random 4K Reads: Up to 75,000 IOPS
- Random 4K Writes: Up to 36,000 IOPS
顺序读写带宽:
- Sustained Sequential Read: Up to 500MB/s
- Sustained Sequential Write: Up to 460MB/s
延时:
- Read: 50us
- Write: 65us

可伸缩元数据
元数据是任何智能系统的核心,对文件系统或存储阵列而言甚至更为重要。就 DSF 而言,一些关键结构对于它的成功至关重要:它必须时刻保持正确(又称“严格一致性”),它必须可伸缩,而且它必须能够大规模执行。 Nutanix 利用经过大量修改的 Cassandra 平台存储元数据和其他必要信息。Cassandra 利用环式结构并复制到环中的 n 个对等位置,以确保数据一致性和可用性。此时使用 “环式”结构作为键值存储,键值存储将存储重要元数据及其他平台数据(如状态等)。为了确保元数据的可用性和冗余,在奇数节点(如3、5 等)之间使用 RF。在下面我们会有较详细的描述。
当元数据写入或更新时,写入或更新的行将被写入环中的一个节点,然后复制到 n 个对等节点中(其中 n 取决于群集大小)。大部分节点必须同意,然后才能提交任何内容,内容的提交是使用 paxos 算法强制执行的。这将确保所有作为平台一部分存储的数据和元数据的严格一致性。
下面我们将展示 4 节点群集的元数据插入/更新的一个示例:
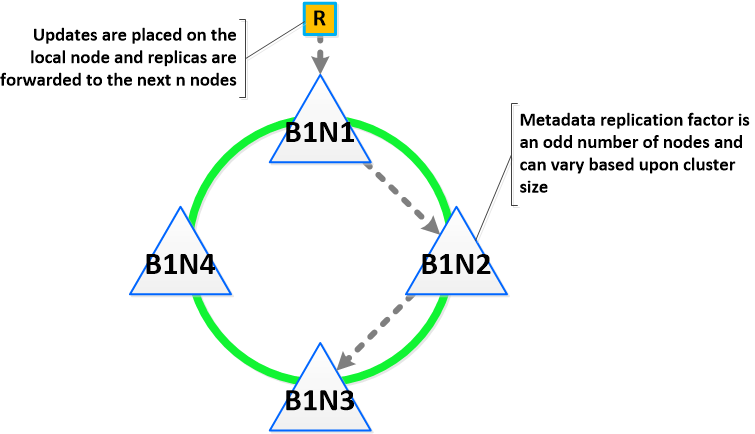
扩展时的性能也是 DSF 元数据的另一个重要结构。与传统的双控制器或“主”模型不同,每个 Nutanix 节点负责整个平台元数据的一个子集。这消除了传统上允许群集中所有节点为元数据提供服务并进行管理的瓶颈现象。通过一致性哈希方案来尽量减少修改群集大小时键的重新分配(又称“添加/移除节点”)
当群集扩展时(例如从 4 个扩展到 8 个节点),为了确保“块感知”和可靠性,这些节点将被插入整个环中的节点之间。
下面的示例将展示包含 12 个节点的群集的 Cassandra 环:
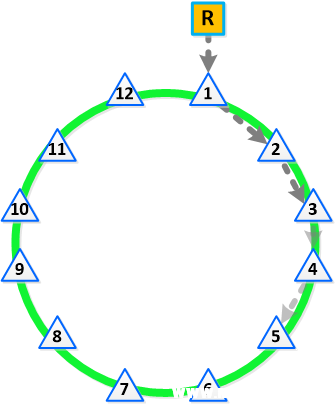
Cassandra 对等复制在整个环中以顺时针方向遍历各个节点。借助块感知功能,对等节点分布于各个块中,以确保同一个块上不会有两个对等节点。
下面我们将展示一个节点布局示例,将上述环转换为基于块的布局:
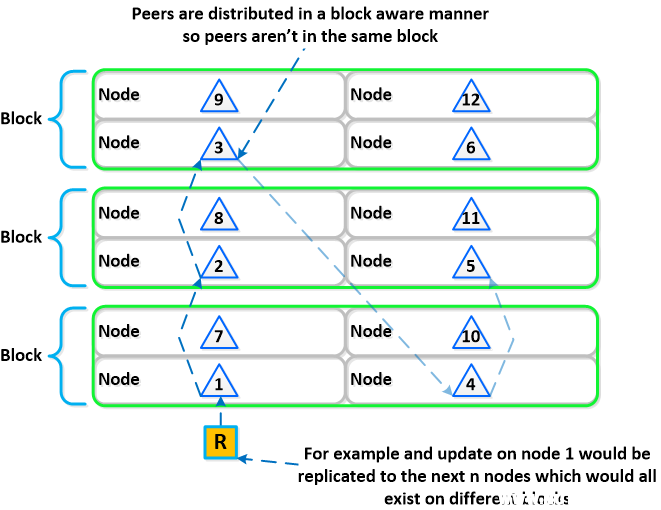
借助这种块感知特性,如果块发生故障,仍然至少有两个数据副本(适用于元数据 RF3 - 在更大群集中可以使用 RF5)。
配置数据
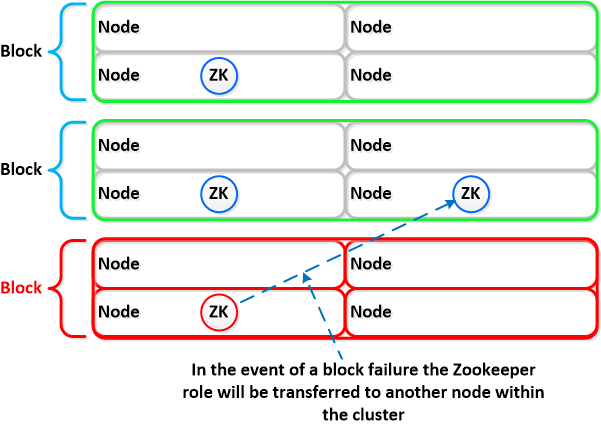
