

作者简介:向阳,云杉网络研发总监、网络架构师。2013年获清华大学计算机科学与技术博士学位,师从吴建平教授并独立实现了世界上第一个基于关联分析的 BGP 劫持检测系统,因此摘得 Internet Measurement Conference( IMC,网络测量领域国际顶级会议)社区贡献奖。2015年获得清华大学博士后证书,主要研究方向为云数据中心网络架构,获得了多项网络安全、云数据中心相关专利。2013年起加入云杉,负责云杉 DeepFlowTM 云网分析的架构设计和核心功能实现。
前几年大家讲 SDN 比较多的是怎样利用控制器,像 OpenDayLight、ONOS 这些东西,其实在讲怎样做一个 Driver、怎样做控制。大概从去年开始,SDN 开始跨入应用的时代,现在大家更多地在讲实际要做的事情、应用场景是什么。由于大家对 SDN 有多种不同的理解,在本文中我想把话题聚焦一下,落到云数据中心的网络运维这个点上,分享一些运维中的实际例子。没有大的篇章,只说说我们遇到的那些苦与乐。
因为本文话题的场景是云数据中心,所以我们有必要先看一下云数据中心里面的网络是什么样子。
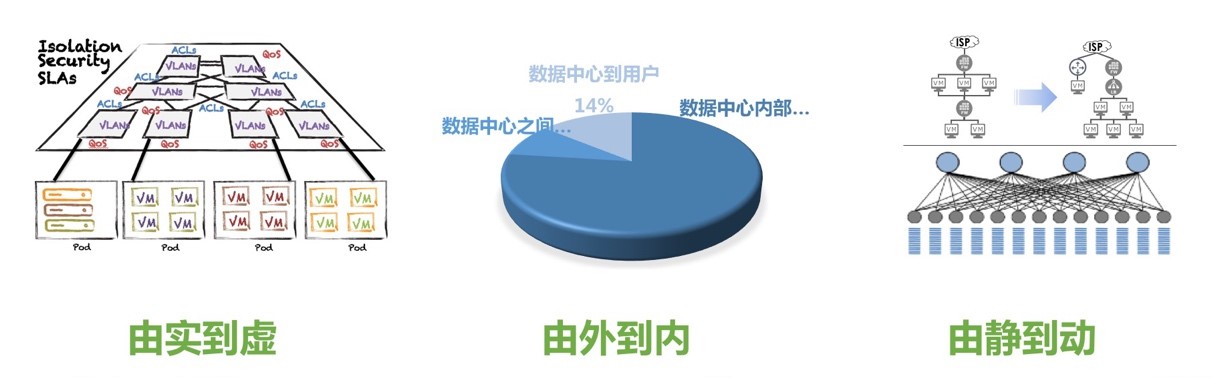
简单来说,云数据中心的网络环境发生了如上图所示的三大变化,网络由物理的变为虚拟的;流量由南北的变成了东西的;配置由静态的变成了动态的。以前数据中心的网络比较简单,那时数据中心的网络运维也比较干净;后来随着虚拟化技术的进入,这个网络变得复杂起来。由于业务形态和网络模型的变化,流量随之由南北向为主变成了东西向为主,这个变化也是目前运维技术特别头疼的题目。最后一个让运维人员头疼的变化是,网络配置的变更随着业务的发展已经变得动态且无休止。
此外,众所周知还有一些中国特色的网络,比如互联互通的问题,以及抗 DDoS 的产品和服务需求巨大。本文试图厘清在这样的网络环境下怎样解决运维的难题。
那些熟悉的“车祸现场”
让我们先看几个运维人员特别熟悉的“车祸现场”吧。
第一个比较常见的问题是没有收到报警但是用户报障。当然,这并不是云数据中心网络特有的现象,只不过是在云数据中心这个问题更加突出。以前运维看到的网络是“租户—数据中心—运营商”,现在看到的网络在数据中心和租户之间多了一个“云平台”——这里增加了一个复杂的拓扑层。一般情况下网络和服务器可能是两个团队,现实情况下网络的健壮性要高于服务器,当出现网络风暴的时候,最先被打趴下的往往是服务器——以及上面的租户。这就是为什么网络没有报警而用户却在报障。
第二个问题是常见的 Loading 故障定位。运维人员经常要和开发团队去讨论到底是网络的问题还是应用的问题,往往耗费很大精力比如用数据证明交换机上没有 error、能否看到 TCP 会话、甚至借助 Web 统计工具的结果来区分故障边界。

第三个常见的问题是 UDP 4789。尽管 VxLAN 已经标准化并且很多地方都在用,但实际上网络运维人员并不能看到 HTTP、DNS、ARP 等包头信息。这也给运维工作带来了很大的挑战。