Nutanix 利用 Zookeeper 存储用于群集的必要配置数据。这一角色也以块感知方式分布,以在块发生故障时确保可用性。
下面我们将展示以块感知方式分布的 3 个 Zookeeper 节点的布局示例:
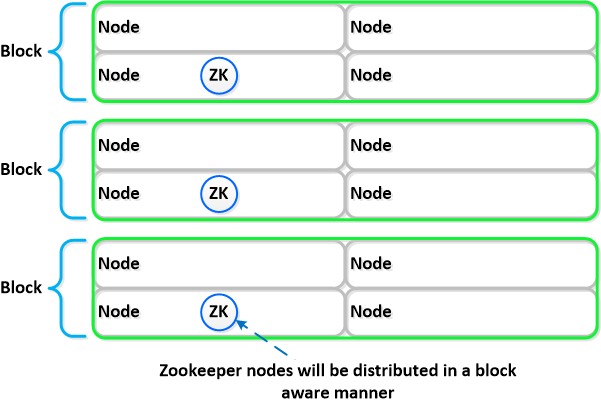
如果块中断,Zookeeper 节点的意义也就消失了,Zookeeper 的角色将转换到群集中的另一个节点,如下所示:
上述是Nutanix超融合架构设计的一些内容,以下我们就在此基础之上的部分功能运行机制做简要的介绍:
运行机制之Shadow Clones
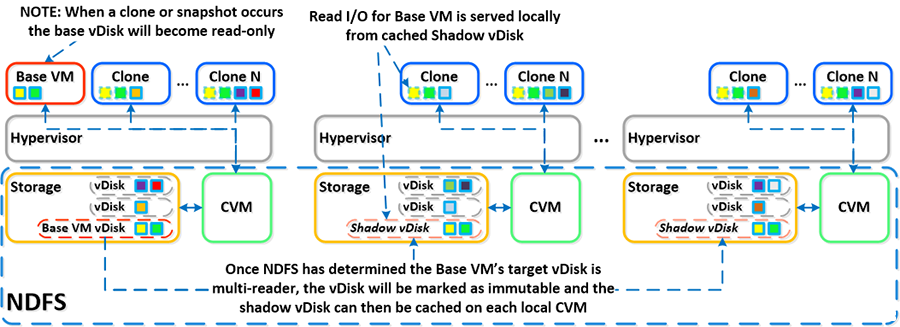
Nutanix 分布式系统有一个称为“影子克隆”的功能,它支持“多读取者”场景下特定虚拟磁盘或 VM 数据的分布式缓存。有关该功能的一个典型例子是,在 VDI 部署期间,许多“链接克隆”会将读取请求转发到中心主 VM 或“基准 VM”。在 VMware View 中,这被称为副本磁盘,通过所有链接的克隆读取,而在 XenDesktop 中,这被称为 MCS 主 VM。这在任何可能有多个读取者的场景(如部署服务器、存储库等)中也会起作用。
数据或 I/O 本地化是实现最高 VM 性能的重要因素,也是 DSF 的关键结构。借助影子克隆,DSF 将监控 vDisk 访问趋势,这与监控数据本地化类似。但是,如果两个以上远程 CVM(以及本地 CVM)发出请求,并且所有请求都是读取 I/O,则 vDisk 将标记为不可变。一旦磁盘标记为不可变,则可通过每个向磁盘发出请求的 CVM 在本地缓存 vDisk(也称基准 vDisk 的影子克隆)。
如此一来,每个节点上的 VM 即可在本地读取基准 VM 的 vDisk。对于 VDI 而言,这意味着副本磁盘可以通过每个节点进行缓存,所有针对基准的读取请求可以在本地获得服务。注意:为了不泛洪网络并有效利用缓存,只在读取时迁移数据。如果基准 VM 已修改,将会放弃影子克隆并重新开始这一过程。影子克隆默认为禁用状态(在 3.5 版及之前版本中),可以使用以下 NCLI 命令启用/禁用:ncli cluster edit-params enable-shadow-clones=true
下面的示例将展示影子克隆的工作原理及其如何实现分布式缓存:
运行机制之Elastic Dedupe Engine
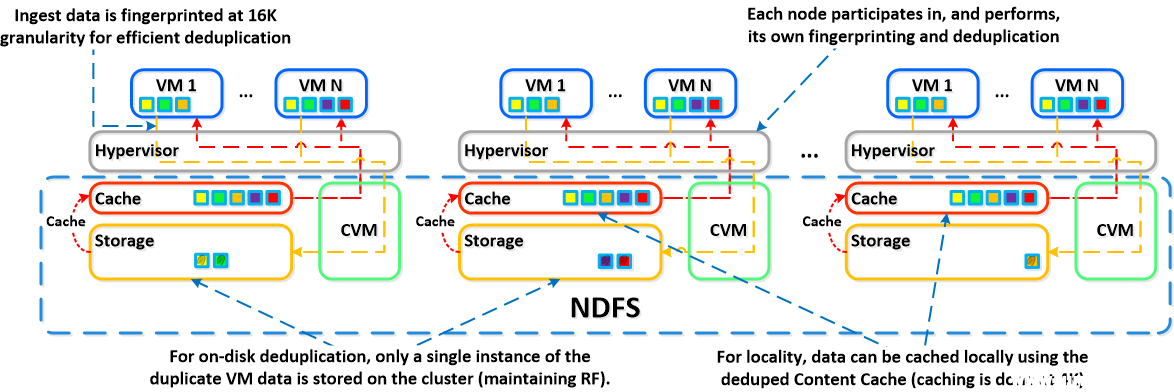