第四个常见的问题略坑。运维人员在故障响应的时候,往往会在交换机上做一些临时的变更,比如创建一个 SVI、增/减一个 VLAN 之类;在应急处理完毕之后常常忘记回滚这些操作,“手术后不小心留在患者体内的纱布”在未来的某一天就会变身成新的故障。道理都懂,“我们应该用自动化、用机器减少这些人为的失误”。
第五个常见的问题是环路。网络风暴在虚拟网络里会进一步放大,尤其是虚拟交换机的性能和物理交换机无法相比,本来不足以构成威胁的问题此时也成了大问题。
第六个常见的问题是后端主机莫名故障。排查下来发现很可能是因为 DNS 配置不当所致;其他还有一些常见问题诸如 IP 的管理、多线接入流量统计的问题等等,本文不再赘述。
一个真实的部署场景
下面介绍一个实际的部署场景。
我们要面对的通常是基于 OpenStack 或者 VMWare 的云环境。控制器通过云平台的网络模块如 Neutron、NSX 来获取我们想要的项目、资源和网络的元数据,比如物理服务器、租户、Subnetwork 等。除了元数据,我们还会获取交换机的配置和状态信息。此外我们还会通过分光或镜像的方式获取一些网包,一般来讲云的环境里会有较多的网络重叠,我们需要全量的包头以保留更多的信息。
总体来说交换机上的信息都是传统网工所熟悉的。通过控制器 Web 页面,我们可以对服务器(比如 KVM 宿主机)上的虚拟交换机执行自动化网络诊断,例如最基本的虚拟端口 VLAN 配置正确性检查等;对于虚拟机之间的东西向流量,我们可以在宿主机上插入 DFI 内核模块,或者在服务器上启动一个虚拟机用于数据采集,这样就能拿到 OvS 的全部网包了。拿到数据之后我们选择输出网流(当然我们也可以输出网包),为什么是网流呢?
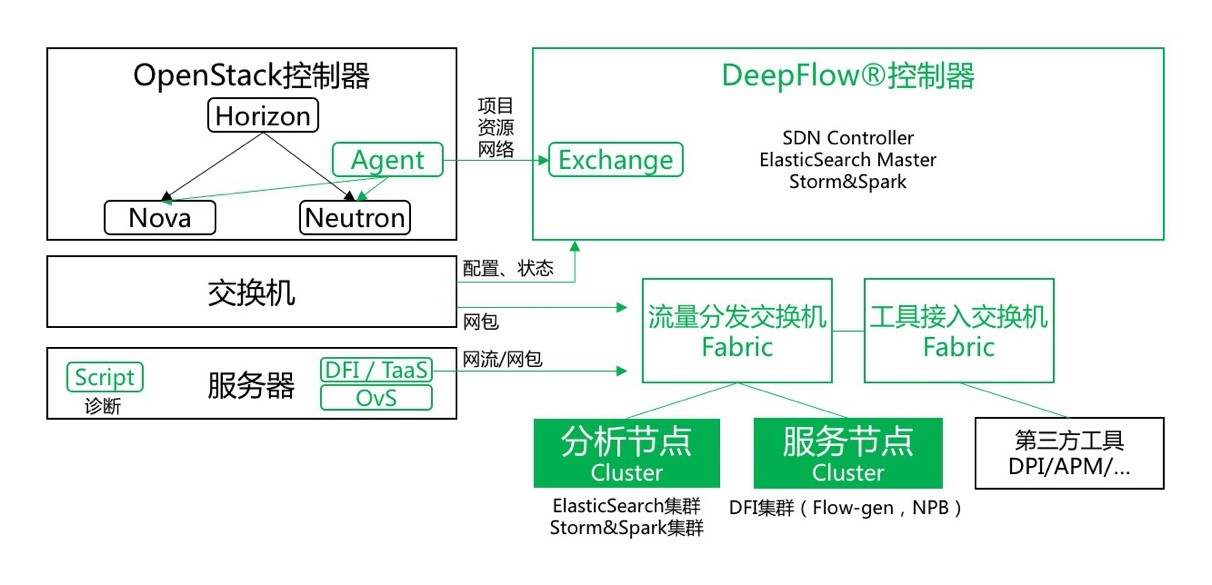
因为大多数情况下理想和现实是有差距的:对于网络监控来说,服务器往往不会预留端口,又或者网卡不够用。而转成网流之后的数据量非常小(当然这会占用生产网络的一点点带宽),这样我们就可以把采集到的信息导给监控网络了。当需要更细粒度分析的时候我们可以选择输出网包。这里的网流你可以认为是为云数据中心定义的增强版 NetFlow。最后一步是网流吐到分析节点进行更多的处理。
说到网流,不得不说包头,这个在下面的篇幅展开。
起承转合四式组合拳
多数人面对的也不可能都是 BAT 那么大量级的服务器,我们的 DeepFlowTM 云网分析最小可以支持一台交换机、一台 2U 高密度服务器(一个控制器三个节点)。在本文所述的部署场景中,当用户报障的时候我们可以通过一下简单的四步操作,快速定位问题。

1、首先控制器 Web 页面上可以触发对 OvS 的自动化网络检查,把排障范围进一步缩小。
2、其次可以集中执行多个端口的网络监听,这有点像 Splunk 的做法,将信息汇总分析。
3、当 tcpdump 依然无法定位故障的时候,我们可以通过在 OvS 上构造一个包,通过分析回包定位故障;这里有技术挑战的地方在于回包不能对虚拟机的业务有实际的影响。
4、最后当我们排除了 Overlay 网络层面的问题后,可以通过关联 Underlay 网络路径进一步对物理网络进行检查。
通过以上四步检测,多数情况下故障都能被排查到。这样该网络处理的问题就网络团队解决,是应用出现的问题就找开发团队处理去吧。
云网分析的技术栈
虽然目前运维界都在谈自动化,但我们希望更进一步——要有一个智能的解决方案,这样运维人员才能有一个好的睡眠。经过几年的摸爬滚打和不懈的努力,我们基于 Flow 的原理设计了这样一个技术栈,如图所示这是一个闭环。
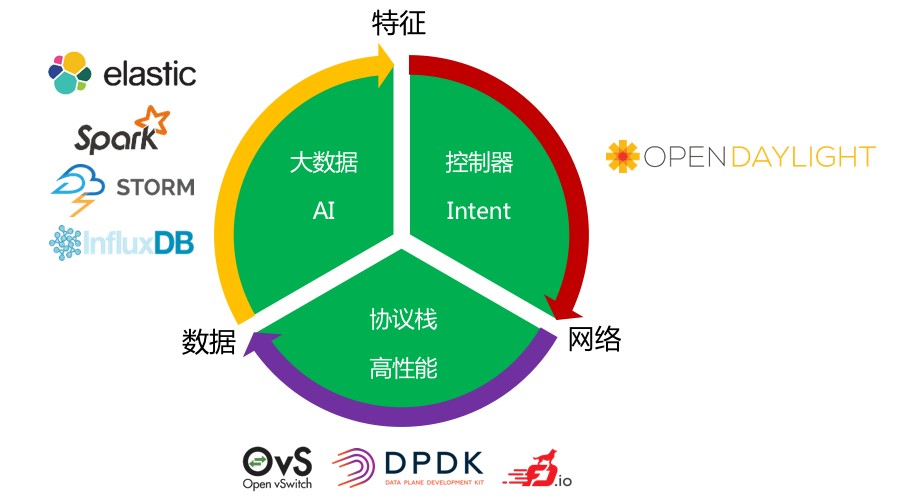
几年之前大家谈的控制器,开源 Driver(OpenDayLight、ONOS等) 其实已经做的挺好了,但他们并不是 product ready 的。我们做 DeepFlowTM 是限定在云数据中心网络监控分析的应用场景之下,控制器把从网流特征中提取出来的配置 deploy 到生产网络中。
基于 OvS 比较常见的 DPDK、FD.io 最近也很流行,在协议栈部分我们专注在高性能方面。同样的网络环境,我们利用高性能技术可以更快、更多地采集到数据。
在大数据方面,我们主要是通过实时流处理和机器学习技术,从中提取特征并反馈给控制器部分。就这样,从一段数据中提取特征、制定规则、下发网络、再观察/采集数据,如此循环。
关于大数据分析
我们做了一些基础的工作来解决运维场景的问题。比如前面提到由于 SVI 带来的 IP 冲突问题、网络的环路、审计日志等问题。关于大规模实时流处理业界已经讲过太多,本文从略。从网工的角度,我们并不关心 Payload 文件的内容。但是在虚拟化网络中细粒度计量变得比较困难,Netflow 已经无法满足。前面提过,在 OvS 层我们会把一个 Flow 对应的近百个字段完整地采集下来,通过和云平台对接实现映射关系的还原后再分析,能轻松应对 ECMP、浮动 IP 等应用场景。
以大家熟知的 IPv4 希尔伯特图为例,DeepFlowTM 提供的 IP 活跃度功能即可实现类似的展现:用户可自行设定某个网段,网段中所有IP地址的活跃时长或分配量可轻松地全局展示。
关于包头
从监控分析的角度来说,业界已经做到了 DPI 的层面,似乎很难再做出什么有新意的东西,但业务在不断变化,对网络监控的需求也是水涨船高。我们从软件的角度做了基于 X86、可扩展的高性能。
为什么我们能在一条很微小的 Flow 里保存那么多的字段数据?从包到流的聚合最重要的是压缩比。我们能做到对同一个 Flow 在不追求极致性能的前提下压缩比达到90%以上。在现在主流硬件设备的默认配置下,我们处理数据的能力是 100Gbps 起,存储时间是30天起。对网络故障的历史回溯能力自然不可同日而语。