弹性重复数据删除引擎是基于软件的 DSF 功能,可以在容量 (HDD) 和性能(SSD/内存)层执行重复数据删除。在插入数据的过程中,会使用 SHA-1 哈希以 16K 的粒度为连续的数据流提取指纹。指纹只在插入数据时提取,之后则会永久性地存储到写入块的元数据中。这与传统方法相反,传统方法是利用后台扫描,需要重新读取数据,而 Nutanix 直接在插入时提取指纹。对于能够在容量层执行重复数据删除的重复数据,则不需要扫描或重新读取数据,实际上可以删除重复副本。
注意:最初提取指纹时使用的是 4K 的粒度,但在测试之后,16K 在重复数据删除和降低元数据开销这两方面的综合性能最佳。完成重复数据删除的数据保存到缓存中时,则使用 4K。
下面的示例将展示弹性重复数据删除引擎伸缩和处理本地 VM I/O 请求的方式:
当数据 I/O 大小为 64K 或更大时,在插入数据时会提取指纹。SHA-1 计算利用 Intel 加速技术,这一过程仅产生非常小的 CPU 开销。如果在插入数据时没有完成指纹提取(例如 I/O 大小较小时),可以作为后台进程完成指纹提取。
弹性重复数据删除引擎不仅适用于容量磁盘层 (HDD),而且适用于性能层(SSD/内存)。在确定重复数据后,依据相同指纹的多个副本,后台进程将使用 DSF MapReduce 框架(管理者)移除重复数据。对于正被读取的数据,数据会保存到 DSF 内容缓存,这是一个多层/池缓存。对具有相同指纹的数据的任何后续请求都将直接从缓存中提取。有关内容缓存和池结构的详细信息,请参阅 I/O 路径概述中的“内容缓存”小节,或者单击此处。
下面的示例将展示展示弹性重复数据删除引擎如何与 DSF I/O 路径进行交互:
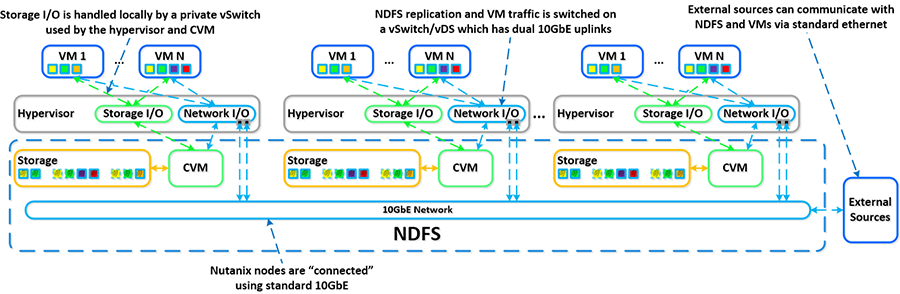
运行机制之网络和 I/O
Nutanix 平台没有利用任何底板/内置交换模块来实现节点间通信,只依靠标准 10GbE 网络。专用私有网络上的虚拟机监控程序可以处理在 Nutanix 节点上运行的 VM 的所有存储 I/O。虚拟机监控程序处理 I/O 请求,然后将请求转发到本地 CVM 上的私有 IP。随后,CVM 将使用其外部 IP,通过公有 10GbE 网络对其他 Nutanix 节点执行远程复制。对于所有读取请求,大多数情况下都可以在本地完成,而不需要利用 10GbE 网络。
这意味着,利用公有 10GbE 网络的流量只有 DSF 远程复制流量和 VM 网络 I/O。但是,如果 CVM 发生故障或数据位于远程位置,CVM 会将请求转发到群集中的其他 CVM。同时,群集范围内的任务(例如磁盘平衡)会在 10GbE 网络上临时生成 I/O。
下面的示例将展示 VM 的 I/O 路径如何与私有和公有 10GbE 网络进行交互:
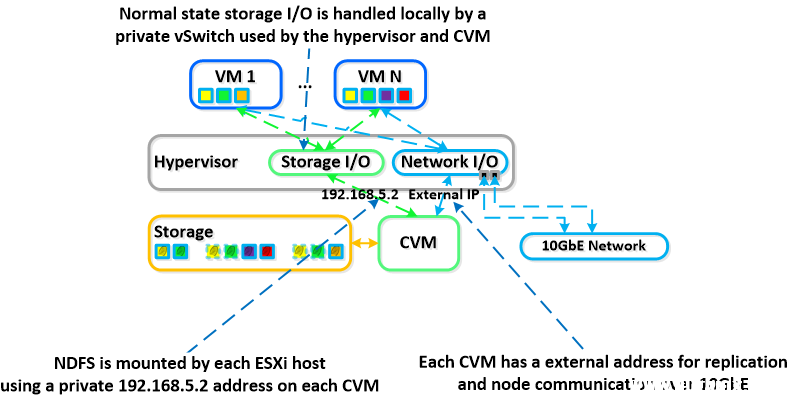
运行机制之CVM Autopathing
对于 DSF,可靠性和灵活性即使不是最重要的部分,也是一个关键部分。作为一个分布式系统,DSF 的作用是处理组件、服务和 CVM 故障。CVM 故障包括用户关闭 CVM 电源、CVM 滚动升级或可能导致 CVM 发生故障的任何事件。DSF 有一个称为“自动寻路”的功能,当本地 CVM 不可用时,则由另一个 CVM 透明地处理 I/O。
虚拟机监控程序和 CVM 使用私有 192.168.5.0 网络在专用 vSwitch 上进行通信。这意味着,对于所有存储 I/O,这一过程发生在 CVM 的内部 IP 地址上 (192.168.5.2)。CVM 的外部 IP 地址用于远程复制和 CVM 通信。
下面的示例将展示此过程:
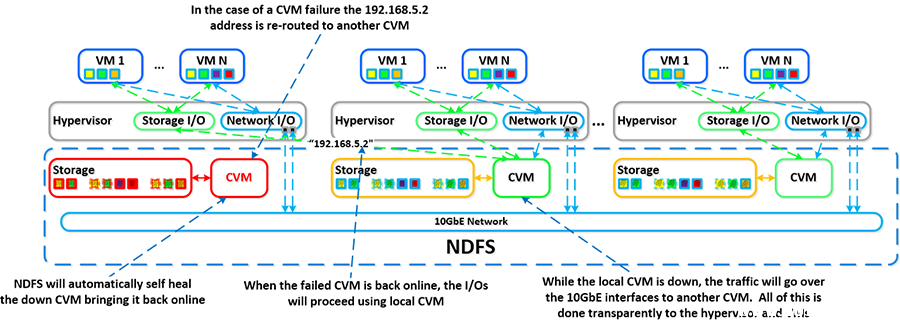
如果本地 CVM 发生故障,之前由本地 CVM 托管的本地 192.168.5.2 地址将不可用。DSF 将自动检测到这一中断,并通过 10GbE 将这些 I/O 重定向到群集中的另一个 CVM。重新路由过程对主机上运行的虚拟机监控程序和 VM 都是透明的。这意味着,即使 CVM 电源已经关闭,VM 仍然能够继续为 DSF 执行 I/O。DSF 也能够自我修复,这意味着它将检测到 CVM 已经关闭电源,并将自动重新启动或开启本地 CVM 电源。一旦本地 CVM 恢复并可用,流量将无缝地回传并由本地 CVM 提供服务。
下面我们将展示故障 CVM 的这一过程的图形表示:
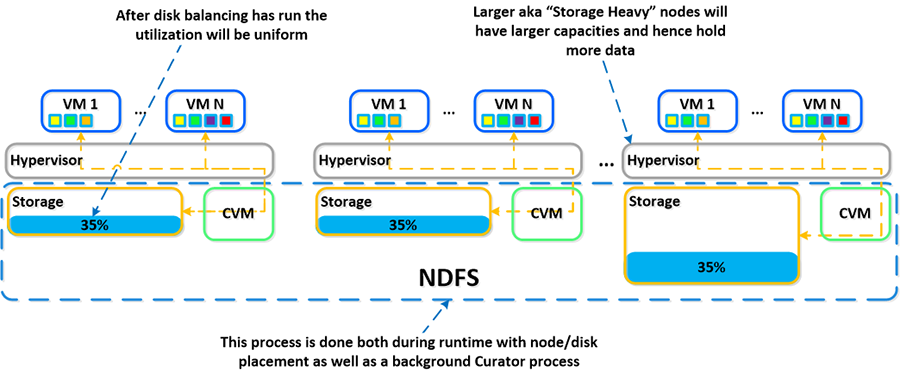
运行机制之磁盘平衡
DSF 采用极其动态的平台设计,可以处理各种工作负载,并且一个群集可以混合使用多种异类节点:计算密集型和存储密集型 。混合使用具有较大存储容量的节点时,必须确保数据均匀分布。
DSF 拥有一个称为“磁盘平衡”的本机功能,该功能用于确保数据在整个群集中均匀分布。磁盘平衡控制节点对其本地存储容量的利用率,并与 DSF ILM 集成。其目的是,一旦利用率达到一定阈值,就让节点之间的利用率保持均匀。
下面的示例将展示处于“不平衡”状态的混合群集(NX3000-计算和NX6000-存储):

磁盘平衡利用 DSF 管理者框架,作为预定进程运行,并在超过阈值时运行(例如本地节点容量利用率 > n %)。如果数据不平衡,管理者将确定需要移动的数据,并将任务分布到群集中的各个节点。
如果节点类型是同类(例如NX-3000),利用率应特别均匀。但是,如果某个节点上运行的某些 VM 写入的数据多于其他节点,则每个节点的容量利用率会有所倾斜。在这种情况下,磁盘平衡会开始运行,并将该节点上的最冷数据移动到群集中的其他节点。
如果节点类型是异类(例如 NX-3000 + NX-6000),或者某个节点用于“仅限存储”模式(不运行任何 VM),则可能需要移动数据。
下面的示例将展示运行磁盘平衡后处于“平衡”状态的混合群集:
在有些情况下, 客户可能需要以“仅限存储”状态运行某些节点,CVM 只在主要用于批量存储容量的节点上运行。
下面的示例将展示混合群集中的仅限存储节点,磁盘平衡将数据从活动 VM 节点移动到该节点:
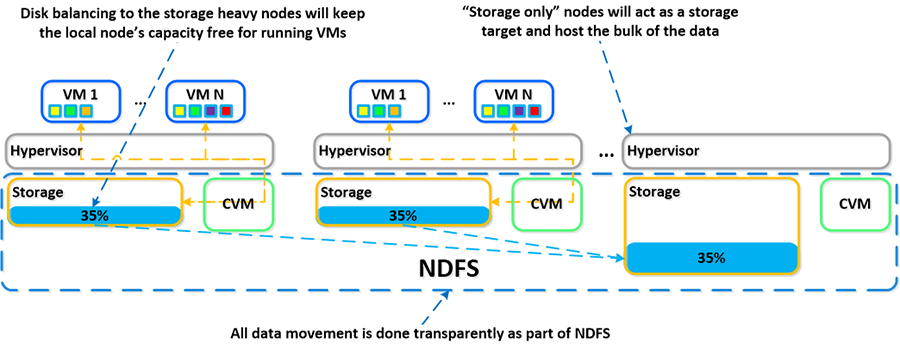
运行机制之存储分层与优先级
上面内容的“磁盘平衡” 讨论了 Nutanix 群集中的所有节点之间如何共用存储容量,以及如何使用 ILM 将热数据保存到本地。类似的概念适用于磁盘分层,其中群集的 SSD 和 HDD 层属于群集范围,DSF ILM 负责触发数据移动事件。
对于本地节点上运行的 VM 生成的所有 I/O,本地节点的 SSD 层始终是优先级最高的层,但是群集的所有 SSD 资源可用于群集内的所有节点。SSD 层将始终提供最高性能,它也是混合阵列需要管理的一个重要事项。
可以按照以下原则在较高级别上划分层优先级:

特定类型的资源(例如 SSD、HDD 等)实现共用,形成群集范围内的存储层。这意味着,群集内的任何节点都可以利用整个层容量,无论是否位于本地。
下面我们将展示共用分层的一个高级示例:

一个常见的问题是,如果本地节点的 SSD 满了将会出现什么情况?正如“磁盘平衡”一节所述,一个重要概念是尽量让磁盘层内的设备利用率保持均匀。如果某个本地节点的 SSD 利用率很高,磁盘平衡将开始起作用,将本地 SSD 上的最冷数据移动到群集中的其他 SSD。这样可以释放本地 SSD 上的空间,以便让本地节点写入到本地 SSD,而不是通过网络。值得一提的是,所有 CVM 和 SSD 都可用于此远程 I/O,以消除任何潜在的瓶颈,并修复通过网络执行 I/O 的某些问题。
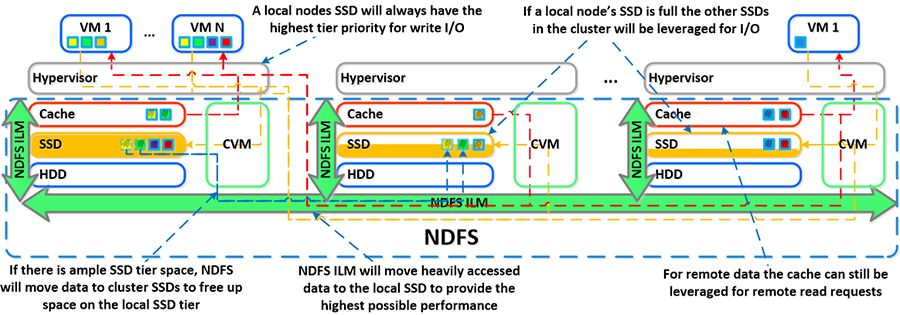
另一种情况是,当整体层利用率超过特定阈值 [curator_tier_usage_ilm_threshold_percent (Default=75)] 时,DSF ILM 将开始起作用并作为管理者工作的一部分,将数据从 SSD 层向下迁移到 HDD 层。这将使利用率保持在上述阈值范围内,或者释放以下数量的空间 [curator_tier_free_up_percent_by_ilm (Default=15)],取两者中较大者。需要向下迁移的数据使用最后一次访问时间进行选择。
如果 SSD 层利用率为 95%,则 SSD 层中 20% 的数据将移动到 HDD 层 (95% –> 75%)。但是,如果利用率为 80%,按照最少的层释放数量,只有 15% 的数据会移动到 HDD 层。

DSF ILM 将持续监控 I/O 模式并按需要(向下/向上)迁移数据,同时还会将最热数据保存在本地,而不论其在哪一层。
可用性域
可用性域(也称节点/块/机架感知)是分布式系统在确定组件和数据位置时所遵循的一个关键结构。DSF 当前具有节点和块感知功能,但随着群集大小不断增加,将增加机架感知功能。Nutanix 用“块”指代包含一个、两个或四个服务器“节点”的机架。注意:要激活块感知,必须使用 3 个块。
例如,NX-3460-G5 是一个具有 4 个节点的块。跨多个块分布角色或数据的原因在于,当一个块发生故障或需要维护时,系统可以不间断地继续运行。注意:在块中,冗余 PSU 和风扇是唯一共享的组件。
感知可以分为几个关键领域:
- Data (The VM data)
- Metadata (Cassandra)
- 配置数据 (Zookeeper)
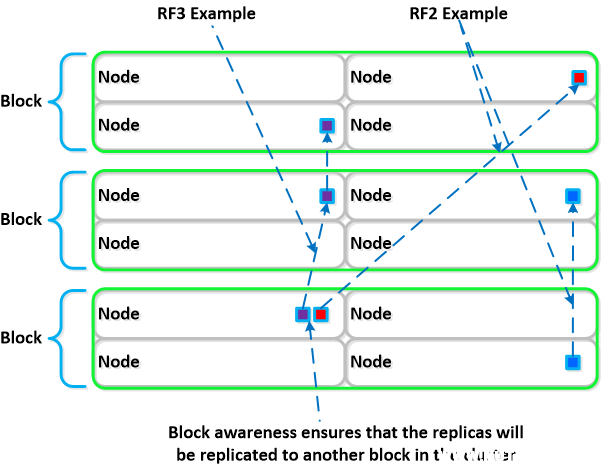
数据
借助 DSF,数据副本将写入到群集中的其他块,以确保在某个块发生故障时或计划停机时间,数据仍然可用。这同样适用于 RF2 和 RF3 场景以及块故障。
可以与“节点感知”做一个简单比较,在节点感知中,副本需要复制到另一个节点,从而在节点发生故障时提供保护。块感知在块发生中断时提供数据可用性保证,进一步加强了保护。
下面我们将展示副本位置在有 3 个块的部署中有何作用:
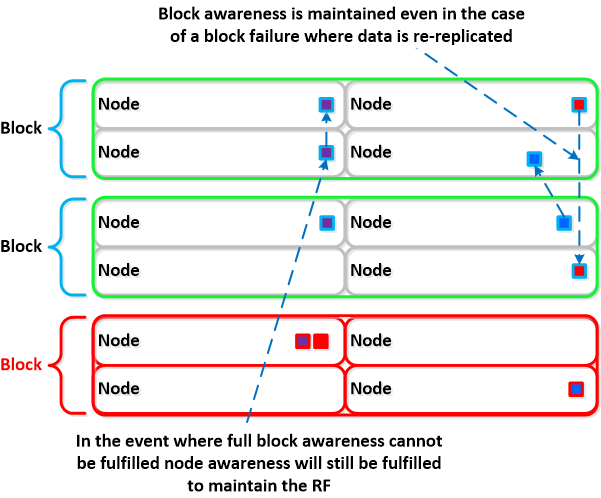
如果块发生故障,块感知将保持运行,重新复制的块将复制到群集中的其他块:
通过以上对Nutanix超融合架构设计和部分运行机制的介绍,希望能够让大家对Nutanix超融合平台所采用的技术有所了解,非常感谢。
Nutanix企业云展望
Nutanix企业云平台展望:
目标:摆脱基础架构的束缚,给予应用充分自由
以应用为中心
- 注重服务水平协议与成本
- 公有与私有应用商店相集成
可定制,同时又简单易用
- 采用类似于Webscale的策略
- 基础架构即可视化代码
平台构建围绕选择 和自动化展开
- 全堆栈自动化
- 一切均可选择(HW/VM/容器/协议……)
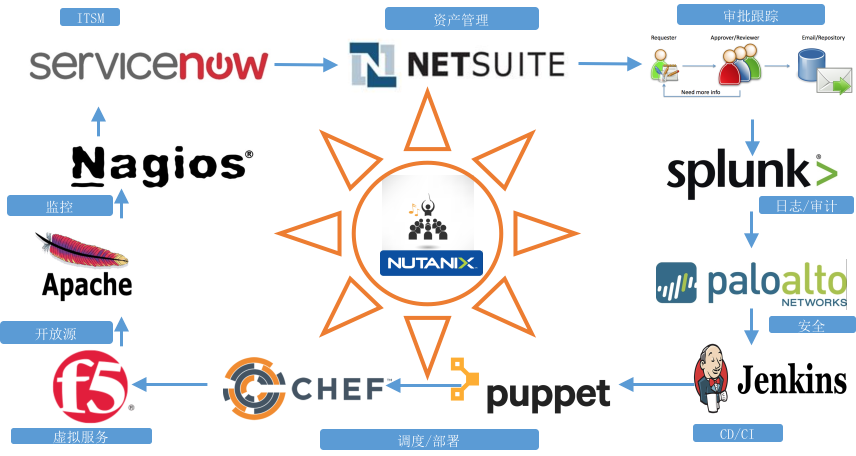
Nutanix企业云生态系统:

概括来看,Nutanix企业云是基于现有标准化、模块化、单一管理界面的超融合系统,在2016年中收购的Calm.IO功能基础上(代码级整合),所构建的以应用为核心的企业云平台,并能够提供与公有云之间的互通。
收购之前的Calm.IO可以看成是一个DevOps自动化 平台,以可视化的应用与服务编排管理界面,通过API和SDK等的调用,实现从应用开发测试到部署的一系列自动化管理过程,例如部署到AWS和Azure这样的云服务SP。在Calm.IO 1.83的版本已经可以结合Nutanix超融合集群,并将其作为企业云平台基础资源服务提供者,进行开发、测试与部署的自动化管理。
Calm.IO 1.83版本的界面如下所示:
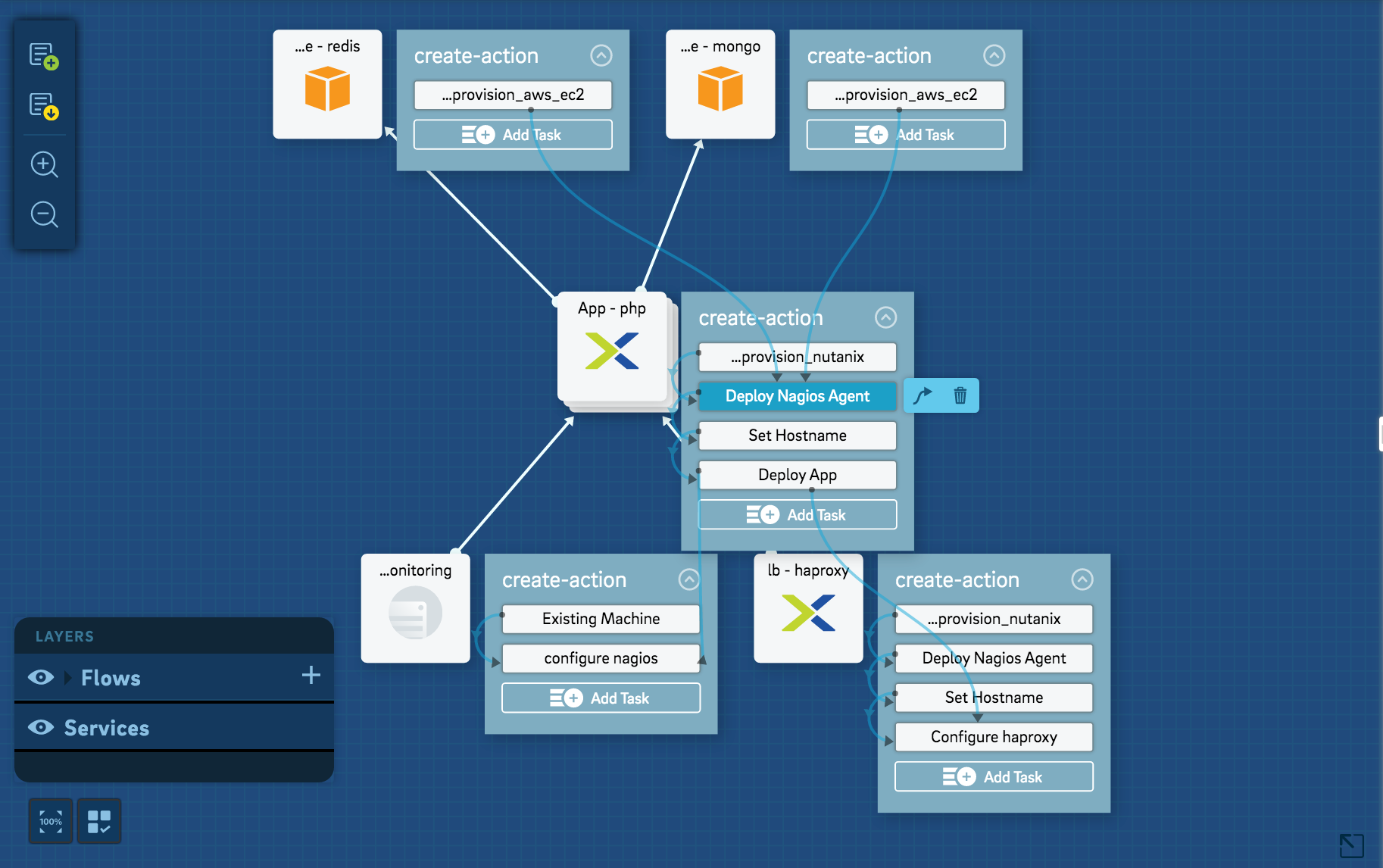
云与API、SDK和自动化有关,Nutanix超融合平台提供了本身基础架构的统一API调用,而收购Calm.IO提供了与更多对于应用及公有云平台的支持,这两者的整合将在下半年的Nutanix大会发布的 Tech-preview版本中得以体现。
我们希望能够通过自动化管理平台与API、SDK的集成,实现Nutanix企业云完整的生态系统。
如下图所示:
Nutanix企业云界面预览如下图所示:
1、应用商店:

2、与第三方目录的集成(AWS、VMware等)
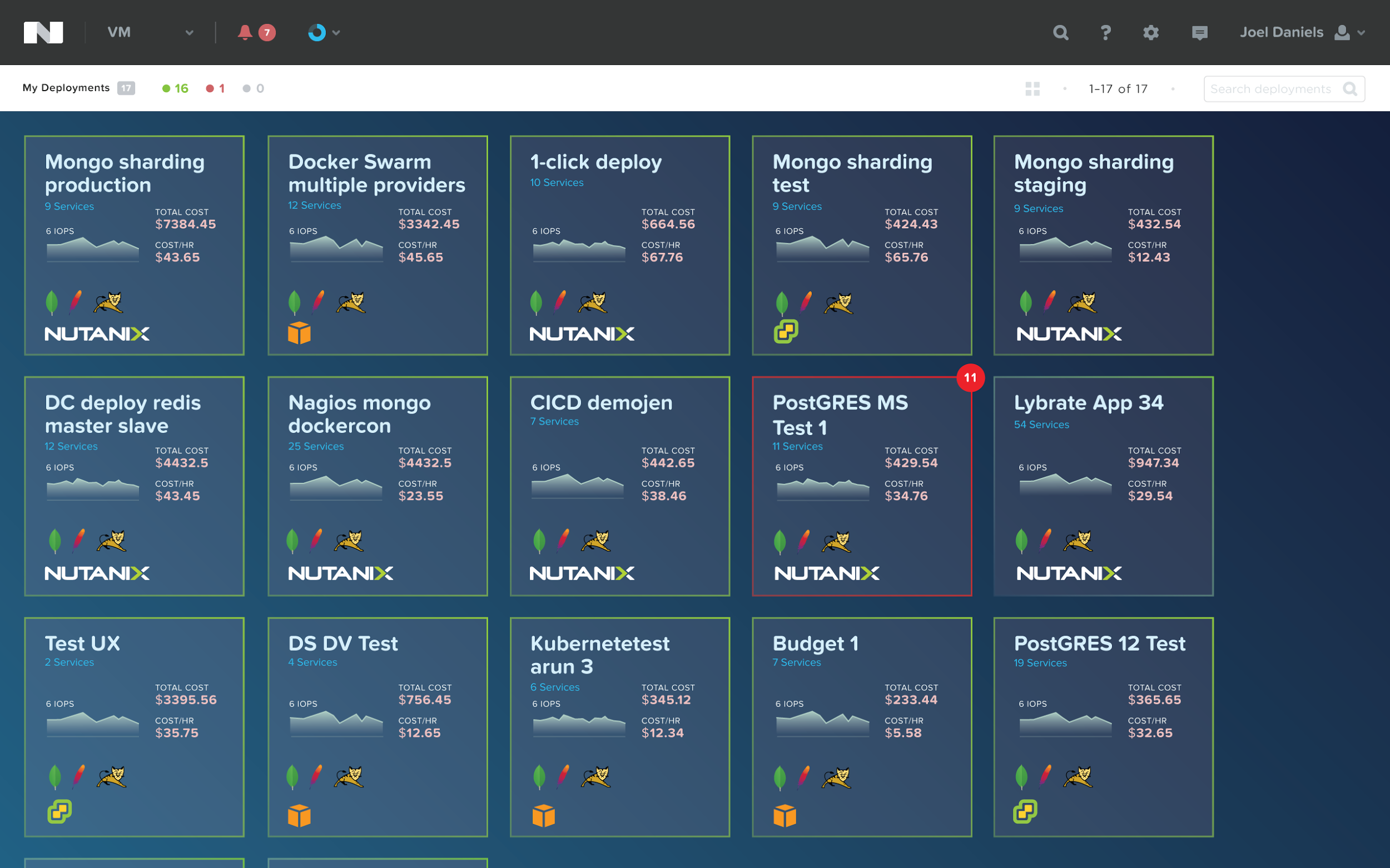
3、Nutanix企业云展望:
- 一个平台运行所有应用
- 开放的应用商店
- 精选应用列表
- 由Nutanix提供的
- 合作伙伴应用
- 自建应用
- 评论与评级
- 支持渠道
- 多云
- 全自动
- 可管理的 LCM
- 成本/货币化
以上是对Nutanix基于超融合架构的企业云平台发展展望,更详细的内容分享还需要等到今年7/8月份的Nutanix .NEXT会议之后。
分享内容文档下载链接:https://pan.baidu.com/s/1slzvOJV
Q&A
Q1:你们对数据中心的规划是如何考虑的?
A1:Nutanix主要是做基础架构的公司,因此对于企业云数据中心的规划,是在IAAS层面上适当考虑与paas的结合,而对于基础架构来说,是基于超融合的标准模块化方式构建存储、计算一体化平台,在后续的版本中也会增加虚拟化平台Micro segment的内容. 在数据中心整体架构方面,会结合业界的网络、负载均衡等厂商方案,在企业云平台中予以集成,如上述的生态系统图。此外,对于数据中心基础架构规划方面比较全面的技术发展介绍, 个人觉得ZDNet在13年的“软件定义与硬件重构”不错,是比较好的中文公开发行资料,可以结合当前的技术发展趋势作为参考。
Q2; 竞争分析可以介绍下吗? 主流的超融合之间的比较
A2:关于竞争分析,从技术角度讲会比较多,我下面引用一个用户在选择Nutanix时候的分析吧,他写的比较简洁.
这个用户从09年开始虚拟化,虚拟化软件是vSphere。经过前期对比,最终方案在Nutanix和vSan间选择,最后他考虑1、兼容性对系统的影响——以前吃过很多兼容性造成的苦头,因此没有选择软件排他的vSAN;2、Nutanxi在这个用户的应用性能测试时有很好的表现和对比,应用测试主要是他们核心的SQL Server数据库,用的实际业务数据;3、 保留一定的软件平台选择性也是用户考虑的一部分因素;因此最终这个用户选择了Nutanix。当然不同用户的关注点也可能会有所不同。

Q3: 请问Nutanix可以和Openstack云平台整合吗?
A3:Nutanix可以和OpenStack云平台进行整合,通过一个或一组已定制的OVM,内含Openstack的驱动,如下图所示:
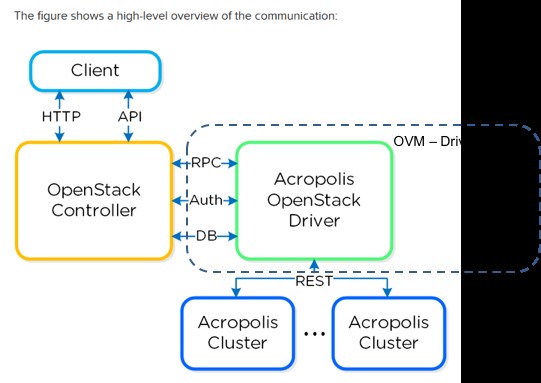
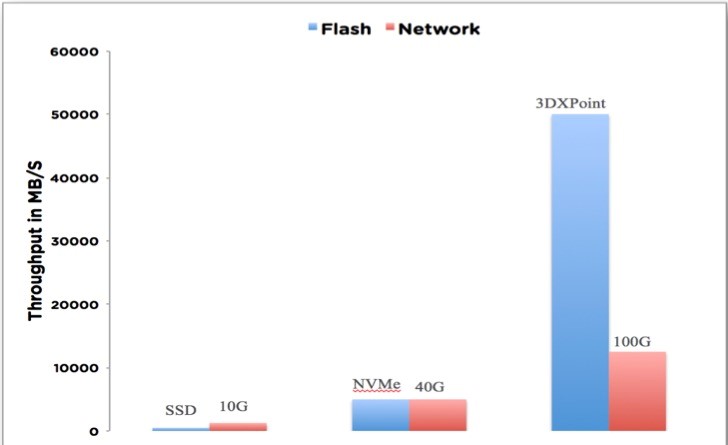
Q4:Nutanix有节点数规模限制吗?会受到传统网络架构的限制吗?
A4:节点规模数没有明确的限制,但在软件版本上有限制:标准版最大12节点,高级版和Ultimate版无限制,但实际部署时还是要根据网络、数据、应用的情况进行考虑,例如百思买现在是660个节点、5PB数据,但也根据实际情况做了多集群部署,通过Prism Central统一管理,通过数据本地化功能能够最少的使Nutanix受到传统网络架构的限制
如上图,在后续NVme和3dxpoint这样的技术出现后,如果没有数据本地话化,即使网络也会存在瓶颈。
Q5: oracle rac可以跑着nutanix上吗?可以讲讲技术实现吗?
A5:可以,很多实际案例,Oracle跑在Nutanix上的问题,从两方面看1、大部分用户做Oracle RAC不是为了性能而是为了可靠性;2、目前PC服务器单处理器已经可以支持24个计算核心,有足够的计算能力应对Oracle的需要;3、Nutanix的缓存技术在混合模式下已经可以提供很好的性能,同时支持pIN模式——全数据库保存在ssd 上,即使在混合模式;4、全闪存在IO上也能满足Oracle的io需要。
Q6:上面两个集群可以做同步吗?通过什么技术实现数据同步?
A6:集群间支持同步和异步两种数据复制方式;DSF底层的自有复制功能实现,DSF底层除了上述的几个关键服务外,其实一共有29个底层服务,里面包含了复制功能
Q7:如果都是大于128K的查询文件适合使用nutanix平台吗?
A7:大于128K的查询文件也适合使用nutanix平台。需要根据实际场景的工作负载和数据量等相关因素,对Nutanix平台进行配置选择。
Q8:请问一下,虚机与cvm 的io是通过iscsi 还是smb 的方式实现的
A8:esxi是nfs ahv是iscsi hyperv是smb,虚拟机与CVM的IO,通过前述的cvm中的Stargate服务,在形式上,对KVM/AHV是ISCSI,对ESXi是nfs,对Hyper-v是smb
Q9:超融合常被业界和分析师公司和其他存储相关技术比较,比如SAN,有人(简单化地)认为超融是直接来颠覆SAN技术(你死我活的zero-sum game),个人觉得支持的应用负载实际上有很具体的差异区分(各有所长),请问Nutanix怎么看?是否有non-zero sum game的可能?
A9:非零和的课题,我觉得也是存在的,就如小机和PC服务器,PC服务器的增长快并不意味着小机失去了市场,存储市场也是一样的,只是从发展趋势来看,超融合这样的技术会在后续的场景中相比传统存储发展更快。此外您也可以看到,高端存储的架构本身也已经逐渐有从专用芯片和网络向x86芯片和通用网络等方向发展的趋势,例如HDS也推出了基于 X86芯片的产品。
Q10:超融合对底层网络有什么要求?
A10:Nutanix在生产环境超融合部署中,一般还是建议采用万兆网络, 当然也需要考虑网络延——与分布式系统的I/O性能相关。 但还是看应用规模, 应用体量小的时候,千兆都没有问题。因此不同场景底层要分开讨论。
Q11:比如:因为网络规模是不可能无限的大,不安全和稳定性的问题。为了解决实际部署,都会分割较小规模来考虑。这就是我所讲的nutanix如何规划数据中心的问题?
A11:数据中心规划的议题很大,我觉得总的来看,从数据中心基础架构来看的发展趋势还是软件定义和硬件重构——13年至顶网的那篇文档写的还是不错的,可以参考。从本质上讲,超融合和云计算实现的都是数据中心的自动化,但数据中心规划从目前看还有所谓Green field以及已有legacy system——尤其是应用——及架构的问题。Nutanix Blobal现在也在做与OCP的结合,不过还在测试阶段,后续有一定的进展可以报告时,我们再做进一步的分享。
Q12:nutanix的产品有做网络闭环反馈的案例吗?
A12:您说的网络闭环反馈是指节点间互连的方式吗?这个没有。不知道是否正确理解了您的问题;nutanix目前自己的AHV虚拟化平台上的网络方面是完全基于openswitch的实现。
Q13:nutanix 计算资源池是通过x86服务器虚拟化来实现的,虚拟化后装RAC没问题吧?
A13: nutanix 计算资源池是通过x86服务器虚拟化来实现的,虚拟化后装RAC没问题吧:没问题,ESXI下仲裁盘可以用vmfs打开multi write,ahv下用iscsi——nUtanix有ABS服务,ABS是acropolis block service,通过dsf也可提供对外的iscsi块存储服务。Oracle RAC运行于虚拟化平台,我自己在2012年重庆地税金税三期项目里就已经有过实践,单纯从技术上讲是肯定没有问题的。
--------------------------------------------------------------------------
SDN实战团微信群由Brocade中国区CTO张宇峰领衔组织创立,携手SDN Lab以及海内外SDN/NFV/云计算产学研生态系统相关领域实战技术牛,每周都会组织定向的技术及业界动态分享,欢迎感兴趣的同学加微信:eigenswing,进群参与,您有想听的话题可以给我们留言。








